Classification of proposals using neural networks without pre-processing
Quite often there is the task of classifying texts — for example, determining tonality (whether the text expresses a positive opinion or a negative one about something), or posting text on topics. On Habré there are already good articles with an introduction to this question .
Today I want to talk about the problem of classification of individual sentences. Solving this problem allows you to do many interesting things, for example, to distinguish positive and negative points from long texts, to determine the tonality of tweets, it is a component of many systems that respond to natural language questions (classification of the type of question), helps to segment the web page into meaningful blocks and much more. . However, the classification of individual sentences is much more complicated than the classification of large blocks of text — in one sentence there are considerably fewer useful signs, and the influence of word order is great. For example: “as it should be for a horror film, this film was very creepy” - contains negative words (“horror”, “creepy”), but expresses a positive opinion about the film, “everything was terribly beautiful”, or even “a great film, nothing you will not tell, only in vain money spent ".
Traditionally, this difficulty is tried to be solved with the help of preprocessing of the text and manual selection of signs. Pre-processing can include as relatively simple techniques (taking into account the negation by sticking the particle "not" to the following words), there are more complex sets of rules for switching the tonality, as well as building a dependency tree, and in the manual signs - dictionaries of positive and negative words, place words in a sentence, and others - how much fantasy is enough. It is clear that this process is tedious, requiring many third-party functions (for example, a parser is needed for parsing sentences, dictionaries), and is not always effective. For example, if the authors of the sentences made a lot of grammatical errors, the parser that builds the dependency tree starts to get very confused, and the quality of the entire system decreases sharply.
But the matter is not even this - but the fact that it is too lazy to do all this. I am deeply convinced that machine learning systems should work end-to-end - download the training data - get a working model. Even if the quality falls by a couple of percent, but labor costs will be reduced by an order of magnitude, and the way will open for a large number of new and useful applications (for example, I found an article about an interesting application of the text classifier).
')
Theory : But in short, from words to deeds. In order for a proposal to be submitted to the input of a neural network, several problems need to be solved. First, you need to convert words to numbers. The first desire that arises is to compare each word from the dictionary with its own number. Say (Apricot - 1, Apparatus - 2, .... Apple - 53845). But this cannot be done, because in this way we implicitly assume that apricot is much more like a machine than an apple. The second option is to encode words with a long vector, in which the desired word corresponds to, and to all the others - 0 (Apricot - 1 0 0 ..., Apparatus - 0 1 0 0 ..., ... Apple - ... 0 0 0 1). Here all words are equidistant and not similar to each other. This approach is much better and in some cases works well (if there are a lot of examples).
But if the set of examples is small, then it is very likely that some words (for example, “apricot”) will be absent in it, and as a result, having encountered such words in real examples, the algorithm will not know what to do with them. Therefore, it is optimal to encode words with such vectors so that words similar in meaning are close to each other - and far, respectively - far away. There are several algorithms that “read” large volumes of texts, and on the basis of this they create such vectors (the most famous, but not always the best, word2vec). Details are a topic for a separate conversation, while for understanding it is enough to know that there are such methods, they take as input long arrays of texts and give out vectors of fixed length corresponding to each word.
Having received word vectors, we are faced with task number two - how to present a complete sentence for a neural network. The fact is that normal feed-forward neural networks must have input data of a fixed length (see image). I will not explain how the classical artificial neural network of direct propagation works here - there are already enough articles on this subject, see, for example . To complete the picture I will insert only a drawing.
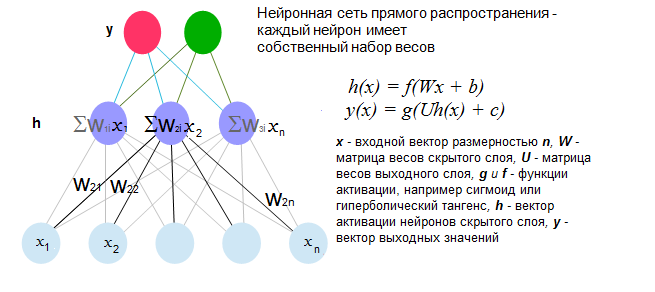
So, our problem is that all sentences contain different numbers of words. The easiest way out is to add all the vectors, thus obtaining the resulting vector of the sentence. Having reduced all such vectors to unit length, we obtain suitable input data. Such a presentation is often called “neural bag of words” (NBoW) - “neural bag of words” because the word order in it is lost. The advantage of this algorithm is the extreme simplicity of implementation (having a word vector at hand and any library with the implementation of neural networks or another classifier, you can make a working version in 10 - 20 min). At the same time, the results sometimes surpass other more complex algorithms, remaining, however, far from the maximum possible (this, however, depends on the task - for example, when classifying texts on product reviews / product descriptions / others, NBoW has shown 92% accuracy on test sample, versus 86% of the algorithm using logistic regression and a carefully selected manual dictionary).
However, we have already said that word ordering is important for the classification of sentences. In order to preserve the word order, a sentence vector can be formed by connecting all the vectors of the words “head to tail” into one long vector, if of course you figure out how to transfer the neural network with input data of different lengths.
A small digression — the attentive reader should be indignant — I promised the classifier of sentences without preliminary processing, but to divide the sentence into words and convert it into a vector is already a preliminary treatment. Therefore, I had to write "with minimal pretreatment." But this doesn’t sound so good, and besides, compared to conventional methods, such processing is not generally considered. Today there are methods that allow you to work directly with letters, allowing you to avoid dividing sentences into words and converting them into vectors, but this is again a separate topic.
Let us return to the problem of different lengths of input data. It has different solutions, but for now we will consider one thing - namely, the convolution filter. The idea is simple - we take one neuron and feed two (or more) words to the input (see Figure 2). Then we shift the input by one word and repeat the operation. At the output, we have a presentation of the proposal, which is two (or n) times smaller than the original one. At the same time, there are usually several such filters (from 10 to 100). Then the operation can be repeated by placing the first layer over the first one, the second one using the input values of the first one until the whole sentence is minimized, or, at a certain stage, choose the maximum activation value of the neuron (the so-called pooling layer). Due to this, the last layer of neurons gets a representation of a fixed length, and he already predicts the desired category of the sentence.

The main result - the neural network gets the opportunity to build hierarchical models, forming in each subsequent layer more abstract representations of the proposal. There are a number of modifications that differ in the details of the architecture, while some of them not only get the best known results in the classification of sentences for standard tasks, but can also be trained to translate from one language to another.
In general, such networks are similar to those that are successfully used in image recognition, which is again nice (one architecture for all tasks). The truth is completely alone does not work - the networks that process the text, still have their own characteristics.
Experiments: For experiments, we had to write the implementation of a neural network on our own. We did not want to do this, but it turned out that this is easier than using some ready-made libraries, which are also difficult to transfer to the final application. Well, it is useful in terms of self-education. Moreover, we do not need this implementation by itself (although this is useful), but as part of a large system.
In our test implementation of a simple convolutional network, there are three layers, one convolutional layer, one merging layer, and the upper fully connected layer (as in the first figure), which gives the actual classification. All this follows approximately the description of the system from the work of Kim et al, 2014 - there is also an illustration, which I will not copy here, so as not to think about copyright once again.
As a test object, we took a standard set of positive and negative sentences about films in English. Here's what happened:
In general, it turned out quite well. The best published result on this data for such networks is now 83% with 100 filters (see the article above), and the best result using manual selection of signs is 77.3%.
Today I want to talk about the problem of classification of individual sentences. Solving this problem allows you to do many interesting things, for example, to distinguish positive and negative points from long texts, to determine the tonality of tweets, it is a component of many systems that respond to natural language questions (classification of the type of question), helps to segment the web page into meaningful blocks and much more. . However, the classification of individual sentences is much more complicated than the classification of large blocks of text — in one sentence there are considerably fewer useful signs, and the influence of word order is great. For example: “as it should be for a horror film, this film was very creepy” - contains negative words (“horror”, “creepy”), but expresses a positive opinion about the film, “everything was terribly beautiful”, or even “a great film, nothing you will not tell, only in vain money spent ".
Traditionally, this difficulty is tried to be solved with the help of preprocessing of the text and manual selection of signs. Pre-processing can include as relatively simple techniques (taking into account the negation by sticking the particle "not" to the following words), there are more complex sets of rules for switching the tonality, as well as building a dependency tree, and in the manual signs - dictionaries of positive and negative words, place words in a sentence, and others - how much fantasy is enough. It is clear that this process is tedious, requiring many third-party functions (for example, a parser is needed for parsing sentences, dictionaries), and is not always effective. For example, if the authors of the sentences made a lot of grammatical errors, the parser that builds the dependency tree starts to get very confused, and the quality of the entire system decreases sharply.
But the matter is not even this - but the fact that it is too lazy to do all this. I am deeply convinced that machine learning systems should work end-to-end - download the training data - get a working model. Even if the quality falls by a couple of percent, but labor costs will be reduced by an order of magnitude, and the way will open for a large number of new and useful applications (for example, I found an article about an interesting application of the text classifier).
')
Theory : But in short, from words to deeds. In order for a proposal to be submitted to the input of a neural network, several problems need to be solved. First, you need to convert words to numbers. The first desire that arises is to compare each word from the dictionary with its own number. Say (Apricot - 1, Apparatus - 2, .... Apple - 53845). But this cannot be done, because in this way we implicitly assume that apricot is much more like a machine than an apple. The second option is to encode words with a long vector, in which the desired word corresponds to, and to all the others - 0 (Apricot - 1 0 0 ..., Apparatus - 0 1 0 0 ..., ... Apple - ... 0 0 0 1). Here all words are equidistant and not similar to each other. This approach is much better and in some cases works well (if there are a lot of examples).
But if the set of examples is small, then it is very likely that some words (for example, “apricot”) will be absent in it, and as a result, having encountered such words in real examples, the algorithm will not know what to do with them. Therefore, it is optimal to encode words with such vectors so that words similar in meaning are close to each other - and far, respectively - far away. There are several algorithms that “read” large volumes of texts, and on the basis of this they create such vectors (the most famous, but not always the best, word2vec). Details are a topic for a separate conversation, while for understanding it is enough to know that there are such methods, they take as input long arrays of texts and give out vectors of fixed length corresponding to each word.
Having received word vectors, we are faced with task number two - how to present a complete sentence for a neural network. The fact is that normal feed-forward neural networks must have input data of a fixed length (see image). I will not explain how the classical artificial neural network of direct propagation works here - there are already enough articles on this subject, see, for example . To complete the picture I will insert only a drawing.
So, our problem is that all sentences contain different numbers of words. The easiest way out is to add all the vectors, thus obtaining the resulting vector of the sentence. Having reduced all such vectors to unit length, we obtain suitable input data. Such a presentation is often called “neural bag of words” (NBoW) - “neural bag of words” because the word order in it is lost. The advantage of this algorithm is the extreme simplicity of implementation (having a word vector at hand and any library with the implementation of neural networks or another classifier, you can make a working version in 10 - 20 min). At the same time, the results sometimes surpass other more complex algorithms, remaining, however, far from the maximum possible (this, however, depends on the task - for example, when classifying texts on product reviews / product descriptions / others, NBoW has shown 92% accuracy on test sample, versus 86% of the algorithm using logistic regression and a carefully selected manual dictionary).
However, we have already said that word ordering is important for the classification of sentences. In order to preserve the word order, a sentence vector can be formed by connecting all the vectors of the words “head to tail” into one long vector, if of course you figure out how to transfer the neural network with input data of different lengths.
A small digression — the attentive reader should be indignant — I promised the classifier of sentences without preliminary processing, but to divide the sentence into words and convert it into a vector is already a preliminary treatment. Therefore, I had to write "with minimal pretreatment." But this doesn’t sound so good, and besides, compared to conventional methods, such processing is not generally considered. Today there are methods that allow you to work directly with letters, allowing you to avoid dividing sentences into words and converting them into vectors, but this is again a separate topic.
Let us return to the problem of different lengths of input data. It has different solutions, but for now we will consider one thing - namely, the convolution filter. The idea is simple - we take one neuron and feed two (or more) words to the input (see Figure 2). Then we shift the input by one word and repeat the operation. At the output, we have a presentation of the proposal, which is two (or n) times smaller than the original one. At the same time, there are usually several such filters (from 10 to 100). Then the operation can be repeated by placing the first layer over the first one, the second one using the input values of the first one until the whole sentence is minimized, or, at a certain stage, choose the maximum activation value of the neuron (the so-called pooling layer). Due to this, the last layer of neurons gets a representation of a fixed length, and he already predicts the desired category of the sentence.
The main result - the neural network gets the opportunity to build hierarchical models, forming in each subsequent layer more abstract representations of the proposal. There are a number of modifications that differ in the details of the architecture, while some of them not only get the best known results in the classification of sentences for standard tasks, but can also be trained to translate from one language to another.
In general, such networks are similar to those that are successfully used in image recognition, which is again nice (one architecture for all tasks). The truth is completely alone does not work - the networks that process the text, still have their own characteristics.
Experiments: For experiments, we had to write the implementation of a neural network on our own. We did not want to do this, but it turned out that this is easier than using some ready-made libraries, which are also difficult to transfer to the final application. Well, it is useful in terms of self-education. Moreover, we do not need this implementation by itself (although this is useful), but as part of a large system.
In our test implementation of a simple convolutional network, there are three layers, one convolutional layer, one merging layer, and the upper fully connected layer (as in the first figure), which gives the actual classification. All this follows approximately the description of the system from the work of Kim et al, 2014 - there is also an illustration, which I will not copy here, so as not to think about copyright once again.
As a test object, we took a standard set of positive and negative sentences about films in English. Here's what happened:
| Algorithm | Classification accuracy |
| NBoW | 68% |
| Convolutional network, 8 filters | 74.3% |
| Convolution network, 16 filters | 77.8% |
In general, it turned out quite well. The best published result on this data for such networks is now 83% with 100 filters (see the article above), and the best result using manual selection of signs is 77.3%.
Source: https://habr.com/ru/post/256593/
All Articles