Approaches and tools for working with BigData - everything is just beginning, it begins
You still do not save tens of millions of events a day? Managers with a screaming question are not running to you yet - when your expensive cluster on “nadat” machines will calculate the aggregated statistics on sales for a week (and in the eyes read: “dude, the guys at php / python / ruby / go solve the problem in an hour, and do you and your Bigdata pull time in days until? ”)? You still do not throw up at night in a cold sweat from a nightmare: “the sky opened up and a huge pile fell out on you, your colleagues and the whole nafig ... Bigdats and no one knows what to do with all this now?” :-)
There is another interesting symptom - there are many, many logs in the company and someone, by the last name, remotely sounding like “Susanin”, says: “colleagues, and in the logs there is actually hidden gold , there is information about the ways of users, transactions , about groups, about search queries - but let's start extracting gold ”? And you turn into a “retriever” of good from a terabyte (and dozens of them) of the informational waterfall under motivating advice: “But is it impossible to receive valuable information for business in the stream, why drive the cluster for hours?”.
If this is not about you, then do not go under the cat, because there is trash and hard technological awe ...
In vain you went under the cat. But men - do not retreat and fight to the end. In fact, the purpose of the post: to orient the reader and form him a minimal and effective "army ration" of knowledge and skills that will be useful at the most difficult initial stage of implementation of Bigdats in the company.
')
So warm up.

Speaking of "garlic" we, the developers, there are two kinds (I see that the points below are three):
In the university, usually (not all, of course, I speak for myself) we struggle with a hormonal explosion, meet beautiful girls, sleep on couples, code at night what we want, learn before the session and finally remember the list of books where we need if something looks . And in the university, we can meet teachers or colleagues who, with their energy, attitude, competence and attitude, can become our reference points for life and warm us and motivate us in various circumstances (well, again brought myself to tears) .
If, after university, it is systematic to spend a couple of hours a day on theory in the subway (bus, shuttle bus) and 8 hours on the practice of “designing and creating software” and read the minimal books necessary for general literacy, then exhale with a sense of accomplishment in years 40, and if you also sleep at night - then 50 years old. This is what I mean:
Colleagues, this is just about “designing software and writing good code.”
And math for a developer is a separate world. The fact is that in order to thoroughly understand the algorithms considered below and adjust them to the needs of the company, it is necessary, as a matter of fact, to understand well the following areas of mathematics:
And if you are lucky to face data clustering (group similar Buyers, Products, etc.), then:
Well, yes, of course you can and do not understand and copy-paste. But if you have to adapt and mix the algorithms to your needs - fundamental knowledge is certainly needed, and here it’s probably best to work as a joint team, whose members have enough knowledge to understand where to go.
And you ask, does a project need a mathematician who lives in mathematics, sleeps with mathematics and remembers the proof of the Pythagorean theorem in 20 ways and with the “Bin Newton” poster above the bed - for understanding and organizing the process of working with Bigdata? Does he know how to write good code - quickly, in release? And he will not hang in front of the monitor for 15 minutes with a grimace of terrible suffering, contemplating a quickly made object-disoriented alogical, but sexy hack? We know the answer to this question - for it is impossible (except for geniuses and Jedi) to succeed equally well in serving the light and dark sides.

Apparently, therefore, clever by nature uncles and aunties diligently study Computer Science and write only clear, written formulas for the article, and hard-working by nature developers just have time to kiss before going to bed not open, but standing in the most prominent place at home multi-volume Knut :-)
Well, of course there are exceptions! And they say that people sometimes self-ignite and he remains a bunch of ashes.
So, colleagues, let us list what you will have to face in the first battles with Bigdata.
The algorithms of this area initially seem very very simple and well "go under the vodka with cucumbers."
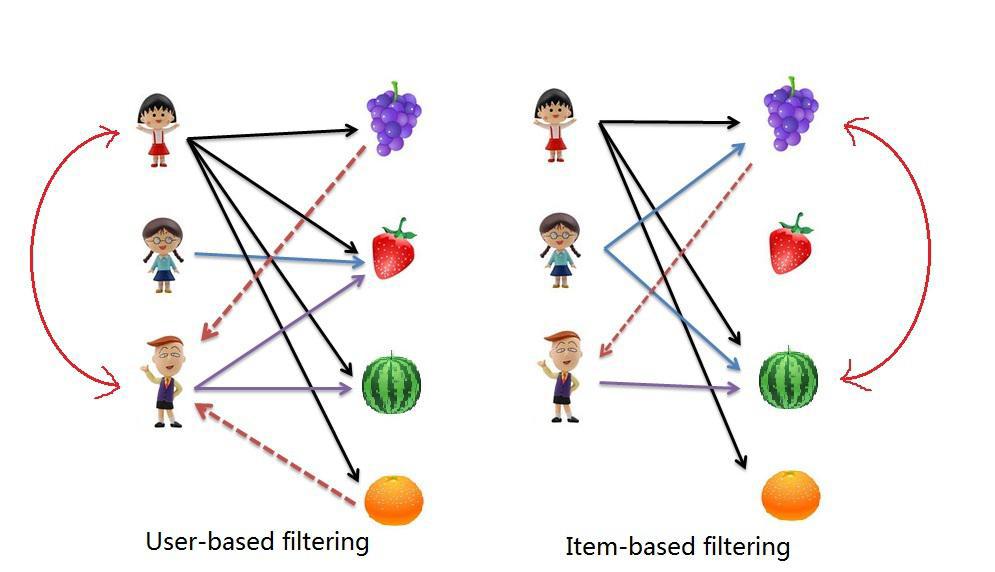
Well, what's difficult? No mathematics, only physics and chemistry. Matrix Users * Products and look for similar lines, using the vector similarity formulas studied in the older group of the kindergarten:
But in fact, everything is much worse. If you have millions of Users and Products (like ours), non-fiction books on building recommender systems, as well as 99% of the information and scientific articles available on the web, you can safely throw it out. No-dit :-)
Here a hidden monster called “ curse of dimension ” crawls out, serious questions about scalability, speed of algorithms start (everyone knows that Amazon invented the Item2Item algorithm not from a good life, but because the User2Item algorithm just started to slow) and etc.
And having added the insistent request of the marketing department to change the collaborative filtering online ... you understand that it is getting hot.
The principle of construction is also painfully simple. We create profiles of objects, whether they are Users, Groups, or Products, and then look for similar objects by using the well-known cosine of the angle between the vectors .
Do you smell it? That smelled the world of search engines ...
Recently, even Mahout himself began to talk about the great role of search engines in building recommender systems.
And here, knowledge of IR algorithms is already required of you - well, if the project is not very very simple. At least to distinguish between "precision" from "recall" and "F1" - you need to be able to.
And of course, all this can be burned when there is a lot of data, because a lot of things stop working and you have to do the implementation of IR algorithms yourself with an understanding of their essence, for example, in NoSQL and / or memory.
But be careful! You yourself team can declare a heretic and burn for dissent right in the kitchen :-)
We'll talk about the tools later. And as algorithms we are now offered not very many options:
With the second more interesting. If you have not yet understood the principle of MapReduce, this must be done, it is simple as “cowards for 1 rub 20 kopecks” and powerful.
There is, for example, even a chapter in the famous Stanford course on processing large data on how to translate any relational algebra operation into MapReduce (and drive according to SQL data !!!).
But here's the catch. The well-known simple algorithms you need from popular books need to be translated into a distributed form in order to use MapReduce - and how to do this is not reported :-) Distributed algorithms, it turns out, are much smaller and they are often ... different.
You may still encounter streaming algorithms for processing big data, but this is a separate topic of another post.
You have several million documents or users and need to find groups. Or glue similar. In the forehead, the task is not solved, it is too long and expensive to compare each with each one or drive iterations of k-means.
Therefore, they invented tricks with:
If you have a lot of data, neither k-means, nor c-means, nor, even more so, classical hierarchical clustering will help you. It is necessary to “hack” technology and mathematics, look for solutions in scientific articles and experiment.
The topic is interesting, extensive, useful - but sometimes it requires serious knowledge of the above sections of mathematics.
On the one hand, on the business side, it’s pretty understandable here - you are learning the model on the previously prepared data to guess the new data. For example, we have 10,000 letters and we know for everyone whether it is spam or not. And then we submit a new letter to the model and, lo and behold, the model tells us whether it is spam or not.
By "guessing power" models are divided into:
But there are a lot of algorithms, here is a useful resource .
And of course, this is only a small part of the algorithms that you may have to deal with.
So we got to the tools. What is ready, what will help us in the fight against Bigdata?
Many start with the good old Hadoop MapReduce . In principle, Hadoop itself is a hodgepodge of various subprojects that are so intertwined with each other that their own mother will not separate them.

Of the most sought after:
Spark is a bit off. This framework looks, to put it mildly, more modern, and allows you to process data, placing it in memory as much as possible, as well as build a chain of requests - which, of course, is convenient. We ourselves actively use it.
Although the impressions of Spark are very contradictory. It is covered with lubricating oil and sticking out under-voltage wires - apparently it will be polished for a long time, so that you can control the use of Spark RAM in reasonable ways, without causing Voodoo spirits for this.
And if you're in the Amazon cloud, then HDFS, you probably do not need and you can directly use the cloud object storage s3 .
Unfortunately, deploying Spark in Amazon is not easy. Yes, there is a well-known script , but - not worth it. Not only does it load half of the code at the University of Berkeley in California to your server, then even if it is inaccurately started (you want to add a new machine to the cluster or upgrade), your Spark cluster will be mercilessly disfigured and broken and you will not spend the next night in your arms friends, and making love with bash / ruby / copy-paste configurations in 100-500 places :-)
And in order to preserve a positive sediment, look how coolly very recently Amazon began selling a new cloud-based machine learning service based on the good and old “industry-standard logistic regression algorithm” (and no “forests” and alien dancing).
That's probably all that I wanted to tell in the introductory post about the algorithms and technologies for processing big data, with which the developer will most likely have to fight in the next 3-6 months. I hope the information and advice will be useful and save you, dear colleagues, health and manna.
And finally, well, to understand how this can be arranged from the inside, a bird's eye view of our new cloud service:
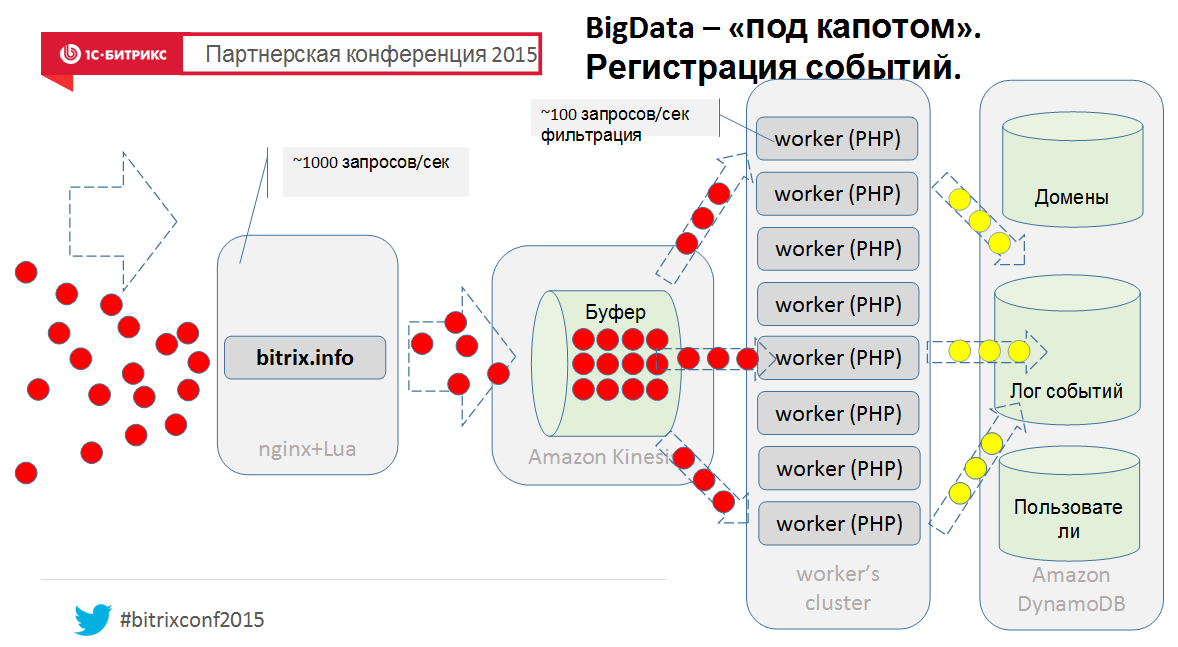
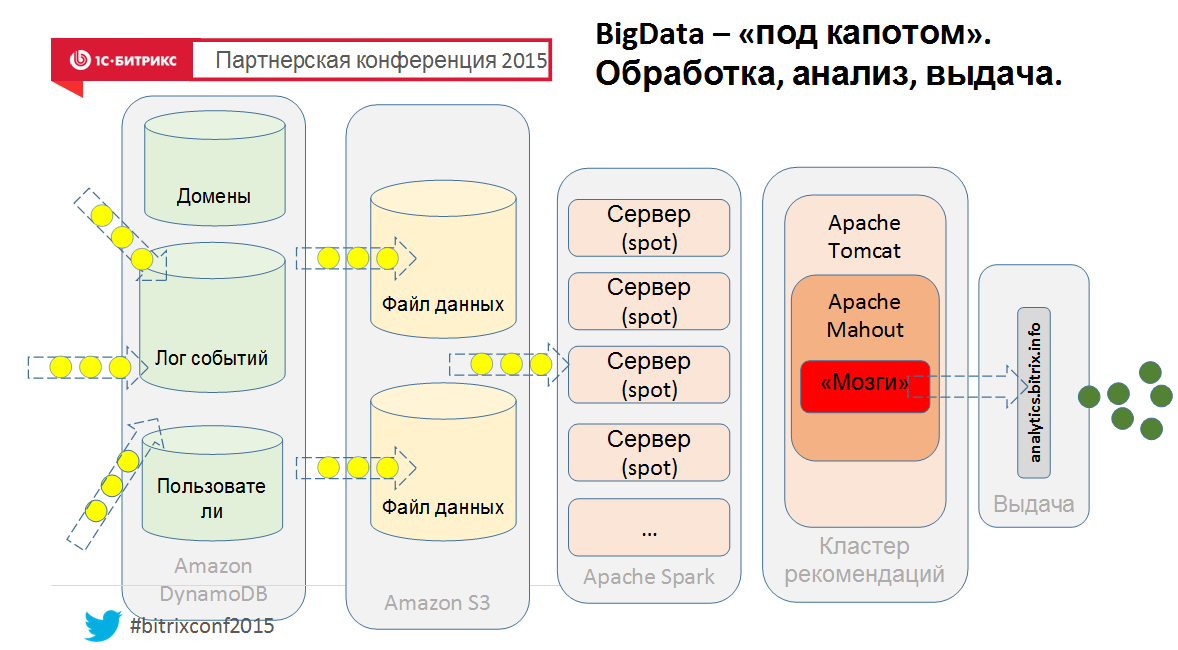
Well, this is so simplistic, if that :-) Therefore - ask in the comments.
There is another interesting symptom - there are many, many logs in the company and someone, by the last name, remotely sounding like “Susanin”, says: “colleagues, and in the logs there is actually hidden gold , there is information about the ways of users, transactions , about groups, about search queries - but let's start extracting gold ”? And you turn into a “retriever” of good from a terabyte (and dozens of them) of the informational waterfall under motivating advice: “But is it impossible to receive valuable information for business in the stream, why drive the cluster for hours?”.
If this is not about you, then do not go under the cat, because there is trash and hard technological awe ...
In vain you went under the cat. But men - do not retreat and fight to the end. In fact, the purpose of the post: to orient the reader and form him a minimal and effective "army ration" of knowledge and skills that will be useful at the most difficult initial stage of implementation of Bigdats in the company.
')
So warm up.
What the developer knows and does not yet know
Speaking of "garlic" we, the developers, there are two kinds (I see that the points below are three):
- with math education
- with technical education
- humanists
In the university, usually (not all, of course, I speak for myself) we struggle with a hormonal explosion, meet beautiful girls, sleep on couples, code at night what we want, learn before the session and finally remember the list of books where we need if something looks . And in the university, we can meet teachers or colleagues who, with their energy, attitude, competence and attitude, can become our reference points for life and warm us and motivate us in various circumstances (well, again brought myself to tears) .
If, after university, it is systematic to spend a couple of hours a day on theory in the subway (bus, shuttle bus) and 8 hours on the practice of “designing and creating software” and read the minimal books necessary for general literacy, then exhale with a sense of accomplishment in years 40, and if you also sleep at night - then 50 years old. This is what I mean:
- adult programming languages at the specification level (C ++, java, C #)
- a couple of popular languages like php, python, go
- understand and ... forgive all normal and "abnormal" forms of SQL
- books on design patterns (GoF, Fauler , etc)
- books in the style of "Effective ..."
- understand how unix works - from the inside
- understand network protocols at the RFC level (not all TCP and IP are different)
- how does the computer work! going down to the OS and its system calls, going through multiprocessor systems with their caches and mutexes and spin locks and to the level of chips
- fail 10 software projects on the PLO
- delete the code and the only copy of the data backup on Friday evening (they say 3 times you need to do this in order to accumulate a callus in the brain)
Colleagues, this is just about “designing software and writing good code.”
And math for a developer is a separate world. The fact is that in order to thoroughly understand the algorithms considered below and adjust them to the needs of the company, it is necessary, as a matter of fact, to understand well the following areas of mathematics:
- probability theory with subtankers in the form of Markov models (otherwise PageRank will not understand how it works, you will not understand Bayesian filtering, you will not understand LSH clustering)
- combinatorics, without which it is difficult to understand the theory of probability
- set theory (to understand probability theory, and at least to understand Jaccard-distance in a collaborative, but it is common everywhere)
- linear algebra (collaborative filtering, compression of dimensions, co-occurence matrices, eigenvectors / values are not vectors invented by Eugene !!)
- mathematical statistics (I don’t even know where it is in Bigdat)
- machine learning (here mathematical thrash and hell, starting with primitive perceptrons, continuing “stochastic gradient descent” and not ending with neural networks)
And if you are lucky to face data clustering (group similar Buyers, Products, etc.), then:
- for understanding old and good k-means in Euclidean spaces, nothing is needed, except that it does not work without scrap and brute force on “big data” :-)
- understanding c-means in non-Euclidean spaces may require an extra cup of coffee (although it also does not work with big data)
- but to understand spectral clustering that is now popular (here I consciously simplified and even slightly distorted “power iteration clustering”), in which we move data from one space to another (i.e., we need to cluster the horns, and you cluster the hooves and even nothing), you will most likely jump out of the window with the useless volume “Algorithms in C ++” of Sedgwick :-)
Well, yes, of course you can and do not understand and copy-paste. But if you have to adapt and mix the algorithms to your needs - fundamental knowledge is certainly needed, and here it’s probably best to work as a joint team, whose members have enough knowledge to understand where to go.
Need an analyst?
And you ask, does a project need a mathematician who lives in mathematics, sleeps with mathematics and remembers the proof of the Pythagorean theorem in 20 ways and with the “Bin Newton” poster above the bed - for understanding and organizing the process of working with Bigdata? Does he know how to write good code - quickly, in release? And he will not hang in front of the monitor for 15 minutes with a grimace of terrible suffering, contemplating a quickly made object-disoriented alogical, but sexy hack? We know the answer to this question - for it is impossible (except for geniuses and Jedi) to succeed equally well in serving the light and dark sides.
Apparently, therefore, clever by nature uncles and aunties diligently study Computer Science and write only clear, written formulas for the article, and hard-working by nature developers just have time to kiss before going to bed not open, but standing in the most prominent place at home multi-volume Knut :-)
Well, of course there are exceptions! And they say that people sometimes self-ignite and he remains a bunch of ashes.
Algorithms
So, colleagues, let us list what you will have to face in the first battles with Bigdata.
Collaborative filtering
The algorithms of this area initially seem very very simple and well "go under the vodka with cucumbers."
Well, what's difficult? No mathematics, only physics and chemistry. Matrix Users * Products and look for similar lines, using the vector similarity formulas studied in the older group of the kindergarten:
- Euclidean distance
- Distance of city blocks
- Cosine of the angle between vectors
- Piroson's correlation coefficient
- Jaccard distance (on sets)
But in fact, everything is much worse. If you have millions of Users and Products (like ours), non-fiction books on building recommender systems, as well as 99% of the information and scientific articles available on the web, you can safely throw it out. No-dit :-)
Here a hidden monster called “ curse of dimension ” crawls out, serious questions about scalability, speed of algorithms start (everyone knows that Amazon invented the Item2Item algorithm not from a good life, but because the User2Item algorithm just started to slow) and etc.
And having added the insistent request of the marketing department to change the collaborative filtering online ... you understand that it is getting hot.
Content-based recommendation systems
The principle of construction is also painfully simple. We create profiles of objects, whether they are Users, Groups, or Products, and then look for similar objects by using the well-known cosine of the angle between the vectors .
Do you smell it? That smelled the world of search engines ...
Recently, even Mahout himself began to talk about the great role of search engines in building recommender systems.
And here, knowledge of IR algorithms is already required of you - well, if the project is not very very simple. At least to distinguish between "precision" from "recall" and "F1" - you need to be able to.
And of course, all this can be burned when there is a lot of data, because a lot of things stop working and you have to do the implementation of IR algorithms yourself with an understanding of their essence, for example, in NoSQL and / or memory.
But be careful! You yourself team can declare a heretic and burn for dissent right in the kitchen :-)
Processing, filtering, aggregation
We'll talk about the tools later. And as algorithms we are now offered not very many options:
With the second more interesting. If you have not yet understood the principle of MapReduce, this must be done, it is simple as “cowards for 1 rub 20 kopecks” and powerful.
There is, for example, even a chapter in the famous Stanford course on processing large data on how to translate any relational algebra operation into MapReduce (and drive according to SQL data !!!).
But here's the catch. The well-known simple algorithms you need from popular books need to be translated into a distributed form in order to use MapReduce - and how to do this is not reported :-) Distributed algorithms, it turns out, are much smaller and they are often ... different.
You may still encounter streaming algorithms for processing big data, but this is a separate topic of another post.
Clustering
You have several million documents or users and need to find groups. Or glue similar. In the forehead, the task is not solved, it is too long and expensive to compare each with each one or drive iterations of k-means.
Therefore, they invented tricks with:
- minhash
- simhash
- LSH
If you have a lot of data, neither k-means, nor c-means, nor, even more so, classical hierarchical clustering will help you. It is necessary to “hack” technology and mathematics, look for solutions in scientific articles and experiment.
The topic is interesting, extensive, useful - but sometimes it requires serious knowledge of the above sections of mathematics.
Machine learning
On the one hand, on the business side, it’s pretty understandable here - you are learning the model on the previously prepared data to guess the new data. For example, we have 10,000 letters and we know for everyone whether it is spam or not. And then we submit a new letter to the model and, lo and behold, the model tells us whether it is spam or not.
By "guessing power" models are divided into:
- binary classifiers , for example, guessing "spam / not spam"
- multiclass classifiers , for example related documents to several groups
- using regression , for example, guessing age or air temperature
But there are a lot of algorithms, here is a useful resource .
And of course, this is only a small part of the algorithms that you may have to deal with.
Instruments
So we got to the tools. What is ready, what will help us in the fight against Bigdata?
Many start with the good old Hadoop MapReduce . In principle, Hadoop itself is a hodgepodge of various subprojects that are so intertwined with each other that their own mother will not separate them.
Of the most sought after:
- HDFS - a cluster file system to store your Bigdata
- MapReduce - to take samples from this data.
- Hive - not to mess with low-level MapReduce-technicians, but use good old SQL
- Mahout - not to learn math, but to take it ready and see that it does not work with big data :-)
- YARN - to manage all this "chicken coop"
Spark is a bit off. This framework looks, to put it mildly, more modern, and allows you to process data, placing it in memory as much as possible, as well as build a chain of requests - which, of course, is convenient. We ourselves actively use it.
Although the impressions of Spark are very contradictory. It is covered with lubricating oil and sticking out under-voltage wires - apparently it will be polished for a long time, so that you can control the use of Spark RAM in reasonable ways, without causing Voodoo spirits for this.
And if you're in the Amazon cloud, then HDFS, you probably do not need and you can directly use the cloud object storage s3 .
Unfortunately, deploying Spark in Amazon is not easy. Yes, there is a well-known script , but - not worth it. Not only does it load half of the code at the University of Berkeley in California to your server, then even if it is inaccurately started (you want to add a new machine to the cluster or upgrade), your Spark cluster will be mercilessly disfigured and broken and you will not spend the next night in your arms friends, and making love with bash / ruby / copy-paste configurations in 100-500 places :-)
And in order to preserve a positive sediment, look how coolly very recently Amazon began selling a new cloud-based machine learning service based on the good and old “industry-standard logistic regression algorithm” (and no “forests” and alien dancing).
Good luck!
That's probably all that I wanted to tell in the introductory post about the algorithms and technologies for processing big data, with which the developer will most likely have to fight in the next 3-6 months. I hope the information and advice will be useful and save you, dear colleagues, health and manna.
And finally, well, to understand how this can be arranged from the inside, a bird's eye view of our new cloud service:
Well, this is so simplistic, if that :-) Therefore - ask in the comments.
Source: https://habr.com/ru/post/256551/
All Articles