Virtual memory organization
 Hi, Habrahabr!
Hi, Habrahabr!In the previous article, I talked about vfork () and promised to talk about the implementation of the fork () call both with and without MMU support (the latter, of course, with significant restrictions). But before going into the details, it would be more logical to start with a virtual memory device.
Of course, many have heard about the MMU, page tables and TLB. Unfortunately, materials on this topic usually consider the hardware side of this mechanism, mentioning the mechanisms of the OS only in general terms. I want to make out the specific software implementation in the Embox project. This is just one of the possible approaches, and it is easy enough to understand. In addition, it is not a museum piece, and if you wish, you can get under the hood of the OS and try to change something.
Introduction
Any software system has a logical memory model. The simplest of them is the same as physical, when all programs have direct access to the entire address space.
With this approach, programs have access to the entire address space, not only can "interfere" with each other, but can also lead to the failure of the entire system - for this it is enough, for example, to wipe a piece of memory in which the OS code is located. In addition, sometimes physical memory may simply not be enough for all the necessary processes to work simultaneously. Virtual memory is one of the mechanisms for solving these problems. This article discusses how to work with this mechanism from the operating system on the example of the Embox OS . All functions and data types mentioned in the article can be found in the source code of our project.
')
A number of listings will be given, and some of them are too cumbersome to be placed in the article in its original form, therefore, if possible, they will be shortened and adapted. Also in the text there will be references to functions and structures that are not directly related to the subject of the article. A brief description will be given for them, and more complete information on implementation can be found on the project wiki.
General ideas
Virtual memory is a concept that avoids the use of physical addresses using virtual ones instead, and this gives a number of advantages:
- Expansion of real address space. A part of virtual memory can be preempted onto a hard disk, and this allows programs to use more RAM than they actually are.
- Creating isolated address spaces for various processes, which increases the security of the system, and also solves the problem of attachment of the program to certain memory addresses.
- Setting different properties for different parts of memory plots. For example, there may be an immutable chunk of memory visible to several processes.
In this case, the entire virtual memory is divided into chunks of constant size, called pages.
Hardware support
The MMU is a hardware component of a computer through which all requests to the memory made by the processor “pass”. The task of this device is address translation, memory caching management and its protection.
The appeal to memory is well described in this habrostate . It occurs as follows:
The processor provides a virtual address for MMU input.
If the MMU is turned off, or if the virtual address is in an untranslated region, then the physical address is simply equated to virtual
If the MMU is enabled and the virtual address is in the broadcast area, the address is translated, that is, the virtual page number is replaced with the physical page number corresponding to it (the same offset within the page):
If the entry with the desired virtual page number is in the TLB [Translation Lookaside Buffer], then the physical page number is taken from it.
If there is no necessary record in the TLB, then it is necessary to look for it in the page tables that the operating system places in the non-translated RAM area (so that there is no TLB miss when processing the previous slip). The search can be implemented both in hardware and in software - through an exception handler, called a page fault. The found entry is added to the TLB, after which the command that caused the TLB miss is executed again.
Thus, when a program accesses a particular section of memory, address translation is performed in hardware. The software part of working with the MMU is the formation of page tables and work with them, the allocation of memory areas, the installation of certain flags for the pages, as well as the processing of the page fault, an error that occurs when there is no page in the display.
The article will mainly consider a three-level memory model, but this is not a fundamental limitation: to obtain a model with more levels, you can act in a similar way, and the features of working with fewer levels (for example, in the x86 architecture there are only two levels ) will be reviewed separately.
Software support
For applications, working with virtual memory is invisible. This transparency is provided by the presence in the kernel of the OS of the corresponding subsystem that performs the following actions:
- Allocating physical pages from some reserved area of memory
- Making appropriate changes to the virtual memory table
- Comparison of virtual memory plots with the processes that allocated them
- Projecting a physical memory region to a virtual address
These mechanisms will be discussed in detail below, after introducing several basic definitions.
Virtual address
Page Global Directory (hereinafter - PGD ) - a table (hereinafter - the same as the directory) of the highest level, each entry in it - a link to the Page Middle Directory ( PMD ), whose records, in turn, refer to the table Page Table Entry ( PTE ). Entries in PTE refer to real physical addresses, and also store page status flags.
That is, with a three-level memory hierarchy, the virtual address will look like this:

The values of the PGD , PMD and PTE fields are the indices in the respective tables (i.e., the shifts from the beginning of these tables), and the offset is the offset of the address from the beginning of the page.
Depending on the architecture and paging mode, the number of bits allocated to each of the fields may vary. In addition, the page hierarchy itself may have a number of levels other than three: for example, there is no PMD on x86.
To ensure portability, we defined the boundaries of these fields using the constants: MMU_PGD_SHIFT , MMU_PMD_SHIFT , MMU_PTE_SHIFT , which in the above diagram are equal to 24, 18 and 12, respectively, their definition is given in the header file src / include / hal / mmu.h. In the following, this particular example will be considered.
Based on the PGD , PMD, and PTE shifts, the corresponding address masks are calculated.
#define MMU_PTE_ENTRIES (1UL << (MMU_PMD_SHIFT - MMU_PTE_SHIFT)) #define MMU_PTE_MASK ((MMU_PTE_ENTRIES - 1) << MMU_PTE_SHIFT) #define MMU_PTE_SIZE (1UL << MMU_PTE_SHIFT) #define MMU_PAGE_SIZE (1UL << MMU_PTE_SHIFT) #define MMU_PAGE_MASK (MMU_PAGE_SIZE - 1) These macros are given in the same header file.
To work with virtual tables of virtual memory, pointers to all PGDs are stored in a certain area of memory. In addition , each task stores the context of mm mm_context , which, in fact, is an index in this table. Thus, for each task there is one PGD table, which can be defined using mmu_get_root (ctx) .
Pages and work with them
Page size
In real (that is, not in training) systems, pages from 512 bytes to 64 kilobytes are used. Most often, the page size is determined by the architecture and is fixed for the entire system, for example - 4 KiB.
On the one hand, with a smaller page size, memory is less fragmented. After all, the smallest unit of virtual memory that can be allocated to a process is one page, and programs rarely need an integer number of pages. So, in the last page that the process requested, most likely there will be unused memory, which, however, will be allocated, which means it is used inefficiently.
On the other hand, the smaller the page size, the larger the size of the page tables. Moreover, when shipping to the HDD and reading pages from the HDD, it will be faster to write several large pages than many small ones of the same total size.
Special attention is given to the so-called big pages: huge pages and large pages [wikis] .
| Platform | Normal page size | Page size as large as possible |
| x86 | 4KB | 4MB |
| x86_64 | 4KB | 1GB |
| IA-64 | 4KB | 256MB |
| PPC | 4KB | 16GB |
| SPARC | 8KB | 2GB |
| ARMv7 | 4KB | 16MB |
Indeed, the use of such pages increases the memory overhead. However, the performance gains of programs in some cases can go up to 10% [ link ] , which is explained by the smaller size of the page directories and the more efficient operation of the TLB.
In the future, we will focus on pages of normal size.
Page Table Entry Device
In an Embox project, the mmu_pte_t type is a pointer.
Each PTE entry must refer to some physical page, and each physical page must be addressed to some PTE entry. Thus, in mmu_pte_t , MMU_PTE_SHIFT bits remain unoccupied, which can be used to maintain the state of the page. The specific address of the bit responsible for a particular flag, as well as the set of flags in general, depends on the architecture.
Here are some of the flags:
- MMU_PAGE_WRITABLE - Is it possible to change the page
- MMU_PAGE_SUPERVISOR - Super User / User Space
- MMU_PAGE_CACHEABLE - Should I Cach
- MMU_PAGE_PRESENT - Is this directory entry in use?
You can remove and set these flags using the following functions:
mmu_pte_set_writable (), mmu_pte_set_usermode (), mmu_pte_set_cacheable (), mmu_pte_set_executable ()
For example: mmu_pte_set_writable (pte_pointer, 0)
You can set several flags at once:
void vmem_set_pte_flags(mmu_pte_t *pte, vmem_page_flags_t flags) Here, vmem_page_flags_t is a 32-bit value, and the corresponding flags are taken from the first MMU_PTE_SHIFT bits.
Translation of virtual address to physical
As mentioned above, when addressing memory, address translation is done in hardware, however, explicit access to physical addresses may be useful in some cases. The principle of finding the right room is, of course, the same as in the MMU.
In order to get a physical address from a virtual address, you need to go through the chain of tables PGD, PMD and PTE . The vmem_translate () function performs these steps.
First it is checked whether the pointer to the PMD directory is in the PGD . If so, the PMD address is calculated, and then the PTE is found in the same way. After allocating the physical address of the page from the PTE, you need to add an offset, and after that the desired physical address will be obtained.
Source code of the vmem_translate function
mmu_paddr_t vmem_translate(mmu_ctx_t ctx, mmu_vaddr_t virt_addr) { size_t pgd_idx, pmd_idx, pte_idx; mmu_pgd_t *pgd; mmu_pmd_t *pmd; mmu_pte_t *pte; pgd = mmu_get_root(ctx); vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx); if (!mmu_pgd_present(pgd + pgd_idx)) { return 0; } pmd = mmu_pgd_value(pgd + pgd_idx); if (!mmu_pmd_present(pmd + pmd_idx)) { return 0; } pte = mmu_pmd_value(pmd + pmd_idx); if (!mmu_pte_present(pte + pte_idx)) { return 0; } return mmu_pte_value(pte + pte_idx) + (virt_addr & MMU_PAGE_MASK); } Explanation of the function code.
mmu_paddr_t is the physical address of the page, the purpose of mmu_ctx_t has already been discussed above in the “Virtual Address” section.
Using the vmem_get_idx_from_vaddr () function, the shifts are in the PGD, PMD, and PTE tables.
void vmem_get_idx_from_vaddr(mmu_vaddr_t virt_addr, size_t *pgd_idx, size_t *pmd_idx, size_t *pte_idx) { *pgd_idx = ((uint32_t) virt_addr & MMU_PGD_MASK) >> MMU_PGD_SHIFT; *pmd_idx = ((uint32_t) virt_addr & MMU_PMD_MASK) >> MMU_PMD_SHIFT; *pte_idx = ((uint32_t) virt_addr & MMU_PTE_MASK) >> MMU_PTE_SHIFT; } 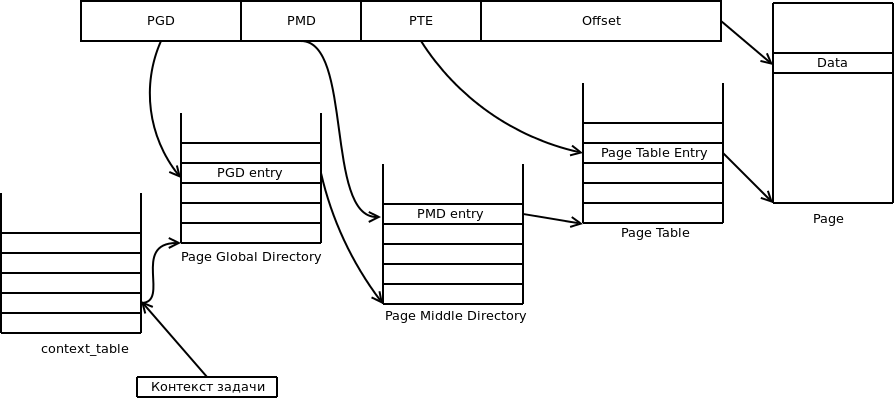
Working with Page Table Entry
There are a number of functions for working with entries in the page table, as well as with the tables themselves:
These functions return 1 if the corresponding structure has the MMU_PAGE_PRESENT bit set.
int mmu_pgd_present(mmu_pgd_t *pgd); int mmu_pmd_present(mmu_pmd_t *pmd); int mmu_pte_present(mmu_pte_t *pte); Page Fault
Page fault is an exception that occurs when accessing a page that is not loaded into physical memory — either because it was preempted, or because it was not allocated.
In general-purpose operating systems, when processing this exception, the required page is searched on the external storage medium (hard disk, for example).
In our system, all pages to which the process has access are considered to be present in memory. For example, the corresponding segments .text, .data, .bss; a bunch; and so on are displayed in tables when the process is initialized. Data associated with threads (for example, a stack) is displayed in the process tables when creating threads.
Pushing pages into external memory and reading them in the case of a page fault is not implemented. On the one hand, this makes it impossible to use more physical memory than it actually is, but on the other hand, it is not an actual problem for embedded systems. There are no restrictions that make the implementation of this mechanism impossible, and if desired, the reader can try himself in this matter :)
Memory allocation
For virtual pages and for physical pages that can be used when working with virtual memory, some place in RAM is statically reserved. Then, when allocating new pages and directories, they will be taken from this particular place.
The exception is a set of pointers to PGD for each process (MMU process contexts): this array is stored separately and used when creating and destroying the process.
Highlighting pages
So, you can select a physical page using vmem_alloc_page
void *vmem_alloc_page() { return page_alloc(virt_page_allocator, 1); } The page_alloc () function searches for a section of memory from the N unallocated pages and returns the physical address of the beginning of this section, marking it as occupied. In the above code, virt_page_allocator refers to a section of memory reserved for allocating physical pages, and 1 indicates the number of pages needed.
Selection tables
The type of the table ( PGD, PMD, PTE ) does not matter during allocation. Moreover, the selection of tables is also performed using the page_alloc () function, only with a different allocator ( virt_table_allocator ).
Memory areas
After adding pages to the appropriate tables, you need to be able to match the memory sections with the processes to which they relate. In our system, the process is represented by a task structure containing all the necessary information for the OS to work with the process. All physically accessible areas of the process address space are recorded in a special repository: task_mmap. It is a list of descriptors of these areas (regions) that can be mapped to virtual memory, if appropriate support is included.
struct emmap { void *brk; mmu_ctx_t ctx; struct dlist_head marea_list; }; brk is the largest of all the physical addresses of the repository, this value is necessary for a number of system calls that will not be considered in this article.
ctx is the task context, the use of which was discussed in the “Virtual Address” section.
The struct dlist_head is a pointer to the beginning of a doubly linked list whose organization is similar to the Linux Linked List .
For each allocated area of memory marea structure is responsible.
struct marea { uintptr_t start; uintptr_t end; uint32_t flags; uint32_t is_allocated; struct dlist_head mmap_link; }; The fields of this structure have speaking names: addresses of the beginning and end of this section of memory, flags of the region of memory. The mmap_link field is needed to maintain the doubly linked list mentioned above.
void mmap_add_marea(struct emmap *mmap, struct marea *marea) { struct marea *ma_err; if ((ma_err = mmap_find_marea(mmap, marea->start)) || (ma_err = mmap_find_marea(mmap, marea->end))) { /* */ } dlist_add_prev(&marea->mmap_link, &mmap->marea_list); } Mapping of virtual memory areas to physical ones (Mapping)
Earlier it was described how the allocation of physical pages, what data about virtual memory relates to the task, and now everything is ready to talk about the direct mapping of virtual memory sections to physical ones.
Mapping virtual memory plots to physical memory implies making appropriate changes to the hierarchy of page directories.
It is understood that some part of the physical memory is already allocated. In order to highlight the corresponding virtual pages and link them to the physical, use the function vmem_map_region ()
int vmem_map_region(mmu_ctx_t ctx, mmu_paddr_t phy_addr, mmu_vaddr_t virt_addr, size_t reg_size, vmem_page_flags_t flags) { int res = do_map_region(ctx, phy_addr, virt_addr, reg_size, flags); if (res) { vmem_unmap_region(ctx, virt_addr, reg_size, 0); } return res; } As parameters, the task context, the start address of the physical memory location, and the start address of the virtual location are transmitted. The flags variable contains flags that will be set for the corresponding entries in PTE .
The main work is done by do_map_region () . It returns 0 on success and an error code otherwise. If an error occurred during mapping, then some of the pages that managed to stand out need to be rolled back through the changes using the vmem_unmap_region () function, which will be discussed later.
Consider the function do_map_region () in more detail.
The source code of the do_map_region () function
static int do_map_region(mmu_ctx_t ctx, mmu_paddr_t phy_addr, mmu_vaddr_t virt_addr, size_t reg_size, vmem_page_flags_t flags) { mmu_pgd_t *pgd; mmu_pmd_t *pmd; mmu_pte_t *pte; mmu_paddr_t p_end = phy_addr + reg_size; size_t pgd_idx, pmd_idx, pte_idx; /* Considering that all boundaries are already aligned */ assert(!(virt_addr & MMU_PAGE_MASK)); assert(!(phy_addr & MMU_PAGE_MASK)); assert(!(reg_size & MMU_PAGE_MASK)); pgd = mmu_get_root(ctx); vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx); for ( ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) { GET_PMD(pmd, pgd + pgd_idx); for ( ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) { GET_PTE(pte, pmd + pmd_idx); for ( ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) { /* Considering that address has not mapped yet */ assert(!mmu_pte_present(pte + pte_idx)); mmu_pte_set(pte + pte_idx, phy_addr); vmem_set_pte_flags(pte + pte_idx, flags); phy_addr += MMU_PAGE_SIZE; if (phy_addr >= p_end) { return ENOERR; } } pte_idx = 0; } pmd_idx = 0; } return -EINVAL; } Auxiliary Macros
#define GET_PMD(pmd, pgd) \ if (!mmu_pgd_present(pgd)) { \ pmd = vmem_alloc_pmd_table(); \ if (pmd == NULL) { \ return -ENOMEM; \ } \ mmu_pgd_set(pgd, pmd); \ } else { \ pmd = mmu_pgd_value(pgd); \ } #define GET_PTE(pte, pmd) \ if (!mmu_pmd_present(pmd)) { \ pte = vmem_alloc_pte_table(); \ if (pte == NULL) { \ return -ENOMEM; \ } \ mmu_pmd_set(pmd, pte); \ } else { \ pte = mmu_pmd_value(pmd); \ } Macros GET_PTE and GET_PMD are needed for better readability of the code. They do the following: if in the memory table the pointer we need does not refer to the existing record, we need to select it, if not, then simply follow the pointer to the next record.
At the very beginning, you need to check whether the size of the region, physical and virtual addresses are aligned to the page size. After that, the PGD corresponding to the specified context is determined and shifts from the virtual address are extracted (this has already been discussed in more detail above).
Then the virtual addresses are sequentially sorted, and the corresponding physical address is attached to them in the corresponding PTE records. If there are no records in the tables, they will be automatically generated when calling the above-mentioned macros GET_PTE and GET_PMD .
Unmapping
After a section of virtual memory has been mapped to physical memory, sooner or later it will have to be released: either in case of an error or in the case of a process shutdown.
Changes that must be made to the structure of the memory page hierarchy are made using the vmem_unmap_region () function.
Source code of the vmem_unmap_region () function
void vmem_unmap_region(mmu_ctx_t ctx, mmu_vaddr_t virt_addr, size_t reg_size, int free_pages) { mmu_pgd_t *pgd; mmu_pmd_t *pmd; mmu_pte_t *pte; mmu_paddr_t v_end = virt_addr + reg_size; size_t pgd_idx, pmd_idx, pte_idx; void *addr; /* Considering that all boundaries are already aligned */ assert(!(virt_addr & MMU_PAGE_MASK)); assert(!(reg_size & MMU_PAGE_MASK)); pgd = mmu_get_root(ctx); vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx); for ( ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) { if (!mmu_pgd_present(pgd + pgd_idx)) { virt_addr = binalign_bound(virt_addr, MMU_PGD_SIZE); pte_idx = pmd_idx = 0; continue; } pmd = mmu_pgd_value(pgd + pgd_idx); for ( ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) { if (!mmu_pmd_present(pmd + pmd_idx)) { virt_addr = binalign_bound(virt_addr, MMU_PMD_SIZE); pte_idx = 0; continue; } pte = mmu_pmd_value(pmd + pmd_idx); for ( ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) { if (virt_addr >= v_end) { // Try to free pte, pmd, pgd if (try_free_pte(pte, pmd + pmd_idx) && try_free_pmd(pmd, pgd + pgd_idx)) { try_free_pgd(pgd, ctx); } return; } if (mmu_pte_present(pte + pte_idx)) { if (free_pages && mmu_pte_present(pte + pte_idx)) { addr = (void *) mmu_pte_value(pte + pte_idx); vmem_free_page(addr); } mmu_pte_unset(pte + pte_idx); } virt_addr += VMEM_PAGE_SIZE; } try_free_pte(pte, pmd + pmd_idx); pte_idx = 0; } try_free_pmd(pmd, pgd + pgd_idx); pmd_idx = 0; } try_free_pgd(pgd, ctx); } All parameters of the function, except the last, should be already familiar. free_pages is responsible for whether page records should be deleted from the tables.
try_free_pte, try_free_pmd, try_free_pgd are auxiliary functions. When deleting the next page, it may become clear that the directory containing it could become empty, which means that it should be deleted from memory.
Source code of try_free_pte, try_free_pmd, try_free_pgd functions
static inline int try_free_pte(mmu_pte_t *pte, mmu_pmd_t *pmd) { for (int pte_idx = 0 ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) { if (mmu_pte_present(pte + pte_idx)) { return 0; } } #if MMU_PTE_SHIFT != MMU_PMD_SHIFT mmu_pmd_unset(pmd); vmem_free_pte_table(pte); #endif return 1; } static inline int try_free_pmd(mmu_pmd_t *pmd, mmu_pgd_t *pgd) { for (int pmd_idx = 0 ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) { if (mmu_pmd_present(pmd + pmd_idx)) { return 0; } } #if MMU_PMD_SHIFT != MMU_PGD_SHIFT mmu_pgd_unset(pgd); vmem_free_pmd_table(pmd); #endif return 1; } static inline int try_free_pgd(mmu_pgd_t *pgd, mmu_ctx_t ctx) { for (int pgd_idx = 0 ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) { if (mmu_pgd_present(pgd + pgd_idx)) { return 0; } } // Something missing vmem_free_pgd_table(pgd); return 1; } View Macros
#if MMU_PTE_SHIFT != MMU_PMD_SHIFT ... #endif needed just for the case of a two-level hierarchy of memory.
Conclusion
Of course, this article is not enough to organize work with the MMU from scratch, but I hope it will at least help OSDev to those who find it too complicated.
PS All with the beginning of the week Mat-Mech :)
Source: https://habr.com/ru/post/256191/
All Articles