GrabDuck: a new look at bookmarks
Hello reader. This small introductory post about our project - search service GrabDuck . About what it is, what problems we tried to solve and what all this turns out.
Simply put, the history of the project in search of its grateful clients, which we have tried to make not boring and interesting. It turned out or not - to judge you. Anyone interested, please under Cut.
Most of us know the problem with saving bookmarks in the browser. We constantly read something new and postpone what is interesting in order to quickly find it later.
I did that too. Everything that was interesting, I saved as bookmarks in Google Chrome. When there was a lot of bookmarks, a long process of their classification began - this is how the “Programming” folder appeared, in it “java”, and “php” and “javascript” were located next to it. Then a bunch of other technologies that somehow interested me. Over time, it became difficult to understand all this - standard functionality does not allow to do much. Some links could be attributed to several folders at once, and sometimes I just forgot about the old classification and made a new one next door.
When there were a lot of bookmarks and there was no time to sort them right away, I found a way out - I had an Inbox. I promised myself that I would clear it on Fridays and began dumping everything I found there. However, this did not work, on Fridays there was always something more interesting. So, most of my bookmarks were in my inboxes (I once thought that it was somewhere far beyond 400). Over time, I found myself just going into the inbox and opening from there what I need and remember. And what I didn’t remember, I just didn’t open it, but looked again in Google.
So the idea of GrabDuck was born. And why I can not search in my bookmarks as well, as we regularly do in search engines - by asking search queries. After all, most of the time I try to find the article I need because (1) I know what exactly the article was about (and therefore I can formulate a search query in general terms) and (2) remember exactly that I had the necessary article somewhere ( and maybe not one).
“Stop,” I told myself, because I’m at work doing just that — searching. I know how it works, I have practical experience. And here on you - the shoemaker without shoes.
So began our GrabDuck.
What is GrabDuck and how do we see it?
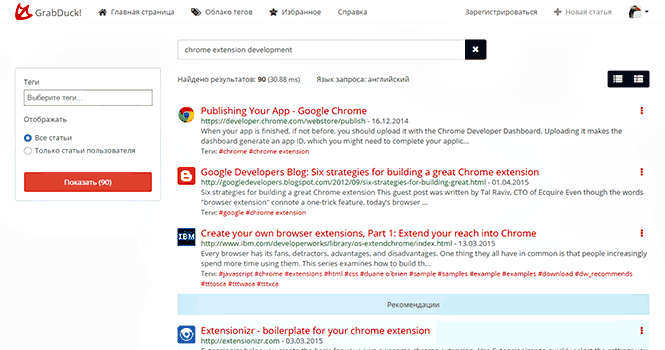
GrabDuck is a bookmarking service where you can search “like in Google”. The main idea of the service is to allow the user to drop the document in the "piggy bank" and forget - the system will help you find it when it is needed.
Therefore, GrabDuck, this is primarily a search. A good full-featured full-text search for all the materials that I saved (not only the title, but the entire article). A search that tries to find search phrase phrases based on vocabulary, and not just a set of words that the user has entered. This is a search that is constantly being studied, which search queries I enter and which documents I open most often and adapts to my preferences.
In addition, as a “free” bonus, the system offers its recommendations from articles of other users, which may also be of interest to me, again, based on my requests and preferences. And, if the recommended article is really interesting, I can add this article to me.
A small review with comments on what technologies and what we use.

Our server is Apache Tomcat running several Java applications. We tried to follow the principles of Microservices Architecture and brought different parts of the application to different modules that communicate with each other. In principle, now we need only one server for everything, but in the future, when needed, we can, for example, deploy an additional module that parses articles on a second machine, thus increasing the power of only one component of the system, without changing everything else.
We use Nginx as the front-end server. Long chose between Apache and Nginx, as a result, stopped at the second. The reasons are simple - for us it turned out to be more lightweight and easy to configure.
To store and work with data using a bunch of MySQL + Solr. A sort of hybrid, where each component is doing what it does best.
MySQL is responsible for the integrity and storage of data in a normalized form. We can always collect from several tables all the necessary information about the document - page content, meta data, who has the page in bookmarks, personal information for each user, such as tags. One big disadvantage of this system is that MySQL is very slow and provides almost no full-text search capabilities. It should be said that in general, from the point of view of the search, all the fulltext search solutions that modern SQL products now provide are, as a rule, some basic features with which it is very difficult and sometimes impossible to do something useful.
In summary, MySQL was not very good for searching. Therefore, when it is necessary to find something at the user's request, the second component, Solr, which is responsible for searching and aggregating information, comes into operation. Each document from the database, when created or modified, is sent to Solr and on the basis of it a view is created, which will be used directly for searching.
Thus, we have all the advantages of a classic SQL database combined with the speed and power that NoSQL gives us.
Consider what happens when the user adds something to the system. This can be either a single document added through the chrome extension , or the import of a large number of bookmarks, the essence does not change and data always follows the same algorithm.
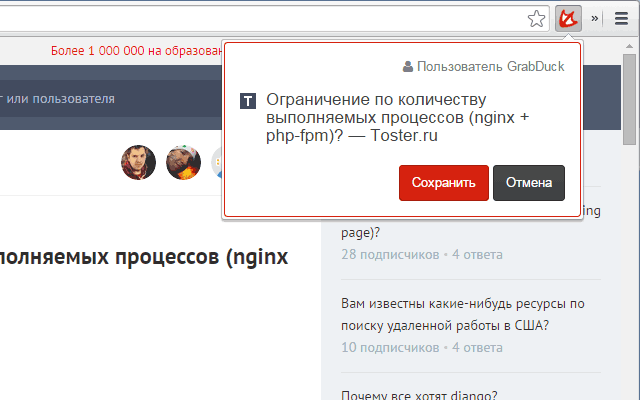
To begin with, a new document is created in which the URL and, if known, the title is stored. From this point on, the user sees the document in himself, although full-text search is of course not yet available. After some time, as a rule, the parsing task is started no later than 5 minutes. To parse the page and retrieve articles from it, we use the Snaktory library that we have adapted. At the exit we get the contents of the article, meta information and tags.
Now we need to check if this article is already in the database. If yes, then there is no need to save it and the user can “reuse” the existing one. Matching the canonical URL . As an example, any article on Habré has at least 3 different valid URLs: for google / yandex, for mobile display and for desktop. In this case, the canonical URL will always be the same. The same scheme allows us to avoid duplication of information if, for example, a user wants to import the same bookmarked file several times.
If the link is not duplicate, then the next step is the definition of the document language. This is necessary for two things. Firstly, the document is specifically adapted in the search index for searching in this particular language (at the moment we support Russian and English, next in line is German). And second, the language is used for filtering with recommendations. For example, if a user is aware that he is reading in English and German, then the recommendations in Russian will not be shown, even if there are some documents in Russian on the search query. To determine the language we use the Language-detection library. A big minus, as libraries in particular, as a whole probably all approaches to the definition of language - the quality drops sharply with a small amount of text, according to our observations, for 100% of the result, you must at least have 500 characters, after the quality starts to limp.
And the last step, based on the saved document, is created an entity in the Solr search index. From this point on, the document is available both for direct full-text search and for display in recommendations.
MVP is ready, first users appeared. When looking for something, we rejoice together. Particularly motivated when there are comments on the case. We want to say a special thank you to one of our users anton_slim - the person really went through the service and rolled out a list of what is incomprehensible and crooked - corrected.
Now we are actively testing the service and therefore we invite everyone to try and share their impressions.
We are planning to write on the blog on the topic of search: how we use technology, what problems we face and how we solve them, in general, anything that might be interesting to you.
Subscribe and let's chat.
Simply put, the history of the project in search of its grateful clients, which we have tried to make not boring and interesting. It turned out or not - to judge you. Anyone interested, please under Cut.
Introduction
Offtopic 1, which at the first reading can be skipped
Yes, we know that this is a goose, not a duck. It just so happened that when we were looking for the image for the first page, we liked this suspicious goose the most, and, believe me, more than one photo bank went through. And then, and who said that it should be a duck? Yes, it's a goose and he is watching you.
')
No, we have nothing to do with the DuckDuckGo project. I would like to, but no. We are not DDG, we are GD. In general, some kind of mod went on alternative search engines to assign ducks as the main ones, and so have we. Although, when they came up with the name, it didn’t even occur to me that it would look like something else. True true!
Frequently given answers
Yes, we know that this is a goose, not a duck. It just so happened that when we were looking for the image for the first page, we liked this suspicious goose the most, and, believe me, more than one photo bank went through. And then, and who said that it should be a duck? Yes, it's a goose and he is watching you.
')
No, we have nothing to do with the DuckDuckGo project. I would like to, but no. We are not DDG, we are GD. In general, some kind of mod went on alternative search engines to assign ducks as the main ones, and so have we. Although, when they came up with the name, it didn’t even occur to me that it would look like something else. True true!
Most of us know the problem with saving bookmarks in the browser. We constantly read something new and postpone what is interesting in order to quickly find it later.
I did that too. Everything that was interesting, I saved as bookmarks in Google Chrome. When there was a lot of bookmarks, a long process of their classification began - this is how the “Programming” folder appeared, in it “java”, and “php” and “javascript” were located next to it. Then a bunch of other technologies that somehow interested me. Over time, it became difficult to understand all this - standard functionality does not allow to do much. Some links could be attributed to several folders at once, and sometimes I just forgot about the old classification and made a new one next door.
When there were a lot of bookmarks and there was no time to sort them right away, I found a way out - I had an Inbox. I promised myself that I would clear it on Fridays and began dumping everything I found there. However, this did not work, on Fridays there was always something more interesting. So, most of my bookmarks were in my inboxes (I once thought that it was somewhere far beyond 400). Over time, I found myself just going into the inbox and opening from there what I need and remember. And what I didn’t remember, I just didn’t open it, but looked again in Google.
So the idea of GrabDuck was born. And why I can not search in my bookmarks as well, as we regularly do in search engines - by asking search queries. After all, most of the time I try to find the article I need because (1) I know what exactly the article was about (and therefore I can formulate a search query in general terms) and (2) remember exactly that I had the necessary article somewhere ( and maybe not one).
“Stop,” I told myself, because I’m at work doing just that — searching. I know how it works, I have practical experience. And here on you - the shoemaker without shoes.
So began our GrabDuck.
about the project
Offtopic 2, which can also be skipped
No, GrabDuck is not a startup. Tired of the tradition of calling everyone and everything a loud word - Startup. We do not want to participate in this endless battle for the investor. We want to make a good service that will bring its users to the benefit.
Yes, we love the service and use it ourselves. We all know that, but we really use GD every day. One day, a few months ago, when I showed my friend an early prototype, he asked: “what will you do if it doesn't work?”. “Not scary, the server is not expensive, I will pay and use myself,” I replied. I have been using it ever since.
Some platitudes (or the continuation of answers)
No, GrabDuck is not a startup. Tired of the tradition of calling everyone and everything a loud word - Startup. We do not want to participate in this endless battle for the investor. We want to make a good service that will bring its users to the benefit.
Yes, we love the service and use it ourselves. We all know that, but we really use GD every day. One day, a few months ago, when I showed my friend an early prototype, he asked: “what will you do if it doesn't work?”. “Not scary, the server is not expensive, I will pay and use myself,” I replied. I have been using it ever since.
What is GrabDuck and how do we see it?
GrabDuck is a bookmarking service where you can search “like in Google”. The main idea of the service is to allow the user to drop the document in the "piggy bank" and forget - the system will help you find it when it is needed.
Therefore, GrabDuck, this is primarily a search. A good full-featured full-text search for all the materials that I saved (not only the title, but the entire article). A search that tries to find search phrase phrases based on vocabulary, and not just a set of words that the user has entered. This is a search that is constantly being studied, which search queries I enter and which documents I open most often and adapts to my preferences.
In addition, as a “free” bonus, the system offers its recommendations from articles of other users, which may also be of interest to me, again, based on my requests and preferences. And, if the recommended article is really interesting, I can add this article to me.
What we use
A small review with comments on what technologies and what we use.
Our server is Apache Tomcat running several Java applications. We tried to follow the principles of Microservices Architecture and brought different parts of the application to different modules that communicate with each other. In principle, now we need only one server for everything, but in the future, when needed, we can, for example, deploy an additional module that parses articles on a second machine, thus increasing the power of only one component of the system, without changing everything else.
We use Nginx as the front-end server. Long chose between Apache and Nginx, as a result, stopped at the second. The reasons are simple - for us it turned out to be more lightweight and easy to configure.
To store and work with data using a bunch of MySQL + Solr. A sort of hybrid, where each component is doing what it does best.
MySQL is responsible for the integrity and storage of data in a normalized form. We can always collect from several tables all the necessary information about the document - page content, meta data, who has the page in bookmarks, personal information for each user, such as tags. One big disadvantage of this system is that MySQL is very slow and provides almost no full-text search capabilities. It should be said that in general, from the point of view of the search, all the fulltext search solutions that modern SQL products now provide are, as a rule, some basic features with which it is very difficult and sometimes impossible to do something useful.
In summary, MySQL was not very good for searching. Therefore, when it is necessary to find something at the user's request, the second component, Solr, which is responsible for searching and aggregating information, comes into operation. Each document from the database, when created or modified, is sent to Solr and on the basis of it a view is created, which will be used directly for searching.
Thus, we have all the advantages of a classic SQL database combined with the speed and power that NoSQL gives us.
How does it work
Consider what happens when the user adds something to the system. This can be either a single document added through the chrome extension , or the import of a large number of bookmarks, the essence does not change and data always follows the same algorithm.
To begin with, a new document is created in which the URL and, if known, the title is stored. From this point on, the user sees the document in himself, although full-text search is of course not yet available. After some time, as a rule, the parsing task is started no later than 5 minutes. To parse the page and retrieve articles from it, we use the Snaktory library that we have adapted. At the exit we get the contents of the article, meta information and tags.
Now we need to check if this article is already in the database. If yes, then there is no need to save it and the user can “reuse” the existing one. Matching the canonical URL . As an example, any article on Habré has at least 3 different valid URLs: for google / yandex, for mobile display and for desktop. In this case, the canonical URL will always be the same. The same scheme allows us to avoid duplication of information if, for example, a user wants to import the same bookmarked file several times.
If the link is not duplicate, then the next step is the definition of the document language. This is necessary for two things. Firstly, the document is specifically adapted in the search index for searching in this particular language (at the moment we support Russian and English, next in line is German). And second, the language is used for filtering with recommendations. For example, if a user is aware that he is reading in English and German, then the recommendations in Russian will not be shown, even if there are some documents in Russian on the search query. To determine the language we use the Language-detection library. A big minus, as libraries in particular, as a whole probably all approaches to the definition of language - the quality drops sharply with a small amount of text, according to our observations, for 100% of the result, you must at least have 500 characters, after the quality starts to limp.
And the last step, based on the saved document, is created an entity in the Solr search index. From this point on, the document is available both for direct full-text search and for display in recommendations.
Where are we now
MVP is ready, first users appeared. When looking for something, we rejoice together. Particularly motivated when there are comments on the case. We want to say a special thank you to one of our users anton_slim - the person really went through the service and rolled out a list of what is incomprehensible and crooked - corrected.
Now we are actively testing the service and therefore we invite everyone to try and share their impressions.
We are planning to write on the blog on the topic of search: how we use technology, what problems we face and how we solve them, in general, anything that might be interesting to you.
Subscribe and let's chat.
Source: https://habr.com/ru/post/256059/
All Articles