SQL Language Tutorial (DDL, DML) on the example of MS SQL Server dialect. Part four
Previous parts
- Part One - habrahabr.ru/post/255361
- Part Two - habrahabr.ru/post/255523
- Part Three - habrahabr.ru/post/255825
In this part we will look at
Multi-query queries:
- Operations of horizontal joining of tables - JOIN
- Linking tables with the WHERE condition
- Vertical operations for combining query results - UNION
Working with subqueries:
- Subqueries in FROM, SELECT blocks
- Subquery in the APPLY construction
- Using the WITH clause
- Subqueries in the WHERE clause:
- Group comparison - ALL, ANY
- EXISTS clause
- IN condition
Add some new data
For demonstration purposes, add a few departments and positions:
SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(4,N' ') INSERT Departments(ID,Name) VALUES(5,N'') SET IDENTITY_INSERT Departments OFF ')
SET IDENTITY_INSERT Positions ON INSERT Positions(ID,Name) VALUES(5,N'') INSERT Positions(ID,Name) VALUES(6,N'') INSERT Positions(ID,Name) VALUES(7,N'') SET IDENTITY_INSERT Positions OFF JOIN joins - horizontal data join operations
Here we will greatly benefit from knowledge of the database structure, i.e. what tables are there in it, what data is stored in these tables and which fields of the table are related to each other. First of all, always thoroughly study the database structure, since A normal query can be written only when you know where it is coming from. Our structure consists of 3 tables Employees, Departments and Positions. I will give here a diagram from the first part:
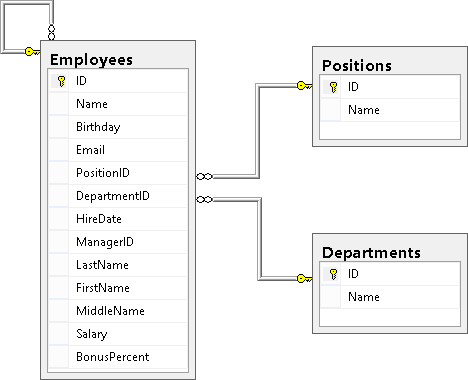
If the essence of the RDB is divide and conquer, then the essence of the operations of unions is again to glue together the data, divided into tables. bring them back to the human form.
Simply put, the operations of horizontal joining the table with other tables are used to get the missing data from them. Recall the example of the weekly report for the director when, when querying from the Employees table, we lacked the “Department Name” field in the Departments table to get the final result.
Let's start with the theory. There are five types of connections:
- JOIN - left_table JOIN right_table ON conditions_connection
- LEFT JOIN - left_table LEFT JOIN right_table ON conditions_connection
- RIGHT JOIN - left_table RIGHT JOIN right_table ON conditions_connection
- FULL JOIN - left_table FULL JOIN right_table ON conditions_connection
- CROSS JOIN - left_table CROSS JOIN right_table_
| Short syntax | Full syntax | Description (It’s not always clear to everyone. So, if it’s not clear, just return here after considering the examples.) |
|---|---|---|
| JOIN | INNER JOIN | From the rows of the left table and the right table, only those rows are returned, according to which join conditions are fulfilled. |
| LEFT JOIN | LEFT OUTER JOIN | All rows of the left_table are returned (keyword LEFT). Only those rows of the left_table that satisfy the conditions of joining are added to the data of the right_table. For missing data, NULL values are inserted instead of rows in the right_table. |
| RIGHT JOIN | RIGHT OUTER JOIN | Returns all rows in right_table (keyword RIGHT). Only those rows of the right_table that satisfy the conditions of joining are added to the data of the left_table. For missing data, NULL values are inserted instead of the left-table rows. |
| FULL JOIN | FULL OUTER JOIN | All rows from left_table and right_table are returned. If join_line conditions are met for the left_table and right_table, then they are combined into a single line. For rows that do not have join_conditions, NULL values are inserted in place of the left table or in the place of right table, depending on the data of which table in the row is not available. |
| CROSS JOIN | - | Combining each row of the left_table with all rows of the right_table. This type of compound is sometimes called Cartesian product. |
As the table shows, the full syntax from the short one differs only in the presence of the words INNER or OUTER.
Personally, I always use short syntax when writing queries, for the reason:
- This is shorter and does not litter the query with unnecessary words;
- According to LEFT, RIGHT, FULL and CROSS, and so it’s clear what kind of mix it is, just as in the case of JOIN;
- I consider the words INNER and OUTER in this case to be unnecessary rudiments, which more confuse beginners.
But of course, this is my personal preference, maybe someone likes to write long, and he sees this as his charms.
Understanding each type of compound is very important, because from the use of one or another type, the result of the query may differ. Compare the results of the same query using a different type of connection, just try to see the difference for now and move on (we'll come back here):
-- JOIN 5 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID | ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Ivanov I.I. | one | one | Administration |
| 1001 | Petrov P.P. | 3 | 3 | IT |
| 1002 | Sidorov S.S. | 2 | 2 | Accounting |
| 1003 | Andreev A.A. | 3 | 3 | IT |
| 1004 | Nikolaev N.N. | 3 | 3 | IT |
-- LEFT JOIN 6 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID | ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Ivanov I.I. | one | one | Administration |
| 1001 | Petrov P.P. | 3 | 3 | IT |
| 1002 | Sidorov S.S. | 2 | 2 | Accounting |
| 1003 | Andreev A.A. | 3 | 3 | IT |
| 1004 | Nikolaev N.N. | 3 | 3 | IT |
| 1005 | Aleksandrov A.A. | Null | Null | Null |
-- RIGHT JOIN 7 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID | ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Ivanov I.I. | one | one | Administration |
| 1002 | Sidorov S.S. | 2 | 2 | Accounting |
| 1001 | Petrov P.P. | 3 | 3 | IT |
| 1003 | Andreev A.A. | 3 | 3 | IT |
| 1004 | Nikolaev N.N. | 3 | 3 | IT |
| Null | Null | Null | four | Marketing and advertising |
| Null | Null | Null | five | Logistics |
-- FULL JOIN 8 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp FULL JOIN Departments dep ON emp.DepartmentID=dep.ID | ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Ivanov I.I. | one | one | Administration |
| 1001 | Petrov P.P. | 3 | 3 | IT |
| 1002 | Sidorov S.S. | 2 | 2 | Accounting |
| 1003 | Andreev A.A. | 3 | 3 | IT |
| 1004 | Nikolaev N.N. | 3 | 3 | IT |
| 1005 | Aleksandrov A.A. | Null | Null | Null |
| Null | Null | Null | four | Marketing and advertising |
| Null | Null | Null | five | Logistics |
-- CROSS JOIN 30 - (6 Employees) * (5 Departments) SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp CROSS JOIN Departments dep | ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Ivanov I.I. | one | one | Administration |
| 1001 | Petrov P.P. | 3 | one | Administration |
| 1002 | Sidorov S.S. | 2 | one | Administration |
| 1003 | Andreev A.A. | 3 | one | Administration |
| 1004 | Nikolaev N.N. | 3 | one | Administration |
| 1005 | Aleksandrov A.A. | Null | one | Administration |
| 1000 | Ivanov I.I. | one | 2 | Accounting |
| 1001 | Petrov P.P. | 3 | 2 | Accounting |
| 1002 | Sidorov S.S. | 2 | 2 | Accounting |
| 1003 | Andreev A.A. | 3 | 2 | Accounting |
| 1004 | Nikolaev N.N. | 3 | 2 | Accounting |
| 1005 | Aleksandrov A.A. | Null | 2 | Accounting |
| 1000 | Ivanov I.I. | one | 3 | IT |
| 1001 | Petrov P.P. | 3 | 3 | IT |
| 1002 | Sidorov S.S. | 2 | 3 | IT |
| 1003 | Andreev A.A. | 3 | 3 | IT |
| 1004 | Nikolaev N.N. | 3 | 3 | IT |
| 1005 | Aleksandrov A.A. | Null | 3 | IT |
| 1000 | Ivanov I.I. | one | four | Marketing and advertising |
| 1001 | Petrov P.P. | 3 | four | Marketing and advertising |
| 1002 | Sidorov S.S. | 2 | four | Marketing and advertising |
| 1003 | Andreev A.A. | 3 | four | Marketing and advertising |
| 1004 | Nikolaev N.N. | 3 | four | Marketing and advertising |
| 1005 | Aleksandrov A.A. | Null | four | Marketing and advertising |
| 1000 | Ivanov I.I. | one | five | Logistics |
| 1001 | Petrov P.P. | 3 | five | Logistics |
| 1002 | Sidorov S.S. | 2 | five | Logistics |
| 1003 | Andreev A.A. | 3 | five | Logistics |
| 1004 | Nikolaev N.N. | 3 | five | Logistics |
| 1005 | Aleksandrov A.A. | Null | five | Logistics |
It’s time to think about table aliases
The time has come to recall the pseudonyms of the tables, which I described at the beginning of the second part.
In multi-query queries, the pseudonym helps us explicitly specify from which table the field is taken. Let's look at an example:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID In it, the fields with the names ID and Name are in both tables in both Employees and Departments. And in order to distinguish them, we preface the field name with an alias and a period, i.e. "Emp.ID", "emp.Name", "dep.ID", "dep.Name".
We recall why it is more convenient to use short pseudonyms - because, without pseudonyms, our query would look like this:
SELECT Employees.ID,Employees.Name,Employees.DepartmentID,Departments.ID,Departments.Name FROM Employees JOIN Departments ON Employees.DepartmentID=Departments.ID For me, it became very long and worse to read, because field names are visually lost among duplicate table names.
In multi-query queries, although you can specify a name without a pseudonym, if the name is not duplicated in the second table, I would recommend always using pseudonyms when connecting, because nobody guarantees that a field with the same name will not be added to the second table over time, and then your query will simply break, swearing that it cannot understand to which table this field belongs.
Only by using pseudonyms can we make the connection of the table with ourselves. Suppose there is a task to get for each employee, the data of the employee who was accepted right before him (the personnel number differs by one less). Suppose that our personnel numbers are issued sequentially and without holes, then we can do it in the following way:
SELECT e1.ID EmpID1, e1.Name EmpName1, e2.ID EmpID2, e2.Name EmpName2 FROM Employees e1 LEFT JOIN Employees e2 ON e1.ID=e2.ID+1 -- Those. here is one table Employees, we gave the alias "e1", and the second "e2".
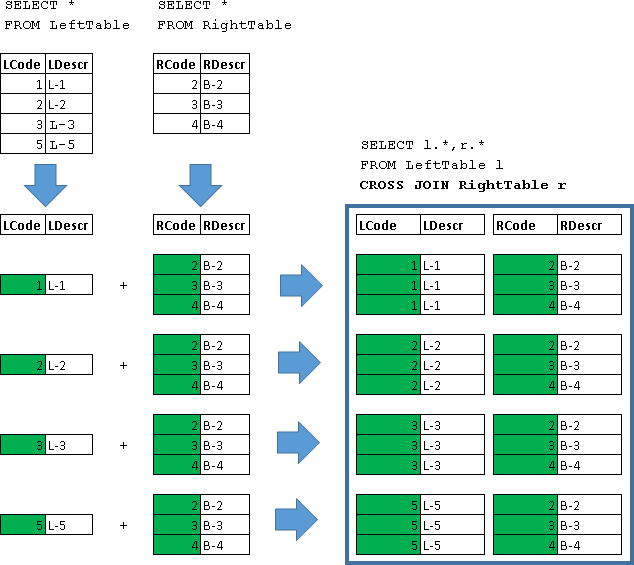
Parse each type of horizontal connection.
For this purpose, we consider 2 small abstract tables, which we call LeftTable and RightTable:
CREATE TABLE LeftTable( LCode int, LDescr varchar(10) ) GO CREATE TABLE RightTable( RCode int, RDescr varchar(10) ) GO INSERT LeftTable(LCode,LDescr)VALUES (1,'L-1'), (2,'L-2'), (3,'L-3'), (5,'L-5') INSERT RightTable(RCode,RDescr)VALUES (2,'B-2'), (3,'B-3'), (4,'B-4') Let's see what's in these tables:
SELECT * FROM LeftTable | LCode | Ldescr |
|---|---|
| one | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| five | L-5 |
SELECT * FROM RightTable | RCode | RDescr |
|---|---|
| 2 | B-2 |
| 3 | B-3 |
| four | B-4 |
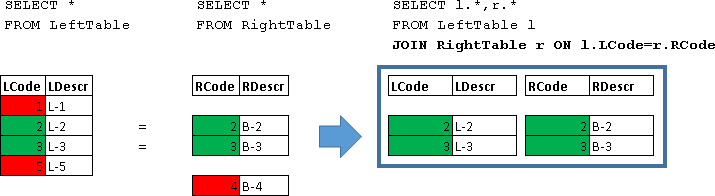
JOIN
SELECT l.*,r.* FROM LeftTable l JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Here string returns were returned for which the condition was met (l.LCode = r.RCode)
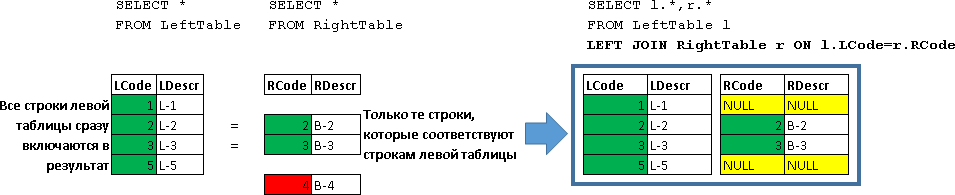
LEFT JOIN
SELECT l.*,r.* FROM LeftTable l LEFT JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| one | L-1 | Null | Null |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| five | L-5 | Null | Null |
Here, all LeftTable strings were returned, which were supplemented with data from the RightTable strings, for which the condition was satisfied (l.LCode = r.RCode)
RIGHT JOIN
SELECT l.*,r.* FROM LeftTable l RIGHT JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| Null | Null | four | B-4 |
Here all the RightTable strings were returned, which were supplemented with the data strings from the LeftTable, for which the condition was met (l.LCode = r.RCode)

In fact, if we rearrange LeftTable and RightTable in some places, we will get a similar result using the left connection:
SELECT l.*,r.* FROM RightTable r LEFT JOIN LeftTable l ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| Null | Null | four | B-4 |
I noticed with myself that I use LEFT JOIN more often, i.e. I first think which table data is important to me, and then I think which table / tables will play the role of a complementary table.
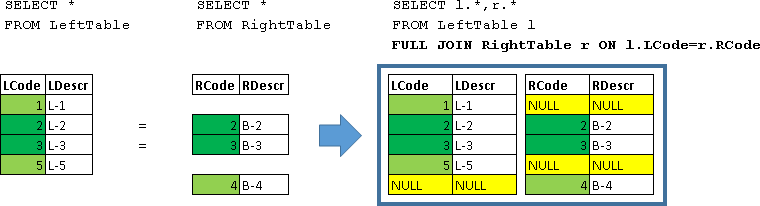
FULL JOIN is essentially a simultaneous LEFT JOIN + RIGHT JOIN
SELECT l.*,r.* FROM LeftTable l FULL JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| one | L-1 | Null | Null |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| five | L-5 | Null | Null |
| Null | Null | four | B-4 |
All rows from LeftTable and RightTable are returned. The strings for which the condition was met (l.LCode = r.RCode) were combined into one string. Missing in the line data on the left or right side are filled with NULL-values.
CROSS JOIN
SELECT l.*,r.* FROM LeftTable l CROSS JOIN RightTable r | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| one | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| five | L-5 | 2 | B-2 |
| one | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| five | L-5 | 3 | B-3 |
| one | L-1 | four | B-4 |
| 2 | L-2 | four | B-4 |
| 3 | L-3 | four | B-4 |
| five | L-5 | four | B-4 |
Each LeftTable line connects to the data of all RightTable lines.
Go back to the Employees and Departments tables.
I hope you understand the principle of horizontal joints. If this is the case, then return to the beginning of the “JOIN-connections - horizontal data-joining operations” section and try to understand the examples yourself by combining the Employees and Departments tables, and then come back again, discuss it together.
Let's try to summarize together for each request:
| Request | Summary |
|---|---|
| In essence, this query will return only employees who have the DepartmentID value. Those. we can use this connection in the case when we need data on employees belonging to some department (excluding external correspondents). |
| Will return all employees. For those employees who do not have the DepartmentID specified, the “dep.ID” and “dep.Name” fields will contain NULL. Remember that NULL values can be processed, for example, with the help of ISNULL (dep. Name, 'out of state'), for example. This type of connection can be used when it is important for us to obtain data on all employees, for example, to get a list for the calculation of the salary. |
| Here we got holes on the left, i.e. there is a department, but there are no employees in this department. Such a connection can be used, for example, when you need to find out which departments are occupied and who we are and who have not yet been formed. This information can be used to search and receive new employees from which the department will be formed. |
| This query is important when we need to get all the data on employees and all the data on the existing departments. Accordingly, we get holes (NULL-values) either by employees or by departments (freelancers). This request, for example, can be used to check whether all employees are in the right departments, because maybe some employees who are listed as freelancers simply forgot to specify a department. |
| In this form, it is even difficult to think of where this can be applied, so I will show the example with CROSS JOIN below. |
Note that in case of repeating the DepartmentID values in the Employees table, each such row was connected to a row from the Departments table with the same ID, that is, the Departments data merged with all the records for which the condition was fulfilled (emp.DepartmentID = dep.ID):

In our case, everything turned out right, i.e. we supplemented the Employees table with data from the Departments table. I specifically drew attention to this, because there are times when we do not need this behavior. For the demonstration, we set the task - for each department to bring out the last employee who has been received, if there are no employees, then simply print the name of the department. Perhaps such a solution suggests itself - just take the previous query and change the connection condition to RIGHT JOIN, plus rearrange the fields in some places:
SELECT dep.ID,dep.Name,emp.ID,emp.Name FROM Employees emp RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID | ID | Name | ID | Name |
|---|---|---|---|
| one | Administration | 1000 | Ivanov I.I. |
| 2 | Accounting | 1002 | Sidorov S.S. |
| 3 | IT | 1001 | Petrov P.P. |
| 3 | IT | 1003 | Andreev A.A. |
| 3 | IT | 1004 | Nikolaev N.N. |
| four | Marketing and advertising | Null | Null |
| five | Logistics | Null | Null |
But for the IT department, we got three lines, when we needed only a line with the last employee we took, i.e. Nikolayev N.N.
A task of this kind can be solved, for example, by using a subquery:
SELECT dep.ID,dep.Name,emp.ID,emp.Name FROM Employees emp /* ( - MAX(ID)) (GROUP BY DepartmentID) */ JOIN ( SELECT MAX(ID) MaxEmployeeID FROM Employees GROUP BY DepartmentID ) lastEmp ON emp.ID=lastEmp.MaxEmployeeID RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID -- Departments | ID | Name | ID | Name |
|---|---|---|---|
| one | Administration | 1000 | Ivanov I.I. |
| 2 | Accounting | 1002 | Sidorov S.S. |
| 3 | IT | 1004 | Nikolaev N.N. |
| four | Marketing and advertising | Null | Null |
| five | Logistics | Null | Null |
With the help of pre-combining Employees with subquery data, we were able to leave only the employees we need to connect to Departments.
Here we smoothly turn to the use of subqueries. I think using them in this form should be clear to you on an intuitive level. That is, the subquery is substituted into the place of the table and plays its role, nothing complicated. We will return to the topic of subqueries separately.
See separately what the subquery returns:
SELECT MAX(ID) MaxEmployeeID FROM Employees GROUP BY DepartmentID | MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Those. he returned only the identifiers of the last employees he received, in the context of the departments.
Connections are performed sequentially from top to bottom, building up like a snowball that rolls down a mountain. First, the “Employees emp JOIN (Subquery) lastEmp” is connected, forming a new output set:

Then comes the combination of the set obtained by “Employees emp JOIN (Subquery) lastEmp” (let's call it conditionally “LastResult”) with Departments, i.e. “Last Result RIGHT JOIN Departments dep”:

Independent work to secure the material
If you are a beginner, then you definitely need to work through each JOIN-design, until you understand 100% how each type of connection works and correctly represent the result of what kind will be obtained as a result.
To consolidate the material about the JOIN-connection, we will do the following:
-- LeftTable RightTable TRUNCATE TABLE LeftTable TRUNCATE TABLE RightTable GO -- INSERT LeftTable(LCode,LDescr)VALUES (1,'L-1'), (2,'L-2a'), (2,'L-2b'), (3,'L-3'), (5,'L-5') INSERT RightTable(RCode,RDescr)VALUES (2,'B-2a'), (2,'B-2b'), (3,'B-3'), (4,'B-4') Let's see what is in the tables:
SELECT * FROM LeftTable | LCode | Ldescr |
|---|---|
| one | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| five | L-5 |
SELECT * FROM RightTable | RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| four | B-4 |
Now try to figure out for yourself how each line of the query turned out with each type of connection (Excel to help you):
SELECT l.*,r.* FROM LeftTable l JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
SELECT l.*,r.* FROM LeftTable l LEFT JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| one | L-1 | Null | Null |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| five | L-5 | Null | Null |
SELECT l.*,r.* FROM LeftTable l RIGHT JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| Null | Null | four | B-4 |
SELECT l.*,r.* FROM LeftTable l FULL JOIN RightTable r ON l.LCode=r.RCode | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| one | L-1 | Null | Null |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| five | L-5 | Null | Null |
| Null | Null | four | B-4 |
SELECT l.*,r.* FROM LeftTable l CROSS JOIN RightTable r | LCode | Ldescr | RCode | RDescr |
|---|---|---|---|
| one | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| five | L-5 | 2 | B-2a |
| one | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| five | L-5 | 2 | B-2b |
| one | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| five | L-5 | 3 | B-3 |
| one | L-1 | four | B-4 |
| 2 | L-2a | four | B-4 |
| 2 | L-2b | four | B-4 |
| 3 | L-3 | four | B-4 |
| five | L-5 | four | B-4 |
Once again about JOIN connections
Another example using multiple sequential join operations. Here, the repetition was not intentional, it turned out - not to throw away the same material. ;) But nothing "repetition - the mother of learning."
If several join operations are used, then they are applied sequentially from top to bottom. Roughly speaking, after each connection a new set is created and the next connection is already happening with this extended set. Consider a simple example:
SELECT e.ID, e.Name EmployeeName, p.Name PositionName, d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID First of all, we selected all the entries in the Employees table:
SELECT e.* FROM Employees e -- 1 Next was a connection to the Departments table:
SELECT e.*, -- Employees d.* -- (e.DepartmentID=d.ID) Departments FROM Employees e -- 1 LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2 Next is the connection of this set with the table Positions:
SELECT e.*, -- Employees d.*, -- (e.DepartmentID=d.ID) Departments p.* -- (e.PositionID=p.ID) Positions FROM Employees e -- 1 LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2 LEFT JOIN Positions p ON e.PositionID=p.ID -- 3 Those. it looks like this:

And last but not least, we are returning the data that we ask to display:
SELECT e.ID, -- 1. e.Name EmployeeName, -- 2. p.Name PositionName, -- 3. d.Name DepartmentName -- 4. FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID Accordingly, the WHERE filter and ORDER BY sorting can be applied to all of this resulting set:
SELECT e.ID, -- 1. e.Name EmployeeName, -- 2. p.Name PositionName, -- 3. d.Name DepartmentName -- 4. FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID WHERE d.ID=3 -- ID Departments AND p.ID=3 -- ID Positions ORDER BY e.Name -- Name Employees | ID | EmployeeName | PositionName | DepartmentName |
|---|---|---|---|
| 1004 | Nikolaev N.N. | Programmer | IT |
| 1001 | Petrov P.P. | Programmer | IT |
That is, the last set received is the same table over which you can perform a basic query:
SELECT [DISTINCT] _ * FROM WHERE ORDER BY _ That is, if earlier only one table acted as a source, now we simply substitute our expression for this place:
Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID As a result, we get the same basic query:
SELECT e.ID, e.Name EmployeeName, p.Name PositionName, d.Name DepartmentName FROM /* - */ Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID /* - */ WHERE d.ID=3 AND p.ID=3 ORDER BY e.Name And now, apply grouping:
SELECT ISNULL(dep.Name,'') DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg -- FROM /* - */ Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID /* - */ GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName You see, we are still spinning around the base structures, now I hope it’s clear why it’s very important to understand them first of all.
And as we have seen, in a query, a subquery can be in place of any table. In turn, subqueries can be nested in subqueries. And all these subqueries are basic constructs too. That is, the basic design, these are the bricks from which any query is built.
CROSS JOIN promised example
Let's use the CROSS JOIN connection to calculate how many employees, in which department, and in which positions. For each department we will list all existing posts:
SELECT d.Name DepartmentName, p.Name PositionName, e.EmplCount FROM Departments d CROSS JOIN Positions p LEFT JOIN ( /* (DepartmentID,PositionID) */ SELECT DepartmentID,PositionID,COUNT(*) EmplCount FROM Employees GROUP BY DepartmentID,PositionID ) e ON e.DepartmentID=d.ID AND e.PositionID=p.ID ORDER BY DepartmentName,PositionName 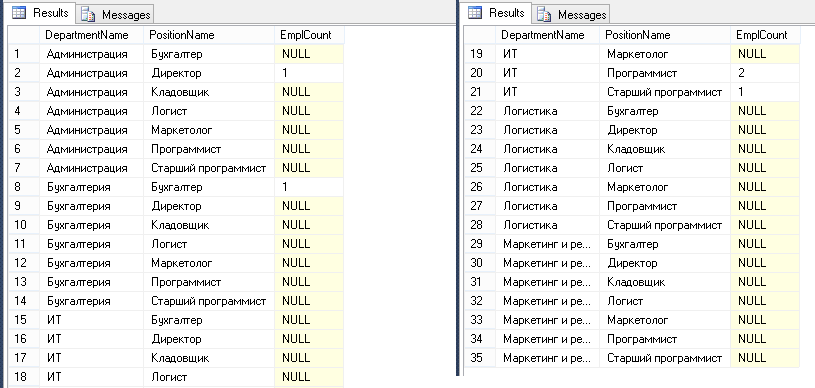
In this case, the connection was first performed using a CROSS JOIN, and then a connection was made to the received set with the data from the subquery using the LEFT JOIN. Instead of a table in the LEFT JOIN, we used a subquery.
, «e». , :
SELECT DepartmentID,PositionID,COUNT(*) EmplCount FROM Employees GROUP BY DepartmentID,PositionID | DepartmentID | PositionID | EmplCount |
|---|---|---|
| Null | Null | one |
| 2 | one | one |
| one | 2 | one |
| 3 | 3 | 2 |
| 3 | four | one |
«e» DepartmentID, PositionID EmplCount. , . , ,
, , .
WHERE-
JOIN-:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID -- WHERE emp.DepartmentID=3 -- WHERE- :
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp, Departments dep WHERE emp.DepartmentID=dep.ID -- AND emp.DepartmentID=3 -- , (emp.DepartmentID=dep.ID) (emp.DepartmentID=3).
, CROSS JOIN:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp CROSS JOIN Departments dep -- ( ) WHERE emp.DepartmentID=3 -- WHERE- :
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp, Departments dep WHERE emp.DepartmentID=3 -- Those. Employees Departments. ? , - « , (emp.DepartmentID=dep.ID)» , , . , .. CROSS JOIN. , , , , CROSS JOIN.
For the query optimizer, it can be no matter how you implement the connection (using WHERE or JOIN), it can do them exactly the same. But for reasons of understanding the code, I would recommend in modern DBMS to try never to make the connection of tables using WHERE conditions. To use WHERE conditions for the connection, in the event that the JOIN constructions are implemented in the DBMS, I would now call it the moveton. WHERE conditions are used to filter the set, and there is no need to mix the conditions used for the connection with the conditions responsible for filtering. But if you have come to the conclusion that you cannot do without implementing a connection via WHERE, then of course the priority for the task is solved and “to hell with all foundations”.
UNION unions - operations of vertical unification of query results
, .. , .
:
SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL -- , , , , UNION ALL, :
SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- UNION ALL SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- UNION ALL SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- UNION ALL SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL -- 
Those. UNION ALL , .
, , .. , , ..
Some theory
MS SQL :
| Operation | Description |
|---|---|
| UNION ALL | . (A+B) |
| UNION | . DISTINCT(A+B) |
| EXCEPT | , . 2- . DISTINCT(AB) |
| INTERSECT | , . 2- . DISTINCT(A&B) |
.
2 :
CREATE TABLE TopTable( T1 int, T2 varchar(10) ) GO CREATE TABLE BottomTable( B1 int, B2 varchar(10) ) GO INSERT TopTable(T1,T2)VALUES (1,'Text 1'), (1,'Text 1'), (2,'Text 2'), (3,'Text 3'), (4,'Text 4'), (5,'Text 5') INSERT BottomTable(B1,B2)VALUES (2,'Text 2'), (3,'Text 3'), (6,'Text 6'), (6,'Text 6') :
SELECT * FROM TopTable | T1 | T2 |
|---|---|
| one | Text 1 |
| one | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| four | Text 4 |
| five | Text 5 |
SELECT * FROM BottomTable | B1 | B2 |
|---|---|
| 2 | Text 2 |
| 3 | Text 3 |
| 6 | Text 6 |
| 6 | Text 6 |
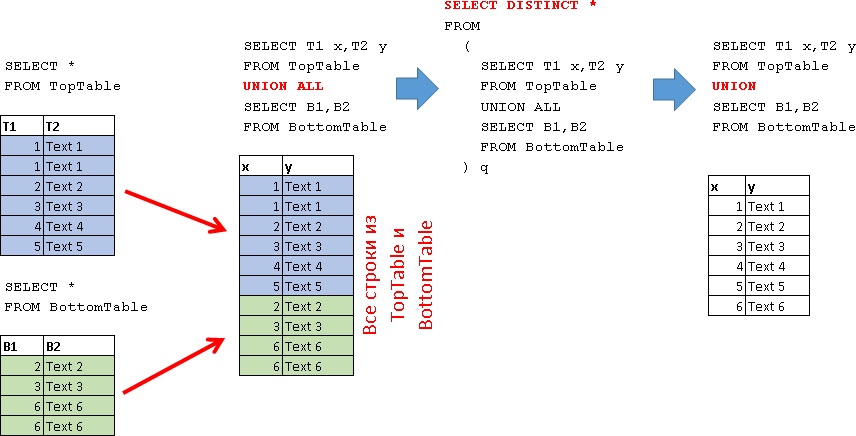
UNION ALL
SELECT T1 x,T2 y FROM TopTable UNION ALL SELECT B1,B2 FROM BottomTable 
UNION
SELECT T1 x,T2 y FROM TopTable UNION SELECT B1,B2 FROM BottomTable UNION , UNION ALL, DISTINCT:
EXCEPT
SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable 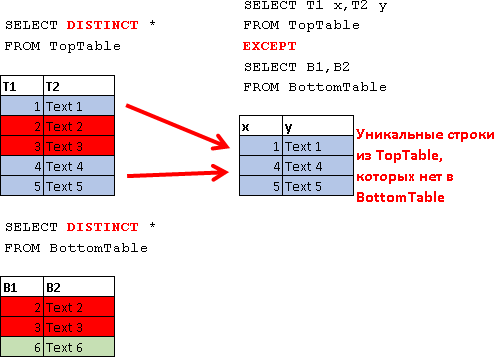
INTERSECT
SELECT T1 x,T2 y FROM TopTable INTERSECT SELECT B1,B2 FROM BottomTable 
UNION-
That's basically all that concerns vertical joins, it is much easier than JOIN joins.
Most often, UNION ALL is used in my practice, but other types of vertical unions also find their application.
With several operations vertically merging, it is not guaranteed that they will be performed sequentially from top to bottom. Create another table and consider it with an example:
CREATE TABLE NextTable( N1 int, N2 varchar(10) ) GO INSERT NextTable(N1,N2)VALUES (1,'Text 1'), (4,'Text 4'), (6,'Text 6') For example, if we write simply:
SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable INTERSECT SELECT N1,N2 FROM NextTable Then we get:
| x | y |
|---|---|
| one | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| four | Text 4 |
| five | Text 5 |
Those. INTERSECT, EXCEPT. , .. -.
, , , , , , , EXCEPT, INTERSECT:
( SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) INTERSECT SELECT N1,N2 FROM NextTable | x | y |
|---|---|
| one | Text 1 |
| four | Text 4 |
, .
, :
SELECT x,y FROM ( SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) q INTERSECT SELECT N1,N2 FROM NextTable ORDER BY :
SELECT T1 x,T2 y FROM TopTable UNION ALL SELECT B1,B2 FROM BottomTable UNION ALL SELECT B1,B2 FROM BottomTable ORDER BY x DESC , .
UNION- , UNION- .
Note. Oracle , EXCEPT, MINUS.
, .. . .
FROM. , . , . 2- :
SELECT q1.x1,q1.y1,q2.x2,q2.y2 FROM ( SELECT T1 x1,T2 y1 FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) q1 JOIN ( SELECT T1 x2,T2 y2 FROM TopTable EXCEPT SELECT N1,N2 FROM NextTable ) q2 ON q1.x1=q2.x2 , , . Those. , «q1», , «q2», JOIN «q1» «q2».
WITH
.
Compare:
SELECT q1.x1,q1.y1,q2.x2,q2.y2 FROM ( SELECT T1 x1,T2 y1 FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) q1 JOIN ( SELECT T1 x2,T2 y2 FROM TopTable EXCEPT SELECT N1,N2 FROM NextTable ) q2 ON q1.x1=q2.x2 The same is written with WITH:
WITH q1 AS( SELECT T1 x1,T2 y1 FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ), q2 AS( SELECT T1 x2,T2 y2 FROM TopTable EXCEPT SELECT N1,N2 FROM NextTable ) -- SELECT q1.x1,q1.y1,q2.x2,q2.y2 FROM q1 JOIN q2 ON q1.x1=q2.x2 As you can see, large subqueries are rendered and named in the WITH block, which made it possible to unload the text of the main query and make it understandable.
Let us also recall the example from the previous part, where the ViewEmployeesInfo view was used:
CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- Employees dep.Name DepartmentName, -- Name Departments pos.Name PositionName -- Name Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID And the query that used this presentation:
SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName In essence, WITH allows us to place text from the view directly in the request, i.e. the meaning is the same:
WITH cteEmployeesInfo AS( SELECT emp.*, -- Employees dep.Name DepartmentName, -- Name Departments pos.Name PositionName -- Name Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID ) SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM cteEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName Only in the case of a created view, we can use it from different requests, since The view is created at the database level. Whereas the subquery issued in the WITH block is visible only within the framework of this query.
WITH - CTE-:
(CTE — Common Table Expressions) , . CTE , , .
CTE , .
. ( , Employees , ).
WITH cteEmpl AS( SELECT ID,CAST(Name AS nvarchar(300)) Name,1 EmpLevel FROM Employees WHERE ManagerID IS NULL -- UNION ALL SELECT emp.ID,CAST(SPACE(cte.EmpLevel*5)+emp.Name AS nvarchar(300)),cte.EmpLevel+1 FROM Employees emp JOIN cteEmpl cte ON emp.ManagerID=cte.ID ) SELECT * FROM cteEmpl | ID | Name | EmpLevel |
|---|---|---|
| 1000 | Ivanov I.I. | one |
| 1002 | _____ .. | 2 |
| 1003 | _____ .. | 2 |
| 1005 | _____ .. | 2 |
| 1001 | __________ .. | 3 |
| 1004 | __________ .. | 3 |
.
, , . , , . , , . , , .
Let's now look at how you can still use subqueries, and also pass parameters to them using an alias from the main query.
Here I will no longer go deeply into the explanation, since By this stage you should have already learned to think and understand the principle of working with data. Be sure to practice, follow the examples and try and understand the result. To understand, you need to feel each example itself.
The subquery can be used in the SELECT block
Let's return to our report:
SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg -- FROM Employees GROUP BY DepartmentID Here the department name can also be obtained using a subquery with the parameter:
SELECT /* */ (SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM Employees emp -- GROUP BY DepartmentID ORDER BY DepartmentName (SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) 4 , .. emp.DepartmentID
. , TOP, - , . , ID :
SELECT ID, Name, -- 1 - ID (SELECT MAX(ID) FROM Employees emp WHERE emp.DepartmentID=dep.ID) LastEmpID_var1, -- 1 - ID (SELECT TOP 1 ID FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpID_var2, -- 2 - (SELECT TOP 1 Name FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpName FROM Departments dep ? Since 4 ( ), 12 .
, , .. , .. . .
APPLY
MS SQL :
SELECT ID, Name, -- 1 - ID (SELECT TOP 1 ID FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpID, -- 2 - (SELECT TOP 1 Name FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpName FROM Departments dep APPLY, 2 – CROSS APPLY OUTER APPLY.
APPLY , , ID Name :
SELECT ID, Name, empInfo.LastEmpID, empInfo.LastEmpName FROM Departments dep CROSS APPLY ( SELECT TOP 1 ID LastEmpID,Name LastEmpName FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY emp.ID DESC ) empInfo | ID | Name | LastEmpID | LastEmpName |
|---|---|---|---|
| one | Administration | 1000 | Ivanov I.I. |
| 2 | Accounting | 1002 | .. |
| 3 | IT | 1004 | .. |
CROSS APPLY Departments. , .
, Departments, OUTER APPLY:
SELECT ID, Name, empInfo.LastEmpID, empInfo.LastEmpName FROM Departments dep OUTER APPLY ( SELECT TOP 1 ID LastEmpID,Name LastEmpName FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY emp.ID DESC ) empInfo | ID | Name | LastEmpID | LastEmpName |
|---|---|---|---|
| one | Administration | 1000 | Ivanov I.I. |
| 2 | Accounting | 1002 | .. |
| 3 | IT | 1004 | .. |
| four | Null | Null | |
| five | Logistics | Null | Null |
, , . , .. , , . APPLY, , , , . , , :
SELECT dep.ID,dep.Name,pos.PositionID,pos.PositionName FROM Departments dep CROSS APPLY ( SELECT ID PositionID,Name PositionName FROM Positions ) pos WHERE
, :
SELECT * FROM Departments dep WHERE (SELECT COUNT(*) FROM Employees emp WHERE emp.DepartmentID=dep.ID)>2 , , .. SELECT.
EXISTS and NOT EXISTS constructs
Allow to check whether there are records corresponding to the condition in the subquery:
-- SELECT * FROM Departments dep WHERE EXISTS(SELECT * FROM Employees emp WHERE emp.DepartmentID=dep.ID) -- SELECT * FROM Departments dep WHERE NOT EXISTS(SELECT * FROM Employees emp WHERE emp.DepartmentID=dep.ID) Everything is simple here - EXISTS returns True if the subquery returns at least one row, and False if the subquery does not return rows. NOT EXISTS - inversion of the result.
IN and NOT IN subquery construction
Before that, we looked at IN with a listing of values. You can also use it with a subquery that returns a list of these values:
-- SELECT * FROM Departments WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees WHERE DepartmentID IS NOT NULL) -- SELECT * FROM Departments WHERE ID NOT IN(SELECT DISTINCT DepartmentID FROM Employees WHERE DepartmentID IS NOT NULL) Note that I excluded the NULL value using the condition (DepartmentID IS NOT NULL) in the subquery. NULL values in this case are just as dangerous - see this in the description of the IN construct in the second part.
Group comparison operations ALL and ANY
, . , IN EXISTS.
ALL ANY , , . , EXISTS .
, . ALL:
SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE e1.Salary>ALL( SELECT e2.Salary FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID -- AND e2.ID<>e1.ID -- AND e2.Salary IS NOT NULL -- NULL ) | ID | Name | DepartmentID | Salary |
|---|---|---|---|
| 1000 | Ivanov I.I. | one | 5000 |
| 1002 | .. | 2 | 2500 |
| 1003 | .. | 3 | 2000 |
| 1005 | .. | Null | 2000 |
, e1.Salary e2.Salary, .
, , ? – , , . ))) .
, , ALL NOT EXISTS:
SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE NOT EXISTS( SELECT * FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID -- AND e2.Salary>e1.Salary -- ) Those. « ».
ALL .
, ALL NULL- , . ALL AND, .. (Salary>1000 AND Salary>1500 AND Salary>NULL) NULL.
ANY ( SOME) -:
SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE e1.Salary>ANY( -- ANY = SOME SELECT e2.Salary FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID -- AND e2.ID<>e1.ID -- ) | ID | Name | DepartmentID | Salary |
|---|---|---|---|
| 1003 | .. | 3 | 2000 |
C ANY , , . Since , -, .., . Those. , .
, ANY EXISTS:
SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE EXISTS( SELECT * FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID -- AND e2.Salary<e1.Salary -- ) « - ».
, ANY , .
NULL- , .. . ANY OR, .. (Salary>1000 OR Salary>1500 OR Salary>NULL) .
ANY , IN:
SELECT * FROM Departments WHERE ID=ANY(SELECT DISTINCT DepartmentID FROM Employees) , . :
SELECT * FROM Departments WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees) ALL ANY . , . Those. « »:
SELECT * FROM Employees e1 WHERE e1.Salary>ALL(SELECT e2.Salary FROM Employees e2 WHERE e2.ID<>e1.ID AND e2.Salary IS NOT NULL) « »:
SELECT * FROM Employees e1 WHERE NOT EXISTS(SELECT * FROM Employees e2 WHERE e2.Salary>e1.Salary) , SQL , .
, , HAVING, CASE. , .
SELECT, , , .
. , SELECT , .. , , , ( -), . , , , , .
, – , .. . , , . , .
Conclusion
SELECT. , , , .
, SQL, 10 , ( Paradox). , SQL . , , -. , - , . , , .
In the next part, I will discuss in general terms the data modification operators. In general terms, since this information, like knowledge of DDL, is not needed by everyone (mostly IT professionals) - most people learn SQL precisely in order to learn how to sample data using the SELECT statement. I think the next part will be final. All knowledge gained up to this point will also be useful to us in the next part, since for the correct writing of complex structures for data modification, you need to confidently use the constructions of the SELECT operator. For example, before deleting or modifying a group of rows of a table, we must correctly select this data. Therefore, the next part will also contain SELECT constructs and I think it will be of interest to those people who learn SQL precisely because of the SELECT statement.
, , . «SQL-EX.RU – SQL», , . SQL. , , .
, :
- OVER, :
- (COUNT, SUM, MIN, MAX, AVG) GROUP BY;
- : ROW_NUMBER(),RANK() DENSE_RANK();
- : LAG() LEAD(),FIRST_VALUE() LAST_VALUE();
- : GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), … : GROUPING_ID() GROUPING();
- PIVOT, UNPIVOT.
« 1 – SELECT» « 2 – OVER ». , MSDN.
.
— habrahabr.ru/post/256169
Source: https://habr.com/ru/post/256045/
All Articles