IPP functions with border support for multi-stream image processing
As a result of prolonged use of even the best software products, one or another of their shortcomings is gradually revealed. Not an exception, and the Intel Performance Primitives Library (IPP). By the time of release of version 8.0, some problems emerged, some of which relate to the functions of processing two-dimensional images.
To solve them, in IPP 8.0, many image processing functions are reduced to a common template, which allows to process images in blocks ( tiles ) and, therefore, effectively parallelize at the application level code containing calls to IPP functions. The new API of the corresponding IPP functions supports several types of borders, does not use the internal allocation of dynamic memory, allows you to divide images into fragments of arbitrary size and process these fragments independently; simplifies use and improves the performance of a number of functions. This article details the new API and provides examples of its use.
As mentioned above, the IPP development team did a lot of work on changing the interface of two-dimensional functions and bringing it to a single standard “API with curb support” (“new API”). What for? To answer this question, let's describe the problems that were present in previous versions.
So the first problem is how to use IPP in multi-threaded applications. Sometimes the problem of parallel image processing is more effectively solved at the top level, i.e. at the application level. In this case, the application itself breaks the image into blocks and creates threads for their parallel processing. The multi-threaded version of IPP uses OpenMP with nested parallelism disabled (in English nested threading ). If an application uses another tool for multithreading or even OpenMP, but a different version, then when calling an IPP function from such an application, several threads will be created in turn, as shown in Fig. one.
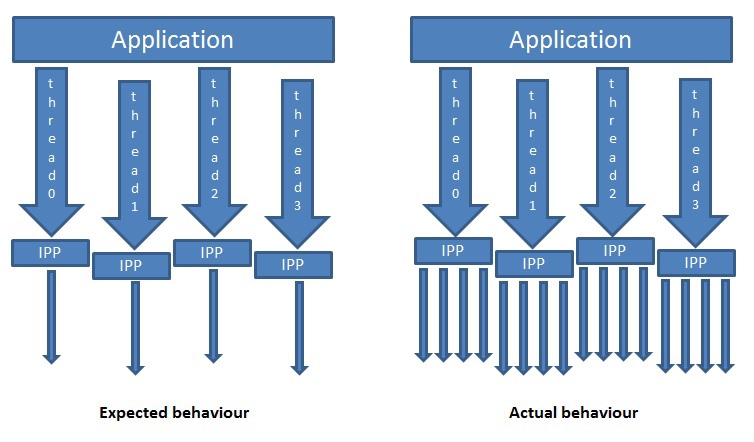
Figure 1. Two-level parallelism (nested threading)
')
Such a two-level parallelization instead of the desired acceleration can lead to a decrease in performance (in English oversubscription ), which can be explained by the fact that various parallelization tools work simultaneously and fight for queue resources, semaphores, physical flows, push competing threads from the cache, and t .P.
The user's application, in contrast to IPP, has information on how the resulting image will be processed further, and can form parallel blocks so that the data remaining in the cache is used after the previous processing stage, and not read from memory (in English cache locality ). Let us explain in more detail what is meant. IPP is mostly used in client machines - desktops, laptops, the topology of which in the general case is as follows Fig.2
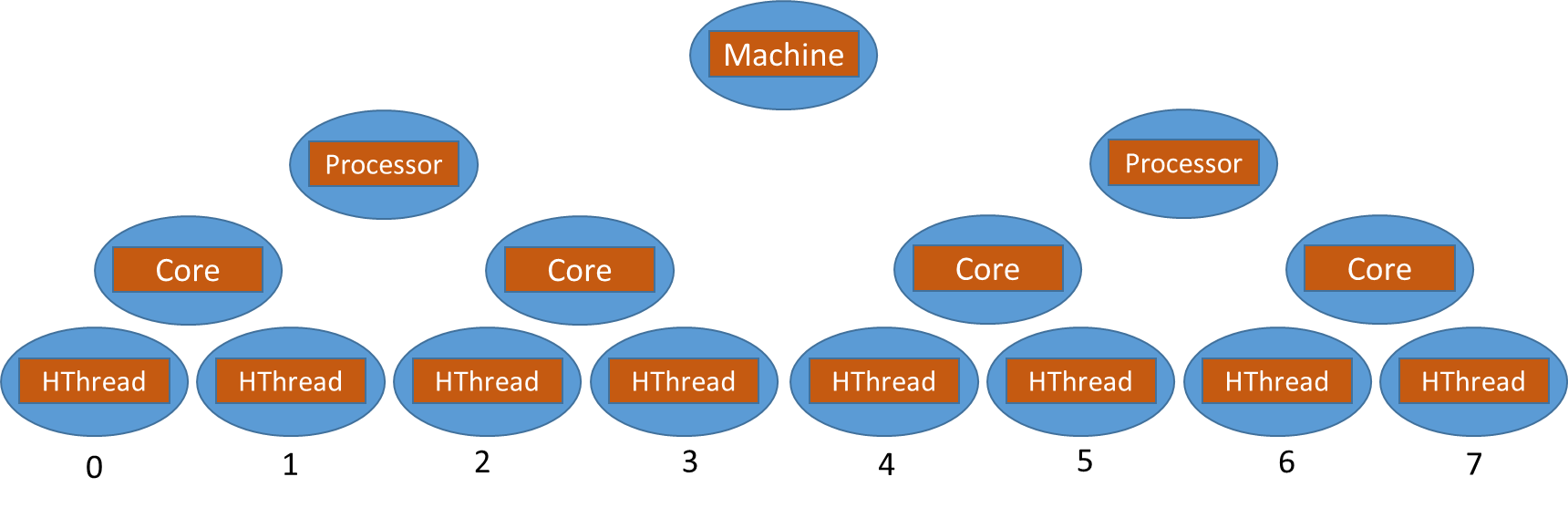
Fig. 2: Modern HW topology, HW threads numeration
IPP is also used in the HPC segment, and it is assumed that HPC systems differ from client systems only in the number of X processors. The numbering of flows in the figure is conditional and you can find out the physical number of the flow through the identifier belonging to it APIC (in English Advanced Programmable Interrupt Controller ), which is unique for each flow. The correspondence between the logical and the physical thread number is assigned by the operating system or the parallelization tool used. If you run an intensive computing task in the Windows system and watch it in the task manager, then you will notice that the system sometimes switches it from one core to another. Therefore, there is no guarantee that the flow will be executed on the same core in two consecutive parallel regions. To indicate the correspondence between a thread with a certain logical number and a physical one (in English HW thread from the word hardware ) there is a special term - affinity. When affinity is installed, the operating system will start a logical stream in consecutive parallel regions on the same HW stream. In the ideal case, a completely “clean” system specifying affinity could help solve performance problems related to the fact that logical flows are switching from one HW flow to another. However, in a real modern system hundreds and possibly thousands of processes are performed. At any time, each such process can be taken out of sleep and started on some HW thread.
Suppose that in some application the calculation volume for each stream was carefully calculated, and at the same time, in accordance with the established affinity, each application thread was launched on the corresponding HW stream. In the picture - in green.
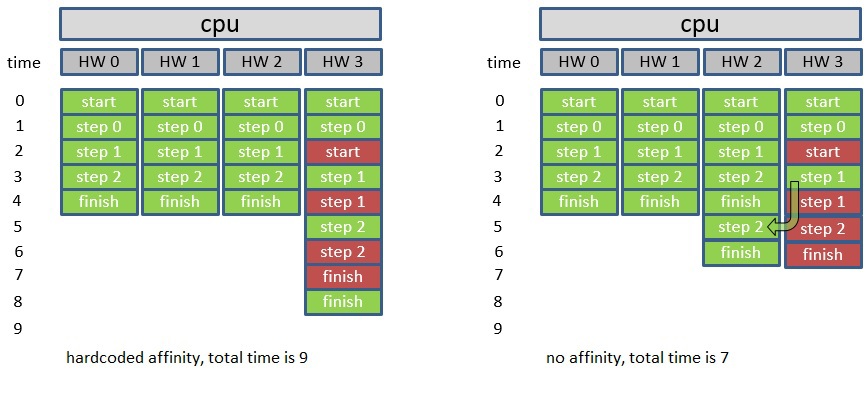
After some time, the operating system may start another process, for example, on HW stream # 3, which is shown in red. Since all threads of the first application are tightly bound to HW threads, thread # 3 will wait for resources to be released by another process, and the operating system will not be able to switch it from HW thread # 3, although threads # 0-2 may already be completed and will be idle. We consider the ideal situation, and we see that in the first case of a fixed affinity, 9 conventional units of time will be spent, and in the case where affinity is not specified, 7 units will be indicated. So, in the end, such a fixed affinity installation leads to the fact that in some cases, the performance will be high, while in others it will be very bad.
Now consider what problems may arise when affinity, on the contrary, is not installed, and the operating system can redistribute threads at its discretion. Take a simple example that implements the Sobel filter. It consists of several successive stages, each of which can be parallelized:
Apply a Sobel vertical filter to the original image and get a temporary image A (ippiFilterSobelVertBorder_8u16s_C1R)
Apply a horizontal Sobel filter to the original image and get a temporary image B (ippiFilterSobelHorizBorder_8u16s_C1R)
Calculate the square of each element A and save the result again in A (ippiSqr_16s_C1IRSfs)
Calculate the square of each element B and save the result again in B (ippiSqr_16s_C1IRSfs)
We get the sum of images A and B, we can save the result again in A (ippiAdd_16s_C1IRSfs)
The last stage is the square root of A (ippiSqrt_16u_C1IRSfs) and conversion to 8u (ippiConvert_16s8u_C1R)
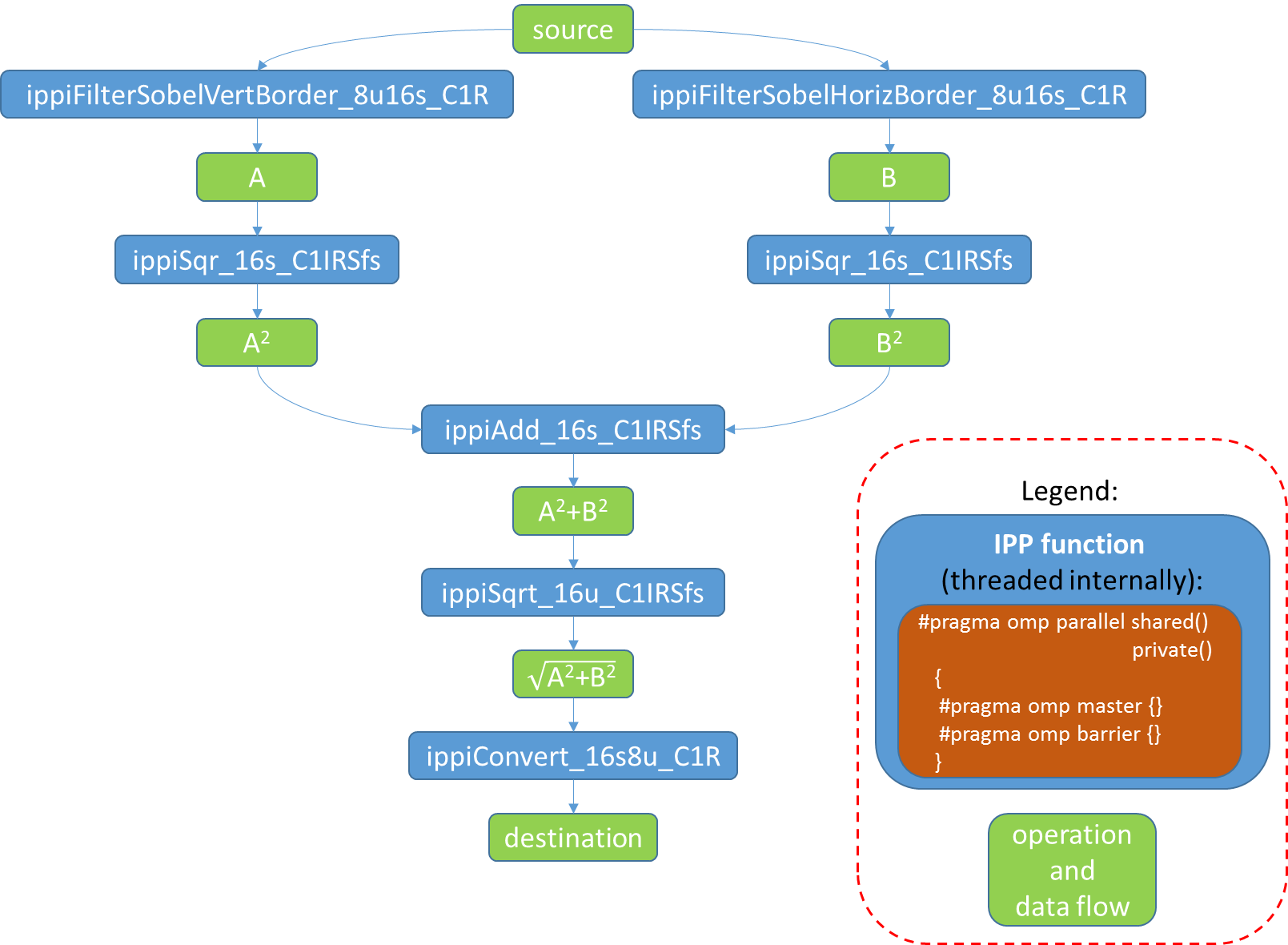
Fig. 3 Stages of the implementation of the Sobel filter, which may have internal parallelization.
Each of the internal functions can be parallelized. However, this approach seems to be inefficient, since there are 7 consecutive function calls, each of which has synchronization points for creating / terminating parallel regions. The listed IPP functions use a simple blocking pattern in a parallel region.
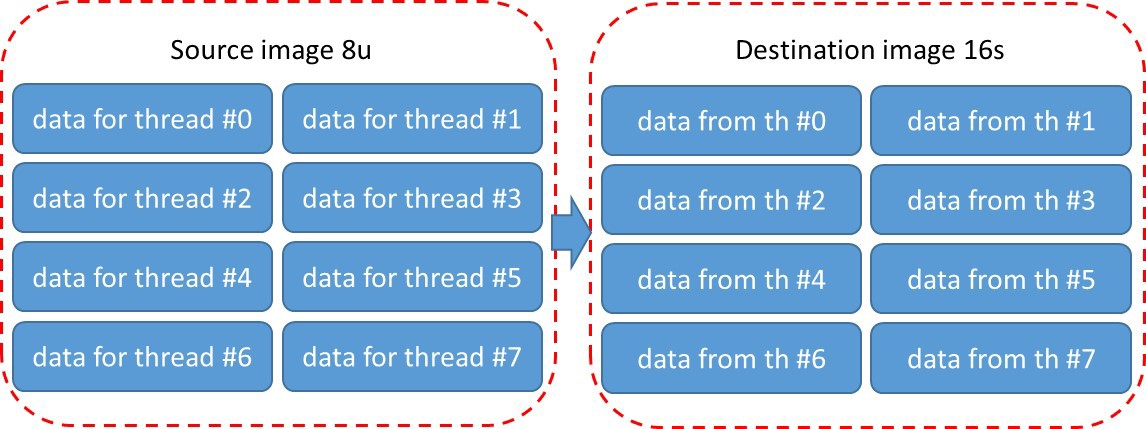
Fig. 4 Standard blocking method in IPP functions
Consider, for example, a sequential call ippiFilterSobelVertBorder_8u16s_C1R (src-> A) and ippiSqr_16s_C1IRSfs (A-> A2)). First, the first parallel region (region # 1) is created for the ippiFilterSobelVertBorder_8u16s_C1R function, then the second (region # 2).
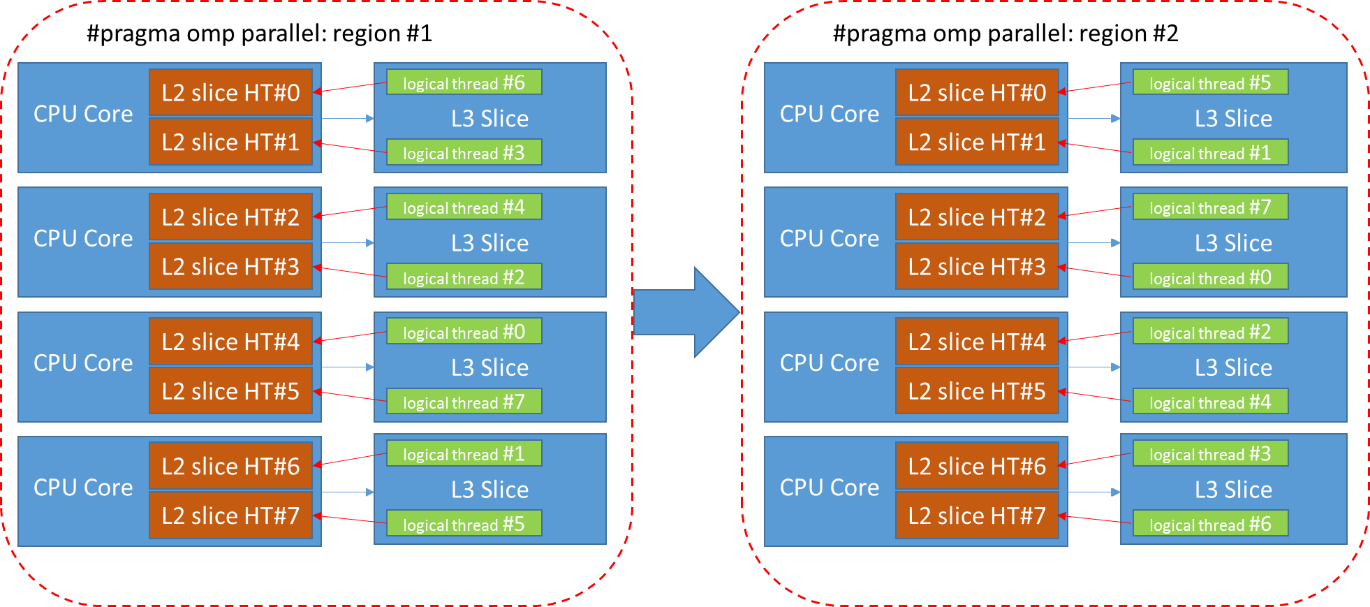
Fig. 5 Distribution of logical flows by hw flows in two consecutive parallel regions.
The logical flow # 0 will be executed on the physical flow # 4 and therefore the portion of data of the SobelVert function will be stored in the L2 and L3 caches related to the physical flow # 4. In the next parallel region # 2 created by the Sqr function, the image will be divided into blocks using the same pattern as in the first function, so the logical flow # 0 will wait for the data available in the cache. However, the OS launched this logical stream # 0 on the physical # 3. There will be no data in the cache and intensive data exchange between the caches of these threads will start, which will slow down the application execution time.
Another problem was related to the fact that before the release of IPP version 8.0 gold, users had a situation that the application and library use the same version of OpenMP, but different linking models. For example, the static version of IPP also used the OpenMP static library, and the user has a dynamic version in his application. In this case, OpenMP detects a conflict and issues a warning about possible performance degradation. In IPP 8.0, only the dynamic version of OpenMP is now used, so after switching to this version of this kind, library users should no longer have problems.
The result of the problems discussed above was that, despite the ubiquitous multi-core, functions with the new API have only the usual single-threaded implementation. However, it takes into account the possibility of image processing in parallel. However, for IPP functions that were already present in the IPP multithreaded OpenMP implementation was preserved.
The second problem of the previous version of the API appears when the image is sequentially processed by several filters. It implies that all the necessary pixels along the edges of the region of interest (abbreviated ROI from the region of interest) are available in memory. Therefore, to obtain an output image with a width of dstWidth and a height of dstHeight and a filter of size kernelWidth X kernelHeight, you must submit an input image of width dstWidth + kernelWidth-1 and height dstHeight + kernelHeight-1, fig. 6b) and 6c).
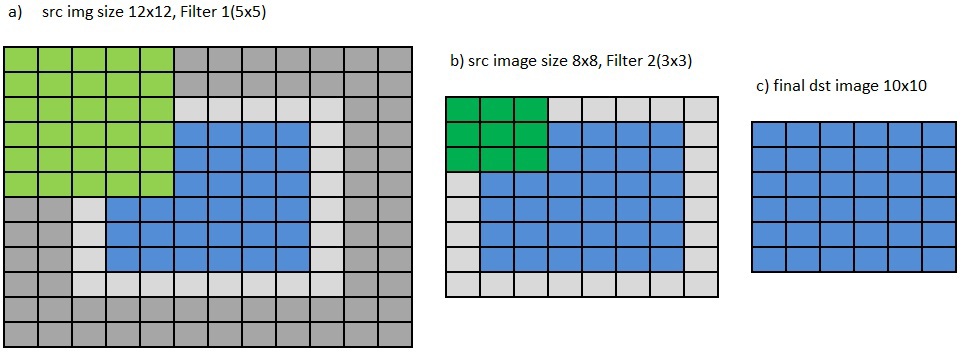
Fig.6 The need for additional rows of pixels around the ROI for the sequential application of several filters in the old API.
And if 2, .., N filters are applied in series, with the core sizes of kWidth1 X kHeight1, ..., kWidthN X kHeightN, then the size of the input image should be
(dstWidth + kWidth1 + ... + kWidthN - N) X (dstHeight + kHeight1 + ... + kHeightN-N), fig. 6a). In this example, in order to get a resulting image of 6x6 pixels in size, two filters of 5x5 and 3x3 are used. The first image has a size of 6 + 5-1 + 3-1 X 6 + 5-1 + 3-1, i.e. 12 X 12 pixels, and the image obtained after the first filter is 8x8. Applying the following 3x3 filter to it, we get the final image of 6x6. In order to create image borders, you can use the ippiCopyReplicate (Mirror / Const) Border IPP functions, but this is very costly in terms of performance and the required additional memory for a new image with a border.
The new API allows you to avoid calling such functions and provides a choice of three options for handling pixels outside of ROI — to still consider them available in memory, substitute a fixed value for them, or use a copy of the pixels lying on the border of the image. More details will be given below.
In the previous version of the API of two-dimensional filters, the reverse order of the coefficients was used according to the formula
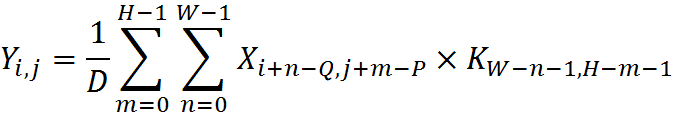
where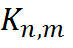 - kernel values
- kernel values
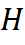 ,
, 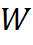 - horizontal and vertical size of the core,
- horizontal and vertical size of the core,
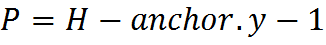 , anchor.y anchor Y coordinate,
, anchor.y anchor Y coordinate,
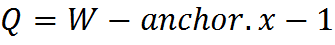 , anchor.x is the x coordinate of the anchor.
, anchor.x is the x coordinate of the anchor.
The term anchor means the position of a fixed cell inside the core, which is combined with the pixel currently being processed. Thus, using an anchor, you can specify the location of the core relative to a pixel.
In order to simplify the use of functions, the input filter coefficients are now used in direct order by the formula
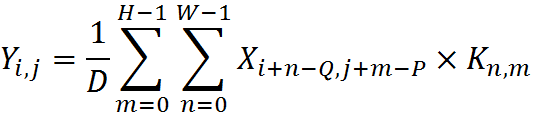
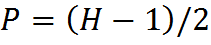 ,
,
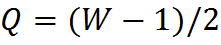 .
.
Fig. 6. demonstrates the differences between the inverse and direct order of using coefficients.
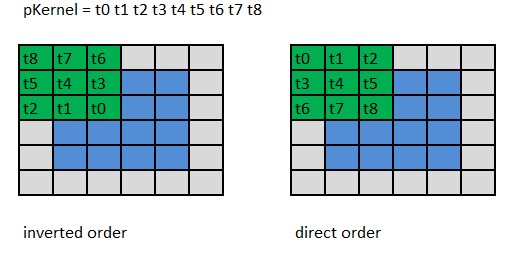
Fig. 6 Direct and inverse order of coefficients
Also in the new API, the concept of anchor (anchor) fig.7 was removed.
It is now at a fixed position Q = anchor.x = (kernelWidth-1) / 2, P = anchor.y = (kernelHeight-1) / 2.
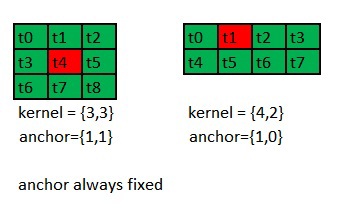
Fig. 7. The fixed position of the anchor x = (kw-1) / 2, y = (kh-1) / 2
In principle, the anchor determines the offset in memory from the pointer to the ROI, so in the new API, in the case of a “non-standard” value of the anchor, it is enough to shift the ROI in the required direction, see Fig. 8, which shows the required for different values of the anchor ROI shift in new API. The same memory area is shown in gray, and the pointer to the ROI supplied to the function is shown in blue. In the old it is unchanged, but in the new it moves.
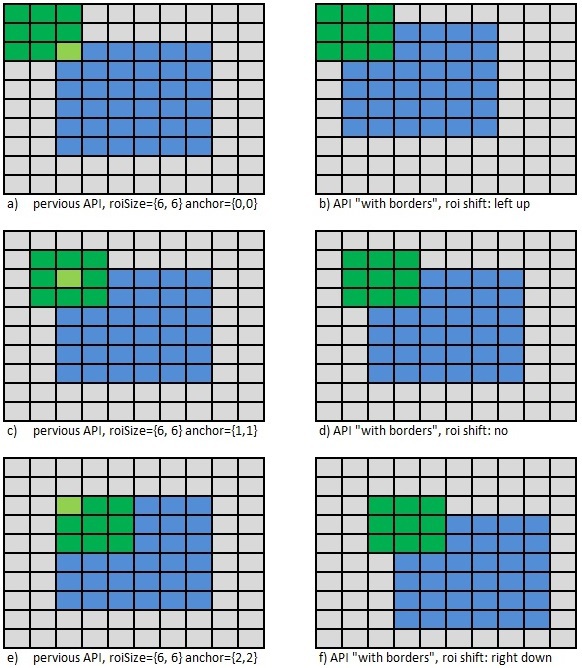
Fig. 8 ROI shift for “non-standard” armature value
For masks with an even width (height) when specifying the type of border that is in memory to the right (bottom) of the image, there should be one more rows of pixels available.
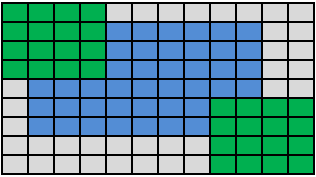
Fig. 9. For a mask with an even width (height), a row of pixels is required more to the right (bottom).
In addition to ease of use, the direct order allows you to reduce the overhead within the function associated with rearranging the coefficients. Often, the coefficients of the kernel are symmetric and such transposing was unnecessary.
Functions that have a new API do not use internal dynamic memory allocation using the malloc operation. Since the allocation of such memory in any of the streams, all other streams are stopped. The memory should now be allocated outside the processing functions, and the required size of the required buffers can be obtained using auxiliary functions of the ippiGetBufferSize type.
The use of functions with the new API will be considered on the example of the operation morphology. A detailed description of the properties of this operation can be found in the literature and on the Internet. In general terms, the result of this operation is the minimum or maximum element within a certain neighborhood of a pixel. In the first case, the operation is called Erode fig.11, in the second Dilate, fig. 12
Fig. 10 Original Image

Fig. 11 Operation Erode
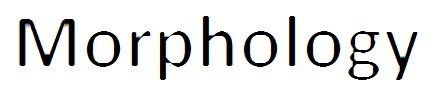
Fig. 12 Operation Dilate
At first glance, it seems that the name does not correspond to the result, however, everything is correct. Since the Erode operation selects the minimum value, and black is formed with smaller values than white, the pixels adjacent to the letters are replaced with black and the effect of thickening of the letters appears. In the case of the Dilate operation, on the contrary, the edges of the letters are replaced with white pixels and the letters become thinner.
In order to get the result in Figure 12, you must use the following functions.
The first function calculates the required size of buffers, the next initializes these buffers, and the third function performs image processing. The code snippet using these functions is as follows.
And the whole code is given in the sheet. 2
In this example, and in general, the call of all functions with the new API follows the following pattern.
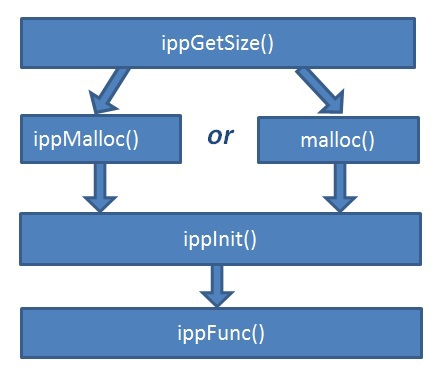
Fig. 13 General pattern of calling IPP functions
Functions that return the size of buffers contain a GetSize suffix in the name.
IppStatus ippiMorphologyBorderGetSize_32f_C1R (int roiWidth,
IppiSize (maskSize, int * pSpecSize, int * pBufferSize)
Functions can have different input parameters characterizing the operation and the image, and return the size of the internal data structure used by pSpecSize (pStateSize) and the size used by the buffer function pBufferSize.
Since the new API has eliminated the internal allocation of dynamic memory, it is necessary to use the means of the operating system malloc, new, etc. to allocate the required memory. or use the IPP functions of ippMalloc / ippiMalloc, which are convenient in that they allocate memory and image strings at an address that is optimal for the architecture used. On x86, in most cases, to increase performance, it is desirable that all arrays start at the 64-byte boundary. These IPP functions allocate memory that is aligned exactly in this way. And the ippiMalloc function also returns the step between the image lines such that the beginning of each line of the image will also be aligned.
It is possible that the application will use several IPP functions in sequence. In this case, you can select one maximum of all the largest buffer and submit it to all functions consistently, see fig. below. This approach will reduce the fragmentation of memory and, with high probability, the allocated buffer will be reused and, therefore, be in the cache.
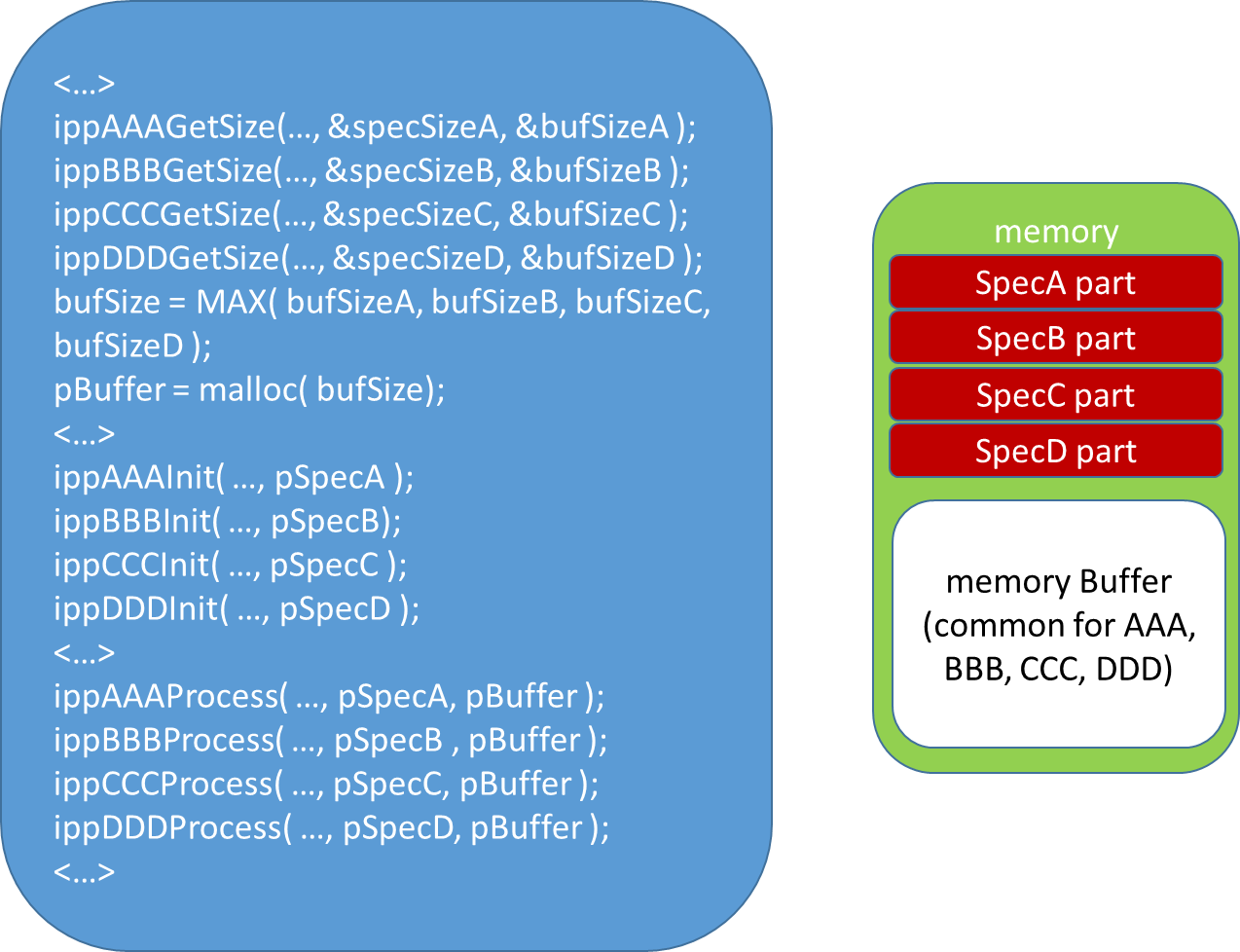
Fig. 14 Using the maximum buffer size required reduces memory fragmentation and “warms up” the buffer.
The internal structures are initialized by the functions containing the Init suffix.
IppStatus ippiMorphologyBorderInit_32f_C1R (int roiWidth,
const Ipp8u * pMask, IppiSize maskSize,
IppiMorphState * pMorphSpec, Ipp8u * pBuffer)
The internal data structure contains coefficient tables, pointers and other pre-calculated data. In IPP, the following rule is used: if the word Spec is used in the parameter name, then the contents of this structure are constant from the call to function call. Therefore, it can be used simultaneously in multiple threads. If the word State is used, this means some state, for example, a delay line in the filter and such a structure cannot be divided between streams. The contents of the pBuffer can unambiguously change, so it is necessary to allocate a separate buffer for each stream.
The directly processing functions of the new API contain the word Border in the title.
IppStatus ippiDilateBorder_32f_C1R (const Ipp32f * pSrc, int srcStep,
Ipp32f * pDst, int dstStep, IppiSize roiSize,
IppiBorderType borderType, Ipp32f borderValue,
const IppiMorphState * pMorphSpec, Ipp8u * pBuffer)
The new API uses three types of image borders.
ippBorderInMem, ippBorderConst, ippBorderRepl, see fig. 15
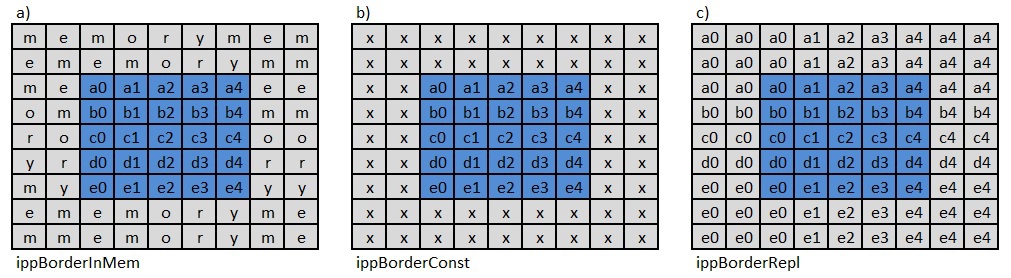
Figure 15. Three types of curb
In the first case, ippBorderInMem functions, the necessary pixels are available both inside the image and in memory. The second, ippBorderConst, uses a fixed value for borderValue. For multichannel images, an array of values is used. The formation of missing pixels in the case of ippBorderRepl is shown in fig. 15c). The angular pixels of the image are duplicated in two external sides of the angle, and the remaining boundary pixels are only in the corresponding direction from the border.
Modifiers with the following values can be applied to the specified types of borders.
These modifiers are designed to process images in blocks. They are combined with the borderType parameter using the “|” operation
The new API allows you to process images in multiple streams in blocks. To properly connect the resulting individual image blocks into a single output image, you need to apply modifiers corresponding to the position of the block to the main type of border. For example, if there are 16 streams and the ippBorderRepl border type is used, then the borderType value needs to be generated as follows. sixteen
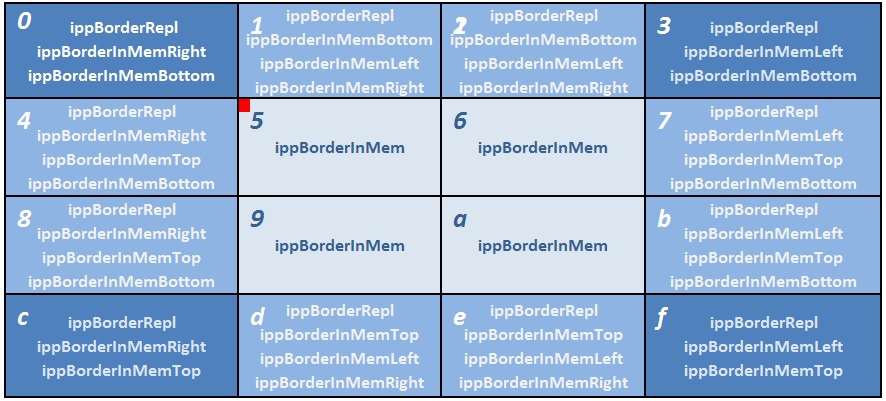
Fig. 16 Image processing in 16 streams by blocks
Block number 0 is located in the upper left of the image. Therefore, necessary for processing, but the missing pixels on the left and on the top of the block will be duplicated by the boundary ones, and the necessary pixels on the right and on the bottom of the block will be loaded from neighboring blocks 1 , 4 and 5 , in accordance with the ippBorderInMemRight | ippBorderInMemBottom modifiers. Blocks 1 , 2 do not have pixels only from above, and on the other three sides and corners are surrounded by neighboring blocks in which the right pixels lie, therefore three ippBorderInMemBottom | ippBorderInMemRight | ippBorderInMemLeft modifiers are indicated. For blocks 3,4,8,7, B, C, D, E, F modifiers are set in the same way. Blocks 5,6,9, and are inside the image and therefore you can specify all 4 modifiers for them, but it is easier to use a separate value of the ippBorderInMem border type. Returning to block number 0 , the ippBorderInMemBottom | ippBorderInMemRight modifier combination allows the function to conclude that you need to use pixels from block number 5. And for block number C, pixels from block D will be duplicated in this area, but pixels on the right and on top will be used from block 9 . All the logic of reading pixels from memory or duplicating pixels is structured in such a way that the result of image processing as a whole and in blocks completely coincides.
Also, this approach assumes that when specifying the ippBorderInMem * modifier, the memory is actually available. In some particular cases the following situation is possible, as in Figure 17

Fig.17 Going beyond the image boundary
If you divide an 1x2 image into two blocks one pixel at a time and use a 5x5 mask, then processing the left block and specifying the ippBorderInMemRight modifier for it as an ipBorderInMemRight modifier may cause the memory to go beyond the boundary with unpredictable consequences. Therefore, when dividing an image into blocks and using the ippBorderInMem modifier, you should ensure that kernelWidth / 2 pixels are in memory in the right direction.
Figure 16 depicts a general case of splitting an image into blocks for parallel processing and, generally speaking, the implementation of splitting into blocks may not be such a simple task and it is possible to more effectively divide an image not into blocks, but into bands, as shown in Figure 18 . The Border API allows this blocking.
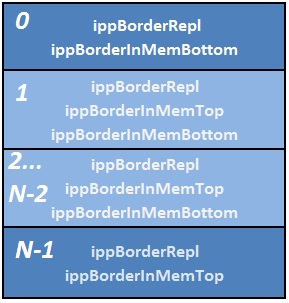
Fig. 18 Processing by strip.
Let's give an example of image processing in several streams. For this we will use OpenMP.
This example splits the image into 16 blocks according to fig. 16. The general data structure pMorphSpec is used, its position in the image is determined according to the stream identifier, after which the border modifiers are formed. Also, each thread is allocated its own buffer t_buf.
Thus, the advantages of the new API functions with a border implemented in IPP 8.0 allow users of the IPP library to solve several important problems related to image processing - you can use arbitrary parallelization tools at the application level, the size of the resulting images does not decrease, and it is also possible to process large images by breaking them into blocks.
To solve them, in IPP 8.0, many image processing functions are reduced to a common template, which allows to process images in blocks ( tiles ) and, therefore, effectively parallelize at the application level code containing calls to IPP functions. The new API of the corresponding IPP functions supports several types of borders, does not use the internal allocation of dynamic memory, allows you to divide images into fragments of arbitrary size and process these fragments independently; simplifies use and improves the performance of a number of functions. This article details the new API and provides examples of its use.
1 Reasons for switching to a new API
As mentioned above, the IPP development team did a lot of work on changing the interface of two-dimensional functions and bringing it to a single standard “API with curb support” (“new API”). What for? To answer this question, let's describe the problems that were present in previous versions.
1.1 Problems of the effectiveness of using OpenMP in IPP
So the first problem is how to use IPP in multi-threaded applications. Sometimes the problem of parallel image processing is more effectively solved at the top level, i.e. at the application level. In this case, the application itself breaks the image into blocks and creates threads for their parallel processing. The multi-threaded version of IPP uses OpenMP with nested parallelism disabled (in English nested threading ). If an application uses another tool for multithreading or even OpenMP, but a different version, then when calling an IPP function from such an application, several threads will be created in turn, as shown in Fig. one.
Figure 1. Two-level parallelism (nested threading)
')
Such a two-level parallelization instead of the desired acceleration can lead to a decrease in performance (in English oversubscription ), which can be explained by the fact that various parallelization tools work simultaneously and fight for queue resources, semaphores, physical flows, push competing threads from the cache, and t .P.
The user's application, in contrast to IPP, has information on how the resulting image will be processed further, and can form parallel blocks so that the data remaining in the cache is used after the previous processing stage, and not read from memory (in English cache locality ). Let us explain in more detail what is meant. IPP is mostly used in client machines - desktops, laptops, the topology of which in the general case is as follows Fig.2
Fig. 2: Modern HW topology, HW threads numeration
IPP is also used in the HPC segment, and it is assumed that HPC systems differ from client systems only in the number of X processors. The numbering of flows in the figure is conditional and you can find out the physical number of the flow through the identifier belonging to it APIC (in English Advanced Programmable Interrupt Controller ), which is unique for each flow. The correspondence between the logical and the physical thread number is assigned by the operating system or the parallelization tool used. If you run an intensive computing task in the Windows system and watch it in the task manager, then you will notice that the system sometimes switches it from one core to another. Therefore, there is no guarantee that the flow will be executed on the same core in two consecutive parallel regions. To indicate the correspondence between a thread with a certain logical number and a physical one (in English HW thread from the word hardware ) there is a special term - affinity. When affinity is installed, the operating system will start a logical stream in consecutive parallel regions on the same HW stream. In the ideal case, a completely “clean” system specifying affinity could help solve performance problems related to the fact that logical flows are switching from one HW flow to another. However, in a real modern system hundreds and possibly thousands of processes are performed. At any time, each such process can be taken out of sleep and started on some HW thread.
Suppose that in some application the calculation volume for each stream was carefully calculated, and at the same time, in accordance with the established affinity, each application thread was launched on the corresponding HW stream. In the picture - in green.
After some time, the operating system may start another process, for example, on HW stream # 3, which is shown in red. Since all threads of the first application are tightly bound to HW threads, thread # 3 will wait for resources to be released by another process, and the operating system will not be able to switch it from HW thread # 3, although threads # 0-2 may already be completed and will be idle. We consider the ideal situation, and we see that in the first case of a fixed affinity, 9 conventional units of time will be spent, and in the case where affinity is not specified, 7 units will be indicated. So, in the end, such a fixed affinity installation leads to the fact that in some cases, the performance will be high, while in others it will be very bad.
Now consider what problems may arise when affinity, on the contrary, is not installed, and the operating system can redistribute threads at its discretion. Take a simple example that implements the Sobel filter. It consists of several successive stages, each of which can be parallelized:
Apply a Sobel vertical filter to the original image and get a temporary image A (ippiFilterSobelVertBorder_8u16s_C1R)
Apply a horizontal Sobel filter to the original image and get a temporary image B (ippiFilterSobelHorizBorder_8u16s_C1R)
Calculate the square of each element A and save the result again in A (ippiSqr_16s_C1IRSfs)
Calculate the square of each element B and save the result again in B (ippiSqr_16s_C1IRSfs)
We get the sum of images A and B, we can save the result again in A (ippiAdd_16s_C1IRSfs)
The last stage is the square root of A (ippiSqrt_16u_C1IRSfs) and conversion to 8u (ippiConvert_16s8u_C1R)
Fig. 3 Stages of the implementation of the Sobel filter, which may have internal parallelization.
Each of the internal functions can be parallelized. However, this approach seems to be inefficient, since there are 7 consecutive function calls, each of which has synchronization points for creating / terminating parallel regions. The listed IPP functions use a simple blocking pattern in a parallel region.
Fig. 4 Standard blocking method in IPP functions
Consider, for example, a sequential call ippiFilterSobelVertBorder_8u16s_C1R (src-> A) and ippiSqr_16s_C1IRSfs (A-> A2)). First, the first parallel region (region # 1) is created for the ippiFilterSobelVertBorder_8u16s_C1R function, then the second (region # 2).
Fig. 5 Distribution of logical flows by hw flows in two consecutive parallel regions.
The logical flow # 0 will be executed on the physical flow # 4 and therefore the portion of data of the SobelVert function will be stored in the L2 and L3 caches related to the physical flow # 4. In the next parallel region # 2 created by the Sqr function, the image will be divided into blocks using the same pattern as in the first function, so the logical flow # 0 will wait for the data available in the cache. However, the OS launched this logical stream # 0 on the physical # 3. There will be no data in the cache and intensive data exchange between the caches of these threads will start, which will slow down the application execution time.
Another problem was related to the fact that before the release of IPP version 8.0 gold, users had a situation that the application and library use the same version of OpenMP, but different linking models. For example, the static version of IPP also used the OpenMP static library, and the user has a dynamic version in his application. In this case, OpenMP detects a conflict and issues a warning about possible performance degradation. In IPP 8.0, only the dynamic version of OpenMP is now used, so after switching to this version of this kind, library users should no longer have problems.
The result of the problems discussed above was that, despite the ubiquitous multi-core, functions with the new API have only the usual single-threaded implementation. However, it takes into account the possibility of image processing in parallel. However, for IPP functions that were already present in the IPP multithreaded OpenMP implementation was preserved.
1.2 Border problems in sequential image processing
The second problem of the previous version of the API appears when the image is sequentially processed by several filters. It implies that all the necessary pixels along the edges of the region of interest (abbreviated ROI from the region of interest) are available in memory. Therefore, to obtain an output image with a width of dstWidth and a height of dstHeight and a filter of size kernelWidth X kernelHeight, you must submit an input image of width dstWidth + kernelWidth-1 and height dstHeight + kernelHeight-1, fig. 6b) and 6c).
Fig.6 The need for additional rows of pixels around the ROI for the sequential application of several filters in the old API.
And if 2, .., N filters are applied in series, with the core sizes of kWidth1 X kHeight1, ..., kWidthN X kHeightN, then the size of the input image should be
(dstWidth + kWidth1 + ... + kWidthN - N) X (dstHeight + kHeight1 + ... + kHeightN-N), fig. 6a). In this example, in order to get a resulting image of 6x6 pixels in size, two filters of 5x5 and 3x3 are used. The first image has a size of 6 + 5-1 + 3-1 X 6 + 5-1 + 3-1, i.e. 12 X 12 pixels, and the image obtained after the first filter is 8x8. Applying the following 3x3 filter to it, we get the final image of 6x6. In order to create image borders, you can use the ippiCopyReplicate (Mirror / Const) Border IPP functions, but this is very costly in terms of performance and the required additional memory for a new image with a border.
The new API allows you to avoid calling such functions and provides a choice of three options for handling pixels outside of ROI — to still consider them available in memory, substitute a fixed value for them, or use a copy of the pixels lying on the border of the image. More details will be given below.
1.3 Direct order of filter coefficients and fixed anchor
In the previous version of the API of two-dimensional filters, the reverse order of the coefficients was used according to the formula
where
- kernel values , - horizontal and vertical size of the core, , anchor.y anchor Y coordinate, , anchor.x is the x coordinate of the anchor.The term anchor means the position of a fixed cell inside the core, which is combined with the pixel currently being processed. Thus, using an anchor, you can specify the location of the core relative to a pixel.
In order to simplify the use of functions, the input filter coefficients are now used in direct order by the formula
, .Fig. 6. demonstrates the differences between the inverse and direct order of using coefficients.
Fig. 6 Direct and inverse order of coefficients
Also in the new API, the concept of anchor (anchor) fig.7 was removed.
It is now at a fixed position Q = anchor.x = (kernelWidth-1) / 2, P = anchor.y = (kernelHeight-1) / 2.
Fig. 7. The fixed position of the anchor x = (kw-1) / 2, y = (kh-1) / 2
In principle, the anchor determines the offset in memory from the pointer to the ROI, so in the new API, in the case of a “non-standard” value of the anchor, it is enough to shift the ROI in the required direction, see Fig. 8, which shows the required for different values of the anchor ROI shift in new API. The same memory area is shown in gray, and the pointer to the ROI supplied to the function is shown in blue. In the old it is unchanged, but in the new it moves.
Fig. 8 ROI shift for “non-standard” armature value
For masks with an even width (height) when specifying the type of border that is in memory to the right (bottom) of the image, there should be one more rows of pixels available.
Fig. 9. For a mask with an even width (height), a row of pixels is required more to the right (bottom).
In addition to ease of use, the direct order allows you to reduce the overhead within the function associated with rearranging the coefficients. Often, the coefficients of the kernel are symmetric and such transposing was unnecessary.
1.4 Lack of internal allocation of dynamic memory
Functions that have a new API do not use internal dynamic memory allocation using the malloc operation. Since the allocation of such memory in any of the streams, all other streams are stopped. The memory should now be allocated outside the processing functions, and the required size of the required buffers can be obtained using auxiliary functions of the ippiGetBufferSize type.
2 Operation of morphology of images by Erode / Dilate
The use of functions with the new API will be considered on the example of the operation morphology. A detailed description of the properties of this operation can be found in the literature and on the Internet. In general terms, the result of this operation is the minimum or maximum element within a certain neighborhood of a pixel. In the first case, the operation is called Erode fig.11, in the second Dilate, fig. 12
Fig. 10 Original Image
Fig. 11 Operation Erode
Fig. 12 Operation Dilate
At first glance, it seems that the name does not correspond to the result, however, everything is correct. Since the Erode operation selects the minimum value, and black is formed with smaller values than white, the pixels adjacent to the letters are replaced with black and the effect of thickening of the letters appears. In the case of the Dilate operation, on the contrary, the edges of the letters are replaced with white pixels and the letters become thinner.
3 General principles of the new API functions with border support
3.1 Example code for morphology operation - Dilate
In order to get the result in Figure 12, you must use the following functions.
- IppStatus ippiMorphologyBorderGetSize_32f_C1R (int roiWidth, IppiSize maskSize, int * pSpecSize, int * pBufferSize)
- IppStatus ippiMorphologyBorderInit_32f_C1R (int roiWidth, const Ipp8u * pMask, IppiSize maskSize, IppiMorphState * pMorphSpec, Ipp8u * pBuffer)
- IppStatus ippiDilateBorder_32f_C1R (const
The first function calculates the required size of buffers, the next initializes these buffers, and the third function performs image processing. The code snippet using these functions is as follows.
Sheet. 1 standard function call sequence
ippiMorphologyBorderGetSize_32f_C1R(roiSize.width, maskSize, &specSize, &bufferSize); pMorphSpec = (IppiMorphState*)ippsMalloc_8u(specSize); pBuffer = (Ipp8u*)ippsMalloc_8u(bufferSize); ippiMorphologyBorderInit_32f_C1R(roiSize.width, pMask, maskSize, pMorphSpec, pBuffer); ippiDilateBorder_32f_C1R(pSrc, srcStep, pDst, dstStep, roiSize, border, borderValue, pMorphSpec, pBuffer); And the whole code is given in the sheet. 2
Sheet. 2 Image processing code
#define WIDTH 128 #define HEIGHT 128 int morph_dilate_st() { IppiSize roiSize = { WIDTH, HEIGHT }; IppiSize maskSize = { 3, 3 }; IppStatus status; int specSize = 0, bufferSize = 0; IppiMorphState* pMorphSpec; Ipp8u* pBuffer; Ipp32f* pSrc; Ipp32f* pDst; int srcStep, dstStep; Ipp8u pMask[3 * 3] = { 1, 1, 1, 1, 1, 1, 1, 1, 1 }; IppiBorderType border = ippBorderRepl; int borderValue = 0; int i, j; pSrc = ippiMalloc_32f_C1(WIDTH, HEIGHT, &srcStep); pDst = ippiMalloc_32f_C1(WIDTH, HEIGHT, &dstStep); for (j = 0; j<HEIGHT; j++){ for (i = 0; i<WIDTH; i++){ pSrc[WIDTH*j + i] = rand();//make image } } status = ippiMorphologyBorderGetSize_32f_C1R(roiSize.width, maskSize, &specSize, &bufferSize); if (status != ippStsOk){ printf("ippiMorphologyBorderGetSize_32f_C1R / %s\n", ippGetStatusString(status)); return -1; } pMorphSpec = (IppiMorphState*)ippsMalloc_8u(specSize); pBuffer = (Ipp8u*)ippsMalloc_8u(bufferSize); status = ippiMorphologyBorderInit_32f_C1R(roiSize.width, pMask, maskSize, pMorphSpec, pBuffer); if (status != ippStsOk){ printf("ippiMorphologyBorderInit_32f_C1R / %s\n", ippGetStatusString(status)); ippsFree(pMorphSpec); ippsFree(pBuffer); return -1; } status = ippiDilateBorder_32f_C1R(pSrc, srcStep, pDst, dstStep, roiSize, border, borderValue, pMorphSpec, pBuffer); if (status != ippStsOk){ printf("ippiMorphologyBorderGetSize_32f_C1R / %s\n", ippGetStatusString(status)); ippsFree(pMorphSpec); ippsFree(pBuffer); return -1; } ippsFree(pMorphSpec); ippsFree(pBuffer); ippiFree(pSrc); ippiFree(pDst); return 0; } 3.2 Common Border API Template
In this example, and in general, the call of all functions with the new API follows the following pattern.
Fig. 13 General pattern of calling IPP functions
3.3 ippGetSize — calculate buffer sizes
Functions that return the size of buffers contain a GetSize suffix in the name.
IppStatus ippiMorphologyBorderGetSize_32f_C1R (int roiWidth,
IppiSize (maskSize, int * pSpecSize, int * pBufferSize)
Functions can have different input parameters characterizing the operation and the image, and return the size of the internal data structure used by pSpecSize (pStateSize) and the size used by the buffer function pBufferSize.
Since the new API has eliminated the internal allocation of dynamic memory, it is necessary to use the means of the operating system malloc, new, etc. to allocate the required memory. or use the IPP functions of ippMalloc / ippiMalloc, which are convenient in that they allocate memory and image strings at an address that is optimal for the architecture used. On x86, in most cases, to increase performance, it is desirable that all arrays start at the 64-byte boundary. These IPP functions allocate memory that is aligned exactly in this way. And the ippiMalloc function also returns the step between the image lines such that the beginning of each line of the image will also be aligned.
It is possible that the application will use several IPP functions in sequence. In this case, you can select one maximum of all the largest buffer and submit it to all functions consistently, see fig. below. This approach will reduce the fragmentation of memory and, with high probability, the allocated buffer will be reused and, therefore, be in the cache.
Fig. 14 Using the maximum buffer size required reduces memory fragmentation and “warms up” the buffer.
3.4 ippInit - initialization of the internal structure
The internal structures are initialized by the functions containing the Init suffix.
IppStatus ippiMorphologyBorderInit_32f_C1R (int roiWidth,
const Ipp8u * pMask, IppiSize maskSize,
IppiMorphState * pMorphSpec, Ipp8u * pBuffer)
The internal data structure contains coefficient tables, pointers and other pre-calculated data. In IPP, the following rule is used: if the word Spec is used in the parameter name, then the contents of this structure are constant from the call to function call. Therefore, it can be used simultaneously in multiple threads. If the word State is used, this means some state, for example, a delay line in the filter and such a structure cannot be divided between streams. The contents of the pBuffer can unambiguously change, so it is necessary to allocate a separate buffer for each stream.
3.5 ippFuncBorder - processing function
The directly processing functions of the new API contain the word Border in the title.
IppStatus ippiDilateBorder_32f_C1R (const Ipp32f * pSrc, int srcStep,
Ipp32f * pDst, int dstStep, IppiSize roiSize,
IppiBorderType borderType, Ipp32f borderValue,
const IppiMorphState * pMorphSpec, Ipp8u * pBuffer)
3.6 Supported Border Types
The new API uses three types of image borders.
ippBorderInMem, ippBorderConst, ippBorderRepl, see fig. 15
Figure 15. Three types of curb
In the first case, ippBorderInMem functions, the necessary pixels are available both inside the image and in memory. The second, ippBorderConst, uses a fixed value for borderValue. For multichannel images, an array of values is used. The formation of missing pixels in the case of ippBorderRepl is shown in fig. 15c). The angular pixels of the image are duplicated in two external sides of the angle, and the remaining boundary pixels are only in the corresponding direction from the border.
Modifiers with the following values can be applied to the specified types of borders.
ippBorderInMemTop = 0x0010, ippBorderInMemBottom = 0x0020, ippBorderInMemLeft = 0x0040, ippBorderInMemRight = 0x0080 These modifiers are designed to process images in blocks. They are combined with the borderType parameter using the “|” operation
4. Using API functions with support for borders for external parallelization of functions.
4.1 Image splitting into blocks
The new API allows you to process images in multiple streams in blocks. To properly connect the resulting individual image blocks into a single output image, you need to apply modifiers corresponding to the position of the block to the main type of border. For example, if there are 16 streams and the ippBorderRepl border type is used, then the borderType value needs to be generated as follows. sixteen
Fig. 16 Image processing in 16 streams by blocks
Block number 0 is located in the upper left of the image. Therefore, necessary for processing, but the missing pixels on the left and on the top of the block will be duplicated by the boundary ones, and the necessary pixels on the right and on the bottom of the block will be loaded from neighboring blocks 1 , 4 and 5 , in accordance with the ippBorderInMemRight | ippBorderInMemBottom modifiers. Blocks 1 , 2 do not have pixels only from above, and on the other three sides and corners are surrounded by neighboring blocks in which the right pixels lie, therefore three ippBorderInMemBottom | ippBorderInMemRight | ippBorderInMemLeft modifiers are indicated. For blocks 3,4,8,7, B, C, D, E, F modifiers are set in the same way. Blocks 5,6,9, and are inside the image and therefore you can specify all 4 modifiers for them, but it is easier to use a separate value of the ippBorderInMem border type. Returning to block number 0 , the ippBorderInMemBottom | ippBorderInMemRight modifier combination allows the function to conclude that you need to use pixels from block number 5. And for block number C, pixels from block D will be duplicated in this area, but pixels on the right and on top will be used from block 9 . All the logic of reading pixels from memory or duplicating pixels is structured in such a way that the result of image processing as a whole and in blocks completely coincides.
Also, this approach assumes that when specifying the ippBorderInMem * modifier, the memory is actually available. In some particular cases the following situation is possible, as in Figure 17
Fig.17 Going beyond the image boundary
If you divide an 1x2 image into two blocks one pixel at a time and use a 5x5 mask, then processing the left block and specifying the ippBorderInMemRight modifier for it as an ipBorderInMemRight modifier may cause the memory to go beyond the boundary with unpredictable consequences. Therefore, when dividing an image into blocks and using the ippBorderInMem modifier, you should ensure that kernelWidth / 2 pixels are in memory in the right direction.
4.2 Splitting an image into stripes
Figure 16 depicts a general case of splitting an image into blocks for parallel processing and, generally speaking, the implementation of splitting into blocks may not be such a simple task and it is possible to more effectively divide an image not into blocks, but into bands, as shown in Figure 18 . The Border API allows this blocking.
Fig. 18 Processing by strip.
4.3 Sample code with a new API for processing in several OpenMP streams
Let's give an example of image processing in several streams. For this we will use OpenMP.
Sheet. 3 Image processing code by block
#define WIDTH 128 #define HEIGHT 128 int morph_dilate_omp() { IppiSize roiSize = { WIDTH, HEIGHT }; IppiSize maskSize = { 3, 3 }; IppStatus status; int specSize = 0, bufferSize = 0; IppiMorphState* pMorphSpec; Ipp8u* pBuffer; Ipp32f *pSrc, *pDst; int srcStep, dstStep; Ipp8u pMask[3 * 3] = { 1, 1, 1, 1, 1, 1, 1, 1, 1 }; IppiBorderType border = ippBorderRepl; int borderValue = 0; int nThreads = 16; int i, j; /*allocate memory*/ pSrc = ippiMalloc_32f_C1(WIDTH, HEIGHT, &srcStep); pDst = ippiMalloc_32f_C1(WIDTH, HEIGHT, &dstStep); /*fill image*/ for (j = 0; j<HEIGHT; j++){ for (i = 0; i<WIDTH; i++){ pSrc[WIDTH*j + i] = rand(); } } /*get sizes of spec and buffer */ ippiMorphologyBorderGetSize_32f_C1R(roiSize.width, maskSize, &specSize, &bufferSize); /*allocate spec. It will be shared between all threads.*/ pMorphSpec = (IppiMorphState*)ippsMalloc_8u(specSize); /*allocate individual buffers for every thread*/ pBuffer = (Ipp8u*)ippsMalloc_8u(bufferSize * nThreads); /*initialize spec*/ ippiMorphologyBorderInit_32f_C1R(roiSize.width, pMask, maskSize, pMorphSpec, pBuffer); /*set number of threads*/ omp_set_num_threads(nThreads); { int t_w, t_wt, /*width and height per one block(thread)*/ t_h, t_ht; /*tails for last threads */ #pragma omp parallel { #pragma omp master { nThreads = omp_get_num_threads(); t_w = roiSize.width / 4; /*calculate blocks WxH*/ t_wt = roiSize.width % 4; t_h = roiSize.height / 4; t_ht = roiSize.height % 4; } #pragma omp barrier { int t_id, /* id of thread*/ t_x, t_y; /*x and y position of block*/ IppiSize t_roi; Ipp32f* t_src; Ipp32f* t_dst; Ipp8u* t_buf; IppiBorderType t_bor = ippBorderRepl; t_id = omp_get_thread_num(); t_roi.width = t_w; t_roi.height = t_h; t_x = t_id & 3; /*get x and y for block.*/ t_y = t_id >> 2; /* image splitted at 4x4 blocks*/ if (t_x == 3) t_roi.width += t_wt; if (t_y == 3) t_roi.height += t_ht; if (t_x > 0) t_bor |= ippBorderInMemLeft; /*analyze block position*/ if (t_x < 3) t_bor |= ippBorderInMemRight; /*and set InMem* modifier*/ if (t_y > 0) t_bor |= ippBorderInMemTop; if (t_y < 3) t_bor |= ippBorderInMemBottom; if (t_x > 0 && t_x < 3 && t_y > 0 && t_y < 3) t_bor = ippBorderInMem; /*internal block*/ t_src = (Ipp8u*)pSrc + t_y * t_h * srcStep + t_x * t_w*sizeof(Ipp32f); /*get offset of source and dest for block */ t_dst = (Ipp8u*)pDst + t_y * t_h * dstStep + t_x * t_w*sizeof(Ipp32f); /*using x and y of block*/ t_buf = pBuffer + t_id * bufferSize; /*every thread uses own buffer*/ ippiDilateBorder_32f_C1R(t_src, srcStep, t_dst, dstStep, t_roi,t_bor, borderValue, pMorphSpec, t_buf); } } } } This example splits the image into 16 blocks according to fig. 16. The general data structure pMorphSpec is used, its position in the image is determined according to the stream identifier, after which the border modifiers are formed. Also, each thread is allocated its own buffer t_buf.
5. Conclusion
Thus, the advantages of the new API functions with a border implemented in IPP 8.0 allow users of the IPP library to solve several important problems related to image processing - you can use arbitrary parallelization tools at the application level, the size of the resulting images does not decrease, and it is also possible to process large images by breaking them into blocks.
Source: https://habr.com/ru/post/255931/
All Articles