Review of QCon London 2015 conference reports
 Hi, my name is Max Matyukhin, I am a PHP programmer at Badoo. Last month, the next QCon 2015 International Developers Conference was held in London. I visited it and now I want to share with you my impressions of the event and talk about the most interesting, in my opinion, speeches. In this article, you'll learn a little more about the architecture of Uber, Spotify, CloudFlare, as well as how Google manages its infrastructure and much more.
Hi, my name is Max Matyukhin, I am a PHP programmer at Badoo. Last month, the next QCon 2015 International Developers Conference was held in London. I visited it and now I want to share with you my impressions of the event and talk about the most interesting, in my opinion, speeches. In this article, you'll learn a little more about the architecture of Uber, Spotify, CloudFlare, as well as how Google manages its infrastructure and much more.For the first time QCon was held in 2007 in London and San Francisco. Since then, it has steadily been gaining popularity and expanding geography, and this year it will be held in 8 cities. London QCon takes place in the heart of the British capital, a stone’s throw from Westminster Abbey. At various times, such famous personalities as Martin Fowler, Kent Beck, Erik Meijer, Steve Vinoski, Joe Armstrong, Rich Hickey and many others spoke at QCon.
This year the conference lasted 3 days, 5-7 simultaneous sections were held every day. Almost all the reports were filmed and then were available to all conference participants. Within 6 months, these entries will be made publicly available on the infoq.com website.
One of the distinguishing features of QCon is the so-called open spaces. In each section, at a certain time, there is an open space, where anyone can come and ask questions to other participants on the topic of the section or suggest a discussion of any issue within its framework.
As for the reports, I will tell only about those that I saw live and which I really liked. I will describe them in chronological order and intentionally will not disclose all the details so that you would be interested to watch and video.
Reports Day 1
To the moon
The conference was opened by Russ Olsen, vice president of Cognitect, with the report “To the Moon”.
It was not even a report, but simply an interesting story about how the Americans flew to the moon. During the Cold War, the Russians achieved impressive achievements in space: they launched the first satellite, sent the first man into space, took the first photograph of the far side of the moon. And everyone was waiting for a response from America. After some time, John F. Kennedy spoke to the US Congress with a plan for landing a man on the moon and returning him home safe and sound.
Further, the author spoke about how the Americans worked on this program, about the process of landing on the moon, about the problems that have arisen. Then it was about working on the bugs, about the causes of each of the problems that could not only disrupt the execution of the task, but also threatened the life of the crew.
It turned out a good motivational report that the impossible does not exist.
Video of this report is already available: http://www.infoq.com/presentations/moon-software
')
Treat your Code as a Crime Scene (Adam Tornhill)
The description of the report says that the author has an education in the field of psychology and programming, therefore he uses some approaches of traditional and forensic psychology to find problem areas in the code. The author argues that programming can take a lot of psychology, because it includes not only writing code, but also people who make decisions, correct mistakes, communicate with each other.
Most of the time, programmers do not write code, but study existing ones and make changes to it, so they should take care that their code is easy to understand.
Further, after some educational campaign about the behavior of criminals, the author proceeded to the description of the CodeCity utility http://www.inf.usi.ch/phd/wettel/codecity.html . This program visualizes your code as a virtual city in which each module or class is a building. The more complex the class, the larger the building. But the complexity of the code itself is not a problem. Until you need to change this code. Therefore, if we apply the change rate of each module to the CodeCity results, then we will be able to see the complex modules that we often have to change. Refactoring these particular modules is the most appropriate.
Another interesting code analysis technique is called Temporal Coupling Analysis. Imagine that you have 2 modules that are clearly not related to each other. But if you look at the history of their commits, you can see that very often they change together. If the modules are not really interconnected, then this behavior may indicate the presence of copy-paste-code in both modules.
I will not retell the report completely - it’s better to see it once. In general, the author gives interesting, though obvious ideas. In most cases, it simply analyzes various statistical indicators of the code and history of commits and then correctly visualizes the statistics obtained.
A Taste of Random Decision Forests on Apache Spark (Sean Owen)
Slides
The report is a short seminar on the use of machine learning algorithms on the Apache Spark platform.
I went to this report to hear about Spark, and in this regard, the report disappointed me. About Spark in the report was literally a couple of examples: reading a dataset and using MLLib to build a Decision Tree and Random Decision Tree are basic things. But for those who are only taking the first steps in Machine Learning and want to get a good example of how to use Spark and MLLib for classification tasks, the report will be quite useful.
The author took this dataset https://archive.ics.uci.edu/ml/datasets/Covertype , which contains data on areas in the Colorado forests (30 m² each): slope, height above sea level, soil type, forest type cover, etc.
Having these data, the author first built a decision tree (Decision Tree), which would learn to determine the type of forest cover by the main parameters - this is a typical task of classification in machine learning (Machine Learning). Then the author constantly made changes to the constructed decision tree in order to improve the quality of classification (the accuracy with which the classifier determines the type of forest cover according to the transmitted parameters).
At some point, the author switched from the Decision Tree algorithm to the Random decision forests algorithm, which gave better results on his data.
The report may be useful for beginners as a simple example of how modern Data Science specialists work. Although, in my opinion, the author forgot to talk about the problem of retraining (Overfitting).
Beating the traffic jam using embedded devices, OPC-UA, Akka and NoSQL (Kristoffer Dyrkorn)
Slides
The author works for a government agency in Norway that deals with the planning, construction, maintenance and repair of roads. The goal of his project is to collect real-time traffic and traffic statistics in Norway.
The construction and maintenance of roads in Norway is very expensive. For example, in 2013, 4.1 billion euros was spent on the roads. This is due to the harsh Norwegian climate, salt road treatment in winter, sea waves and even bird droppings. And, of course, the traffic itself.
The system consists of many (more than 5000) sensors standing on the roads. They collect information about passing cars, save it to a local disk and send it to a central server using 3G. The number of sensors is constantly growing, respectively, and the volume of stored data, and the load on the server are growing.
Despite the fact that 3G is considered a reliable technology, the sensors quite often lose touch with the server, so the system is written taking into account possible network problems. It is also possible from the server to request all data from the sensor.
The server part is written in Java. Its main task is to receive data from sensors. There is also a REST API for the GUI, through which you can manage the system and add new sensors. A reporting system is provided.
For convenience and flexibility, all data is stored in raw format, without prior aggregation. At the moment, the system is only “run-in” and no one yet knows exactly which reports will be needed. The system operates in three data centers.
Project authors use ElasticSearch as the main data repository. They know that they are not advised to do this, read the results of the Jepsen-test for ElasticSearch and know that he may lose data if netsplit occurs, but in reality the data have not yet been lost.
Later, the author of the report was asked why he was sure that they did not lose data. To this he replied that each sensor, sending a new event, sends a new ID with auto_increment, and it seems they didn’t find any gaps with lost IDs when checking.
The evolution of architecture:
1. Moving from Play to Embedded Jetty + Akka.
2. Switch from MongoDB to ElasticSearch.
3. Transition from one data center to three.
In general, the report was very competent; the scope of the project is impressive, and how much Norway spends on roads.
I really wanted more details about Akka, but the author only said that they were very pleased with its implementation, without any details.
Reports Day # 2
Cluster management at Google (John Wilkes)
Slides
The report began with the question: “Are there people in the hall who used at least one Google service?” :)
The author of the report works in the Infrastructure Team. The goal of this team is to enable Google programmers to launch their Google data center applications.
The screenshot below shows the configuration for running a simple application in the Google data center:

It is worthwhile to clarify that in Google a server cluster is called a cell, and the size of a typical such cluster is about 10,000 servers. Total in this example, the author runs 10,000 copies of the hello_world application in cell = ic, indicating how much memory, disk and CPU it is going to use.
A simple application Hello, world! after assembly will take about 75 megabytes. Because it automatically includes a web server, a system for collecting debug information and much more.
After writing the above configuration file and launching a special utility, the application will be assembled, laid out on the specified cluster and launched.
All this in Google can be done by the programmer himself, without involving administrators or release engineers.
Although we have requested 10,000 copies, it usually starts a little less. This is due to server crashes and scheduled maintenance. And that's fine. Applications in Google were originally designed for the fact that some servers will be unavailable. Therefore, when discussing technical issues, Google first of all discusses what to do in the event of a service crash, and performance has a lower priority than scalability.
When the application starts to work stably, they begin to study its performance. A lot of statistics about the performance of web applications are collected and ways to utilize the resources of each physical server at full capacity are sought. That is, if the server in Google does not use all its resources - this is also bad.
At Google, they conduct many experiments aimed at spreading the load on the servers more closely.
For example, on one server, they run both regular web applications and regular background tasks, such as map-reduce tasks. And it greatly increased the efficiency of their servers.
They also collected statistics on how many resources the application requires (see the “config” example for Hello, world!) And how many resources it actually uses. And it turned out that programmers almost always request more resources than they need. Therefore, it was decided to run more applications on one server, thereby further increasing the efficiency of resource use.
Google is very active in using Linux containers, which provide resource isolation and execution isolation. Every week, Google launches about two billion containers. All applications run inside the container. To manage a Linux container cluster, Google uses its internal development, written in Go and released on OpenSource http://kubernetes.io/ .
The report was very interesting. I deliberately missed many of his details and recommend to look at it completely.
CloudFlare's fourth year of using Go (John Graham-Cumming)
Slides
CloudFlare is a service that is actually a reverse-proxy between the user and the site. The bottom line is that CloudFlare has data centers scattered around the world, and when a user visits their client's site, in fact, they go to the nearest data center, SloudFlare. And already CloudFlare is engaged in the delivery of content to this user. In addition to the main task of content delivery, they also provide other services, such as protection against DDoS, traffic analysis for hacking attempts, support for protocols that are not supported by the client site (for example, SPDY), caching, and so on.
At first, CloudFlare used PHP, nginx, and C, C ++ modules. But gradually they replaced PHP and C ++ with GO, PHP was left only to show the site. And the nginx modules were rewritten on LuaJIT, but some nginx modules on C still remain.
When asked how the speaker managed to convince CloudFlare to start using GO, the author replied that he had lied to the authorities, and at the very last moment said that he had written the program in the GO language.
The first project at GO was a thing called railgun. The bottom line is that CloudFlare often needs to transfer some html pages between data centers. They considered and understood that if you take 2 different pages from one site, make a diff between them and transmit only a diff, it turns out faster than transferring a whole page. Thus, they simply transfer diffs between data centers, and thereby very much speeding up the delivery of content.
They also wrote on GO:
- your DNS server with support for DNS Proxying and DNSSEC;
- TLS / SSL / PKI toolkit;
- a system for recompression of pictures (their system looks at which data centers are currently not loaded, and starts recompression of pictures on these data centers);
- aggregation and analysis of logs (use https://capnproto.org/ to serialize data. Log analysis is used in particular to define distributed attacks);
- different tasks that run through cron.
Main problems with GO:
- garbage collection;
- external dependency management; for themselves, they solved this problem by manually indicating the version of the library used.
In general, they are very satisfied with GO, it is ideal for their tasks.
Building Functional Infrastructure with Mirage OS (Anil Madhavapeddy)
Slides
If someone read about Erlang on Xen, then Mirage OS is the same, only on OCaml.
The bottom line is that Mirage OS allows you to create so-called unikernels on OCaml - specially prepared virtual machine images for the Xen hypervisor. The difference between unikernels and a Docker container is that only those OS capabilities that are really needed are included in unikernels, and such images start very quickly. For example, if an application in unikernels does not work with files, then the file system will simply not be included in the unikernels image. Due to this, unikernels have a small size (sometimes only a few megabytes) and increased security, since they contain only what is necessary for the application.
Security is also enhanced by the guarantees provided by OCaml as a language. Due to the size and speed of work, unikernels can work on small, cheap devices. For the same reasons, tens of thousands of unikernels can be run on modern servers.
The report turned out to be lively, interesting, with many examples. The only pity is that Mirage OS, most likely, will not take off.
Reports Day # 3
Scaling Uber's Realtime Market Platform (Matt Ranney)
Slides
At QCon London 2015, Uber first talked about their architecture. The report described a lot of technical nuances. To understand what problems have to be solved in Uber, you need to understand a little about their business and who they interact with.
The behavior of service providers (drivers) is very unpredictable, because they are free to do what they want. They can interrupt their work at any time. Some of them can work only a few hours a day. Clients (passengers) are also unpredictable in their needs. Another thing to keep in mind is that if the Uber service is unavailable, customers will not wait for it to work - they will simply call another taxi service. Therefore, for Uber, any fall is a loss of money.
The system, which selects drivers for passengers and plans a route, is called Dispatch System in Uber, and the report was about this part of Uber.
They use 4 different languages on the backend: Node.js, Python, Java, GO. Dispatch System is almost all written in Node.js. A very large part of the business logic is allocated to individual services.
They also use various databases: PostgreSQL, Redis, MySQL, Riak.
Dispatch System was recently completely rewritten. The author is familiar with the Joel Spolsky article “ Things you should never do ”, but they had a lot of problems in the code that limited them:
- The code implied that one driver was carrying one passenger - this limited them in their ability to experiment.
- The code implied that the driver always carries a person - this limited them in their ability to enter the adjacent freight markets.
- The system was "shardy" in the city - there were performance problems in big cities.
All this limited the growth of Uber, so they ignored the advice of Joel and completely rewrote this scheme.
In the new system, they made a separate geo-index of service providers (drivers), a separate geo-index of consumers and a system that calculates routes and tries to determine where the driver will be in the future. This system not only determines the physical distance between clients, but can determine the situation when two objects are physically located close to each other, but there is, for example, a channel between them.
For airports, a special logic was developed, because often taxis form queues there, and Uber simulates such a queue in its system.
The system is focused on reducing waiting times and reducing travel time.
They actively use the https://code.google.com/p/s2-geometry-library/ library for geographic calculations. Among other things, this library allows you to break the surface of the earth into diamonds with different levels of scaling. In fact, it allows you to represent any square centimeter of the Earth in the form of int64.

In this system, the entire surface of the earth is divided into Level12 cells, each such cell has its own ID and is used as a key for sharding.
Most of the system is written in Node.js. On top of Node.js they wrote their library https://github.com/uber/ringpop . This library allows you to share the service, written in Node.js, on several servers. It also allows you to work transparently with a remote process, as if it were on a local server. The author admitted that they gradually add all the features of Erlang in Node.js.
This library uses the Gossip protocol and in terms of CAP is an AP system.
How does Uber write a system to guarantee availability?
- Any command can be sent again. If something does not work, it should be possible to try this command again.
- Any process (and even database) can be killed at any time. The application should be ready for this.
- Emergency shutdown process is used as a standard way to turn something off. If the system is able to cope with this, there is no point in wasting time on the implementation of a “smooth shutdown”.
- The whole system is broken into small pieces. Because of this, killing individual processes will not affect global traffic.
To reduce time delays, i.e. when one of the services slows down, the backup request with cross-server cancelation technique is used.
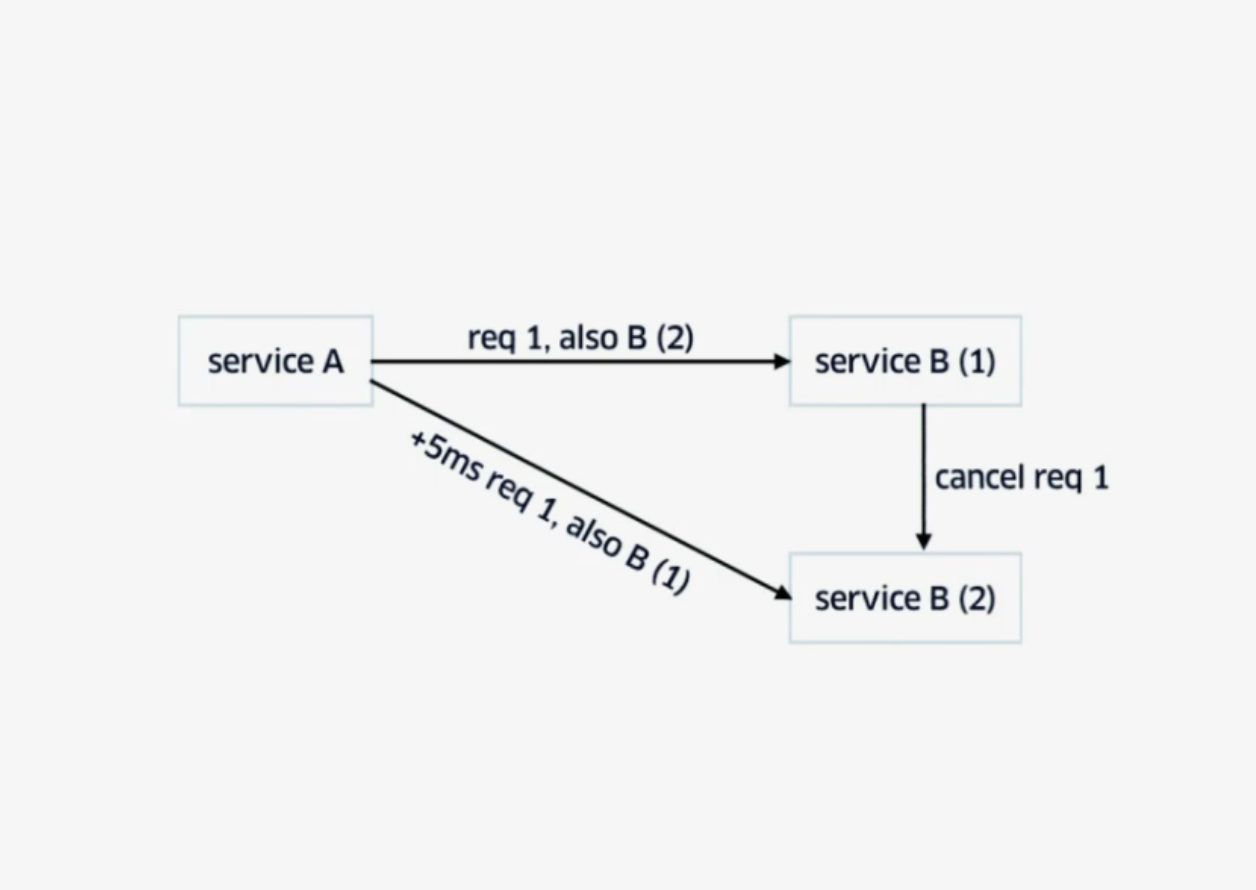
The client sends a request to the service B1 and in the request itself says: "By the way, I am going to send the same request to the service B2". After a short period of time, if the answer did not come, the client sends the same request to service B2 and in the request itself says: "By the way, I have already sent this request to service B1." The first service that will process the request, then will contact the second command “Cancel such a request”.
Of course, this works if the principles of Uber are respected:
- any request can be repeated;
- Any process can be killed.
Service Architectures at Scale: Lessons from Google and eBay (Randy Shoup)
Slides
The author of the report worked in Google and Ebay. He tried to systematize his experience, adding to his information about other major projects, taken from public sources. His report does not affect the technical field of these companies, it is more focused on the processes within companies, principles and methods. I think it will be more interesting to tehlidam and timlidov.
In general, all large systems are moving in this direction:
- First a monolithic application is written, often in a scripting language (Perl - in Ebay, Ruby - on Twitter).
- Then everything is rewritten to a faster language (Java, Scala, C ++) but, again, with a monolithic platform.
- And then everything is altered on microservices.
In general, microservices are one of the main trends at QCon. And in this report, the author talks a lot about how to build processes in a company, when the whole product is divided into many microservices.
Often, in such projects, every microservice has a team that is responsible for it. It has complete freedom of action in terms of how to implement this microservice, what language, database, framework to use, how and when to upload microservice.
But communication between services is standardized:
- network protocols;
- data formats;
- interfaces and circuits.
On this occasion, the report had a good quotation: “In a mature ecosystem of services, we standardize the graph, not the nodes”.
The infrastructure is also standardized:
- version control system;
- configuration management;
- cluster management;
- monitoring.
Often, in such companies, the system architecture is the result of the evolution of the project, rather than a pre-thought-out and detailed planning architecture.
For example, in Google there is no such position as “architect”, and there is no center for making basic technical decisions. Most decisions are made locally within the team.
As a contrast, the author cites the practice that was used earlier in Ebay, where there was an Architecture review board, through which all large projects passed for approval. And although there were many experienced people in the company, they were often involved in the discussion of the project when nothing could be changed. And this board often became a bottleneck, in which many projects stuck for a long time.
Instead of using experienced developers to evaluate other people's projects, the author suggests using them for writing libraries, utilities, low-level services, or even manuals that could be used internally in many projects.
The report was very intelligent, comprehensive, but it is more for those who lead the process, and not for ordinary programmers.
Building a Modern Microservices Architecture at Gilt: The Essentials (Yoni Goldberg)
Slides
Gilt.com sells branded items with discounts. At midnight, they run very large discounts - during these periods the load increases greatly and it is at this time that they earn more money. Therefore, all their technical solutions should take into account these load peaks.
Initially, the company had a monolithic Ruby application using PostgreSQL and memcached, but once the Louboutins (famous designer shoes with a red sole) went on sale and the site could not withstand the load.
After that, they began to rewrite everything to JVM (now they mostly have Scala) using microservices. Postgresql, H2 and Voldemort are used as databases. At first, they had not even microservices, but “macroservices”. In fact, they broke the monolithic application into components: payments, sales, users. But then these macroservices were divided into smaller services.
This solved most of their problems, especially with regards to scalability and performance. But there were problems with the complexity of the code; many services remained monolithic, it was hard to post a new version of this system every week.
For this reason, they continued to break down their services into even smaller microservices. At the same time, the transition to the Scala and Play framework began, and they began to use LOSA - Lots Of Small Applications. It's like microservices but for web applications. That is, each page on the site is a separate microservice.
The overall architecture began to look something like this:
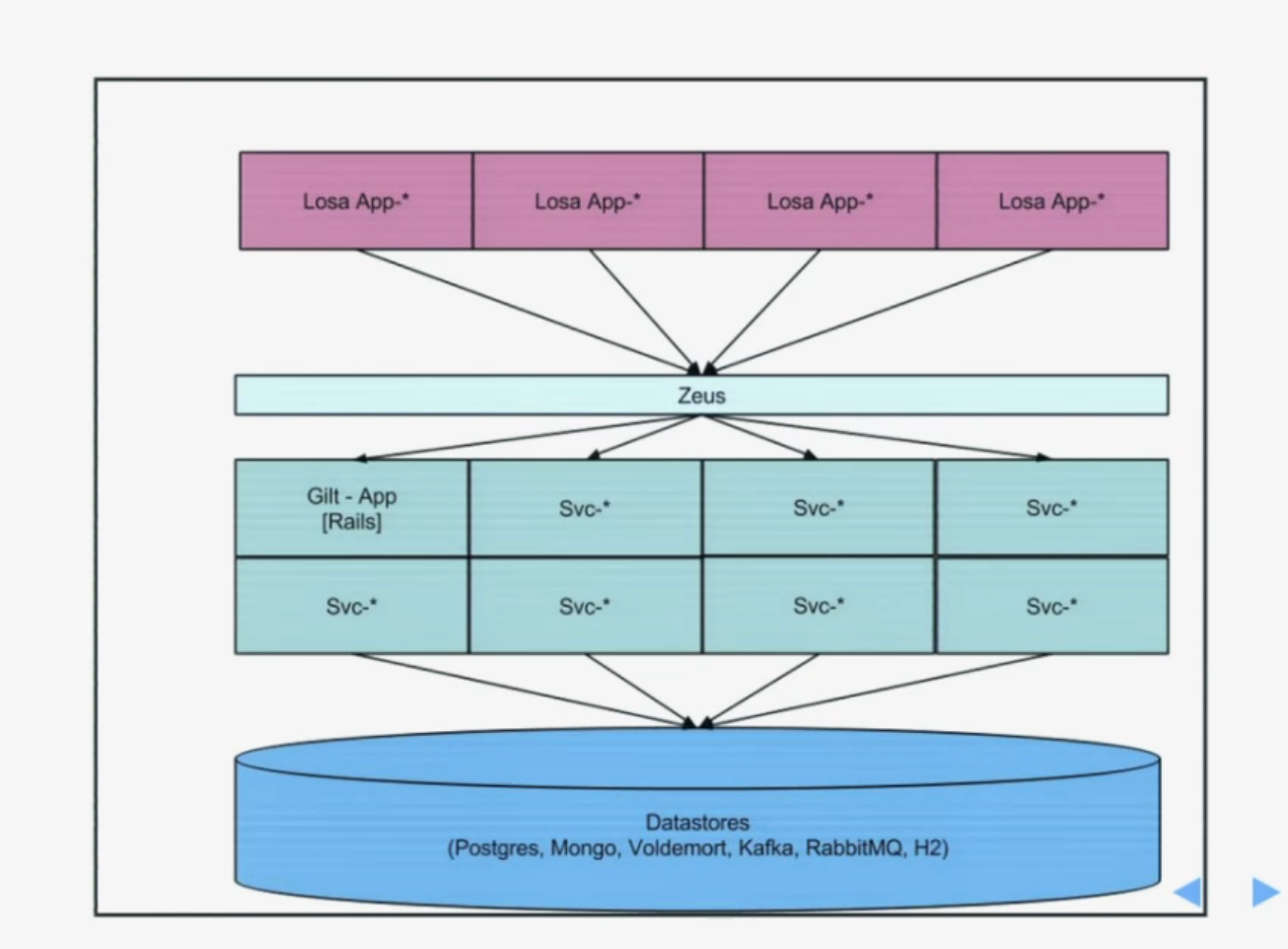
Now they have about 300 services.
All services are wrapped in Docker and run on AWS. Each team within AWS has its own account and budget. Therefore, each team ensures that they are not running services that are no longer used, and, of course, cares about the performance of their services
Despite the fact that some of the decisions seem ambiguous to me, the report was interesting. The author shared interesting experiences, problems and their solutions.
Spotify Audio Delivery at Scale (Niklas Gustavsson)
Slides
The author talked about how Spotify works, what problems have to be solved.
One of the main tasks that confronts the developers at Spotify is that the song selected by the user is played immediately. At least, the user should have the impression that the music began to play without delay. And this imposes certain requirements on the development of backend.
Although the company does not use the term “microservice”, yet the architecture of Spotify is built around microservices, of which there are hundreds, and they are being developed by approximately 40-50 teams.
Pluses of microservices:
- code simplicity;
- system reliability;
- scaling.
Each team works independently of the others - it develops and maintains its microservices. Each team decides how it works, sets the development process, the process of laying out new code, determines the architecture of its microservices. There are several architects in the company who rate Spotify at a very high level, but they do not participate in planning the architecture of specific microservices. If a team needs a change in microservice for which another team is responsible, then they can assign the task to another team, or they can make the change themselves and send it to code review.
Inside Spotify, services communicate over an internal asynchronous protocol built on the basis of ZeroMQ and Protobuf. Initially, internal communications of services were based on HTTP, but many problems arose with this. Previously, almost all of Spotify was written in Python, which had problems with scalability. Now almost the entire backend is written in Java using microservices.
The company has certain guidelines for teams, but they have minimal restrictions. It is recommended to write microservices on JVM or Python, there are recommendations for data storage. , .
, , Spotify. TCP- Perimeter service, . Perimeter service , , backend Spotify . Perimeter service , .
View Services, SearchView. View Services . Spotify rendering , (iPad, iPhone, Android) , View services. SearchView Search Service, , Lucene index. Data Services. . , SearchView Metadata service ( , ).
4 -. - , . , Spotify- Perimeter service. -, . -, Spotify Cassandra.
Spotify - , -. CDN.
Conclusion
. , , . , . - Aerospike. Basho bet365 Riak , , .
, . . , (Docker ) .
Source: https://habr.com/ru/post/255719/
All Articles