SQL Language Tutorial (DDL, DML) on the example of MS SQL Server dialect. Part two
Introduction and DDL - Data Definition Language
Part One - habrahabr.ru/post/255361
DML - Data Manipulation Language
In the first part, we have already slightly touched on the DML language, using almost the entire set of its commands, with the exception of the MERGE command.
I will tell about DML by my own personal experience. Along the way, I will also try to tell you about the “slippery” places that are worth paying attention to, these “slippery” places are similar in many dialects of the SQL language.
')
Since the textbook is dedicated to a wide circle of readers (not only programmers), then the explanation will sometimes be appropriate, i.e. long and tedious. This is my vision of the material, which is mainly obtained in practice as a result of professional activity.
The main goal of this textbook, step by step, is to develop a complete understanding of the essence of the SQL language and teach how to properly apply its constructions. Professionals in this field may also be interested to browse through this material, maybe they will be able to bring out something new for themselves, or maybe it will just be useful to read in order to refresh their memory. I hope that everyone will be interested.
Since DML in the MS SQL DB dialect is very closely related to the syntax of the SELECT clause, then I’ll start talking about DML from there. In my opinion, the SELECT construct is the most important construct of the DML language, since at the expense of her or her parts, the necessary data is retrieved from the database.
DML language contains the following constructs:
- SELECT - data selection
- INSERT - insert new data
- UPDATE - update data
- DELETE - delete data
- MERGE - data fusion
In this part, we consider only the basic syntax of the SELECT command, which looks like this:
SELECT [DISTINCT] _ * FROM WHERE ORDER BY _ The topic of the SELECT statement is very extensive, so in this part I will focus only on its basic structures. I believe that, without knowing the base well, it is impossible to proceed to the study of more complex structures, since then everything will revolve around this basic structure (subqueries, joins, etc.).
Also within this part, I will also talk about the TOP proposal. I intentionally did not indicate this sentence in the basic syntax, since it is implemented differently in different dialects of the SQL language.
If the DDL language is more static, i.e. using it creates rigid structures (tables, relations, etc.), then the DML language is dynamic, here you can get the right results in different ways.
Training will also continue in the Step by Step mode, i.e. when reading, you should immediately try to do an example with your own hands. After doing the analysis of the result and try to understand it intuitively. If something remains unclear, for example, the value of any function, then contact the Internet for help.
Examples will be shown on the Test database, which was created using DDL + DML in the first part.
For those who did not create the database in the first part (because not everyone may be interested in the DDL language), you can use the following script:
Test Database Creation Script
-- CREATE DATABASE Test GO -- Test USE Test GO -- CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL ) GO -- SET IDENTITY_INSERT Positions ON INSERT Positions(ID,Name)VALUES (1,N''), (2,N''), (3,N''), (4,N' ') SET IDENTITY_INSERT Positions OFF GO SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name)VALUES (1,N''), (2,N''), (3,N'') SET IDENTITY_INSERT Departments OFF GO -- CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) ) GO -- INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N' ..','19550219','i.ivanov@test.tt',2,1,NULL), (1001,N' ..','19831203','p.petrov@test.tt',3,3,1003), (1002,N' ..','19760607','s.sidorov@test.tt',1,2,1000), (1003,N' ..','19820417','a.andreev@test.tt',4,3,1000) That's it, now we are ready to start learning the DML language.
SELECT - data selection operator
First of all, for the active query editor, we will make the current Test database, selecting it in the drop-down list or using the “USE Test” command.
Let's start with the most elementary form of SELECT:
SELECT * FROM Employees In this query, we ask you to return all the columns (indicated by “*”) from the Employees table - you can read this as “SELECT ALL_Fields FROM Employee_Tables”. In the case of a clustered index, the returned data is likely to be sorted by it, in this case by the ID column (but this is not important, since in most cases we will explicitly specify the sorting using ORDER BY ...) :
| ID | Name | Birthday | PositionID | DepartmentID | Hiredate | ManagerID | |
|---|---|---|---|---|---|---|---|
| 1000 | Ivanov I.I. | 1955-02-19 | i.ivanov@test.tt | 2 | one | 2015-04-08 | Null |
| 1001 | Petrov P.P. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | Sidorov S.S. | 1976-06-07 | s.sidorov@test.tt | one | 2 | 2015-04-08 | 1000 |
| 1003 | Andreev A.A. | 1982-04-17 | a.andreev@test.tt | four | 3 | 2015-04-08 | 1000 |
In general, it should be said that in the MS SQL dialect the simplest form of the SELECT query may not contain a FROM block, in this case you can use it to get some values:
SELECT 5550/100*15, SYSDATETIME(), -- SIN(0)+COS(0) | (No column name) | (No column name) | (No column name) |
|---|---|---|
| 825 | 2015-04-11 12: 12: 36.0406743 | one |
Note that the expression (5550/100 * 15) gave the result of 825, although if we count on the calculator, we get the value (832.5). The result 825 turned out for the reason that in our expression all the numbers are integers, therefore the result is an integer, i.e. (5550/100) gives us 55, not (55.5).
Remember the following, that the following logic works in MS SQL:
- Integer / Integer = Integer (i.e. integer division occurs in this case)
- Real / Whole = Real
- Integer / Real = Real
Those. the result is converted to a larger type, so in the last 2 cases we get a real number (think like in mathematics - the range of real numbers is greater than the range of integers, so the result is converted to it):
SELECT 123/10, -- 12 123./10, -- 12.3 123/10. -- 12.3 Here (123.) = (123.0), just in this case, 0 can be discarded and leave only a point.
With other arithmetic operations, the same logic operates, just in the case of division, this nuance is more relevant.
Therefore, pay attention to the data type of the numeric columns. In the event that it is integer, and you need to get a real result, then use a transformation, or simply put a period after the number specified in the form of a constant (123.).
You can use the CAST or CONVERT function to convert fields. For example, we use the ID field, it is our int type:
SELECT ID, ID/100, -- CAST(ID AS float)/100, -- CAST float CONVERT(float,ID)/100, -- CONVERT float ID/100. -- FROM Employees | ID | (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|---|
| 1000 | ten | ten | ten | 10.000000 |
| 1001 | ten | 10.01 | 10.01 | 10.010000 |
| 1002 | ten | 10.02 | 10.02 | 10.020000 |
| 1003 | ten | 10.03 | 10.03 | 10.030000 |
On a note. In the ORACLE DB, the syntax without the FROM block is invalid, there the DUAL system table is used for this purpose, which contains one line:SELECT 5550/100*15, -- ORACLE 832.5 sysdate, sin(0)+cos(0) FROM DUAL
Note. The table name in many DBMs can be preceded by the schema name:SELECT * FROM dbo.Employees -- dbo –
A schema is a logical database unit that has its own name and allows grouping database objects such as tables, views, etc.
The schema definition in different databases may differ, somewhere the schema is directly connected with the database user, i.e. in this case, we can say that the schema and the user are synonyms and all the objects created in the schema are in fact the objects of this user. In MS SQL, a schema is an independent logical unit that can be created by itself (see CREATE SCHEMA).
By default, a single schema with the name dbo (Database Owner) is created in the MS SQL database and all created objects by default are created in this schema. Accordingly, if we specify just the name of the table in the query, then it will be searched in the dbo schema of the current database. If we want to create an object in a specific schema, we will also need to prepend the object name with the schema name, for example, “CREATE TABLE schema_name.table_name (...)”.
In the case of MS SQL, the schema name can also be preceded by the name of the database in which the schema is located:SELECT * FROM Test.dbo.Employees -- _._.
Such clarification is useful, for example, if:
- in one request we refer to objects located in different schemes or databases
- required to transfer data from one schema or database to another
- being in one DB, it is required to request data from another DB
- etc.
The scheme is a very convenient tool that is useful for developing a database architecture, and especially large databases.
Just do not forget that in the query text, we can use both single-line "- ..." and multi-line "/ * ... * /" comments. If the request is large and complex, comments can help you or someone else, after a while, to recall or understand its structure.
If there are a lot of columns in the table, and especially if there are still a lot of rows in the table, plus if we make queries to the database over the network, then a sample with a direct listing of the fields you need is preferred, separated by commas:
SELECT ID,Name FROM Employees Those. here we say that we only need to return the ID and Name fields from the table. The result will be as follows (by the way, the optimizer here decided to use the index created by the Name field):
| ID | Name |
|---|---|
| 1003 | Andreev A.A. |
| 1000 | Ivanov I.I. |
| 1001 | Petrov P.P. |
| 1002 | Sidorov S.S. |
On a note. Sometimes it is useful to look at how data is sampled, for example, to find out which indexes are being used. This can be done if you click the button "Display Estimated Execution Plan - Show Calculation Plan" or set "Include Actual Execution Plan - Include the actual execution plan of the query in the result" (in this case we will be able to see the actual plan, respectively, only after the query is executed) :
Analysis of the execution plan is very useful when optimizing a query, it allows you to find out which indexes are missing or which indexes are not used at all and can be deleted.
If you are just starting to learn DML, then now it is not so important for you, just take a note and you can safely forget about it (maybe it will never be useful to you) - our initial goal is to learn the basics of the DML language and learn how to properly apply them, and optimization is a separate art. Sometimes it is more important that you simply have a correctly written query that returns the correct result from the substantive point of view, and some people are already engaged in its optimization. To begin, you need to learn how to just correctly write requests, using any means to achieve the goal. The main goal that you must now achieve is for your query to return the correct results.

Setting aliases for tables
When enumerating columns, they can be preceded by the name of a table located in the FROM block:
SELECT Employees.ID,Employees.Name FROM Employees But such syntax is usually inconvenient to use, since The name of the table may be long. For these purposes, shorter names are usually set and applied - aliases:
SELECT emp.ID,emp.Name FROM Employees AS emp or
SELECT emp.ID,emp.Name FROM Employees emp -- AS ( ) Here emp is the alias for the Employees table, which can be used in the context of this SELECT statement. Those. it can be said that in the context of this SELECT statement we give the table a new name.
Of course, in this case the results of the queries will be exactly the same as for “SELECT ID, Name FROM Employees”. For what it will need to be understood further (not even in this part), for the time being we simply remember that the column name can be preceded (specified) either directly by the table name, or with the help of an alias. Here you can use one of the two, i.e. if you set a pseudonym, then you will need to use it, and you cannot use the table name anymore.
On a note. In ORACLE, only the option to specify a table alias without the keyword AS is allowed.
DISTINCT - garbage duplicate rows
The DISTINCT keyword is used to discard duplicate strings from a query result. Roughly speaking, imagine that a query is first executed without the DISTINCT option, and then all duplicates are dropped from the result. Let us demonstrate this for greater clarity by example:
-- CREATE TABLE #Trash( ID int NOT NULL PRIMARY KEY, Col1 varchar(10), Col2 varchar(10), Col3 varchar(10) ) -- INSERT #Trash(ID,Col1,Col2,Col3)VALUES (1,'A','A','A'), (2,'A','B','C'), (3,'C','A','B'), (4,'A','A','B'), (5,'B','B','B'), (6,'A','A','B'), (7,'A','A','A'), (8,'C','A','B'), (9,'C','A','B'), (10,'A','A','B'), (11,'A',NULL,'B'), (12,'A',NULL,'B') -- DISTINCT SELECT Col1,Col2,Col3 FROM #Trash -- DISTINCT SELECT DISTINCT Col1,Col2,Col3 FROM #Trash -- DROP TABLE #Trash Clearly, it will look like this (all duplicates are marked with the same color):
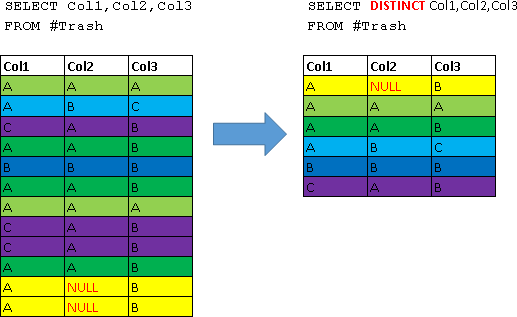
Now let's look at where this can be applied, on a more practical example - we’ll return from the Employees table only unique department identifiers (that is, we’ll find out the IDs of the departments that have employees):
SELECT DISTINCT DepartmentID FROM Employees | DepartmentID |
|---|
| one |
| 2 |
| 3 |
Here we got three lines, because 2 employees are listed in one department (IT).
Now we will find out in which departments, which positions appear:
SELECT DISTINCT DepartmentID,PositionID FROM Employees | DepartmentID | PositionID |
|---|---|
| one | 2 |
| 2 | one |
| 3 | 3 |
| 3 | four |
Here we got 4 lines, because There are no duplicate combinations (DepartmentID, PositionID) in our table.
Let's go back to DDL for a while
Since the data for the demo begins to be missed, and I want to tell more extensively and clearly, then let's expand our Employess table a little. In addition, let us remember a little DDL, as they say, “repetition is the mother of the doctrine,” and again let's run forward a little and apply the UPDATE statement:
-- ALTER TABLE Employees ADD LastName nvarchar(30), -- FirstName nvarchar(30), -- MiddleName nvarchar(30), -- Salary float, -- - BonusPercent float -- GO -- ( ) UPDATE Employees SET LastName=N'',FirstName=N'',MiddleName=N'', Salary=5000,BonusPercent= 50 WHERE ID=1000 -- .. UPDATE Employees SET LastName=N'',FirstName=N'',MiddleName=N'', Salary=1500,BonusPercent= 15 WHERE ID=1001 -- .. UPDATE Employees SET LastName=N'',FirstName=N'',MiddleName=NULL, Salary=2500,BonusPercent=NULL WHERE ID=1002 -- .. UPDATE Employees SET LastName=N'',FirstName=N'',MiddleName=NULL, Salary=2000,BonusPercent= 30 WHERE ID=1003 -- .. Make sure that the data is updated successfully:
SELECT * FROM Employees | ID | Name | ... | LastName | Firstname | MiddleName | Salary | BonusPercent |
|---|---|---|---|---|---|---|---|
| 1000 | Ivanov I.I. | Ivanov | Ivan | Ivanovich | 5000 | 50 | |
| 1001 | Petrov P.P. | Petrov | Peter | Petrovich | 1500 | 15 | |
| 1002 | Sidorov S.S. | Sidorov | Sidor | Null | 2500 | Null | |
| 1003 | Andreev A.A. | Andreev | Andrew | Null | 2000 | thirty |
Specifying aliases for query columns
I think it will be easier to show here than to write:
SELECT -- LastName+' '+FirstName+' '+MiddleName AS , -- , .. HireDate AS " ", -- , .. Birthday AS [ ], -- AS Salary ZP FROM Employees | Full name | date of receipt | Date of Birth | ZP |
|---|---|---|---|
| Ivanov Ivan Ivanovich | 2015-04-08 | 1955-02-19 | 5000 |
| Petrov Petr Petrovich | 2015-04-08 | 1983-12-03 | 1500 |
| Null | 2015-04-08 | 1976-06-07 | 2500 |
| Null | 2015-04-08 | 1982-04-17 | 2000 |
As you can see, the aliases of the columns that we specified are reflected in the header of the resulting table. Actually, this is the main purpose of column aliases.
Pay attention because the last 2 employees have no patronymic (NULL value), the result of the expression “LastName + '' + FirstName + '' + MiddleName” also returned NULL to us.
To connect (add, concatenate) strings in MS SQL, use the “+” symbol.
Remember that all expressions in which NULL is involved (for example, division by NULL, addition with NULL) will return NULL.
On a note.
In the case of ORACLE, the string "||" is used to concatenate strings and the concatenation will look like "LastName || ' '|| FirstName ||' '|| MiddleName ". For ORACLE, it is worth noting that it has an exception for string types, for them NULL and the empty string '' is the same, therefore in ORACLE this expression will return “Sidor Sidor” and “Andreev Andrey” for the last 2 employees. At the time of the version of ORACLE 12c, as far as I know, there is no option that changes this behavior (if wrong, please correct me). Here it is difficult for me to judge whether this is good or bad. in some cases, the NULL string behavior is more convenient as in MS SQL, and in others as in ORACLE.
In ORACLE, all the column aliases listed above are also valid, except for [...].
In order not to fence the structure using the ISNULL function, we can use the CONCAT function in MS SQL. Consider and compare 3 options:
SELECT LastName+' '+FirstName+' '+MiddleName FullName1, -- 2 NULL '' ( ORACLE) ISNULL(LastName,'')+' '+ISNULL(FirstName,'')+' '+ISNULL(MiddleName,'') FullName2, CONCAT(LastName,' ',FirstName,' ',MiddleName) FullName3 FROM Employees | FullName1 | FullName2 | FullName3 |
|---|---|---|
| Ivanov Ivan Ivanovich | Ivanov Ivan Ivanovich | Ivanov Ivan Ivanovich |
| Petrov Petr Petrovich | Petrov Petr Petrovich | Petrov Petr Petrovich |
| Null | Sidorov Sidor | Sidorov Sidor |
| Null | Andreyev Andrey | Andreyev Andrey |
In MS SQL, pseudonyms can still be specified using an equal sign:
SELECT ' '=HireDate, -- "…" […] '…' [ ]=Birthday, ZP=Salary FROM Employees Using the AS keyword or the equal sign to specify an alias is probably a matter of taste. But when analyzing other people's requests, this knowledge can be useful.
Finally, I’ll say that it’s better to set names for pseudonyms using only Latin characters and numbers, avoiding the use of '...', "..." and [...], that is, using the same rules that we used when naming tables. Further, in the examples I will use only such names and no '...', "..." and [...].
Basic SQL Arithmetic Operators
| Operator | Act |
|---|---|
| + | Addition (x + y) or unary plus (+ x) |
| - | Subtraction (xy) or unary minus (-x) |
| * | Multiplication (x * y) |
| / | Division (x / y) |
| % | The remainder of the division (x% y). For example, 15% 10 will give 5 |
The priority of performing arithmetic operators is the same as in mathematics. If necessary, the order of application of operators can be changed using parentheses - (a + b) * (x / (yz)).
And once again I repeat that any operation with NULL gives NULL, for example: 10 + NULL, NULL * 15/3, 100 / NULL - all this will result in a NULL. Those. saying just an undefined value can not give a certain result. Take this into account when making a request and, if necessary, process NULL values with the functions ISNULL, COALESCE:
SELECT ID,Name, Salary/100*BonusPercent AS Result1, -- NULL Salary/100*ISNULL(BonusPercent,0) AS Result2, -- ISNULL Salary/100*COALESCE(BonusPercent,0) AS Result3 -- COALESCE FROM Employees | ID | Name | Result1 | Result2 | Result3 |
|---|---|---|---|---|
| 1000 | Ivanov I.I. | 2500 | 2500 | 2500 |
| 1001 | Petrov P.P. | 225 | 225 | 225 |
| 1002 | Sidorov S.S. | Null | 0 | 0 |
| 1003 | Andreev A.A. | 600 | 600 | 600 |
| 1004 | Nikolaev N.N. | Null | 0 | 0 |
| 1005 | Aleksandrov A.A. | Null | 0 | 0 |
I will tell a little about the COALESCE function:
COALESCE (expr1, expr2, ..., exprn) - NULL . Example:
SELECT COALESCE(f1, f1*f2, f2*f3) val -- FROM (SELECT null f1, 2 f2, 3 f3) q Basically, I will focus on the narrative constructs of the language DML and for the most part I will not talk about the functions that will be found in the examples. If you don’t understand what a function does, look for its description on the Internet, you can even search for information directly by a group of functions, for example, by specifying “MS SQL string functions”, “MS SQL math functions” in Google search, or “MS SQL functions processing null. Information on the functions very much, and you can easily find it. For example, in the MSDN library, you can learn more about the COALESCE function:
MSDN COALESCE CASE
COALESCE — CASE. , COALESCE(expression1,...n) CASE:CASE WHEN (expression1 IS NOT NULL) THEN expression1 WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionN END
, (%). , . , , (ID), .. ID, 2:
SELECT ID,Name FROM Employees WHERE ID%2=0 -- 2 0 | ID | Name |
|---|---|
| 1000 | Ivanov I.I. |
| 1004 | .. |
| 1002 | .. |
ORDER BY –
ORDER BY .
SELECT LastName, FirstName, Salary FROM Employees ORDER BY LastName,FirstName -- 2- – , | LastName | FirstName | Salary |
|---|---|---|
| Andrew | 2000 | |
| Ivan | 5000 | |
| Petrov | Peter | 1500 |
| 2500 |
ORDER BY DESC, :
SELECT LastName,FirstName,Salary FROM Employees ORDER BY -- Salary DESC, -- 1. LastName, -- 2. FirstName -- 3. | LastName | FirstName | Salary |
|---|---|---|
| Ivan | 5000 | |
| 2500 | ||
| Andrew | 2000 | |
| Petrov | Peter | 1500 |
For notes. There is an ASC keyword for ascending sorting, but since ascending sorting is applied by default, you can forget about this option (I don’t remember the time when I used this option once).
It should be noted that in the ORDER BY clause you can also use fields that are not listed in the SELECT clause (except for the case when DISTINCT is used, I will discuss this case below). For example, run a little ahead using the TOP option and show how, for example, you can select 3 employees who have the highest RFP, given that I don’t have to show the RFP for confidentiality purposes:
SELECT TOP 3 -- 3 ID,LastName,FirstName FROM Employees ORDER BY Salary DESC -- | ID | LastName | Firstname |
|---|---|---|
| 1000 | Ivanov | Ivan |
| 1002 | Sidorov | Sidor |
, , . , , – (.. ), ( ), ID ( , ID – , , ):
SELECT TOP 3 -- 3 ID,LastName,FirstName FROM Employees ORDER BY Salary DESC, -- 1. Birthday, -- 2. ID DESC -- 3. ID Those. , « » , .. , .
ORDER BY:
SELECT LastName,FirstName FROM Employees ORDER BY CONCAT(LastName,' ',FirstName) -- ORDER BY :
SELECT CONCAT(LastName,' ',FirstName) fi FROM Employees ORDER BY fi -- DISTINCT, ORDER BY , SELECT. Those. DISTINCT , . , :
SELECT DISTINCT LastName,FirstName,Salary FROM Employees ORDER BY ID -- ID , DISTINCT Those. ORDER BY , .
1. ORDER BY , SELECT:SELECT LastName,FirstName,Salary FROM Employees ORDER BY -- 3 DESC, -- 1. 1, -- 2. 2 -- 3.
, .
( ), , «*» . – , -, , , ( ), , , .. , .
, , , , (.. ), , .
, .
2.
MS SQL NULL .SELECT BonusPercent FROM Employees ORDER BY BonusPercent
DESCSELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC
NULL , , :SELECT BonusPercent FROM Employees ORDER BY ISNULL(BonusPercent,100)
ORACLE 2 NULLS FIRST NULLS LAST ( ). For example:SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC NULLS LAST
.
TOP –
Cut from MSDN. TOP - limits the number of rows returned in the result set of the query to a specified number or percentage. If the TOP clause is used in conjunction with the ORDER BY clause, then the result set is limited to the first N lines of the sorted result. Otherwise, the first N rows are returned in an undefined order.
Usually, this expression is used with the ORDER BY clause and we already looked at examples when it was necessary to return the N-first rows from the result set.
Without ORDER BY, this sentence is usually applied when you just need to look at an unknown table in which there can be a lot of records, in this case we can, for example, ask us to return only the first 10 lines, but for clarity, we will say only 2:
SELECT TOP 2 * FROM Employees PERCENT, :
SELECT TOP 25 PERCENT * FROM Employees .
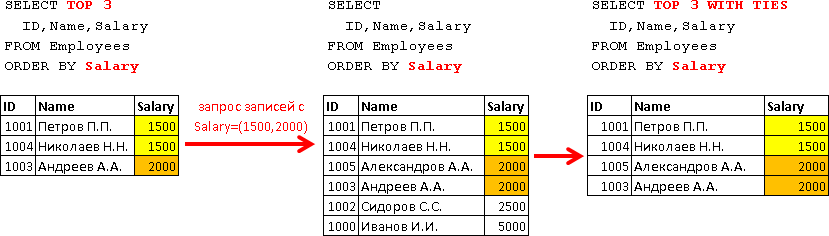
TOP WITH TIES, , .. , , TOP N, N. «» 1500:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1004,N' ..','n.nikolayev@test.tt',3,3,1003,1500) 2000:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1005,N' ..','a.alexandrov@test.tt',NULL,NULL,1000,2000) WITH TIES , 3- , ( , ):
SELECT TOP 3 WITH TIES ID,Name,Salary FROM Employees ORDER BY Salary TOP 3, 4 , .. Salary TOP 3 (1500 2000) 4- . :
.
TOP , MySQL LIMIT, .
ORACLE 12c, TOP LIMIT – «ORACLE OFFSET FETCH». 12c ROWNUM.
DISTINCT TOP? , . , , .. . SELECT , DISTINCT, TOP, .. -, , TOP. - , :
SELECT DISTINCT TOP 2 Salary FROM Employees ORDER BY Salary | Salary |
|---|
| 1500 |
| 2000 |
Those. 2 . - (NULL), .. . NULL ORDER BY, , Salary NULL, WHERE.
WHERE –
. , «» ( ID=3):
SELECT ID,LastName,FirstName,Salary FROM Employees WHERE DepartmentID=3 -- ORDER BY LastName,FirstName | ID | LastName | FirstName | Salary |
|---|---|---|---|
| 1004 | Null | Null | 1500 |
| 1003 | Andrew | 2000 | |
| 1001 | Petrov | Peter | 1500 |
WHERE ORDER BY.
Employees :
- WHERE – , Employees
- DISTINCT – ,
- ORDER BY – ,
- TOP – ,
:
SELECT DISTINCT TOP 1 Salary FROM Employees WHERE DepartmentID=3 ORDER BY Salary :

, NULL , IS NULL IS NOT NULL. , NULL «=» ( ) , .. NULL.
, , (.. DepartmentID IS NULL):
SELECT ID,Name FROM Employees WHERE DepartmentID IS NULL | ID | Name |
|---|---|
| 1005 | .. |
BonusPercent (.. BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent IS NOT NULL , , , BonusPercent (0), , .
, , , (BonusPercent<=0 BonusPercent IS NULL), . , , , OR NOT:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE NOT(BonusPercent<=0 OR BonusPercent IS NULL) Those.here we started exploring boolean operators. The expression in brackets "(BonusPercent <= 0 OR BonusPercent IS NULL)" checks that the employee does not have a bonus, and NOT inverts this value, i.e. says "return all employees who are not employees who do not have a bonus."
Also, this expression can be rewritten and immediately say immediately “return all employees who have a bonus” by expressing it with an expression (BonusPercent> 0 and BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent>0 AND BonusPercent IS NOT NULL Also in the WHERE block, you can do various kinds of expressions using arithmetic operators and functions. For example, a similar test can be made using an expression with the function ISNULL:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE ISNULL(BonusPercent,0)>0 Boolean operators and simple comparison operators
, , .
SQL 3 – AND, OR NOT:
| AND | . (1 AND 2). True, , |
|---|---|
| OR | . (1 OR 2). True, , |
| NOT | /_. (NOT _) True, _ = False False, _ = True |
, NULL:
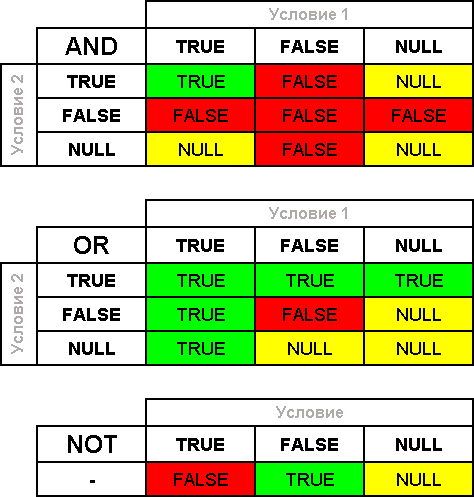
, :
| Condition | Value |
|---|---|
| = | |
| < | |
| > | More |
| <= | |
| >= | |
| <> != |
2 / NULL:
| IS NULL | NULL |
|---|---|
| IS NOT NULL | NULL |
: 1) ; 2) NOT; 3) AND; 4) OR.
:
((1 AND 2) OR NOT(3 AND 4 AND 5)) OR (…) , .
. , , (AND, OR NOT) , .
SELECT , , , – BETWEEN, IN LIKE.
BETWEEN –
:
_ [NOT] BETWEEN _ AND _ .
Let us consider an example:
SELECT ID,Name,Salary FROM Employees WHERE Salary BETWEEN 2000 AND 3000 -- 2000-3000 | ID | Name | Salary |
|---|---|---|
| 1002 | .. | 2500 |
| 1003 | .. | 2000 |
| 1005 | .. | 2000 |
, BETWEEN :
SELECT ID,Name,Salary FROM Employees WHERE Salary>=2000 AND Salary<=3000 -- 2000-3000 BETWEEN NOT, :
SELECT ID,Name,Salary FROM Employees WHERE Salary NOT BETWEEN 2000 AND 3000 -- NOT(Salary>=2000 AND Salary<=3000) , BETWEEN, IN, LIKE AND OR:
SELECT ID,Name,Salary FROM Employees WHERE Salary BETWEEN 2000 AND 3000 -- 2000-3000 AND DepartmentID=3 -- 3 IN –
:
_ [NOT] IN (1, 2, …) , :
SELECT ID,Name,Salary FROM Employees WHERE PositionID IN(3,4) -- 3 4 | ID | Name | Salary |
|---|---|---|
| 1001 | .. | 1500 |
| 1003 | .. | 2000 |
| 1004 | .. | 1500 |
Those. :
SELECT ID,Name,Salary FROM Employees WHERE PositionID=3 OR PositionID=4 -- 3 4 NOT ( , 3 4):
SELECT ID,Name,Salary FROM Employees WHERE PositionID NOT IN(3,4) -- NOT(PositionID=3 OR PositionID=4) NOT IN AND:
SELECT ID,Name,Salary FROM Employees WHERE PositionID<>3 AND PositionID<>4 -- PositionID NOT IN(3,4) , NULL IN , .. NULL=NULL NULL, True:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2,NULL) -- NULL :
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2) -- 1 2 OR DepartmentID IS NULL -- NULL - :
SELECT ID,Name,DepartmentID FROM Employees WHERE ISNULL(DepartmentID,-1) IN(1,2,-1) -- , ID=-1 , , . , , .
, NULL, NOT IN. , , , 1 , .. NULL. :
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1,NULL) , , :
| ID | Name | DepartmentID |
|---|---|---|
| 1001 | .. | 3 |
| 1002 | .. | 2 |
| 1003 | .. | 3 |
| 1004 | .. | 3 |
NULL .
. AND:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID<>1 AND DepartmentID<>NULL -- - NULL - NULL (DepartmentID<>NULL) , .. NULL. AND, (TRUE AND NULL) NULL. Those. (DepartmentID<>1) - (DepartmentID<>1 AND DepartmentID<>NULL), .
:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1) -- DepartmentID<>1 AND DepartmentID IS NOT NULL -- NOT NULL IN , , .
LIKE –
, SQL. , .
:
_ [NOT] LIKE _ [ESCAPE _] «_» :
- «_» — ,
- «%» — , ,
«%» ( , ):
SELECT ID,Name FROM Employees WHERE Name LIKE '%' -- "" SELECT ID,LastName FROM Employees WHERE LastName LIKE '%' -- "" SELECT ID,LastName FROM Employees WHERE LastName LIKE '%%' -- "" «_»:
SELECT ID,LastName FROM Employees WHERE LastName LIKE '_' -- "" SELECT ID,LastName FROM Employees WHERE LastName LIKE '____' -- "" ESCAPE , «_» «%». , .
ESCAPE :
UPDATE Employees SET FirstName='_, %' WHERE ID=1005 , :
SELECT * FROM Employees WHERE FirstName LIKE '%!%%' ESCAPE '!' -- "%" SELECT * FROM Employees WHERE FirstName LIKE '%!_%' ESCAPE '!' -- "_" , , LIKE «=»:
SELECT * FROM Employees WHERE FirstName='' .
MS SQL LIKE , , , .
ORACLE REGEXP_LIKE.
Unicode , N, .. N'…'. Unicode ( nvarchar), . Example:
SELECT ID,Name FROM Employees WHERE Name LIKE N'%' SELECT ID,LastName FROM Employees WHERE LastName=N'' , varchar (ASCII) '…', nvarchar (Unicode) N'…'. , . (INSERT) (UPDATE).
, (collation), , - ( ''=''), - ( ''<>'').
- , , , , – :
SELECT ID,Name FROM Employees WHERE UPPER(Name) LIKE UPPER(N'%') -- LOWER(Name) LIKE LOWER(N'%') SELECT ID,LastName FROM Employees WHERE UPPER(LastName)=UPPER(N'') -- LOWER(LastName)=LOWER(N'') , , '…'.
MS SQL 'YYYYMMDD' (, , ). MS SQL :
SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN '19800101' AND '19891231' -- 80- ORDER BY Birthday , DATEFROMPARTS:
SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31) ORDER BY Birthday DATETIMEFROMPARTS, ( datetime).
CONVERT, date datetime:
SELECT CONVERT(date,'12.03.2015',104), CONVERT(datetime,'2014-11-30 17:20:15',120) 104 120, . MSDN «MS SQL CONVERT».
MS SQL , «ms sql ».
Note. SQL .
-. , , , - , .. SQL, .
CAST, CONVERT , (). , . CONVERT date datetime.
CAST, CONVERT MSDN – « CAST CONVERT (Transact-SQL)»: msdn.microsoft.com/ru-ru/library/ms187928.aspx
Transact-SQL – DECLARE SET.
, ( , ), , .. ( ):
DECLARE @min_int int SET @min_int=-2147483648 DECLARE @max_int int SET @max_int=2147483647 SELECT -- (-2147483648) @min_int,CAST(@min_int AS float),CONVERT(float,@min_int), -- 2147483647 @max_int,CAST(@max_int AS float),CONVERT(float,@max_int), -- numeric(16,6) @min_int/1., -- (-2147483648.000000) @max_int/1. -- 2147483647.000000 , (1.), .. , . , , numeric, , MS SQL (1., 1.0, 1.00 .):
DECLARE @int int SET @int=123 SELECT @int*1., -- numeric(12, 0) - 0 @int*1.0, -- numeric(13, 1) - 1 @int*1.00, -- numeric(14, 2) - 2 -- CAST(@int AS numeric(20, 0)), -- 123 CAST(@int AS numeric(20, 1)), -- 123.0 CAST(@int AS numeric(20, 2)) -- 123.00 , .. , , , (varchar). money float varchar:
-- money varchar DECLARE @money money SET @money = 1025.123456789 -- 1025.1235, .. money 4 SELECT @money, -- 1025.1235 -- CAST CONVERT (.. 0) CAST(@money as varchar(20)), -- 1025.12 CONVERT(varchar(20), @money), -- 1025.12 CONVERT(varchar(20), @money, 0), -- 1025.12 ( 0 - 2 ( )) CONVERT(varchar(20), @money, 1), -- 1,025.12 ( 1 - 2 ) CONVERT(varchar(20), @money, 2) -- 1025.1235 ( 2 - 4 ) -- float varchar DECLARE @float1 float SET @float1 = 1025.123456789 DECLARE @float2 float SET @float2 = 1231025.123456789 SELECT @float1, -- 1025.123456789 @float2, -- 1231025.12345679 -- CAST CONVERT (.. 0) -- 0 - 6 . -- varchar CAST(@float1 as varchar(20)), -- 1025.12 CONVERT(varchar(20), @float1), -- 1025.12 CONVERT(varchar(20), @float1, 0), -- 1025.12 CAST(@float2 as varchar(20)), -- 1.23103e+006 CONVERT(varchar(20), @float2), -- 1.23103e+006 CONVERT(varchar(20), @float2, 0), -- 1.23103e+006 -- 1 - 8 . . -- float CONVERT(varchar(20), @float1, 1), -- 1.0251235e+003 CONVERT(varchar(20), @float2, 1), -- 1.2310251e+006 -- 2 - 16 . . -- CONVERT(varchar(30), @float1, 2), -- 1.025123456789000e+003 - OK CONVERT(varchar(30), @float2, 2) -- 1.231025123456789e+006 - OK As you can see from the example, floating types float, real in some cases can really create a big error, especially when distilling into a string and back (this can happen with all sorts of integrations, when data, for example, is transferred in text files from one system to another) .
If you need to explicitly control the accuracy of a certain character, more than 4, then for storing data, it is sometimes better to use the decimal / numeric type. If 4 characters are enough, then money can be used - it roughly corresponds to numeric (20.4).
-- decimal numeric DECLARE @money money SET @money = 1025.123456789 -- 1025.1235 DECLARE @float1 float SET @float1 = 1025.123456789 DECLARE @float2 float SET @float2 = 1231025.123456789 DECLARE @numeric numeric(28,9) SET @numeric = 1025.123456789 SELECT CAST(@numeric as varchar(20)), -- 1025.12345679 CONVERT(varchar(20), @numeric), -- 1025.12345679 CAST(@money as numeric(28,9)), -- 1025.123500000 CAST(@float1 as numeric(28,9)), -- 1025.123456789 CAST(@float2 as numeric(28,9)) -- 1231025.123456789 Note.
With MS SQL 2008, you can use instead of the construction:DECLARE @money money SET @money = 1025.123456789
Shorter variable initialization syntax:DECLARE @money money = 1025.123456789
The conclusion of the second part
, , . – , SQL.
, , SQL.
.
Part Three - habrahabr.ru/post/255825
Source: https://habr.com/ru/post/255523/
All Articles