Application of parallel algorithms in the 1C Enterprise environment
Probably, each of us faced a situation when you need to perform a large amount of calculations or transmit / receive a large amount of information for a limited period of time. And how many of us stopped at a sequential algorithm and closed our eyes to the duration of execution? So what, that 20 hours is the calculation / sending / receiving (underline necessary) of some data? Well, I “squeezed” everything I could out of the system, it would not work out faster ... At the same time, the server hardware is loaded to a minimum.
In fact, an alternative is almost always available in the form of paralleling the task being performed. Of course, parallel algorithms are somewhat more complicated - load balancing, synchronization between threads, as well as, in the case of shared resources, the struggle with waiting on locks and avoiding deadlocks. But as a rule, it is worth it.
We will talk about this today ... in the context of 1C Enterprises.
Virtually all modern languages have the necessary tools to implement parallelism. But not everywhere this toolkit is convenient for use. Someone will say: “So what’s so complicated and not convenient?” Platform mechanism of background tasks in hand and forward! ". In practice, it was not so easy. And what if the task is business critical? Then it is necessary to ensure, firstly, guaranteed performance of tasks and, secondly, monitoring of the work execution subsystem.
')
None of this provides background jobs.
The background may fall at any time. Here is just a small list of possible situations:
It turns out that it is necessary to monitor the work of the background, correct problems and set the "fallen" tasks to be repeated. Manual control of this good without automation of management scenarios and centralized control, to put it mildly, is still “pleasure”.
I would like to be able to flexibly manage tasks that are started with feedback, error-based, with guaranteed launch, and all this is about the same ease that exists in other languages and frameworks for parallel tasks.
To facilitate your own life, a universal library was developed that allows you to easily create parallel algorithms with guaranteed execution in the 1C Enterprise environment based on background tasks.
The task is added very simply - you need to specify the entry point (the path to the export method with the server context in the general module or the manager module) and a tuple with parameters in the form of a structure:
At the same time, a record is written to the register of tasks. Initially, the task has a status of Waiting . The method returns KeyTasks for possible tracking of progress in the main client thread. A tuple with parameters is also expanded by the KeyKnowledge property, so that when the task is performed, the context can sometimes be useful.
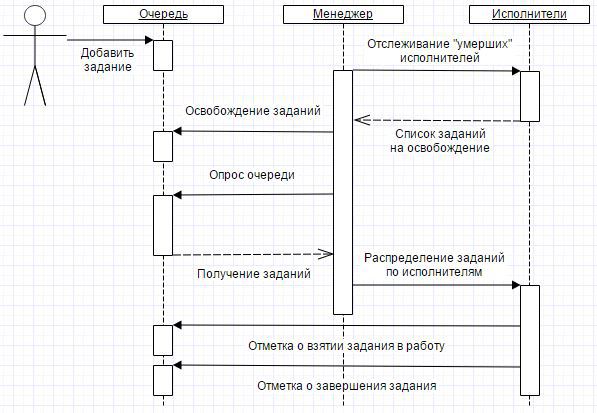
Then, once a minute, the Manager wakes up, who first of all checks the executors and releases the tasks, the performers of which have "died". The check is as follows. If the task is in the Run state and the background is set as the executor, it is not active (deleted by the administrator, an exception occurred in the code, etc.), then the task returns to the queue. To do this, the task is set to Waiting.
The next step is requesting from the job queue in accordance with the load balancing settings (now this is only a limit on the number of simultaneous workers).
After that, the Manager for each task runs the Contractor. The performers are the very background tasks of the 1C platform.
At start-up, the Contractor makes a note that he took the task into work - he registers his unique identifier at the task in the Key of the Contractor property and sets the task status to Running .
When the task is completed, the Contractor also makes the corresponding mark in the task - the status Completed .
To use the subsystem online, there is a method to add a task out of turn. At the same time, the Contractor is immediately launched, bypassing the Manager, and takes a new task. The signature is the same as the main method AddTarget. For such tasks, the limit on the number of performers is NOT covered, but the quota is used.
It is also possible to cancel jobs in the queue using the CancelRequest method. In this case, you can only cancel jobs that are in the Waiting state. Already running tasks are not canceled, because:
For convenient workflow management, the following methods are provided:
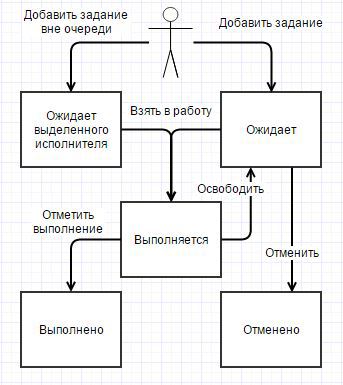
Based on the above, the life cycle of a task is as follows:
For customization there is a special treatment "Task Manager Management":

Available settings:
The launch of the subsystem, the stopping and cleaning of the queue is performed by the upper buttons that speak for themselves.
As an indicator of the operation of the subsystem, the flag Manager is running.
Immediately there is a superficial monitoring that can show how the system copes with tasks. Indicators:
The indicators are automatically updated once a minute. You can explicitly upgrade by clicking on the appropriate button. If you wish, you can look at the job register itself. There is an opportunity to see when the tasks were taken to work and how long they were executed, there is also a counter for the number of attempts to complete the task.
Advanced monitoring is highly dependent on the application and left to the consumers of the subsystem.
For example, payroll can be parallelized by employee, because the payroll of one employee, as a rule, does not depend on the payroll of another employee. (The above code only illustrates the capabilities of the subsystem, and is in no way associated with typical 1C configurations.)
The subsystem is available on github / TaskManagerFor1C . The CF file is open, so you can read the source codes.
The subsystem was developed through testing (TDD), tests are available in external processing / Tests / Tests_ManagerJodes.epf. To run the tests you need the xUnitFor1C toolkit .
Feedback is welcome. I am pleased to answer all questions arising from the instrument.
In fact, an alternative is almost always available in the form of paralleling the task being performed. Of course, parallel algorithms are somewhat more complicated - load balancing, synchronization between threads, as well as, in the case of shared resources, the struggle with waiting on locks and avoiding deadlocks. But as a rule, it is worth it.
We will talk about this today ... in the context of 1C Enterprises.
Virtually all modern languages have the necessary tools to implement parallelism. But not everywhere this toolkit is convenient for use. Someone will say: “So what’s so complicated and not convenient?” Platform mechanism of background tasks in hand and forward! ". In practice, it was not so easy. And what if the task is business critical? Then it is necessary to ensure, firstly, guaranteed performance of tasks and, secondly, monitoring of the work execution subsystem.
')
None of this provides background jobs.
The background may fall at any time. Here is just a small list of possible situations:
- Administrator for maintenance work has completed all sessions;
- external resource required at the time of the assignment, was unavailable for some time;
- after the next update, some of the tasks may have errors in the code, the background will be stopped by the action and, apart from writing to the log, will not tell anyone.
It turns out that it is necessary to monitor the work of the background, correct problems and set the "fallen" tasks to be repeated. Manual control of this good without automation of management scenarios and centralized control, to put it mildly, is still “pleasure”.
I would like to be able to flexibly manage tasks that are started with feedback, error-based, with guaranteed launch, and all this is about the same ease that exists in other languages and frameworks for parallel tasks.
To facilitate your own life, a universal library was developed that allows you to easily create parallel algorithms with guaranteed execution in the 1C Enterprise environment based on background tasks.
Application area
- The use of parallel computing in the automation of business processes;
- Parallel execution of queries in long reports / processing;
- Data loading / unloading processes;
- Organization of load testing.
The basic principle of operation
The task is added very simply - you need to specify the entry point (the path to the export method with the server context in the general module or the manager module) and a tuple with parameters in the form of a structure:
.(".", ("", 3)); At the same time, a record is written to the register of tasks. Initially, the task has a status of Waiting . The method returns KeyTasks for possible tracking of progress in the main client thread. A tuple with parameters is also expanded by the KeyKnowledge property, so that when the task is performed, the context can sometimes be useful.
Then, once a minute, the Manager wakes up, who first of all checks the executors and releases the tasks, the performers of which have "died". The check is as follows. If the task is in the Run state and the background is set as the executor, it is not active (deleted by the administrator, an exception occurred in the code, etc.), then the task returns to the queue. To do this, the task is set to Waiting.
The next step is requesting from the job queue in accordance with the load balancing settings (now this is only a limit on the number of simultaneous workers).
After that, the Manager for each task runs the Contractor. The performers are the very background tasks of the 1C platform.
At start-up, the Contractor makes a note that he took the task into work - he registers his unique identifier at the task in the Key of the Contractor property and sets the task status to Running .
When the task is completed, the Contractor also makes the corresponding mark in the task - the status Completed .
To use the subsystem online, there is a method to add a task out of turn. At the same time, the Contractor is immediately launched, bypassing the Manager, and takes a new task. The signature is the same as the main method AddTarget. For such tasks, the limit on the number of performers is NOT covered, but the quota is used.
It is also possible to cancel jobs in the queue using the CancelRequest method. In this case, you can only cancel jobs that are in the Waiting state. Already running tasks are not canceled, because:
- Background tasks seem to have a cancellation method, but it does not work for me transparently. Very often I observed a picture when a long background task worked through to the end despite the cancel command sent;
- I do not want to leave the system in inconsistent state. Who knows exactly how the task code is written and what it does in the database?
For convenient workflow management, the following methods are provided:
- Wait for Execution (Task Keys, Timeout = 5) - puts the current thread to sleep before the specified list of tasks has been completed, or until the specified time has elapsed;
- Wait for the Task (Key: Job, Expected State, Timeout = 5) - puts the current thread to sleep before the specified state is set at the task, or until the specified time has elapsed;
- Wait for Status Changes (KeyKnowledge, CurrentState, Timeout = 5) - puts the current thread to sleep before the status of the task has changed from specified to any other, or until the specified time has elapsed.
Based on the above, the life cycle of a task is as follows:
Customization
For customization there is a special treatment "Task Manager Management":
Available settings:
- The limit on the number of performers - for load balancing on the server 1C. Accepts a value from 0 to 9999. With a value of 0, tasks will not be taken into work.
- History storage depth (days) - if a value other than 0 is specified, then the subsystem will itself clean the information on the old completed tasks leaving the last N days specified in the configuration.
The launch of the subsystem, the stopping and cleaning of the queue is performed by the upper buttons that speak for themselves.
As an indicator of the operation of the subsystem, the flag Manager is running.
Immediately there is a superficial monitoring that can show how the system copes with tasks. Indicators:
- The number of active performers;
- The number of jobs in the queue (in the Waiting state);
- Total active tasks (p. 1 + p. 2).
The indicators are automatically updated once a minute. You can explicitly upgrade by clicking on the appropriate button. If you wish, you can look at the job register itself. There is an opportunity to see when the tasks were taken to work and how long they were executed, there is also a counter for the number of attempts to complete the task.
Advanced monitoring is highly dependent on the application and left to the consumers of the subsystem.
Examples of using
Using parallel computing in business process automation
For example, payroll can be parallelized by employee, because the payroll of one employee, as a rule, does not depend on the payroll of another employee. (The above code only illustrates the capabilities of the subsystem, and is in no way associated with typical 1C configurations.)
() = (); = (", ", ); . = ; = .("..", ); ; Parallel execution of queries in long reports / processing
() = ; .(.("..", )); .(.("..", )); .(.("..", )); = .(); = (); (); (" , "" """); .("..", ("", )); ; Data loading / unloading processes
() = (); = (""); . = ; = .("..", ); ; Organization of load testing
() = (); = 1 10000 = .(0, .()); = []; = .("..", ); ; Sources and stuff
The subsystem is available on github / TaskManagerFor1C . The CF file is open, so you can read the source codes.
The subsystem was developed through testing (TDD), tests are available in external processing / Tests / Tests_ManagerJodes.epf. To run the tests you need the xUnitFor1C toolkit .
Feedback is welcome. I am pleased to answer all questions arising from the instrument.
Source: https://habr.com/ru/post/255387/
All Articles