Layer caching over Linq to SQL
Over the past year we have transferred an impressive part of the DirectCRM settings to the database. Many elements of promotional campaigns, which we have previously described exclusively with the code, are now created and configured by the manager through the admin area. This turned out to be a very complex database structure, numbering dozens of tables.
However, I had to pay for transferring the settings to the database. About the architecture, allowing to cache rarely changing Linq to SQL entities, look under the cat.
The main unit of the system settings is a promotional campaign. The promotional campaign includes many elements: trigger mailings, prizes and operations that a consumer can perform on the site. Each element has a lot of settings that refer to other entities in the database. The result is a tree with great nesting. To pull out this tree, you need to make dozens of queries to the database, which adversely affect performance.
Initially, it was clear that campaign caching would have to be attributed, but we strictly followed the first optimization rule — not optimize until the system performance satisfies us. But, of course, as a result, the moment came when it was impossible to live without caching.
There were no questions at what point the cache should be reset - it needs to be updated whenever there is a change in the campaign or its element (since the campaign is an aggregate, there are no difficulties in implementing this logic). But I had to think a little about the question of where to store this cache and how to reset it. The following options were considered:
The option of using Redis is attractive because it allows you to keep only one copy of the cache for all WEB servers, and not load it for each server, but in fact it saves on matches: campaigns after the end of the configuration rarely change and it doesn't matter if the cache loaded four times a day or sixteen. Since there are no distributed transactions between Redis and the database, it is difficult to guarantee that when a campaign changes, the cache will be reset, so the first option is no longer possible.
')
The third option has the following advantages over the second:
In general, the problem and the general approach to the solution are clear. Further technical details will follow.
In order to fully use the entities within the current DataContext that are loaded in another DataContext, they need to be cloned and tagged. When attaching an entity is added to the IdentityMap of the current DataContext. You cannot attach the same entity to two different DataContext (therefore, each clone can be used only in one DataContext, that is, in one business transaction). MemberwiseClone cannot be used for cloning, since in this case there will be links to entities cloned to the DataContext in which the entity was loaded, and not to the current DataContext.
As a result, in order to be able to use entities from the static cache, the following code was written in the base class of the repository, using Linq MetaModel and a little Reflection:
So that when cloning, when going through the EntityRef and EntitySet, do not unload half of the database, only those that are marked with the special attribute CacheableAssociationAttribute are cloned.
Since the cache is loaded in a separate DataContext, and cloning occurs after its Dispose, we had to write a method that loads all cached associations for the loaded entity:
Of course, if you use DataLoadOptions, you will need fewer requests to load the EntityRef. But we didn’t even think about building DataLoadOptions dynamically, because Linq to SQL has a bug that, when using DataLoadOptions to load EntitySet, the entity type incorrectly loads (the type discriminator ignores the parent type instead of the child type).
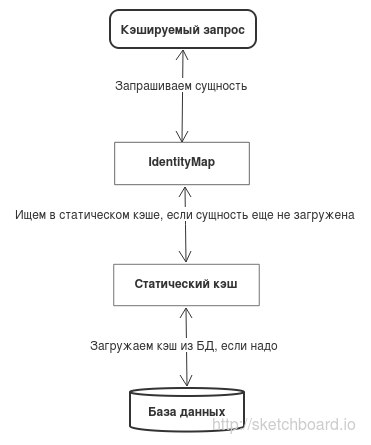
Since we access the records in the database via the repositories, I also accessed the cache references there. When you try to get a campaign or campaign element, the following happens:
With this approach, we only attach campaigns that we need and check the relevance of the cache (the date the campaign was changed) only once per transaction (once during the lifetime of the DataContext). Since there are many methods in the repositories for retrieving campaign elements (by Id, by campaign, by unique string identifier), the cache data structure is complicated, but you can live with it.
The new caching architecture passed all integration tests and was successfully laid out on the Production of one of the projects. Everything worked steadily and nothing foreshadowed trouble.
After laying out the cache for the next project, the following errors en masse fell: “DuplicateKeyException: cannot be an anonymous client” when the campaign attaches to the current DataContext. The first thought: “We made a mistake somewhere in our recursive cloning code and attach the same entity twice.” Turned out to be wrong. The mistake was more conceptual.
The code was to blame for the final project, which accessed the campaign without using the cache before attaching the same campaign from the cache. As I wrote above, when attaching an entity is added to IdentityMap, but if before that the entity has already been loaded from the database, then it already exists in IdentiyMap and an attempt to add an entity with the same key causes an error. Linq to SQL does not allow you to check whether an entity is in the IdentityMap before attaching. And if you catch and ignore errors during attachments, the caching would turn out to be incomplete.
There was an idea to remove from the repositories working with the cache, the ability to access the database bypassing the cache. Besides the fact that this is far from an easy task, it would not solve the problem completely, since many non-cacheable entities have EntityRef for cached entities, and when accessing the EntityRef, the request goes past the repository.
There are two options for solving this problem:
The first option would require rewriting half the code. At the same time, the resulting code would be more cumbersome, since everywhere where there was an appeal to the EntityRef, you would have to use the methods of the repositories. So I had to stop at the second version.
Since we attach entities when creating a DataContext, and not when accessing specific entities, we will have to explicitly specify at the beginning of the transaction which entities from the cache we need (loading the entire cache every time would be clearly redundant). That is, the approach chosen is not universal caching; it only allows you to fine-tune the use of the cache for individual transactions.
In some of our repositories, the results of queries on Id to entities were cached for the duration of the transaction in the Dictionary. In fact, this transaction cache can be considered our IdentityMap used on top of Linq to SQL IdentityMap. We needed only to transfer the transaction cache to the base repository and add access methods to it not only by Id, but also in other ways. As a result, we got a transaction cache class, when accessed by any method, each entity is loaded no more than once. If we, for example, request an entity first by Id, and then by a unique string identifier, the second query will not be executed and the access method will return the entity from the cache.
Since we now have a transaction cache in any repository, to support static caching, it is enough to fill in the transaction cache from the static cache while creating a DataContext, while not forgetting to clone and attach each entity. It all looks like this:

If we talk specifically about campaign caching, then loading a static cache works like this:
Then you can customize caching for other transactions as needed. In addition to the static cache for campaigns, general classes were created for static caching of dictionaries, which change only when the application is displayed. Those. caching any entities for which you do not need to check the relevance of the cache is very easy to enable. In the future, I want to expand this functionality by adding the ability to reset the cache after a certain time, or by simple queries in the database. It may be possible to remake the caching of campaigns to use the standard static cache classes with the necessary settings.
Although the resulting architecture looks slim and allows you to uniformly implement different types of caching, the need to clearly indicate what entities we need at the beginning of a transaction is not encouraging. In addition, in order to load all entities needed in a transaction and not attach a lot of unnecessary objects to the context, you need to know the transaction structure in detail.
There is another cache implementation that, unfortunately, cannot be implemented in Linq to SQL — replacing the standard IdentityMap with its implementation, which, before adding an entity, tries to get it from the cache. With this approach, a cached entity loaded in any way will be replaced with its copy from the cache, which already has all EntityRef and EntitySet loaded. Thus, you will not need to do any subqueries to get them. If you add an entity search in IdentityMap to the most frequently used repository methods before querying the database, the number of database queries will be drastically reduced. At the same time, you can search for any entities in the IdentityMap, not just those for which static caching is used. Since after receiving any entity from the database, it is replaced with its copy from IdentityMap (if it is already there), during the DataContext lifetime one cannot get two different copies of one entity, even if it was changed in another transaction (the first loaded entity will always be returned ). Therefore, there is no point twice in requesting an entity per transaction, for example, by key, and any requests by key during the transaction can be cached by checking the IdentityMap before the request.
We will try to implement this architecture after we go to the Entity Framework. EF allows you to get entities from IdentityMap, so that at least partially the architecture can be improved.
However, I had to pay for transferring the settings to the database. About the architecture, allowing to cache rarely changing Linq to SQL entities, look under the cat.
The main unit of the system settings is a promotional campaign. The promotional campaign includes many elements: trigger mailings, prizes and operations that a consumer can perform on the site. Each element has a lot of settings that refer to other entities in the database. The result is a tree with great nesting. To pull out this tree, you need to make dozens of queries to the database, which adversely affect performance.
Initially, it was clear that campaign caching would have to be attributed, but we strictly followed the first optimization rule — not optimize until the system performance satisfies us. But, of course, as a result, the moment came when it was impossible to live without caching.
There were no questions at what point the cache should be reset - it needs to be updated whenever there is a change in the campaign or its element (since the campaign is an aggregate, there are no difficulties in implementing this logic). But I had to think a little about the question of where to store this cache and how to reset it. The following options were considered:
- store cache in redis and clear when editing campaigns
- store the cache in Redis and, before each use, make a request to the database to check if the date of the campaign has changed
- keep the cache in the memory of the process and, before each use, make a request to the database to check if the date of the campaign has changed
The option of using Redis is attractive because it allows you to keep only one copy of the cache for all WEB servers, and not load it for each server, but in fact it saves on matches: campaigns after the end of the configuration rarely change and it doesn't matter if the cache loaded four times a day or sixteen. Since there are no distributed transactions between Redis and the database, it is difficult to guarantee that when a campaign changes, the cache will be reset, so the first option is no longer possible.
')
The third option has the following advantages over the second:
- To get the cache, you need to perform one request over the network instead of two.
- no need to mess around with serialization (even if all you need to do is to put DataMemberAttribute on the required fields)
In general, the problem and the general approach to the solution are clear. Further technical details will follow.
Version 1.0
In order to fully use the entities within the current DataContext that are loaded in another DataContext, they need to be cloned and tagged. When attaching an entity is added to the IdentityMap of the current DataContext. You cannot attach the same entity to two different DataContext (therefore, each clone can be used only in one DataContext, that is, in one business transaction). MemberwiseClone cannot be used for cloning, since in this case there will be links to entities cloned to the DataContext in which the entity was loaded, and not to the current DataContext.
As a result, in order to be able to use entities from the static cache, the following code was written in the base class of the repository, using Linq MetaModel and a little Reflection:
code
public TEntity CloneAndAttach(TEntity sourceEntity) { if (sourceEntity == null) throw new ArgumentNullException("sourceEntity"); var entityType = sourceEntity.GetType(); var entityMetaType = GetClonningMetaType(entityType); var entityKey = entityMetaType.GetKey(sourceEntity); // , . // . if (attachedEntities.ContainsKey(entityKey)) { return attachedEntities[entityKey]; } var clonedObject = Activator.CreateInstance(entityType); var clonedEntity = (TEntity)clonedObject; attachedEntities.Add(entityKey, clonedEntity); // foreach (var dataMember in entityMetaType.Fields) { var value = dataMember.StorageAccessor.GetBoxedValue(sourceEntity); dataMember.StorageAccessor.SetBoxedValue(ref clonedObject, value); } // EntityRef' foreach (var dataMember in entityMetaType.EntityRefs) { var thisKeyValues = dataMember.Association.ThisKey .Select(keyDataMember => keyDataMember.StorageAccessor.GetBoxedValue(sourceEntity)) .ToArray(); if (thisKeyValues.All(keyValue => keyValue == null)) { continue; } var repository = Repositories.GetRepositoryCheckingBaseTypeFor(dataMember.Type); var value = repository.CloneAndAttach(dataMember.MemberAccessor.GetBoxedValue(sourceEntity)); dataMember.MemberAccessor.SetBoxedValue(ref clonedObject, value); } // EntitySet' foreach (var dataMember in entityMetaType.EntitySets) { var repository = Repositories .GetRepositoryCheckingBaseTypeFor(dataMember.Type.GenericTypeArguments[0]); var sourceEntitySet = (IList)dataMember.MemberAccessor.GetBoxedValue(sourceEntity); var clonedEntitySet = (IList)Activator.CreateInstance(dataMember.Type); foreach (var sourceItem in sourceEntitySet) { var clonedItem = repository.CloneAndAttach(sourceItem); clonedEntitySet.Add(clonedItem); } dataMember.MemberAccessor.SetBoxedValue(ref clonedObject, clonedEntitySet); } table.Attach(clonedEntity); return clonedEntity; } private ClonningMetaType GetClonningMetaType(Type type) { ClonningMetaType result; // ConcurrentDictionary, Reflection if (!clonningMetaTypes.TryGetValue(type, out result)) { result = clonningMetaTypes.GetOrAdd(type, key => new ClonningMetaType(MetaModel.GetMetaType(key))); } return result; } private class ClonningMetaType { private readonly MetaType metaType; private readonly IReadOnlyCollection<MetaDataMember> keys; public ClonningMetaType(MetaType metaType) { this.metaType = metaType; keys = metaType.DataMembers .Where(dataMember => dataMember.IsPrimaryKey) .ToArray(); Fields = metaType.DataMembers .Where(dataMember => dataMember.IsPersistent) .Where(dataMember => !dataMember.IsAssociation) .ToArray(); EntityRefs = metaType.DataMembers .Where(dataMember => dataMember.IsPersistent) .Where(dataMember => dataMember.IsAssociation) .Where(dataMember => !dataMember.Association.IsMany) .Where(dataMember => dataMember.Member.HasCustomAttribute<CacheableAssociationAttribute>()) .ToArray(); EntitySets = metaType.DataMembers .Where(dataMember => dataMember.IsPersistent) .Where(dataMember => dataMember.IsAssociation) .Where(dataMember => dataMember.Association.IsMany) .Where(dataMember => dataMember.Member.HasCustomAttribute<CacheableAssociationAttribute>()) .ToArray(); } public IReadOnlyCollection<MetaDataMember> Fields { get; private set; } public IReadOnlyCollection<MetaDataMember> EntityRefs { get; private set; } public IReadOnlyCollection<MetaDataMember> EntitySets { get; private set; } public ItcEntityKey GetKey(object entity) { return new ItcEntityKey( metaType, keys.Select(dataMember => dataMember.StorageAccessor.GetBoxedValue(entity)).ToArray()); } } So that when cloning, when going through the EntityRef and EntitySet, do not unload half of the database, only those that are marked with the special attribute CacheableAssociationAttribute are cloned.
Since the cache is loaded in a separate DataContext, and cloning occurs after its Dispose, we had to write a method that loads all cached associations for the loaded entity:
code
public void LoadEntityForClone(TEntity entity) { // , if (loadedEntities.Contains(entity)) { return; } loadedEntities.Add(entity); var entityType = entity.GetType(); var entityMetaType = GetClonningMetaType(entityType); // EntityRef' foreach (var dataMember in entityMetaType.EntityRefs) { var repository = Repositories.GetRepositoryCheckingBaseTypeFor(dataMember.Type); var value = dataMember.MemberAccessor.GetBoxedValue(entity); if (value != null) { repository.LoadEntityForClone(value); } } // EntitySet' foreach (var dataMember in entityMetaType.EntitySets) { var repository = Repositories .GetRepositoryCheckingBaseTypeFor(dataMember.Type.GenericTypeArguments[0]); var entitySet = (IList)dataMember.MemberAccessor.GetBoxedValue(entity); foreach (var item in entitySet) { repository.LoadEntityForClone(item); } } } Of course, if you use DataLoadOptions, you will need fewer requests to load the EntityRef. But we didn’t even think about building DataLoadOptions dynamically, because Linq to SQL has a bug that, when using DataLoadOptions to load EntitySet, the entity type incorrectly loads (the type discriminator ignores the parent type instead of the child type).
Since we access the records in the database via the repositories, I also accessed the cache references there. When you try to get a campaign or campaign element, the following happens:
- Checks if the campaign has already been added to the current DataContext from the cache. If so, then return an object that has already been cloned and zatattachen.
- If the campaign is not in the cache, we load it into the cache. Otherwise, we compare the date of the last change of the campaign in the database with the date of the last change of the campaign stored in the cache, and if they are different, restart the campaign.
- We clone and attach a campaign and all its elements to the current DataContext.
With this approach, we only attach campaigns that we need and check the relevance of the cache (the date the campaign was changed) only once per transaction (once during the lifetime of the DataContext). Since there are many methods in the repositories for retrieving campaign elements (by Id, by campaign, by unique string identifier), the cache data structure is complicated, but you can live with it.
The new caching architecture passed all integration tests and was successfully laid out on the Production of one of the projects. Everything worked steadily and nothing foreshadowed trouble.
Something went wrong
After laying out the cache for the next project, the following errors en masse fell: “DuplicateKeyException: cannot be an anonymous client” when the campaign attaches to the current DataContext. The first thought: “We made a mistake somewhere in our recursive cloning code and attach the same entity twice.” Turned out to be wrong. The mistake was more conceptual.
Who is guilty
The code was to blame for the final project, which accessed the campaign without using the cache before attaching the same campaign from the cache. As I wrote above, when attaching an entity is added to IdentityMap, but if before that the entity has already been loaded from the database, then it already exists in IdentiyMap and an attempt to add an entity with the same key causes an error. Linq to SQL does not allow you to check whether an entity is in the IdentityMap before attaching. And if you catch and ignore errors during attachments, the caching would turn out to be incomplete.
There was an idea to remove from the repositories working with the cache, the ability to access the database bypassing the cache. Besides the fact that this is far from an easy task, it would not solve the problem completely, since many non-cacheable entities have EntityRef for cached entities, and when accessing the EntityRef, the request goes past the repository.
What to do
There are two options for solving this problem:
- Remove from cached repositories the ability to access the database bypassing the cache and remove all cached references from all non-cached entities.
- Attach the cache when creating a DataContext before any other database queries are executed.
The first option would require rewriting half the code. At the same time, the resulting code would be more cumbersome, since everywhere where there was an appeal to the EntityRef, you would have to use the methods of the repositories. So I had to stop at the second version.
Since we attach entities when creating a DataContext, and not when accessing specific entities, we will have to explicitly specify at the beginning of the transaction which entities from the cache we need (loading the entire cache every time would be clearly redundant). That is, the approach chosen is not universal caching; it only allows you to fine-tune the use of the cache for individual transactions.
New architecture
In some of our repositories, the results of queries on Id to entities were cached for the duration of the transaction in the Dictionary. In fact, this transaction cache can be considered our IdentityMap used on top of Linq to SQL IdentityMap. We needed only to transfer the transaction cache to the base repository and add access methods to it not only by Id, but also in other ways. As a result, we got a transaction cache class, when accessed by any method, each entity is loaded no more than once. If we, for example, request an entity first by Id, and then by a unique string identifier, the second query will not be executed and the access method will return the entity from the cache.
Since we now have a transaction cache in any repository, to support static caching, it is enough to fill in the transaction cache from the static cache while creating a DataContext, while not forgetting to clone and attach each entity. It all looks like this:
If we talk specifically about campaign caching, then loading a static cache works like this:
- In the factory that creates the DataContext along with all the repositories, IQueryable is transferred from the campaigns, describing which campaigns we need.
- With one request, the Id and the date of the last change of campaigns from the transmitted IQueryable are pulled out.
- For each campaign, the pulled out date is checked against the date of this campaign in the cache and, if different, the campaign, along with all its elements, is reloaded.
- All entities pulled from the static cache are attacked and loaded into the transaction caches of the corresponding repositories.
What's next
Then you can customize caching for other transactions as needed. In addition to the static cache for campaigns, general classes were created for static caching of dictionaries, which change only when the application is displayed. Those. caching any entities for which you do not need to check the relevance of the cache is very easy to enable. In the future, I want to expand this functionality by adding the ability to reset the cache after a certain time, or by simple queries in the database. It may be possible to remake the caching of campaigns to use the standard static cache classes with the necessary settings.
Although the resulting architecture looks slim and allows you to uniformly implement different types of caching, the need to clearly indicate what entities we need at the beginning of a transaction is not encouraging. In addition, in order to load all entities needed in a transaction and not attach a lot of unnecessary objects to the context, you need to know the transaction structure in detail.
There is another cache implementation that, unfortunately, cannot be implemented in Linq to SQL — replacing the standard IdentityMap with its implementation, which, before adding an entity, tries to get it from the cache. With this approach, a cached entity loaded in any way will be replaced with its copy from the cache, which already has all EntityRef and EntitySet loaded. Thus, you will not need to do any subqueries to get them. If you add an entity search in IdentityMap to the most frequently used repository methods before querying the database, the number of database queries will be drastically reduced. At the same time, you can search for any entities in the IdentityMap, not just those for which static caching is used. Since after receiving any entity from the database, it is replaced with its copy from IdentityMap (if it is already there), during the DataContext lifetime one cannot get two different copies of one entity, even if it was changed in another transaction (the first loaded entity will always be returned ). Therefore, there is no point twice in requesting an entity per transaction, for example, by key, and any requests by key during the transaction can be cached by checking the IdentityMap before the request.
We will try to implement this architecture after we go to the Entity Framework. EF allows you to get entities from IdentityMap, so that at least partially the architecture can be improved.
Source: https://habr.com/ru/post/255231/
All Articles