The global importance of English, German, Russian, Chinese and other languages on the Internet (Data Mining)
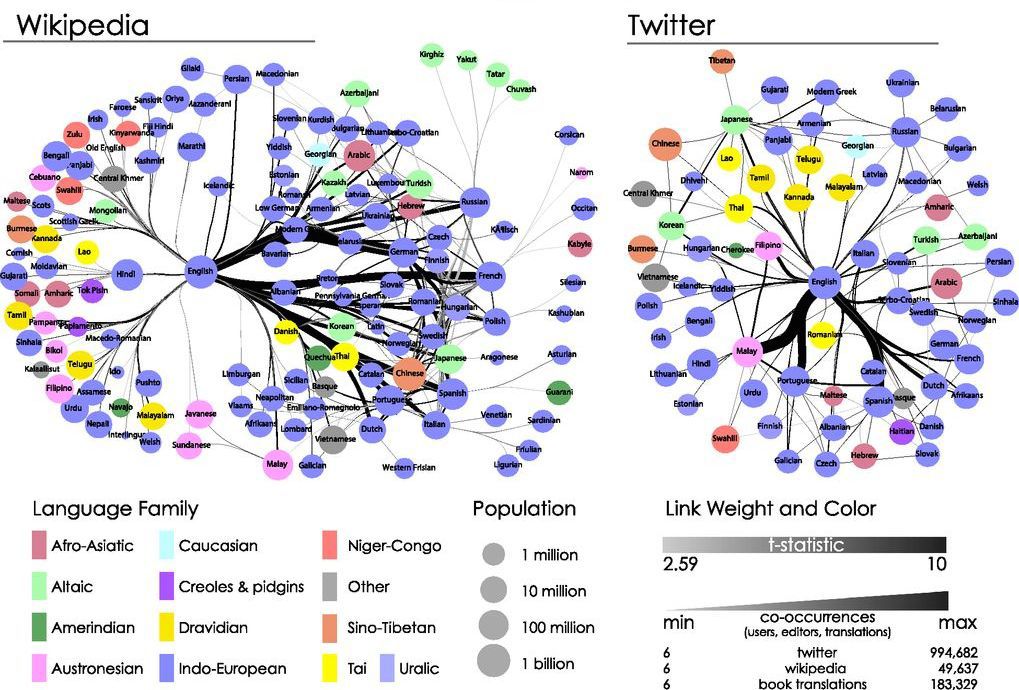
The central languages on this map may not have the largest number of speakers, but they serve as “common” languages for communication of elites.
In the young direction, Big Data has its rising stars and promising leaders, one of the most striking is Caesar Hidalgo - a professor at MIT Media Lab, the developer of an online platform for visualizing data on trade relations between different countries of the world Observatory of Economic Complexity , and one of “50 people that will change the world, ” according to Wired.
')
Several years ago, Cesar and his comrades wanted to explore the relationship of language nodes on the Internet. Languages differ in importance for a bunch of reasons: from technical to demographic. The task was set to be ambitious - to determine the global significance of the language, which does not depend on simple demographic and economic indicators. About what came out of this, read the post below.
The main information in the three global language networks (GLN) is in English - central, as well as a few less common: Spanish, German, French, Russian, Portuguese and Chinese. The significance of the language is in direct proportion to the number of popular people speaking it. The position of the language in GLN also contributes to drawing attention to its speakers and to the cultural content they produce.
The first question, of course, is how to measure the global influence of a language. Prior to this, research was based on the number and well-being of native speakers. However, historically, the spread of the language required serious political support, so these indicators do not greatly affect the globality of the language, since its speakers and their wealth can be concentrated on a relatively small scale. Another method of measuring the global influence of a language is to determine who its carrier is, as well as on the relationship between speakers. Linguist David Crystal states: “The popularity of a language has nothing to do with the number of its speakers. Much more important is who they are. ” In the past, Latin was a common European language, not because it was the mother tongue of most Europeans, but because it was the language of the Roman Empire, and later the Catholic Church, scholars and educators. The use of Latin by the elites and the connection between them, helped her to hold out as a universal language for more than 1000 years.
At the same time in the modern world language card looks like this (again):
Fulsized
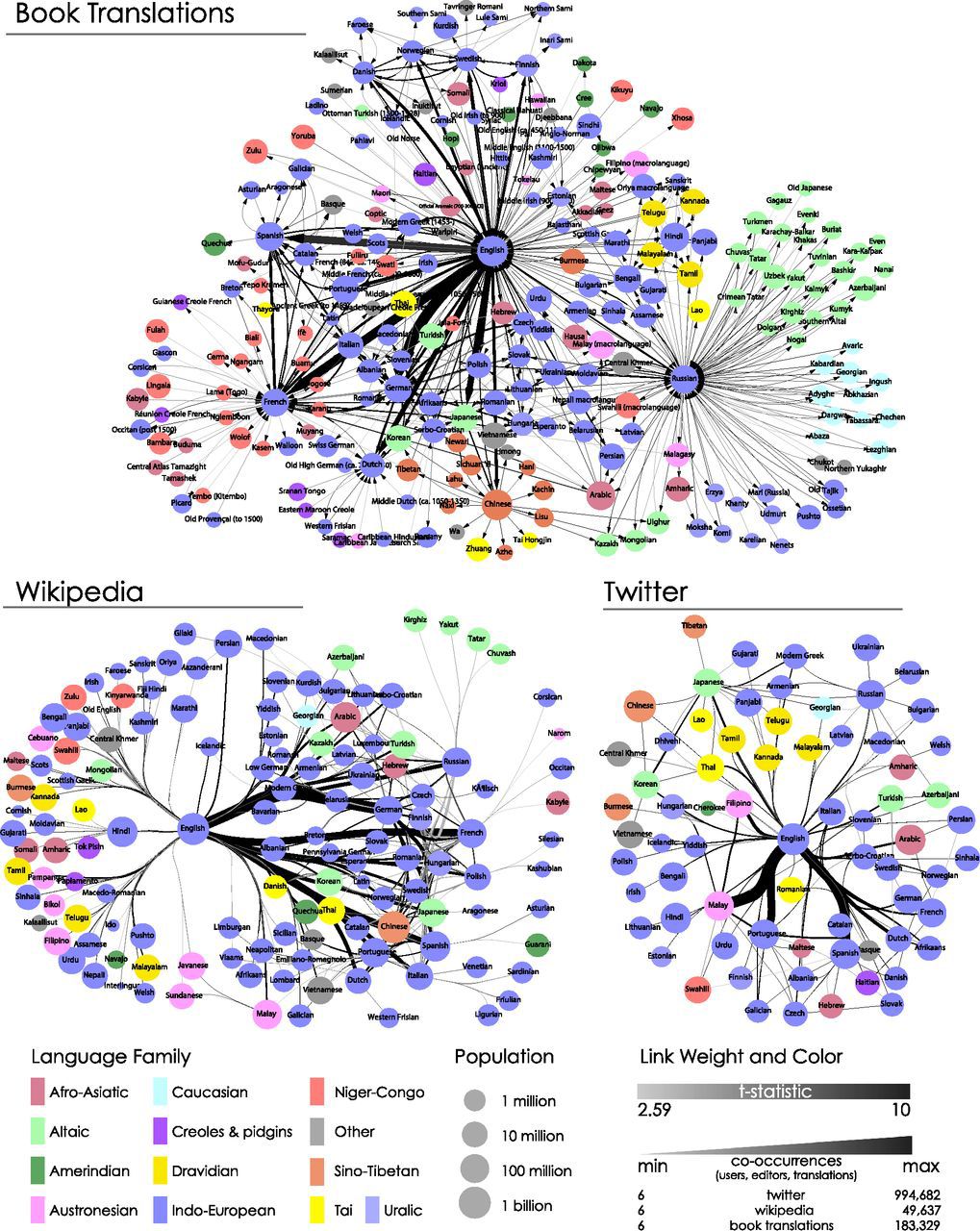
To begin with, we will look at a collection of over 2.2 million book translations compiled by a UNESCO project. This data set allows you to display a network of book translations from authors and professional translators. It was based on the market demand for books in different languages. Each translation from one language to another forms a link. Then we map the multi-language network used by Wikipedia editors. Here, the relationship between languages is formed when a user edits an article in one language version of Wikipedia and with considerable probability edits it in another language version. Finally, we map the language sharing network on Twitter. Here a connection is formed if the user writes a message in one language and is more likely to write it in another.
Languages have a disproportionate degree of influence, as some provide direct and indirect ways of translation between most other languages of the world. For example, in order for a Spaniard to understand an Englishman, a bilingual speaker of English and Spanish is needed. However, the native Vietnamese can understand the native speaker of the language Mapudungun only through workarounds, for example, according to the scheme: Vietnamese - English, English - Spanish, Spanish - mapudungun. In both cases, Spanish and English are involved in the communication process and act as global languages.
Fulsized
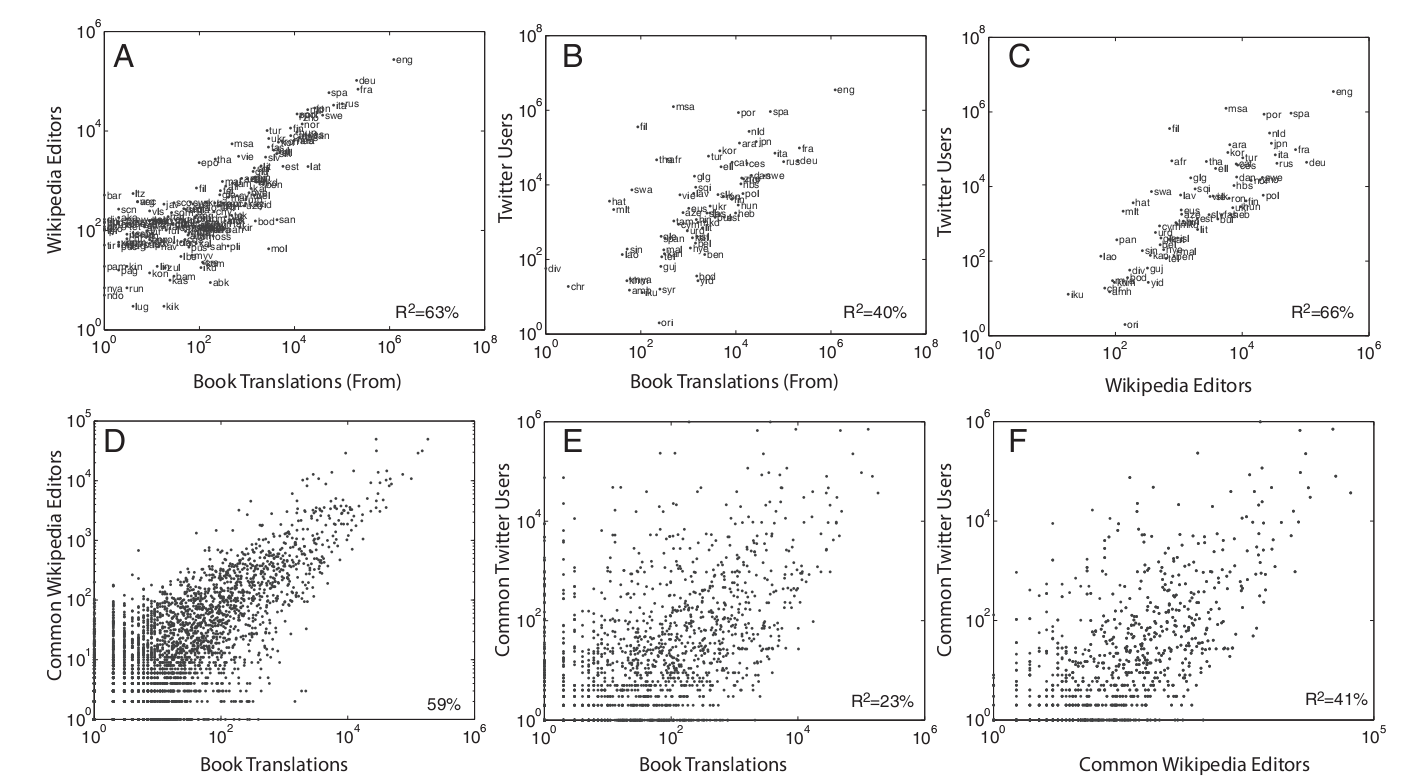
These illustrations show the similarity of the three independent data sets that we use to display the GLN. The top row shows the relationship between the number of expressions for each language in all three data sets: (a) editing Wikipedia articles in the language and translating books from the language; (B) Twitter messages in the language and translation of books from the language; (C) Twitter users and editors on Wikipedia. The bottom row shows the relationship between the number of identical phrases for language pairs in different data sets: (D) the total number of book translations and Wikipedia editors; (E) the total number of Twitter users and book translations; (F) Twitter users and Wikipedia editors. In D and E, we systematized the average number of translations from and to language.
The impact of global languages
Logically, an Englishman, as located on one of the nodes, is easier to influence the language network than a resident of Nepal. The more globalized the language, the more incentive it is to create content on it and translate information from less popular languages into it. For example, a reporter who wants to spread the news about a major event around the world will do it in a global language.
Fulsized
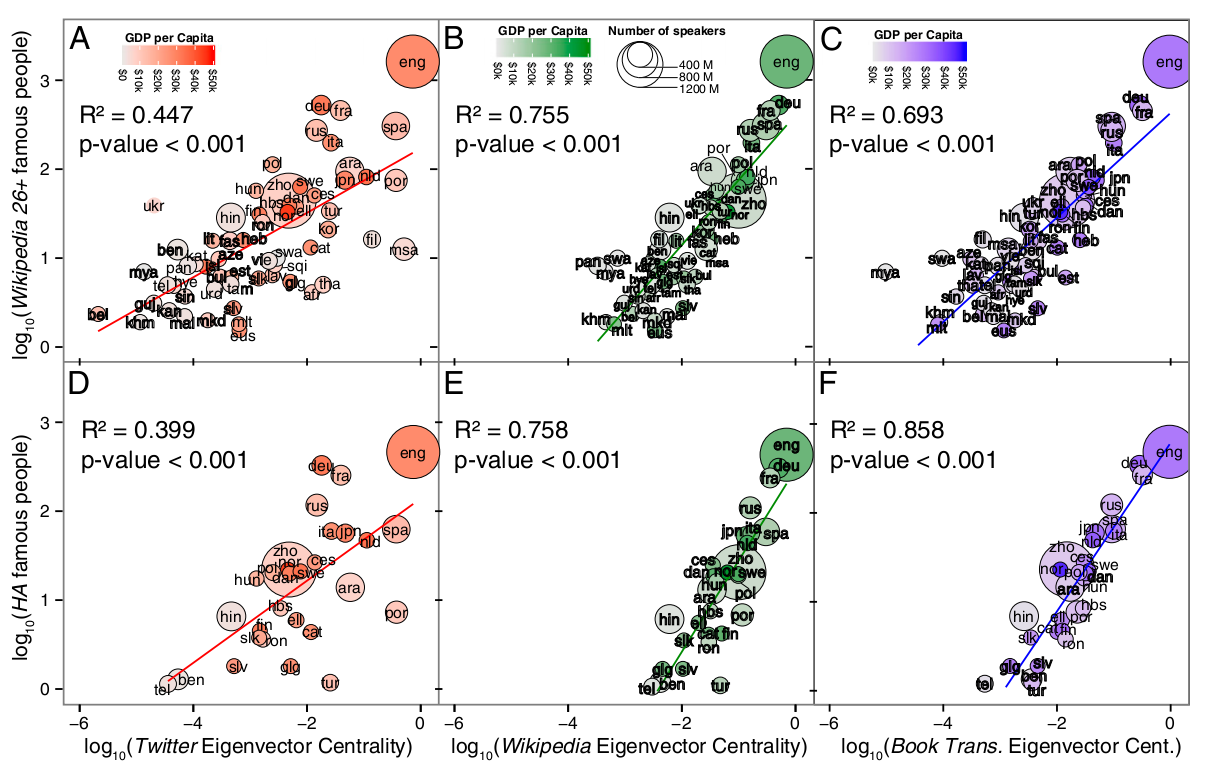
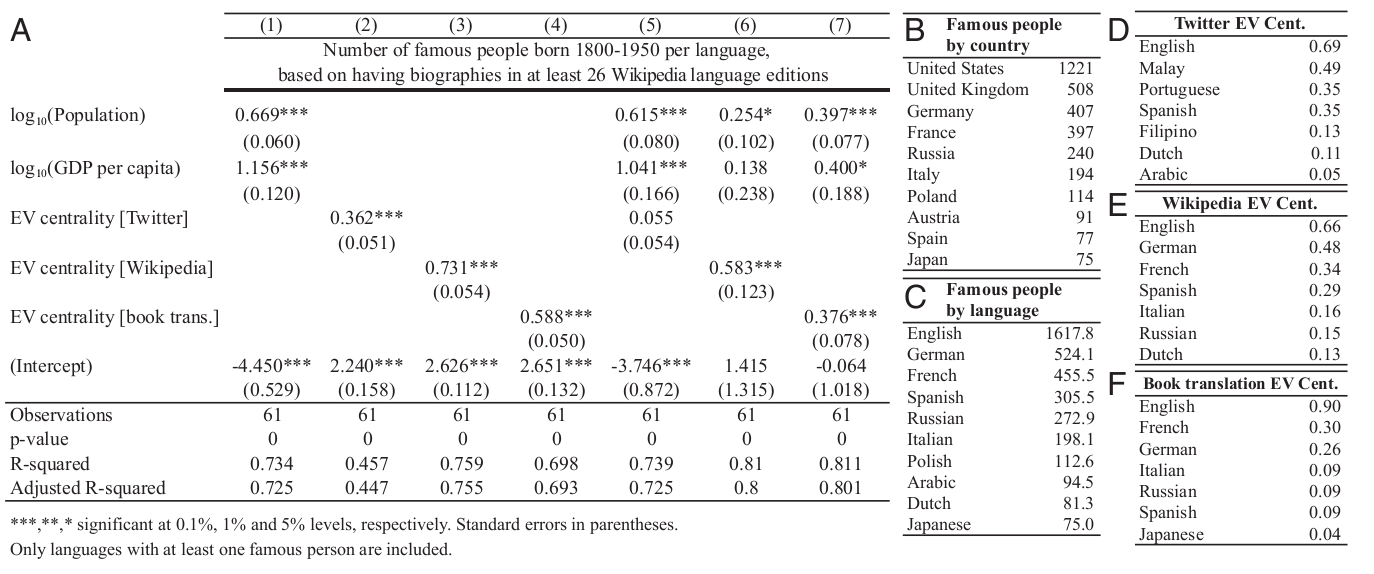
In the illustration, the position of the language in GLN and the global influence of its speakers. The top row shows the number of native speakers (birth years 1800-1950), about which articles were written in at least 26 language versions of Wikipedia, as a function of the centrality of the language’s own vector in (A) GLN Twitter, (B) GLN Wikipedia and (C) GLN book translations. The bottom row shows the number of native speakers (birth years 1800-1950), which are mentioned in Human Accomplishmentas, as functions of the centrality of the native language vector in (D) GLN Twitter, (E) GLN Wikipedia, and (F) GLN book translations. The size depends on the number of speakers of each language, and the intensity of the color - on GDP per capita.
Caesar then collected Twitter data from more than one billion tweets published between December 6, 2011 and February 13, 2012. The language of each tweet was detected using the Chromium Compact Language Detector after clearing hashtags, links, and emoticons. Only messages were used where the chance of a false positive was less than 10%. The final data set consists of nearly 550 million tweets in 73 languages, created by over 17 million unique users. Two languages are considered related if the user has posted a tweet in one language and is more likely to write it on the other.
The Wikipedia data set was compiled while editing the history of all language sections of Wikipedia written in late 2011. After removing information from bots and applying filters, 382 million edits were made in 238 languages from 2.5 million unique editors. Here, the two languages turned out to be related if the user edited the article in one language and most likely did the same on the other.
The translation index data set (PI) consists of 2.2 million translated books published between 1979 and 2011 in 150 countries in more than a thousand languages. The data set contains a list of translations, not a list of translated books. Each translation in it is taken into account separately, for example, Tolstoy’s 22 independent translations of “Anna Karenina” from Russian into English. In the network display, we take into account each transfer separately, and in this case 22 transfers were taken into account, and not one. Also note that the source of translation may differ from the language of the original book. For example, the PI contains data on 15 translations of "Tom Sawyer", 13 of which were made directly from English, and 2 from Spanish and Galician. This dataset feature allows you to define intermediate languages for translation.
In all three cases, we depicted similar languages in accordance with ISO 639-3 (10). For example, Indonesian and Malaysian languages are coded as Malay, and all Arabic dialects are Arabic.
results
Fulsized
In the illustration, concentration and number of famous people in GLN for each language according to Wikipedia. (A) The number of people (born in 1800-1950) for each language, about which there are articles in at least 26 language variants of Wikipedia, depending on GDP per capita, population size and centrality of its own vector for each GLN. Rating of cultural production: (B) countries and (C) languages with the largest number of people about which there are articles in at least 26 language versions of Wikipedia. GLN's own ranking of language values: top seven languages on (D) Twitter, (E) Wikipedia and (F) book translation networks.
As can be seen from the results, a language with a large number of links in one GLN will have many links in another network. Positive correlations of expressions and connections in language pairs suggest that all three GLNs are similar in terms of the strength of connections and the number of representatives of a particular group. Interestingly, the common features observed in the three GLNs are determined, apparently, by the need for certain literary skills to participate in each of these networks. The network of book translations is the most demanding of this factor (since there are authors and professional translators in it), while Twitter is the least demanding (as it consists of short messages that anyone with Internet access can post). Wikipedia is the middle point between book translations and Twitter in terms of literary skills, and its GLN is also in the middle in terms of similarity.
There is a hypothesis that a person translates information from a central language into his own, since it deserves more attention, or the hypothesis that a person born in a country with a central language has more chances to achieve world fame.
It can be argued that the peripheral arrangement of the Hindi, Chinese and Arabic languages in GLN is due to the inadequate representation in the world of these and some other languages that connect to them. These languages may be central to various media, but their weak role in the three global networks - Twitter, Wikipedia and the book translation network, weakens their claims to global influence. In addition, Chinese, Arabic and Hindi could not be central languages, even if databases had better indicated their connection with various regional languages, since the central language should connect even very distant languages, and not only local ones.
Lecture
Caesar Hidalgo can tell a lot about the importance of working with big data. He believes that any economic growth is a special case of the growth of information in the Universe. At the same time, the growth of information in economies is limited by the ability of people to form social networks.
Caesar will speak at Digital October on April 22 with an open lecture (telebridge) “Why is the amount of information growing all the time?”. The language is English, plus each participant receives a radio device for simultaneous translation into Russian, so there will be no problems with understanding. Register for the event and come to visit, it will be interesting.
Source: https://habr.com/ru/post/255189/
All Articles