Cloud services under high load. Cackle experience
Hello! We, at Cackle , have been developing cloud SaaS solutions for websites since 2011. Our products are installed on more than 10,000 sites, every day we process an average of 65 million unique hits. The bandwidth of the peaks reaches 780 Mb / s, and the database receives up to 120 million read requests per day, and up to 300 thousand write requests. Such loads force us to invent difficult solutions, part of which we want to share.

First, a few words about what we have developed in general, on what technologies and architecture everything is based, where the high load comes from. And then - about 5 main decisions that we use to cope with this load.
Cackle Comments is our first product announced in 2011.
')
Simplifies the process of commenting due to convenient authorization - anonymous, social or one with your site. It helps to attract more traffic due to indexing in search engines, broadcast comments on the walls of social networks (VK, My World, Facebook, Twitter), subscribe to new comments and replies. Reduces the load due to the independence of your site.
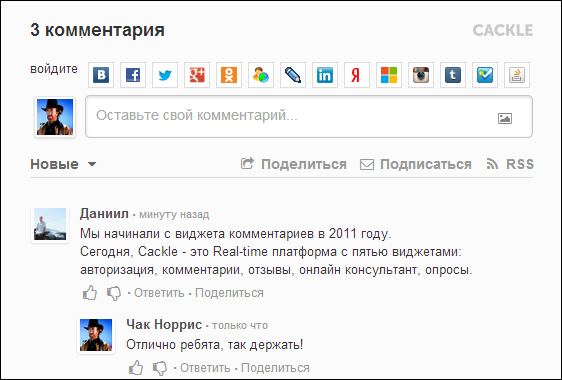
Cackle Reviews is a review system, which was released in 2013. Used mainly online stores, but works without any problems on any site.
Key features:
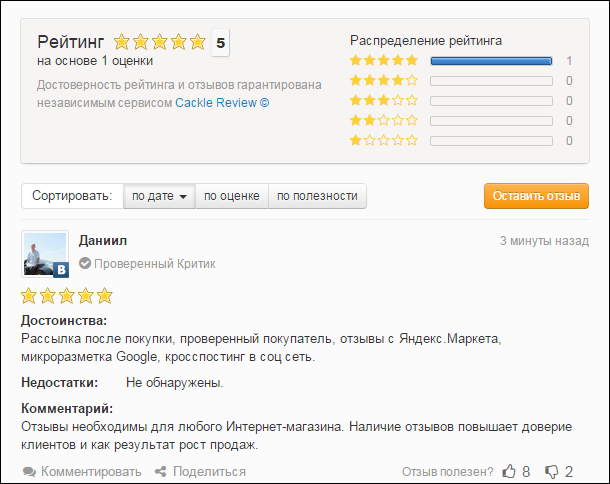
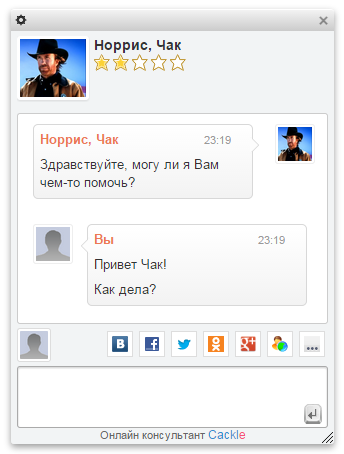
Cackle Live Chat - online chat for site visitors, release in 2013.
Of the features: quick installation, the operator panel is implemented in the browser, no need to spend time installing the desktop client. Social authorization of users, the operator receives information about the client (name, photo, email, link to the profile).
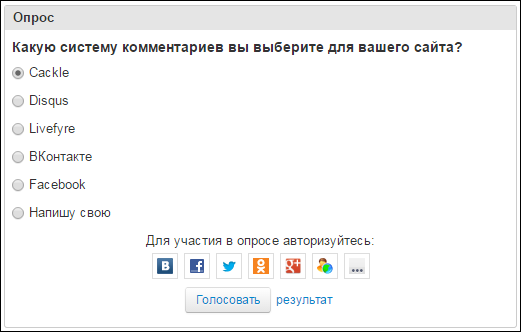
Cackle Polls - polls with the possibility of voting via social networks, IP or Cookie, the release also in 2013.
Polls are automatically indexed by Google, attracting additional traffic. You can upload images, there is video recognition YouTube and Vimeo.
The frontend in the understanding of Cackle is JavaScript. Backend - data and logic server.
The frontend consists of widgets. A widget is an executable JavaScript library based on other common JavaScript libraries. Examples of shared libraries:
All widgets work without an iframe, due to which css can be modified to fit your site.
There is a common widget loader (widget.js), something like RequireJS, just simpler. The loader has two modes of operation - devel and prod. The first is used in the development, loads the library in a loop. The second is in production, loads the assembled bundle. In prod mode, widgets are loaded from different servers randomly selected, resulting in balancing (more on this later).
This is a cluster of Apache Tomcat containers wrapped outside by Nginx servers. Nginx in this case acts not only as a proxy, but also as an “absorber” of the load. PostgreSQL database with streaming replication for several slaves.
All backends are distributed across several data centers (Data Centers) of Russia and Europe. Our experience has shown that hosting all servers in one data center is too risky, so now we are connected to three different data centers.
Support for real-time updates (comments, likes, editing, moderation, personal messages, chat) on the browser side, via any of the supported technologies: WebSocket, EventSource, Long-Polling. That is, first we check if there is a WebSocket, then EventSource, Long-Polling. In case of disconnects (errors), the connection is automatically restored by a function that monitors the connection status in setTimeout.
On the server, we use the cluster Nginx + module Push Stream . Only 3 servers: 2 common and 1 for online consultant. Real-time messages from backends (Tomcat) are sent to all servers. And in the browser, when connecting from the widget, any server is selected (randomly). The result is something like balancing (unfortunately, Push Stream does not support balancing out of the box).
In addition, there are:
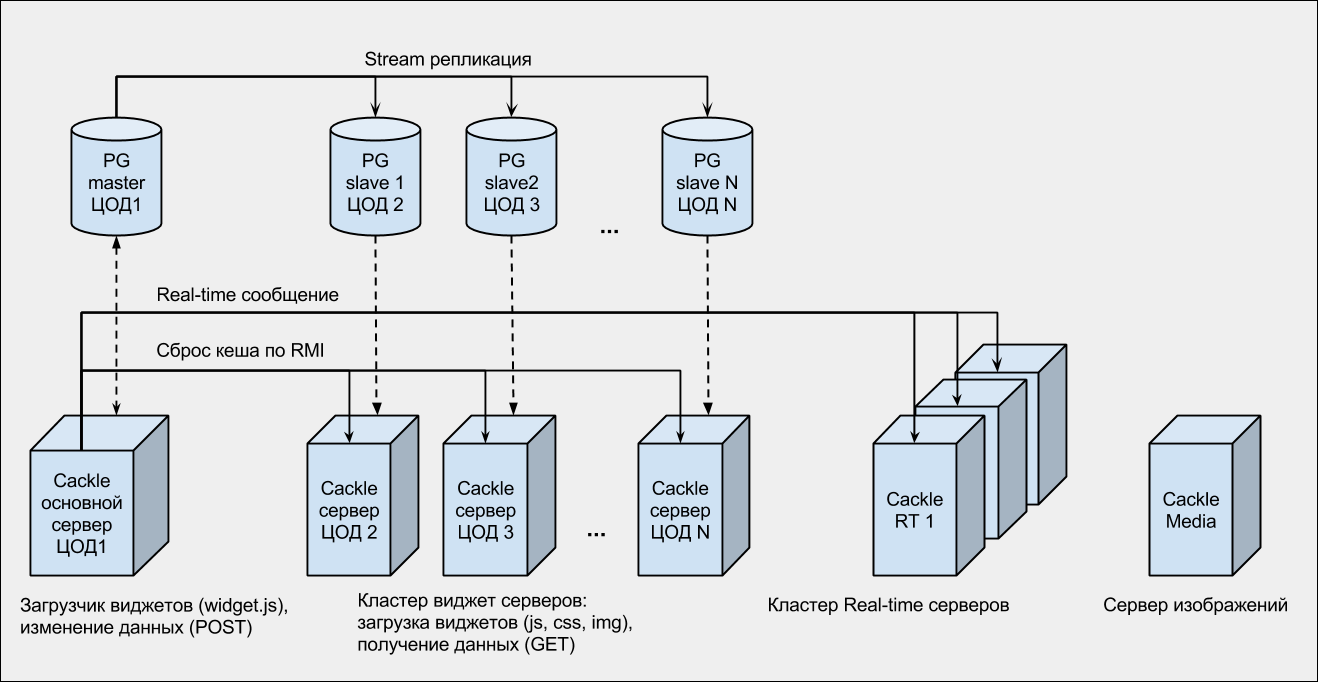
PG - PostgreSQL.
RT - Real-time.
DPC (1,2, ..., N) - various data centers.
RMI - Java technology remote method call ( wikipedia ).
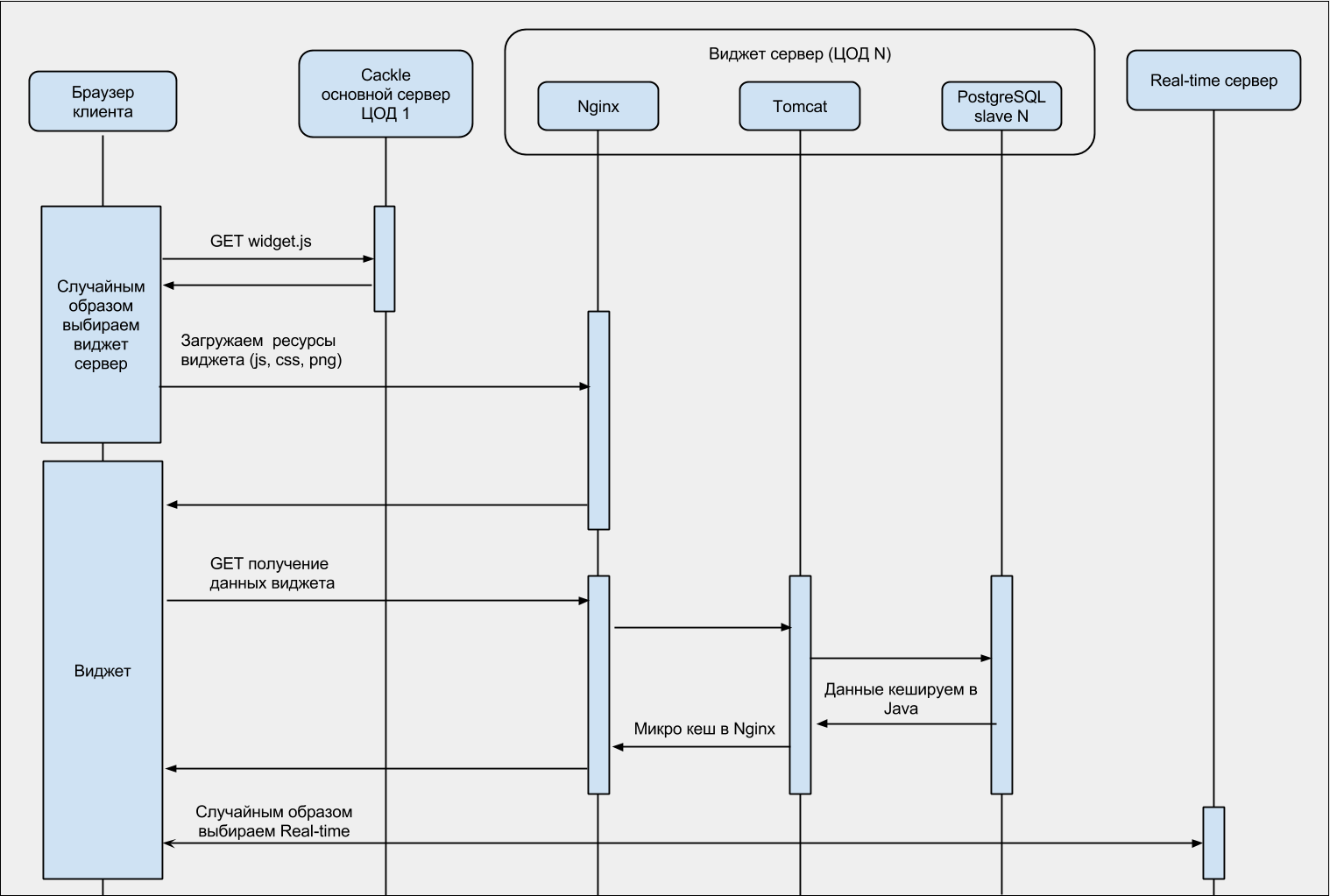
For better understanding, the widget loading sequence diagram:
Below is a summary of the statistics on widgets and API calls.
Unique hits per day: 60 - 70 million
Peak requests per second: 2700
Peak simultaneous real-time sessions: 300,000
Peak bandwidth: 780 Mbps
Traffic per day: 1.6 TB
Nginx daily log summary: 102 GB
Queries to the database for reading (per day): 80 - 120 million
Requests to the database to write (per day): 300 000
Number of registered sites: 32 558
Number of registered users: 8 220 681
Comments posted: 23 840 847
Daily average increment of comments: 50,000
Daily average increase of users: 15 000
High load causes two problems:
First, almost all hosters have a default server bandwidth of 100 Mb / s. Anything higher is cut or, at best, you are asked to purchase additional lanes (and the prices there are several times higher than the cost of the servers themselves).
The second problem is the load itself. Physics can not be fooled, no matter how cool your server is, it has its limit.
Standard load sharing methods talk about balancing an input request on a server. This will solve the second problem, but not the first one (bandwidth), since the outgoing traffic will still go through the same server.
To solve two problems at the same time, we do the balancing in JavaScript, in the loader itself (widget.js), choosing the backend randomly. As a result, the traffic is redirected to the servers from the cluster server widget, dividing the bandwidth between them and distributing the load.
An additional huge plus of this method is caching javascript. All libraries (including the widget.js loader), when refreshing the page, will be obtained from the browser cache, and our servers will continue to calmly process new requests.
Loader code continuation (widget.js part 2):
It's great! The only problem is that with our volumes and loads, in order to use CDN it is necessary to raise prices at least 3 times, while maintaining the current turnover.
A microcache is a cache with a very short lifespan, for example 3 seconds. It is very useful at peak loads, with thousands of identical GET requests per second. For us, this is widget data in JSON format. It makes sense to make a microcache in proxy servers, for example, Nginx to protect the main backend (Tomcat).
Part of the Nginx config with a microbag:
If there are problems with understanding this config, then it is mandatory to read ngx_http_proxy_module .
Especially tune Tomcat will not work. From practical experience:
It is considered to be a DB, in high-loaded projects, as a weak point. It really is. For example, the server accepts the request, sends it to the service level, where the service accesses the database and returns the result. The link “service - DB (relational)” in this case is the slowest, so it is customary to wrap services with a cache. Accordingly, the result from the database is placed in the service cache, and the next time it is used, it is taken from it.
For caching services, we have developed our own cache, since standard ones (for example, Ehcache) work slower and do not always solve specific problems well. Of the specific tasks we have is caching with support for several keys for one value. We use org.apache.commons.collections.map.MultiKeyMap.
You need this for what tasks. For example, a user visits a page with comments. Suppose a lot of comments, 300 pieces. They are divided into three pages (pagination), respectively, 100 each. When first accessed, the first page will be cached (100 comments), if the user scrolls down, then 2 and 3 pages will be cached in turn. Now the user publishes a comment on this page and here you need to reset all three caches. Using MultiKeyMap it looks like this:
Below is the kernel cache code that works fine on highload.
In our opinion, PostgreSQL is the best solution for high-load projects. Now it is fashionable to use NoSQL, but in most cases, with the right approach and the right architecture, PostgreSQL is better.
In PostgreSQL, streaming replication works fine, and it does not matter in one subnet or in different networks, different data centers. We have, for example, database servers located in several countries and no serious problems have been noticed. The only caveat is large database modifications (ALTER TABLE) for releases. It is necessary to make them in pieces, trying not to perform the whole UPDATE at once.
There are a lot of resources on setting up replication, this is a hackneyed topic, so there’s nothing really to add, except:
Do not forget to tune the parameters of the OS kernel , because without this some settings of Nginx or Tomcat simply will not work.
We have, for example, Debian everywhere. In the OS kernel settings (/etc/sysctl.conf) special attention should be paid to:
Rather, one problem - the size of the database. There is sharding, of course, but we have not yet found a standard solution for PostgreSQL without a drop in performance. If someone can share practical experience - welcome!
Thanks for attention. Questions and suggestions on our system are welcome!
First, a few words about what we have developed in general, on what technologies and architecture everything is based, where the high load comes from. And then - about 5 main decisions that we use to cope with this load.
Commenting system
Cackle Comments is our first product announced in 2011.
')
Simplifies the process of commenting due to convenient authorization - anonymous, social or one with your site. It helps to attract more traffic due to indexing in search engines, broadcast comments on the walls of social networks (VK, My World, Facebook, Twitter), subscribe to new comments and replies. Reduces the load due to the independence of your site.
Online Store Feedback System
Cackle Reviews is a review system, which was released in 2013. Used mainly online stores, but works without any problems on any site.
Key features:
- Loading reviews from Yandex.Market;
- Indexing to Google with micromarking out of the box ( ranking in search results );
- Follow-up sending letters with an invitation to leave a review after purchase;
- Convenient anonymous, social, unified authorization;
- Broadcast reviews in social networks: VK, My World, Facebook, Twitter;
- Moderation reviews in real time;
- Comments on reviews;
- SPAM protection;
- CMS plugins: 1C-Bitrix , Joomla (K2, Virtuemart, Zoo) , OpenCart , PrestaShop .
Online consultant
Cackle Live Chat - online chat for site visitors, release in 2013.
Of the features: quick installation, the operator panel is implemented in the browser, no need to spend time installing the desktop client. Social authorization of users, the operator receives information about the client (name, photo, email, link to the profile).
Polls widget
Cackle Polls - polls with the possibility of voting via social networks, IP or Cookie, the release also in 2013.
Polls are automatically indexed by Google, attracting additional traffic. You can upload images, there is video recognition YouTube and Vimeo.
Technology
The frontend in the understanding of Cackle is JavaScript. Backend - data and logic server.
Frontend
The frontend consists of widgets. A widget is an executable JavaScript library based on other common JavaScript libraries. Examples of shared libraries:
- The library for working with DOM: jQuery was very slow and did not work on several mobile platforms, so they wrote their solution on Vanilla JS. As a result, for some operations, the speed of work increased 600 times + our solution works on all versions of Android and iOS;
- Single Authorization Library (anonymous, social, SSO);
- Library of support for Real-time mode with a smart choice of interaction protocol (WebSocket, EventSource, Long-Polling);
- Cross Domain Library GET / POST requests;
- And others: work with the date, browser database (cookie, localstorage), json, image upload, video recognition (YouTube, Vimeo), notification tray, pagination, etc.
All widgets work without an iframe, due to which css can be modified to fit your site.
There is a common widget loader (widget.js), something like RequireJS, just simpler. The loader has two modes of operation - devel and prod. The first is used in the development, loads the library in a loop. The second is in production, loads the assembled bundle. In prod mode, widgets are loaded from different servers randomly selected, resulting in balancing (more on this later).
Cross-browser loader code (widget.js part 1)
Cackle.Bootstrap = Cackle.Bootstrap || { appendToRoot: function(child) { (document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(child); }, // js loadJs: function(src, callback) { var script = document.createElement('script'); script.type = 'text/javascript'; script.src = src; script.async = true; if (callback) { if (typeof script.onload != 'undefined') { script.onload = callback; } else if (typeof script.onreadystatechange != 'undefined') { script.onreadystatechange = function () { if (this.readyState == 'complete' || this.readyState == 'loaded') { callback(); } }; } else { script.onreadystatechange = script.onload = function() { var state = script.readyState; if (!state || /loaded|complete/.test(state)) { callback(); } }; } } this.appendToRoot(script); }, // css loadCss: function(href) { var style = document.createElement('link'); style.rel = 'stylesheet'; style.type = 'text/css'; style.href = href; this.appendToRoot(style); }, // css loadCsss: function(url, css) { for (var i = 0; i < css.length; i++) { Cackle.Bootstrap.loadCss(url + css[i] + Cackle.ver); } }, // js loadJss: function(url, js, i) { var handler = this; if (js.length > i) { Cackle.Bootstrap.loadJs(url + js[i] + Cackle.ver, function() { handler.loadJss(url, js, i + 1); }); } }, // load: function(host, js, css) { var url = host + '/widget/'; this.loadJss(url + 'js/', js, 0); if (css) this.loadCsss(url + 'css/', css); }, /** * , , */ Comment: { isLoaded: false, load: function(host) { this.isLoaded = true; if (Cackle.env == 'prod') { // Cackle.Bootstrap.load(host, ['comment.js'], ['comment.css']); } else { // / Cackle.Bootstrap.load(host, ['fastjs.js', 'json2.js', 'rt.js', 'xpost.js', 'storage.js', 'login.js', 'comment.js'], ['comment.css']); } } }, ... }; // (widget == 'Comment') //host - ( ) if (!Cackle.Bootstrap[widget].isLoaded) { Cackle.Bootstrap[widget].load(host); } Backend
This is a cluster of Apache Tomcat containers wrapped outside by Nginx servers. Nginx in this case acts not only as a proxy, but also as an “absorber” of the load. PostgreSQL database with streaming replication for several slaves.
All backends are distributed across several data centers (Data Centers) of Russia and Europe. Our experience has shown that hosting all servers in one data center is too risky, so now we are connected to three different data centers.
Real-time
Support for real-time updates (comments, likes, editing, moderation, personal messages, chat) on the browser side, via any of the supported technologies: WebSocket, EventSource, Long-Polling. That is, first we check if there is a WebSocket, then EventSource, Long-Polling. In case of disconnects (errors), the connection is automatically restored by a function that monitors the connection status in setTimeout.
On the server, we use the cluster Nginx + module Push Stream . Only 3 servers: 2 common and 1 for online consultant. Real-time messages from backends (Tomcat) are sent to all servers. And in the browser, when connecting from the widget, any server is selected (randomly). The result is something like balancing (unfortunately, Push Stream does not support balancing out of the box).
In addition, there are:
- Server loading, processing and storage of images;
- SMTP server.
Architecture
PG - PostgreSQL.
RT - Real-time.
DPC (1,2, ..., N) - various data centers.
RMI - Java technology remote method call ( wikipedia ).
For better understanding, the widget loading sequence diagram:
Load
Below is a summary of the statistics on widgets and API calls.
Unique hits per day: 60 - 70 million
Peak requests per second: 2700
Peak simultaneous real-time sessions: 300,000
Peak bandwidth: 780 Mbps
Traffic per day: 1.6 TB
Nginx daily log summary: 102 GB
Queries to the database for reading (per day): 80 - 120 million
Requests to the database to write (per day): 300 000
Number of registered sites: 32 558
Number of registered users: 8 220 681
Comments posted: 23 840 847
Daily average increment of comments: 50,000
Daily average increase of users: 15 000
Problems
High load causes two problems:
First, almost all hosters have a default server bandwidth of 100 Mb / s. Anything higher is cut or, at best, you are asked to purchase additional lanes (and the prices there are several times higher than the cost of the servers themselves).
The second problem is the load itself. Physics can not be fooled, no matter how cool your server is, it has its limit.
»Solution 1: Balancing in JavaScript
Standard load sharing methods talk about balancing an input request on a server. This will solve the second problem, but not the first one (bandwidth), since the outgoing traffic will still go through the same server.
To solve two problems at the same time, we do the balancing in JavaScript, in the loader itself (widget.js), choosing the backend randomly. As a result, the traffic is redirected to the servers from the cluster server widget, dividing the bandwidth between them and distributing the load.
An additional huge plus of this method is caching javascript. All libraries (including the widget.js loader), when refreshing the page, will be obtained from the browser cache, and our servers will continue to calmly process new requests.
Loader code continuation (widget.js part 2):
var Cackle = Cackle || {}; Cackle.protocol = ('https:' == window.location.protocol) ? 'https:' : 'http:'; Cackle.host = Cackle.host || 'cackle.me'; Cackle.origin = Cackle.protocol + '//' + Cackle.host; // (a.cackle.me, b.cackle.me, c.cackle.me): Cackle.cluster = ['a.' + Cackle.host, 'b.' + Cackle.host, 'c.' + Cackle.host]; // , . widget.js 1 Cackle.getRandInt = function(min, max) { return Math.floor(Math.random() * (max - min + 1)) + min; } Cackle.getRandHost = function() { return Cackle.cluster[Cackle.getRandInt(0, Cackle.cluster.length - 1)]; }; Cackle.initHosts = function() { //getRandHost var host = Cackle.getRandHost(); for (var i = 0; i < cackle_widget.length; i++) { cackle_widget[i].host = Cackle.protocol + '//' + host; } }; //cackle_widget - , // ( ). //: cackle_widget.push({widget: 'Comment', id: 1}); Cackle.main = function() { Cackle.initHosts(); for (var i = 0; i < cackle_widget.length; i++) { var widget = cackle_widget[i].widget; if (!Cackle.Bootstrap[widget].isLoaded) { Cackle.Bootstrap[widget].load(cackle_widget[i].host); } } }; Cackle.main(); What about professional CDN?
It's great! The only problem is that with our volumes and loads, in order to use CDN it is necessary to raise prices at least 3 times, while maintaining the current turnover.
»Solution 2: Nginx Micro-Cache
A microcache is a cache with a very short lifespan, for example 3 seconds. It is very useful at peak loads, with thousands of identical GET requests per second. For us, this is widget data in JSON format. It makes sense to make a microcache in proxy servers, for example, Nginx to protect the main backend (Tomcat).
Part of the Nginx config with a microbag:
... location /bootstrap { try_files $uri @proxy; } ... location @proxy { # (Tomcat) proxy_pass http://localhost:8888; proxy_redirect off; # Nginx , # - , proxy_ignore_headers X-Accel-Expires Expires Cache-Control; set $no_cache ""; # GET|HEAD if ($request_method !~ ^(GET|HEAD)$) { set $no_cache "1"; } if ($no_cache = "1") { add_header Set-Cookie "_mcnc=1; Max-Age=2; Path=/"; add_header X-Microcachable "0"; } if ($http_cookie ~* "_mcnc") { set $no_cache "1"; } proxy_cache microcache; proxy_no_cache $no_cache; proxy_cache_bypass $no_cache; proxy_cache_key $scheme$host$request_method$request_uri; # 3 proxy_cache_valid 200 301 302 3s; proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_403 http_404 updating; default_type application/json; } ... If there are problems with understanding this config, then it is mandatory to read ngx_http_proxy_module .
»Solution 3: Tomcat tuning, Java cache
Tomcat
Especially tune Tomcat will not work. From practical experience:
- Do not bother with the choice of connector (Http11Protocol, Nio, Apr). With large loads it does not matter.
- Make the connectionTimeout as minimal as possible, preferably not more than 5 seconds.
- Do not make too big maxThreads, it will not help, and in some the situation only hurts. The standard for a loaded project is 300-350. If this is not enough, add a new Tomcat server.
- But acceptCount can be made several thousand (2000-4000). At small values, the connections are cut off (connection refused), and so will be added to the queue. Do not forget to set the same or more backlog in the OS.
Java cache
It is considered to be a DB, in high-loaded projects, as a weak point. It really is. For example, the server accepts the request, sends it to the service level, where the service accesses the database and returns the result. The link “service - DB (relational)” in this case is the slowest, so it is customary to wrap services with a cache. Accordingly, the result from the database is placed in the service cache, and the next time it is used, it is taken from it.
For caching services, we have developed our own cache, since standard ones (for example, Ehcache) work slower and do not always solve specific problems well. Of the specific tasks we have is caching with support for several keys for one value. We use org.apache.commons.collections.map.MultiKeyMap.
You need this for what tasks. For example, a user visits a page with comments. Suppose a lot of comments, 300 pieces. They are divided into three pages (pagination), respectively, 100 each. When first accessed, the first page will be cached (100 comments), if the user scrolls down, then 2 and 3 pages will be cached in turn. Now the user publishes a comment on this page and here you need to reset all three caches. Using MultiKeyMap it looks like this:
MultiKeyMap cache = MultiKeyMap.decorate(new LRUMap(capacity)); cache.put(chanId, "page1", commentSerivce.list(chanId, 1)); //chanId - id cache.put(chanId, "page2", commentSerivce.list(chanId, 2)); //commentSerivce.list - (chanId) (2) cache.put(chanId, "page3", commentSerivce.list(chanId, 3)); cache.removeAll(chanId); // 3 Below is the kernel cache code that works fine on highload.
Cache kernel: thread-safety, deferred and only execution of the caching result, soft links to avoid OOM
public class CackleCache { private final MultiKeyMap CACHE = MultiKeyMap.decorate(new LRUMap(capacity)); public static class SoftValue<K, V> extends SoftReference<V> { final K key; final long expired; public SoftValue(V ref, ReferenceQueue<V> q, K key, long timelife) { super(ref, q); this.key = key; this.expired = System.currentTimeMillis() + timelife; } } public synchronized Future<Object> get(final MultiKey key, final long timelife, final MethodInvocation invocation) { Future<Object> ret; @SuppressWarnings("unchecked") SoftValue<MultiKey, Future<Object>> sr = (SoftValue<MultiKey, Future<Object>>) CACHE.get(key); if (sr != null) { ret = sr.get(); if (ret != null) { if (sr.expired > System.currentTimeMillis()) { return ret; } else { sr.clear(); } } } ret = executor.submit(new Callable<Object>() { @Override public Object call() throws Exception { try { return invocation.proceed(); } catch (Throwable t) { throw new Exception(t); } } }); SoftValue<MultiKey, Future<Object>> value = new SoftValue<MultiKey, Future<Object>>(ret, referenceQueue, key, timelife); CACHE.put(key, value); return ret; } public synchronized void evict(Object key) { try { CACHE.removeAll(key); } catch (Throwable t) {} } } "Solution 4: PostgreSQL streaming replication to different data centers
In our opinion, PostgreSQL is the best solution for high-load projects. Now it is fashionable to use NoSQL, but in most cases, with the right approach and the right architecture, PostgreSQL is better.
In PostgreSQL, streaming replication works fine, and it does not matter in one subnet or in different networks, different data centers. We have, for example, database servers located in several countries and no serious problems have been noticed. The only caveat is large database modifications (ALTER TABLE) for releases. It is necessary to make them in pieces, trying not to perform the whole UPDATE at once.
There are a lot of resources on setting up replication, this is a hackneyed topic, so there’s nothing really to add, except:
- Be sure to make a plan (config) in case of failover (drop master) and really test it;
- Understand the principle of WAL, so that in case the slave and master are out of sync, know why you need archives and where to put them;
- Watch the place on the HDD wizard, if suddenly it doesn’t become, then PostgreSQL can fall, and during replication it is fraught with big troubles.
»Solution 5: OS tuning
Do not forget to tune the parameters of the OS kernel , because without this some settings of Nginx or Tomcat simply will not work.
We have, for example, Debian everywhere. In the OS kernel settings (/etc/sysctl.conf) special attention should be paid to:
kernel.shmmax = 8000234752 // PostgreSQL, shared_buffers (6 - 8GB) fs.file-max = 99999999 // Nginx, "Too many open files" net.ipv4.tcp_max_syn_backlog=524288 // net.ipv4.tcp_max_orphans=262144 // TCP net.core.somaxconn=65535 // net.ipv4.tcp_mem=1572864 1835008 2097152 // TCP net.ipv4.tcp_rmem=4096 16384 16777216 // TCP net.ipv4.tcp_wmem=4096 32768 16777216 // , TCP Problems that have not yet been resolved
Rather, one problem - the size of the database. There is sharding, of course, but we have not yet found a standard solution for PostgreSQL without a drop in performance. If someone can share practical experience - welcome!
Thanks for attention. Questions and suggestions on our system are welcome!
Source: https://habr.com/ru/post/255013/
All Articles