Comparison of deep learning libraries on the example of the handwriting numbers classification problem
Kruchinin Dmitry, Dolotov Evgeny, Kustikova Valentina, Druzhkov Pavel, Kornyakov Kirill
At present, machine learning is an actively developing field of research. This is connected both with the possibility of faster,higher, stronger , simpler and cheaper to collect and process data, and with the development of methods for identifying laws from these data, according to which physical, biological, economic and other processes take place. In some tasks, when such a law is difficult to determine, use deep learning.
Deep learning considers the methods of modeling high-level abstractions in data using a set of consecutive nonlinear transformations, which, as a rule, are represented as artificial neural networks. Today, neural networks are successfully used to solve problems such as forecasting, pattern recognition, data compression, and several others.
The relevance of the topic of machine learning and, in particular, deep learning is confirmed by the regular appearance of articles on this topic in Habré:
This article is devoted to a comparative analysis of some deep learning software tools, of which a great many have recently appeared [ 1 ]. Such tools include software libraries, extensions of programming languages, as well as independent languages that allow the use of ready-made algorithms for creating and teaching neural network models. Existing deep learning tools have different functionalities and require different levels of knowledge and skills from the user. The right choice of tools is an important task, allowing you to achieve the desired result in the shortest time and with less expenditure of effort.
')
The article provides a brief overview of the design and training tools for neural network models. The focus is on four libraries: Caffe , Pylearn2 , Torch and Theano . The basic capabilities of these libraries are considered, examples of their use are given. The quality and speed of the libraries are compared when constructing the same neural network topologies for solving the problem of classifying handwritten numbers ( MNIST is used as a training and test sample). An attempt is also made to evaluate the usability of the libraries in question in practice.
Further, the MNIST handwritten digit image database will be used as the data set under study ( Fig. 1 ). Images in this database have a resolution of 28x28 and are stored in a grayscale format. The numbers are centered on the image. The entire base is divided into two parts: training, consisting of 50,000 images, and test - 10,000 images.

Fig. 1. Examples of images of numbers in the MNIST database
There are many software tools for solving problems of deep learning. In [ 1 ] you can find a general comparison of the functionality of the most well-known, here we give general information about some of them ( table 1 ). The first six program libraries implement the widest range of deep learning methods. Developers provide opportunities for creating fully connected neural networks (fully connected neural network, FC NN [ 2 ]), convolutional neural networks (CNN) [ 3 ], autocoders (autoencoder, AE) and limited Boltzmann machines (restricted Boltzmann machine, RBM) [ 4 ]. It is necessary to pay attention to the remaining libraries. Although they have less functionality, in some cases their simplicity helps to achieve greater performance.
Table 1. Capabilities of deep learning software [ 1 ]
Based on the information provided in [ 1 ] and the recommendations of specialists, four libraries were chosen for further consideration: Theano , Pylearn2 - one of the most mature and functionally complete libraries, Torch and Caffe - widely used by the community. Each library is reviewed according to the following plan:
After reviewing the listed libraries, they are compared on a number of test network configurations.
Caffe has been developing since September 2013. Yangqing Jia began his development during his studies at the University of California at Berkeley. From this point on, Caffe is actively supported by the Berkeley Vision and Learning Center ( BVLC ) and the GitHub developer community. The library is distributed under the BSD 2-Clause license.
Caffe is implemented using the C ++ programming language, there are wrappers in Python and MATLAB. The officially supported operating systems are Linux and OS X, there is also an unofficial port on Windows . Caffe uses the BLAS library (ATLAS, Intel MKL, OpenBLAS) for vector and matrix calculations. Along with this, external dependencies include glog, gflags, OpenCV, protoBuf, boost, leveldb, nappy, hdf5, lmdb. To speed up computing, Caffe can be run on a GPU using the basic capabilities of CUDA technology or the cuDNN deep learning primitive library.
Caffe developers support the creation, training and testing of fully connected and convolutional neural networks. Input data and transformations are described by the concept of a layer . Depending on the storage format, the following types of raw data layers can be used:
Transformations can be specified using layers:
Along with this, various activation functions can be used in the formation of transformations.
The last layer of the neural network model should contain the error function. The library has the following functions:
In the process of teaching models, various optimization methods are used. Caffe developers provide the implementation of a number of methods:
In the Caffe library, the topology of the neural networks, the initial data and the learning method are specified using the configuration files in the prototxt format. The file contains a description of the input data (training and test) and layers of the neural network. Let us consider the stages of building such files using the example of the “logistic regression” network ( Fig. 2 ). Further, we assume that the file is called linear_regression.prototxt, and it is located in the examples / mnist directory.

Fig. 2. The structure of the neural network
Network configuration ready. Next, you need to define the parameters of the training procedure in the prototxt format file (let's call it solver.prototxt). The training parameters include the path to the file with the network configuration (net), the frequency of testing during training (test_interval), the parameters of stochastic gradient descent (base_lr, weight_decay and others), the maximum number of iterations (max_iter), the architecture on which the calculations will be performed (solver_mode), path to save the trained network (snapshot_prefix).
Training is performed using the main library application. In this case, a certain set of keys is transferred, in particular, the name of the file containing the description of the parameters of the training procedure.
After learning, the resulting model can be used to classify images, for example, using Python wrappers:
Thus, by simple actions you can get the first results of experiments with deep neural network models. More complex and detailed examples can be seen on the developers website .

Pylearn2 is a library being developed in the LISA lab at the University of Montreal since February 2011. It has about 100 developers on GitHub . The library is distributed under the BSD 3-Clause license.
Pylearn2 is implemented in Python, currently the Linux operating system is supported, it is also possible to run on any operating system using a virtual machine, since developers provide a configured virtual environment wrapper based on Vagrant. Pylearn2 is a superstructure above Theano library. Additionally required PyYAML, PIL. To speed up the calculations, Pylearn2 and Theano use Cuda-convnet , which is implemented in C ++ / CUDA, which gives a significant increase in speed.
Pylearn2 supports the ability to create fully connected and convolutional neural networks, various types of auto-encoders (Contractive Auto-Encoders, Denoising Auto-Encoders) and limited Boltzmann machines (Gaussian RBM, the spike-and-slab RBM). There are several error functions: cross-entropy, log-likelihood. The following teaching methods are available:
In the Pylearn2 library, neural networks are set using their descriptions in the configuration file in YAML format. YAML files are a convenient and fast way to serialize objects, as it is developed using object-oriented programming techniques.
Consider the procedure for the formation of YAML files describing the structure of a neural network and the way it is trained, using the example of logistic regression.
Thus, the network configuration has been prepared and the necessary infrastructure for training and classification has been determined, which are performed by calling the appropriate Python script. For training, you must run the following command line:
More complex and detailed examples can be seen on the official website or in the repository .

Torch is a library for scientific computing with broad support for machine learning algorithms. Developed by the Idiap Research Institute , New York University and NEC Laboratories America , since 2000, distributed under the BSD license.
The library is implemented in Lua using C and CUDA. The fast scripting language Lua in conjunction with SSE, OpenMP, CUDA technologies allow Torch to show good speed compared to other libraries. Currently, Linux, FreeBSD, Mac OS X operating systems are supported. The main modules also work on Windows. The Torch dependencies are packages imagemagick, gnuplot, nodejs, npm and others.
The library consists of a set of modules, each of which is responsible for different stages of working with neural networks. For example, the nn module provides configuration of the neural network (definition of layers, and their parameters), the optim module contains implementations of various optimization methods used for training, and gnuplot provides the ability to visualize data (graphing, displaying images, etc.). Installing additional modules allows you to extend the functionality of the library.
Torch allows you to create complex neural networks using the container mechanism. The container is a class that combines the declared components of a neural network into one common configuration, which can later be transferred to the learning procedure. The neural network component can be not only fully connected or convolutional layers, but also activation or error functions, as well as ready-made containers. Torch allows you to create the following layers:
Error functions: mean square error (MSE), cross-entropy (CrossEntropy), etc.
When training can be used the following optimization methods:
Consider the process of configuring a neural network in Torch. You must first declare the container, then add layers to it. The order of adding layers is important because the output of the (n-1) -th layer will be the input of the n-th.
Use and training of a neural network:
Now let's put it all together. In order to train the neural network in the Torch library, you need to write your own learning cycle. It declares a special function (closure), which will calculate the network response, determine the error value and recalculate the gradients, and transfer this closure to the gradient descent function to update the weights of the network.
where optimState is the gradient descent parameters (learningRate, momentum, weightDecay, etc.). Full cycle of training can be found here .
It is easy to see that the declaration procedure, like the learning procedure, takes less than 10 lines of code, which indicates the ease of use of the library. At the same time, the library allows working with neural networks at a fairly low level.
Saving and loading of the trained network is carried out with the help of special functions:
Once loaded, the network can be used for classification or additional training. If it is necessary to find out which class the sample element belongs to, then it suffices to go through the network and calculate the output:
More complex examples can be found in the library’s training materials .

Theano is an extension of the Python language that allows you to efficiently calculate mathematical expressions containing multidimensional arrays. The library got its name in honor of the wife of the ancient Greek philosopher and mathematician Pythagoras - Feano (or Teano). Theano is developed in the LISA lab to support the rapid development of machine learning algorithms.
The library is implemented in Python, supported on Windows, Linux and Mac OS. Theano includes a compiler that translates mathematical expressions written in Python into effective C or CUDA code.
Theano provides a basic set of tools for configuring neural networks and learning them. It is possible to implement multi-layer fully interconnected networks (Multi-Layer Perceptron), convolutional neural networks (CNN), recurrent neural networks (Recurrent Neural Networks, RNN), auto-encoders and limited Boltzmann machines. Various activation functions are also provided, in particular, sigmoidal, softmax-function, cross-entropy. In the course of training, a packet gradient descent (Batch SGD) is used.
Consider the configuration of a neural network in Theano. For convenience, we will implement the LogisticRegression class ( Fig. 3 ), which will contain variables — learning parameters W, b and functions for working with them — counting the network response (y = softmax (Wx + b)) and the error function. Then, to train the neural network, we create the function train_model. For it, it is necessary to describe the methods that determine the error function, the rule for calculating gradients, the method of changing the weights of the neural network, the size and location of the mini-batch sample (the images themselves and the answers for them). After determining all the parameters, the function is compiled and passed to the learning cycle.

Fig. 3. Class diagram for the implementation of the neural network in Theano
To quickly save and load neural network parameters, you can use functions from the cPickle package:
It is easy to see that the process of creating a model and determining its parameters requires writing a three-dimensional and noisy code. The library is low-level. It should be noted its flexibility, as well as the availability of the implementation and use of its own components. The official website of the library has a large number of teaching materials on various topics.
The following test infrastructure was used in the course of experiments to evaluate library performance:
Computational experiments were carried out on fully connected and convolutional neural networks of the following structure:
All weights were initialized randomly according to a uniform distribution law in the range (−6 / (n_in + n_out), 6 / (n_in + n_out)), where n_in, n_out is the number of neurons at the input and output of the layer, respectively. The parameters of the stochastic gradient descent (SGD) are chosen equal to the following values: learning rate - 0.01, momentum - 0.9, weight decay - 5e-4, batch size - 128, maximum number of iterations - 150.
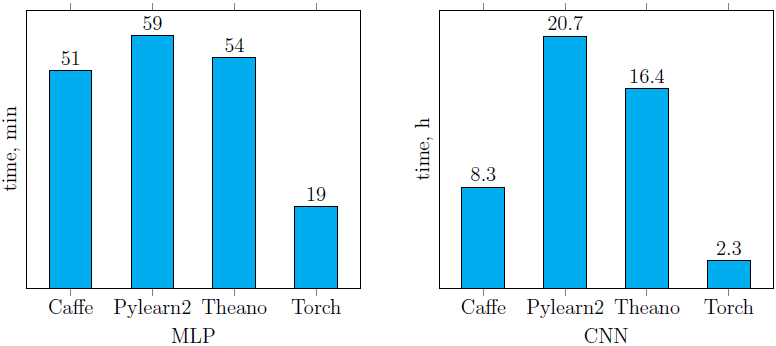
The learning time of the neural networks described earlier ( Fig. 4 , 5 ) using the four libraries reviewed is presented below ( Fig. 6 ). It is easy to see that Pylearn2 shows worse performance (both on the CPU and on the GPU) compared to other libraries.As for the rest, the learning time depends heavily on the network structure. The best result among the implementations of networks running on the CPU, showed the Torch library (and on CNN it overtook itself, running on the GPU). Among GPU implementations, the best result (on both networks) was shown by the Caffe library. In general, the use of Caffe left only positive impressions.
CPU implementation (see infrastructure ):
Implementation GPU (see infrastructure ):
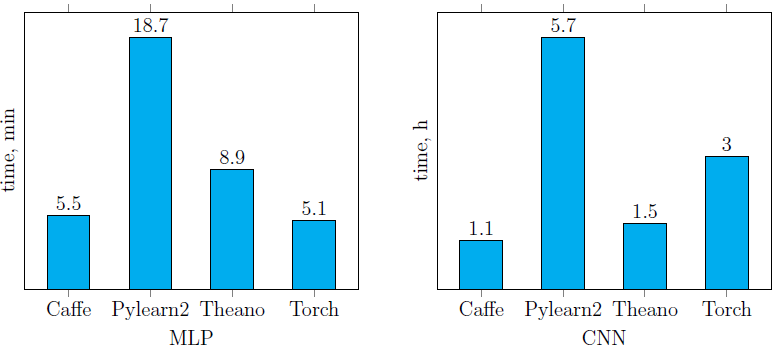
Fig.6. The learning time of the MLP and CNN networks described in the previous paragraph.
As for the time for classifying one image on the CPU using trained models ( Fig. 7 ), it is easy to see that the Torch library was out of competition on both test neural networks. A little behind her was Caffe on CNN, which at the same time showed the worst classification time for MLP.
CPU implementation (see infrastructure ):
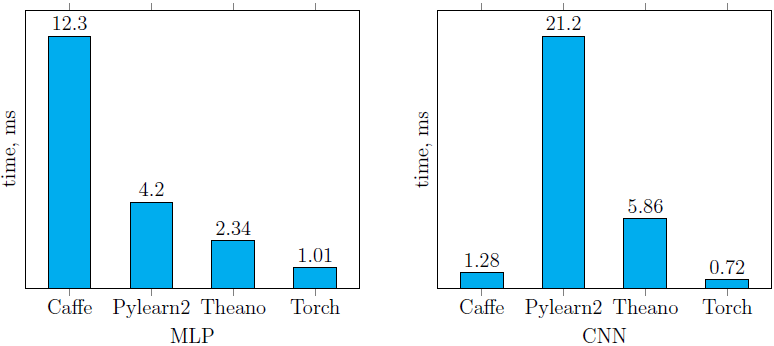
Fig.7. Classification time of one image using trained MLP and CNN networks
If we look at the classification accuracy, on the MLP network it is higher than 97.4%, and CNN - ~ 99% for all libraries ( Table 2 ). The obtained accuracy values are somewhat lower than those listed on the MNIST website on the same neural network structures. Small differences are due to differences in the settings of the initial weights of the networks and the parameters of optimization methods used in the learning process. Actually, the goal of achieving maximum accuracy values was not, it was rather necessary to build identical network structures and set the most similar training parameters.
Table 2. The average value and dispersion of classification accuracy indicators for 5 experiments
Based on the research of the library's functional, as well as the performance analysis, each of them was rated on a scale from 1 to 3 using the following criteria:
Consider the estimates obtained for each criterion, we place the places of each library from the first to the third ( Table 3 ). According to the results of computational experiments in terms of speed of work, the Caffe library is most preferable ( Fig. 6 ). At the same time, it turned out to be the most convenient to use. From a position of flexibility, the Theano library showed the best results. In terms of functionality, Pylearn2 is the most complete, but its use is complicated by the need to understand the internal structure (the formation of YAML files requires this). The most detailed and understandable material for the study provide developers Torch. Having shown the average indicators for each criterion separately, it was she who won in the rating of the reviewed libraries.
Table 3. Library comparison results (ranks from 1 to 3 for each criterion)
Summarizing, we can say that the Torch library is the most mature. At the same time, the libraries of Caffe and Theano are not inferior to it by many criteria ( table 3 ), therefore the possibility of their subsequent use cannot be ruled out. In the future, Caffe and Torch libraries are planned to be used to study the applicability of deep learning methods to the tasks of detecting people, pedestrians and cars.
The work was done in the laboratory "Information Technologies" of the Faculty of the VMK UNN them. N.I. Lobachevsky with the support of the company Itseez.
Introduction
At present, machine learning is an actively developing field of research. This is connected both with the possibility of faster,
Deep learning considers the methods of modeling high-level abstractions in data using a set of consecutive nonlinear transformations, which, as a rule, are represented as artificial neural networks. Today, neural networks are successfully used to solve problems such as forecasting, pattern recognition, data compression, and several others.
The relevance of the topic of machine learning and, in particular, deep learning is confirmed by the regular appearance of articles on this topic in Habré:
- Deep learning and Caffe on New Year's holidays.
- Data mining: Toolkit - Theano.
- About cats, dogs, machine learning and deep learning.
- Weekly reviews of the most interesting materials on data analysis and machine learning.
This article is devoted to a comparative analysis of some deep learning software tools, of which a great many have recently appeared [ 1 ]. Such tools include software libraries, extensions of programming languages, as well as independent languages that allow the use of ready-made algorithms for creating and teaching neural network models. Existing deep learning tools have different functionalities and require different levels of knowledge and skills from the user. The right choice of tools is an important task, allowing you to achieve the desired result in the shortest time and with less expenditure of effort.
')
The article provides a brief overview of the design and training tools for neural network models. The focus is on four libraries: Caffe , Pylearn2 , Torch and Theano . The basic capabilities of these libraries are considered, examples of their use are given. The quality and speed of the libraries are compared when constructing the same neural network topologies for solving the problem of classifying handwritten numbers ( MNIST is used as a training and test sample). An attempt is also made to evaluate the usability of the libraries in question in practice.
MNIST dataset
Further, the MNIST handwritten digit image database will be used as the data set under study ( Fig. 1 ). Images in this database have a resolution of 28x28 and are stored in a grayscale format. The numbers are centered on the image. The entire base is divided into two parts: training, consisting of 50,000 images, and test - 10,000 images.
Fig. 1. Examples of images of numbers in the MNIST database
Software tools for solving problems of deep learning
There are many software tools for solving problems of deep learning. In [ 1 ] you can find a general comparison of the functionality of the most well-known, here we give general information about some of them ( table 1 ). The first six program libraries implement the widest range of deep learning methods. Developers provide opportunities for creating fully connected neural networks (fully connected neural network, FC NN [ 2 ]), convolutional neural networks (CNN) [ 3 ], autocoders (autoencoder, AE) and limited Boltzmann machines (restricted Boltzmann machine, RBM) [ 4 ]. It is necessary to pay attention to the remaining libraries. Although they have less functionality, in some cases their simplicity helps to achieve greater performance.
Table 1. Capabilities of deep learning software [ 1 ]
| # | Title | Tongue | OC | FC NN | CNN | AE | RBM |
| one | DeepLearnToolbox | Matlab | Windows linux | + | + | + | + |
| 2 | Theano | Python | Windows, Linux, Mac | + | + | + | + |
| 3 | Pylearn2 | Python | Linux, Vagrant | + | + | + | + |
| four | Deepnet | Python | Linux | + | + | + | + |
| five | Deepmat | Matlab | ? | + | + | + | + |
| 6 | Torch | Lua, C | Linux, Mac OS X, iOS, Android | + | + | + | + |
| 7 | Darch | R | Windows linux | + | - | + | + |
| eight | Caff e | C ++, Python, Matlab | Linux, OS X | + | + | - | - |
| 9 | nnForge | C ++ | Linux | + | + | - | - |
| ten | CXXNET | C ++ | Linux | + | + | - | - |
| eleven | Cuda convnet | C ++ | Linux, Windows | + | + | - | - |
| 12 | Cuda CNN | Matlab | Linux, Windows | + | + | - | - |
Based on the information provided in [ 1 ] and the recommendations of specialists, four libraries were chosen for further consideration: Theano , Pylearn2 - one of the most mature and functionally complete libraries, Torch and Caffe - widely used by the community. Each library is reviewed according to the following plan:
- Brief reference information.
- Technical features (OS, programming language, dependencies).
- Functionality
- An example of the formation of a network such as logistic regression.
- Training and use of the constructed model for classification.
After reviewing the listed libraries, they are compared on a number of test network configurations.
Caffe library
Caffe has been developing since September 2013. Yangqing Jia began his development during his studies at the University of California at Berkeley. From this point on, Caffe is actively supported by the Berkeley Vision and Learning Center ( BVLC ) and the GitHub developer community. The library is distributed under the BSD 2-Clause license.
Caffe is implemented using the C ++ programming language, there are wrappers in Python and MATLAB. The officially supported operating systems are Linux and OS X, there is also an unofficial port on Windows . Caffe uses the BLAS library (ATLAS, Intel MKL, OpenBLAS) for vector and matrix calculations. Along with this, external dependencies include glog, gflags, OpenCV, protoBuf, boost, leveldb, nappy, hdf5, lmdb. To speed up computing, Caffe can be run on a GPU using the basic capabilities of CUDA technology or the cuDNN deep learning primitive library.
Caffe developers support the creation, training and testing of fully connected and convolutional neural networks. Input data and transformations are described by the concept of a layer . Depending on the storage format, the following types of raw data layers can be used:
- DATA - defines the data layer in the format leveldb and lmdb.
- HDF5_DATA - data layer in hdf5 format.
- IMAGE_DATA is a simple format that assumes that the file contains a list of images with an indication of the class label.
- other.
Transformations can be specified using layers:
- INNER_PRODUCT is a fully bound layer.
- CONVOLUTION - convolutional layer.
- POOLING - layer spatial association.
- Local Response Normalization (LRN) - layer of local normalization.
Along with this, various activation functions can be used in the formation of transformations.
- The positive part (Rectified-Linear Unit, ReLU).
- Sigmoidal function (SIGMOID).
- Hyperbolic Tangent (TANH).
- Absolute value (ABSVAL).
- Exponentiation (POWER).
- Binominal normal log likelihood function (binomial normal log likelihood, BNLL).
The last layer of the neural network model should contain the error function. The library has the following functions:
- Mean-Square Error (MSE).
- Regional error (Hinge loss).
- Logistic error function (Logistic loss).
- Info gain information loss function.
- Sigmoid cross-entropy loss.
- Softmax function. Summarizes sigmoidal cross-entropy in the case of more than two classes.
In the process of teaching models, various optimization methods are used. Caffe developers provide the implementation of a number of methods:
- Stochastic Gradient Descent (Stochastic Gradient Descent, SGD) [ 6 ].
- Algorithm with adaptive learning rate (AdaGrad) [ 7 ].
- Accelerated Gradient Descent of Nesterov (Nesterov's Accelerated Gradient Descent, NAG) [ 8 ].
In the Caffe library, the topology of the neural networks, the initial data and the learning method are specified using the configuration files in the prototxt format. The file contains a description of the input data (training and test) and layers of the neural network. Let us consider the stages of building such files using the example of the “logistic regression” network ( Fig. 2 ). Further, we assume that the file is called linear_regression.prototxt, and it is located in the examples / mnist directory.
Fig. 2. The structure of the neural network
- Set the network name.
name: "LinearRegression" - The MNIST database stored in the lmdb format is used as the training set. To work with lmdb or leveldb formats, a “DATA” type layer is used in which you must specify some parameters that describe the input data (data_param): the path to the data on the hard disk (source), the data type (backend), the sample size (batch_size). You can also perform various transformations with the data (transform_param). For example, you can normalize the image by multiplying all values by 0.00390625 (the number inverse to 255). The top parameter specifies one or more names that will be used to identify the output layer. In this example, these are processed images (data) and labels of classes that own images (label).
layers { name: "mnist" type: DATA top: "data" top: "label" data_param { source: "examples/mnist/mnist_train_lmdb" backend: LMDB batch_size: 64 } transform_param { scale: 0.00390625 } } - We define a fully connected layer (the output of each neuron of the previous layer is connected with the input of each neuron of the next layer). The full link layer in the Caffe library is set using the INNER_PRODUCT layer. The input name is specified using the bottom parameter. In this layer, the input data are processed images (data). The number of neurons in the layer is determined automatically (by the number of outputs in the previous layer), and the number of output neurons is indicated using the num_output parameter. The result of the layer is set by the same name as the layer name (ip).
layers { name: "ip" type: INNER_PRODUCT bottom: "data" top: "ip" inner_product_param { num_output: 10 } } - At the end, add a layer that calculates the error function. It takes as input the result of the previous fully meshed layer (ip) and the class numbers for each image (label). After calculations, the results of this layer can be addressed by the name loss.
layers { name: "loss" type: SOFTMAX_LOSS bottom: "ip" bottom: "label" top: "loss" }
Network configuration ready. Next, you need to define the parameters of the training procedure in the prototxt format file (let's call it solver.prototxt). The training parameters include the path to the file with the network configuration (net), the frequency of testing during training (test_interval), the parameters of stochastic gradient descent (base_lr, weight_decay and others), the maximum number of iterations (max_iter), the architecture on which the calculations will be performed (solver_mode), path to save the trained network (snapshot_prefix).
net: "examples/mnist/linear_regression.prototxt" test_iter: 100 test_interval: 500 base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 lr_policy: "inv" gamma: 0.0001 power: 0.75 display: 100 max_iter: 10000 snapshot: 5000 snapshot_prefix: "examples/mnist/linear_regression" solver_mode: GPU Training is performed using the main library application. In this case, a certain set of keys is transferred, in particular, the name of the file containing the description of the parameters of the training procedure.
caffe train --solver=solver.prototxt After learning, the resulting model can be used to classify images, for example, using Python wrappers:
- We connect the library Caffe. Set the test mode and specify the architecture for performing calculations (CPU or GPU).
import caffe caffe.set_phase_test() caffe.set_mode_cpu() - We create a neural network, specifying the following parameters: MODEL_FILE — network configuration in prototxt format, PRETRAINED — trained caffemodel network, IMAGE_MEAN — average image (calculated from a set of input images and used for subsequent intensity normalization), channel_swap sets the color model, raw_scale — maximum intensity value, image_dims - image resolution. After that, load the image for classification (IMAGE_FILE).
net = caffe.Classifier(MODEL_FILE, PRETRAINED, IMAGE_MEAN, channel_swap=(0,1,2), raw_scale=255, image_dims=(28, 28)) input_image = caffe.io.load_image(IMAGE_FILE) - We get the neural network response for the selected image and display the results on the screen.
prediction = net.predict([input_image]) print 'prediction shape:', prediction[0].shape print 'predicted class:', prediction[0].argmax()
Thus, by simple actions you can get the first results of experiments with deep neural network models. More complex and detailed examples can be seen on the developers website .
Pylearn2 library
Pylearn2 is a library being developed in the LISA lab at the University of Montreal since February 2011. It has about 100 developers on GitHub . The library is distributed under the BSD 3-Clause license.
Pylearn2 is implemented in Python, currently the Linux operating system is supported, it is also possible to run on any operating system using a virtual machine, since developers provide a configured virtual environment wrapper based on Vagrant. Pylearn2 is a superstructure above Theano library. Additionally required PyYAML, PIL. To speed up the calculations, Pylearn2 and Theano use Cuda-convnet , which is implemented in C ++ / CUDA, which gives a significant increase in speed.
Pylearn2 supports the ability to create fully connected and convolutional neural networks, various types of auto-encoders (Contractive Auto-Encoders, Denoising Auto-Encoders) and limited Boltzmann machines (Gaussian RBM, the spike-and-slab RBM). There are several error functions: cross-entropy, log-likelihood. The following teaching methods are available:
- Batch Gradient Descent (BGD).
- Stochastic Gradient Descent (Stochastic Gradient Descent, SGD).
- Nonlinear conjugate gradient descent (NCG) method.
In the Pylearn2 library, neural networks are set using their descriptions in the configuration file in YAML format. YAML files are a convenient and fast way to serialize objects, as it is developed using object-oriented programming techniques.
Consider the procedure for the formation of YAML files describing the structure of a neural network and the way it is trained, using the example of logistic regression.
- Define the training set. Pylearn2 has already implemented a class for working with the MNIST database. Training will be carried out on the first 50,000 images.
!obj:pylearn2.train.Train { dataset: &train !obj:pylearn2.datasets.mnist.MNIST { which_set: 'train', one_hot: 1, start: 0, stop: 50000 }, - We describe the structure of the network. To do this, use the class that implements the logistic regression. It is enough to specify the necessary parameters. The number of input neurons in the fully connected layer (nvis) is 784 (by the number of pixels in the image), the output (n_classes) is 10 (by the number of object classes), the initial weights (iranges) are determined with zeros.
model: !obj:pylearn2.models.softmax_regression.SoftmaxRegression { n_classes: 10, irange: 0., nvis: 784, }, - Let's choose a neural network learning algorithm and its parameters. For learning, choose the method of packet gradient descent (BGD). The batch_size parameter is responsible for the size of the training sample used at each step of the gradient descent. Setting the line_search_mode parameter to exhaustive means that the packet gradient descent method (BGD) will try to use a binary search to reach the best point along the gradient direction, which speeds up the convergence of the gradient descent. During the training, we will track the results of the classification at the training, validation (images from 50,000 to 60,000) and test samples. The stop criterion is the maximum number of optimization iterations.
algorithm: !obj:pylearn2.training_algorithms.bgd.BGD { batch_size: 128, line_search_mode: 'exhaustive', monitoring_dataset: { 'train' : *train, 'valid' : !obj:pylearn2.datasets.mnist.MNIST { which_set: 'train', one_hot: 1, start: 50000, stop: 60000 }, 'test' : !obj:pylearn2.datasets.mnist.MNIST { which_set: 'test', one_hot: 1, } }, termination_criterion: !obj:pylearn2.termination_criteria.And { criteria: [ !obj:pylearn2.termination_criteria.EpochCounter { max_epochs: 150 }, ] } }, - For further use of the trained model, you must save the result. Note that the model is saved in the pkl format.
extensions: [ !obj:pylearn2.train_extensions.best_params.MonitorBasedSaveBest { channel_name: 'valid_y_misclass', save_path: "%(save_path)s/softmax_regression_best.pkl" }, ]
Thus, the network configuration has been prepared and the necessary infrastructure for training and classification has been determined, which are performed by calling the appropriate Python script. For training, you must run the following command line:
python train.py < >.yaml More complex and detailed examples can be seen on the official website or in the repository .
Torch Library
Torch is a library for scientific computing with broad support for machine learning algorithms. Developed by the Idiap Research Institute , New York University and NEC Laboratories America , since 2000, distributed under the BSD license.
The library is implemented in Lua using C and CUDA. The fast scripting language Lua in conjunction with SSE, OpenMP, CUDA technologies allow Torch to show good speed compared to other libraries. Currently, Linux, FreeBSD, Mac OS X operating systems are supported. The main modules also work on Windows. The Torch dependencies are packages imagemagick, gnuplot, nodejs, npm and others.
The library consists of a set of modules, each of which is responsible for different stages of working with neural networks. For example, the nn module provides configuration of the neural network (definition of layers, and their parameters), the optim module contains implementations of various optimization methods used for training, and gnuplot provides the ability to visualize data (graphing, displaying images, etc.). Installing additional modules allows you to extend the functionality of the library.
Torch allows you to create complex neural networks using the container mechanism. The container is a class that combines the declared components of a neural network into one common configuration, which can later be transferred to the learning procedure. The neural network component can be not only fully connected or convolutional layers, but also activation or error functions, as well as ready-made containers. Torch allows you to create the following layers:
- Full connected layer (Linear).
- Activation functions: hyperbolic tangent (Tanh), the choice of minimum (Min) or maximum (Max), softmax-function (SoftMax) and others.
- Convolutional layers: convolution (Convolution), thinning (SubSampling), spatial union (MaxPooling, AveragePooling, LPPooling), difference normalization (SubtractiveNormalization).
Error functions: mean square error (MSE), cross-entropy (CrossEntropy), etc.
When training can be used the following optimization methods:
- Stochastic Gradient Descent (SGD),
- Average stochastic gradient descent (Averaged SGD) [ 9 ].
- The Broyden – Fletcher – Goldfarb – Shanno algorithm (L-BFGS) [ 10 ].
- Conjugate Gradient (CG) Method.
Consider the process of configuring a neural network in Torch. You must first declare the container, then add layers to it. The order of adding layers is important because the output of the (n-1) -th layer will be the input of the n-th.
regression = nn.Sequential() regression:add(nn.Linear(784,10)) regression:add(nn.SoftMax()) loss = nn.ClassNLLCriterion() Use and training of a neural network:
- Loading input data X. The function torch.load (path_to_ready_dset) allows you to load prepared in advance dataset in text or binary format. As a rule, this is a Lua-table consisting of three fields: size, data and labels. If there is no ready dataset, you can use the standard functions of the Lua language (for example, io.open (filename [, mode])) or functions from the Torch library packages (for example, image.loadJPG (filename)).
- Determining the network response for input X:
Y = regression:forward(X) - Calculation of the error function E = loss (Y, T), in our case, this is a likelihood function.
E = loss:forward(Y,T) - Gradient miscalculation according to the backpropagation algorithm.
dE_dY = loss:backward(Y,T) regression:backward(X,dE_dY)
Now let's put it all together. In order to train the neural network in the Torch library, you need to write your own learning cycle. It declares a special function (closure), which will calculate the network response, determine the error value and recalculate the gradients, and transfer this closure to the gradient descent function to update the weights of the network.
-- : w, dE_dw = regression:getParameters() local eval_E = function(w) dE_dw:zero() -- local Y = regression:forward(X) local E = loss:forward(Y,T) local dE_dY = loss:backward(Y,T) regression:backward(X,dE_dY) return E, dE_dw end -- optim.sgd(eval_E, w, optimState) where optimState is the gradient descent parameters (learningRate, momentum, weightDecay, etc.). Full cycle of training can be found here .
It is easy to see that the declaration procedure, like the learning procedure, takes less than 10 lines of code, which indicates the ease of use of the library. At the same time, the library allows working with neural networks at a fairly low level.
Saving and loading of the trained network is carried out with the help of special functions:
torch.save(path, regression) net = torch.load(path) Once loaded, the network can be used for classification or additional training. If it is necessary to find out which class the sample element belongs to, then it suffices to go through the network and calculate the output:
result = net:forward(sample) More complex examples can be found in the library’s training materials .
Theano library
Theano is an extension of the Python language that allows you to efficiently calculate mathematical expressions containing multidimensional arrays. The library got its name in honor of the wife of the ancient Greek philosopher and mathematician Pythagoras - Feano (or Teano). Theano is developed in the LISA lab to support the rapid development of machine learning algorithms.
The library is implemented in Python, supported on Windows, Linux and Mac OS. Theano includes a compiler that translates mathematical expressions written in Python into effective C or CUDA code.
Theano provides a basic set of tools for configuring neural networks and learning them. It is possible to implement multi-layer fully interconnected networks (Multi-Layer Perceptron), convolutional neural networks (CNN), recurrent neural networks (Recurrent Neural Networks, RNN), auto-encoders and limited Boltzmann machines. Various activation functions are also provided, in particular, sigmoidal, softmax-function, cross-entropy. In the course of training, a packet gradient descent (Batch SGD) is used.
Consider the configuration of a neural network in Theano. For convenience, we will implement the LogisticRegression class ( Fig. 3 ), which will contain variables — learning parameters W, b and functions for working with them — counting the network response (y = softmax (Wx + b)) and the error function. Then, to train the neural network, we create the function train_model. For it, it is necessary to describe the methods that determine the error function, the rule for calculating gradients, the method of changing the weights of the neural network, the size and location of the mini-batch sample (the images themselves and the answers for them). After determining all the parameters, the function is compiled and passed to the learning cycle.
Fig. 3. Class diagram for the implementation of the neural network in Theano
Software class implementation
class LogisticRegression(object): def __init__(self, input, n_in, n_out): # y = W * x + b # , , self.W = theano.shared( # value=numpy.zeros((n_in, n_out), dtype=theano.config.floatX), name='W', borrow=True) self.b = theano.shared(value=numpy.zeros((n_out,), dtype=theano.config.floatX), name='b', borrow=True) # softmax, - y_pred self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b) self.y_pred = T.argmax(self.p_y_given_x, axis=1) self.params = [self.W, self.b] # def negative_log_likelihood(self, y): return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y]) # x - # (minibatch) x # y - x = T.matrix('x') y = T.ivector('y') # MNIST 28*28 classifier = LogisticRegression(input=x, n_in=28 * 28, n_out=10) # , cost = classifier.negative_log_likelihood(y) # , Theano - grad g_W = T.grad(cost=cost, wrt=classifier.W) g_b = T.grad(cost=cost, wrt=classifier.b) # updates = [(classifier.W, classifier.W - learning_rate * g_W), (classifier.b, classifier.b - learning_rate * g_b)] # , train_model = theano.function( inputs=[index], outputs=cost, updates=updates, givens={ x: train_set_x[index * batch_size: (index + 1) * batch_size], y: train_set_y[index * batch_size: (index + 1) * batch_size] } ) To quickly save and load neural network parameters, you can use functions from the cPickle package:
import cPickle save_file = open('path', 'wb') cPickle.dump(classifier.W.get_value(borrow=True), save_file, -1) cPickle.dump(classifier.b.get_value(borrow=True), save_file, -1) save_file.close() file = open('path') classifier.W.set_value(cPickle.load(save_file), borrow=True) classifier.b.set_value(cPickle.load(save_file), borrow=True) It is easy to see that the process of creating a model and determining its parameters requires writing a three-dimensional and noisy code. The library is low-level. It should be noted its flexibility, as well as the availability of the implementation and use of its own components. The official website of the library has a large number of teaching materials on various topics.
Comparing libraries on the example of the handwriting numbers classification task
Test infrastructure
The following test infrastructure was used in the course of experiments to evaluate library performance:
- Ubuntu 12.04, Intel Core i5-3210M @ 2.5GHz (CPU experiments).
- Ubuntu 14.04, Intel Core i5-2430M @ 2.4GHz + NVIDIA GeForce GT 540M (GPU experiments).
- GCC 4.8, NVCC 6.5.
Network topologies and learning parameters
Computational experiments were carried out on fully connected and convolutional neural networks of the following structure:
- Three-layer fully connected neural network (MLP, Fig. 4 ):
- 1st layer - FC (in: 784, out: 392, activation: tanh).
- 2d layer - FC (in: 392, out: 196, activation: tanh).
- 3d layer - FC (in: 196, out: 10, activation: softmax).
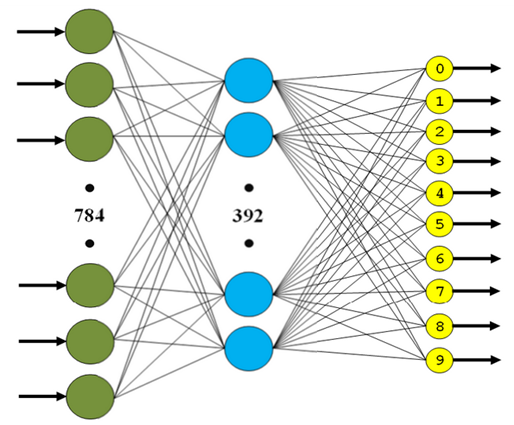
Fig. 4. Structure of a three-layer full mesh network - Convolutional neural network (CNN, Fig. 5 ):
- 1st layer - convolution (in filters: 1, out filters: 28, size: 5x5, stride: 1x1).
- 2d layer - max-pooling (size: 3x3, stride: 3x3).
- 3d layer - convolution (in filters: 28, out filters: 56, size: 5x5, stride 1x1).
- 4th layer - max-pooling (size: 2x2, stride: 2x2).
- 5th layer - FC (in: 224, out: 200, activation: tanh).
- 6th layer - FC (in: 200, out: 10, activation: softmax).
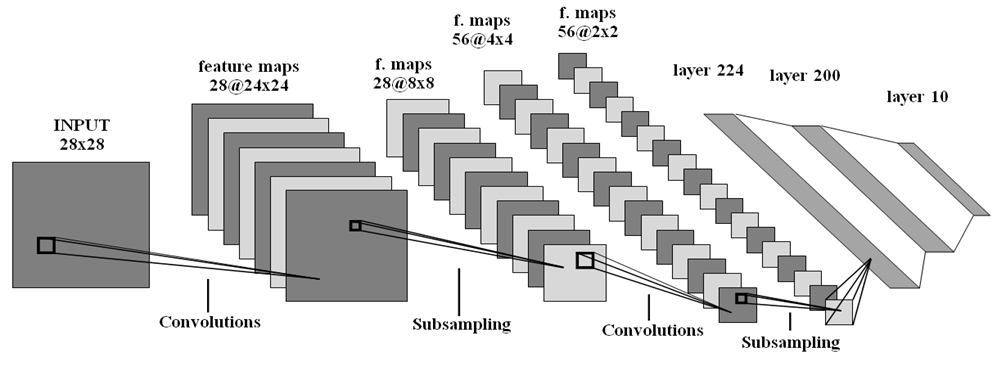
Fig. 5. The structure of the convolutional neural network
All weights were initialized randomly according to a uniform distribution law in the range (−6 / (n_in + n_out), 6 / (n_in + n_out)), where n_in, n_out is the number of neurons at the input and output of the layer, respectively. The parameters of the stochastic gradient descent (SGD) are chosen equal to the following values: learning rate - 0.01, momentum - 0.9, weight decay - 5e-4, batch size - 128, maximum number of iterations - 150.
Experimental results
The learning time of the neural networks described earlier ( Fig. 4 , 5 ) using the four libraries reviewed is presented below ( Fig. 6 ). It is easy to see that Pylearn2 shows worse performance (both on the CPU and on the GPU) compared to other libraries.As for the rest, the learning time depends heavily on the network structure. The best result among the implementations of networks running on the CPU, showed the Torch library (and on CNN it overtook itself, running on the GPU). Among GPU implementations, the best result (on both networks) was shown by the Caffe library. In general, the use of Caffe left only positive impressions.
CPU implementation (see infrastructure ):
Implementation GPU (see infrastructure ):
Fig.6. The learning time of the MLP and CNN networks described in the previous paragraph.
As for the time for classifying one image on the CPU using trained models ( Fig. 7 ), it is easy to see that the Torch library was out of competition on both test neural networks. A little behind her was Caffe on CNN, which at the same time showed the worst classification time for MLP.
CPU implementation (see infrastructure ):
Fig.7. Classification time of one image using trained MLP and CNN networks
If we look at the classification accuracy, on the MLP network it is higher than 97.4%, and CNN - ~ 99% for all libraries ( Table 2 ). The obtained accuracy values are somewhat lower than those listed on the MNIST website on the same neural network structures. Small differences are due to differences in the settings of the initial weights of the networks and the parameters of optimization methods used in the learning process. Actually, the goal of achieving maximum accuracy values was not, it was rather necessary to build identical network structures and set the most similar training parameters.
Table 2. The average value and dispersion of classification accuracy indicators for 5 experiments
| Caffe | Pylearn2 | Theano | Torch | |||||
| Accuracy ,% | Dispersion | Accuracy ,% | Dispersion | Accuracy ,% | Dispersion | Accuracy ,% | Dispersion | |
| MLP | 98.26 | 0.0039 | 98.1 | 0 | 97.42 | 0.0023 | 98.19 | 0 |
| CNN | 99.1 | 0.0038 | 99.3 | 0 | 99.16 | 0.0132 | 99.4 | 0 |
Comparing selected libraries
Based on the research of the library's functional, as well as the performance analysis, each of them was rated on a scale from 1 to 3 using the following criteria:
- The learning rate reflects the learning time of the neural network models considered at the stage of conducting experiments.
- The grading rate reflects the grading time of a single image.
- Usability is a criterion that allows you to estimate the time spent studying a library.
- The flexibility of setting up links between layers, setting parameters for methods, and the availability of various data processing methods.
- — ( , , , , ).
Consider the estimates obtained for each criterion, we place the places of each library from the first to the third ( Table 3 ). According to the results of computational experiments in terms of speed of work, the Caffe library is most preferable ( Fig. 6 ). At the same time, it turned out to be the most convenient to use. From a position of flexibility, the Theano library showed the best results. In terms of functionality, Pylearn2 is the most complete, but its use is complicated by the need to understand the internal structure (the formation of YAML files requires this). The most detailed and understandable material for the study provide developers Torch. Having shown the average indicators for each criterion separately, it was she who won in the rating of the reviewed libraries.
Table 3. Library comparison results (ranks from 1 to 3 for each criterion)
| Learning speed | Grading speed | Convenience | Flexibility | Functional | Documentation | Amount | |
| Caffe | one | 2 | one | 3 | 3 | 2 | 12 |
| Pylearn2 | 3 | 3 | 2 | 3 | one | 3 | 15 |
| Torch | 2 | one | 2 | 2 | 2 | one | ten |
| Theano | 2 | 2 | 3 | one | 2 | 2 | 12 |
Conclusion
Summarizing, we can say that the Torch library is the most mature. At the same time, the libraries of Caffe and Theano are not inferior to it by many criteria ( table 3 ), therefore the possibility of their subsequent use cannot be ruled out. In the future, Caffe and Torch libraries are planned to be used to study the applicability of deep learning methods to the tasks of detecting people, pedestrians and cars.
The work was done in the laboratory "Information Technologies" of the Faculty of the VMK UNN them. N.I. Lobachevsky with the support of the company Itseez.
Used sources
- Kustikova, VD, Druzhkov, PN: A Survey of Deep Learning Methods and Software for Image Classification and Object Detection. In: Proc. of the 9th Open German-Russian Workshop on Pattern Recognition and Image Understanding. (2014)
- Hinton, GE: Learning Multiple Layers of Representation. In: Trends in Cognitive Sciences. Vol. 11. pp. 428-434. (2007)
- LeCun, Y., Kavukcuoglu, K., Farabet, C.: Convolutional networks and applications in vision. In: Proc. of the IEEE Int. Symposium on Circuits and Systems (ISCAS). pp. 253-256. (2010)
- Hayat, M., Bennamoun, M., An, S.: Learning Non-Linear Reconstruction Models for Image Set Classification. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. (2014)
- Restricted Boltzmann Machines (RBMs), www.deeplearning.net/tutorial/rbm.html .
- Bottou, L.: Stochastic Gradient Descent Tricks. Neural Networks: Tricks of the Trade, research.microsoft.com/pubs/192769/tricks-2012.pdf .
- Duchi, J., Hazan, E., Singer, Y.: Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. In: The Journal of Machine Learning Research. (2011)
- Sutskever, I., Martens, J., Dahl, G., Hinton, G.: On the Importance of Initialization and Momentum in Deep Learning. In: Proc. of the 30th Int. Conf. on Machine Learning. (2013)
- (ASGD), research.microsoft.com/pubs/192769/tricks-2012.pdf .
- ---, en.wikipedia.org/wiki/Limited-memory_BFGS .
Source: https://habr.com/ru/post/254747/
All Articles