Asynchronous work with Tarantool on Python
On Habré there are already articles about NoSQL DBMS Tarantool and how it is used in Mail.Ru Group (and not only). However, there is no recipe for how to work with Tarantool on Python. In my article, I want to talk about how we prepare Tarantool Python in our projects, what problems and difficulties arise in this case, pros, cons, pitfalls, and, of course, “what is the trick”. So, first things first.

Tarantool is an Application Server for Lua . He is able to store data on disk, provides quick access to them. Tarantool is used in tasks with large data streams per unit of time. If we talk about numbers, these are tens and hundreds of thousands of operations per second. For example, in one of my projects, more than 80,000 requests per second are generated (sample, insert, update, delete), while the load is evenly distributed across 4 servers with 12 instances of Tarantool. Not all modern DBMSs are ready to work with such loads. In addition, with such a large amount of data, it is very expensive to wait for the request to be completed, so the programs themselves must quickly switch from one task to another. For effective and uniform loading of the server's CPU (all its cores), Tarantool and asynchronous techniques in programming are needed.
Before talking about asynchronous Python code, you need a good understanding of how regular synchronous Python code interacts with Tarantool. I will use the version of Tarantool 1.6 under CentOS, its installation is simple and trivial and is described in detail on the project site, there you can also find an extensive user guide . I want to note that recently, with the advent of good documentation, it has become much easier to understand the launch and use of the Tarantool instance. More on Habré quite recently appeared a useful article " Tarantool 1.6 - let's begin ."
')
So, Tarantool is installed, running and ready to go. To work with Python 2.7, we take the tarantool-python connector from pypi :
This is still enough to solve our problems. And what are they? In one of my projects, it became necessary to “stack” the data stream in Tarantool for further processing, with the size of one data packet being approximately 1.5 KB. Before proceeding to the solution of the problem, one should study the issue well and test the chosen approaches and tools. The script for testing performance looks elementary and is written in a couple of minutes:
It's simple: in a cycle we consistently make 100 thousand inserts in Tarantool. On my virtual machine, this code is executed on average in 32 seconds, that is, about three thousand inserts per second. The program is simple, and if the resulting performance is enough, then you can do nothing more, because, as you know, "premature optimization is evil." However, this was not enough for our project, moreover, Tarantool itself can show much better results.
Before taking thoughtless steps, we will try to carefully examine our code and how it works. Thanks to my colleague Dreadatour for his series of articles on profiling Python code.
Before launching the profiler, it is helpful to understand how the program works; after all, the best tool for profiling is the developer’s head. The script itself is simple, there is nothing special to study there, let's try to "dig deeper." If you look into the implementation of the connector driver, you can understand that the request is packaged using the msgpack library, sent to the socket using the sendall call, and then the length of the response and the response is read from the socket. Already more interesting. How many operations with a Tarantool socket will be made as a result of executing this code? In our case, one call to socket.sendall (sent data) and two calls to socket.recv (received the answer length and the response itself) will be made for one tnt.insert request. The “close look” method says that 200k + 100k = 300k read / write system calls will be made to insert one hundred thousand records. And the profiler (I used cProfile and kcachegrind to interpret the results) confirms our conclusions:
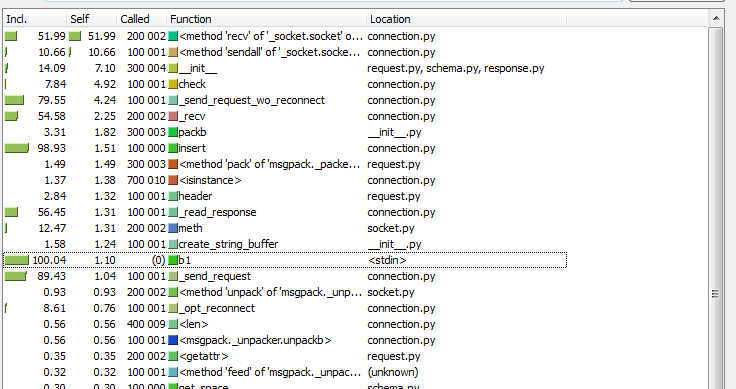
What can be changed in this scheme? First of all, of course, I want to reduce the number of system calls, that is, operations with a Tarantool socket. This can be done by grouping tnt.insert requests into a “bundle” and calling socket.sendall for all requests at once. Likewise, you can read a “packet” of responses from Tarantool for one socket.recv from the socket. With the usual classical programming style, this is not so easy: you need a buffer for the data, a delay to accumulate data into the buffer, and you still need to return the results of the queries without delay. And what to do if there were a lot of requests and suddenly there was very little? There will again be delays that we are trying to avoid. In general, a fundamentally new approach is needed, but most importantly, I want to leave the source code of the original task as simple as it was originally. Asynchronous frameworks come to the rescue of our task.
I had to deal with several asynchronous frameworks: twisted , tornado , gevent, and others. On Habré, the question of comparison and benchmarks of these tools, for example, once and twice , has been raised many times .
My choice fell on gevent. The main reason is the efficiency of working with I / O operations and the simplicity of writing code. A good tutorial on using this library can be found here . And in this tutorial there is a classic example of a fast crawler:
On my virtual machine for this test, the following results were obtained:
A good performance boost! To make the synchronous code work asynchronously using gevent, it was necessary to wrap the fetch call into gevent.spawn , as if parallelizing the downloading of the URLs themselves. It also took monkey.patch_socket () , after which all calls for working with sockets become cooperative. Thus, while one URL is being downloaded and the program is waiting for a response from a remote service, the gevent engine switches to other tasks and instead of useless waiting, tries to download other available documents. In the depths of Python, all gevent threads are executed sequentially, but due to the fact that there are no expectations ( wait system calls), the final result is faster.
It looks good, and most importantly - this approach is very well suited for our task. However, the tarantool-python driver does not know how to work with a gevent out of the box, and I had to write a gtarantool connector on top of it.
The gtarantool connector works with gevent and Tarantool 1.6 and is now available on pypi:
In the meantime, the new solution to our problem takes the following form:
What has changed compared to synchronous code? We divided the insertion of 100k records between ten asynchronous "green" threads, each of which makes about 10k calls to tnt.insert in a loop, and all this through one connection to Tarantool. The program execution time was reduced to 12 seconds, which is almost 3 times more efficient than the synchronous version, and the number of data inserts in the database increased to 8 thousand per second. Why does such a scheme work faster? What is the trick?
The gtarantool connector internally uses a buffer of requests to the Tarantool socket and separate “green streams” of read / write to this socket. We try to look at the results in the profiler (this time I used the Greenlet Profiler - this is an adapted profiler for greenlets yappi):

Analyzing the results in kcachegrind, we see that the number of calls to socket.recv decreased from 100k to 10k, and the number of calls to socket.send dropped from 200k to 2.5k. Actually, this makes working with Tarantool more efficient: less heavy system calls due to lighter and “cheaper” grinlets. And the most important and pleasant thing is that the source program code remained, in fact, “synchronous”. There are no ugly twisted-callbacks in it.
We successfully use this approach in our project. What is the profit:
One of the differences between different asynchronous frameworks is the ability to work under Python 3. For example, gevent does not support it. Moreover, the tarantool-python library will not work under Python 3 either (they have not had time to port yet). How so?
The path of the Jedi is thorny. I really wanted to compare asynchronous work with tarantool from under the second and third versions of Python, and then I decided to rewrite everything in Python 3.4. After Python 2.7 it was a bit unusual to write code:
But the addiction was successful, and now I try to write the code for Python 2.7 right away so that it works in Python 3 without any changes.
The tarantool-python connector had to be slightly modified:
It turned out fork of the synchronous connector working under Python 3.4. After a thorough check, this code may be poured into the main branch of the library, but for now you can install it directly from GitHub:
The first results of benchmarks did not cause delight. The usual synchronous version of inserting 100k records, 1.5 KB in size, began on average a little more than a minute — twice as long as the same code under the second version of Python! Profiling again comes to the rescue:

Wow! Well, where did 400k call socket.recv come from ? Where did the 200k socket.sendall calls come from ? I had to dive into the tarantool-python connector code again: as it turned out, this is the result of the work of Python strings and bytes as dict keys. For example, you can compare this code:
Python 3.4:
Python 2.7:
These little things are a vivid example of the complexity of porting code to Python 3, and even tests here do not always help, because formally everything works, but works twice as slowly, and for our realities this is a significant difference. Replacing the code, adding “a couple of bytes” to the connector (link to changes in the connector code , as well as another change ) - there is a result!

Well, now not bad! The synchronous version of the connector began to cope with the task in an average of 35 seconds, which is slightly slower than Python 2.7, but you can live with it.
Asyncio is Cortina for Python 3 out of the box. There is documentation , there are examples, there are ready-made libraries for asyncio and Python 3. At first glance, everything is quite complicated and confusing (at least compared to gevent), but upon further consideration everything falls into place. And so, after some effort, I wrote a version of the connector for Tarantool for asyncio - aiotarantool .
This connector is also available via pypi:
I want to note that the code of our original task on asyncio has become a bit more complicated than its original version. There were designs yield from , decorators @ asyncio.coroutine appeared , but in general I like it, and there are not so many differences from gevent:
This option copes with the task, on average, in 13 seconds (it turns out about 7.5k inserts per second), which is slightly slower than the version in Python 2.7 and gevent, but much better than all synchronous versions. Aiotarantool has one small, but very important difference from other libraries available on asyncio.org : the tarantool.connect call is made outside of asyncio.event_loop . In fact, this call does not create a real connection: it will be made later, inside one of the corutins when you first call yield from tnt.insert . This approach seemed to me easier and more convenient when programming in asyncio.
By tradition, the results of profiling (I used the yappi profiler, but there is a suspicion that he does not quite correctly count the number of function calls when working with asyncio):

As a result, we see 5k calls of StreamReader.feed_data and StreamWriter.write , which is undoubtedly much better than 200k of socket.recv calls and 100k of socket.sendall calls in a synchronous version.
I present the results of the comparison of the considered options for working with Tarantool. Benchmark code can be found in the tests directory of the gtarantool and aiotrantool libraries . The benchmark performs the insertion, search, modification and deletion of 100,000 records 1.5 KB in size. Each test was run ten times, the tables show the average rounded value, since it is not the exact figures that are important (they depend on the particular iron), but their ratio.
Are compared:
Test run time in seconds (less is better):
The number of operations per second (more - better):
The gtarantool performance is slightly better than that of aiotarantool. We have been using gtarantool for a long time, it is a proven solution for large loads, however gevent is not supported in Python 3. In addition, it should be remembered that gevent is a third-party library that requires compilation during installation. Asyncio attracts with its speed and novelty, it goes into Python 3 "out of the box", and there are no "crutches" in the form of "monkey.patch". But under the real load aiotarantool in our project has not yet worked. All ahead!
To maximize the use of resources of our server, we will try to complicate the code of our benchmark a little. We make simultaneous deletion, insertion, modification and selection of data (a fairly common load profile) in one Python process, and we will create several, say, 22 (magic number) such processes. If there are 24 total cores on the machine, then we will leave one core to the system (just in case), give one core to Tarantool (that's enough for it!), And take the remaining 22 to the Python processes. We will do the comparison on gevent, and on asyncio, the benchmark code can be found here for gtarantool, and here for aiotarantool.
It is very important to visually and beautifully display the results for later comparison. It's time to evaluate the capabilities of the new version of Tarantool 1.6: in fact, it is a Lua interpreter, which means that we can run absolutely any Lua code directly in the database. We write the simplest program, and our Tarantool is already able to send any of its statistics to the graphite . Add the code to our Tarantool init script (in a real project, of course, it’s better to put such things into a separate module):
Run Tarantool and automatically get graphs with statistics. Cool? I really liked this feature!
Now we will conduct two benchmarks: in the first we will perform simultaneous deletion, insertion, modification and selection of data. In the second benchmark we will perform only the sample. On all graphs, the abscissa is time, and the ordinate is the number of operations per second:
Let me remind you that the process Tarantool used only one core. In the first benchmark, the CPU load (of this core) at the same time was 100%, and in the second test, the Tarantool process only recycled its core by 60%.
The results obtained allow us to conclude that the techniques discussed in the article are suitable for working with large loads in our projects.
Examples in the article are, of course, artificial. The real tasks are a bit more complicated and diverse, but their solutions in the general case look exactly as shown in the above code. Where can I apply this approach? Where “many, many, many requests per second” are required: in this case, asynchronous code is needed to work effectively with Tarantool. Korutiny are effective where there is an expectation of events (system calls), and the classic example of such a task is the crawler.
Writing code in asyncio or gevent is not as difficult as it seems, but you should definitely pay a lot of attention to code profiling: often asynchronous code does not work at all as expected.
Tarantool and its protocol are very well suited for working with asynchronous development style. One has only to plunge into the world of Tarantool and Lua, and one can be endlessly surprised at their powerful capabilities. Python code can work effectively with Tarantool, and in Python 3 there is a good potential for developing on asyncio quiches.
I hope that the material of this article will benefit the community and expand the knowledge base about Tarantool and about asynchronous programming. I think that asyncio and aiotarantool will be used in production and in our projects, and I will have something to share with Habr's readers.
And, of course, versions of connectors for Tarantool:
It's time to try them in your case!
Tarantool is an Application Server for Lua . He is able to store data on disk, provides quick access to them. Tarantool is used in tasks with large data streams per unit of time. If we talk about numbers, these are tens and hundreds of thousands of operations per second. For example, in one of my projects, more than 80,000 requests per second are generated (sample, insert, update, delete), while the load is evenly distributed across 4 servers with 12 instances of Tarantool. Not all modern DBMSs are ready to work with such loads. In addition, with such a large amount of data, it is very expensive to wait for the request to be completed, so the programs themselves must quickly switch from one task to another. For effective and uniform loading of the server's CPU (all its cores), Tarantool and asynchronous techniques in programming are needed.
How does the tarantool-python connector work?
Before talking about asynchronous Python code, you need a good understanding of how regular synchronous Python code interacts with Tarantool. I will use the version of Tarantool 1.6 under CentOS, its installation is simple and trivial and is described in detail on the project site, there you can also find an extensive user guide . I want to note that recently, with the advent of good documentation, it has become much easier to understand the launch and use of the Tarantool instance. More on Habré quite recently appeared a useful article " Tarantool 1.6 - let's begin ."
')
So, Tarantool is installed, running and ready to go. To work with Python 2.7, we take the tarantool-python connector from pypi :
$ pip install tarantool-python This is still enough to solve our problems. And what are they? In one of my projects, it became necessary to “stack” the data stream in Tarantool for further processing, with the size of one data packet being approximately 1.5 KB. Before proceeding to the solution of the problem, one should study the issue well and test the chosen approaches and tools. The script for testing performance looks elementary and is written in a couple of minutes:
import tarantool import string mod_len = len(string.printable) data = [string.printable[it] * 1536 for it in range(mod_len)] tnt = tarantool.connect("127.0.0.1", 3301) for it in range(100000): r = tnt.insert("tester", (it, data[it % mod_len])) It's simple: in a cycle we consistently make 100 thousand inserts in Tarantool. On my virtual machine, this code is executed on average in 32 seconds, that is, about three thousand inserts per second. The program is simple, and if the resulting performance is enough, then you can do nothing more, because, as you know, "premature optimization is evil." However, this was not enough for our project, moreover, Tarantool itself can show much better results.
Profile the code
Before taking thoughtless steps, we will try to carefully examine our code and how it works. Thanks to my colleague Dreadatour for his series of articles on profiling Python code.
Before launching the profiler, it is helpful to understand how the program works; after all, the best tool for profiling is the developer’s head. The script itself is simple, there is nothing special to study there, let's try to "dig deeper." If you look into the implementation of the connector driver, you can understand that the request is packaged using the msgpack library, sent to the socket using the sendall call, and then the length of the response and the response is read from the socket. Already more interesting. How many operations with a Tarantool socket will be made as a result of executing this code? In our case, one call to socket.sendall (sent data) and two calls to socket.recv (received the answer length and the response itself) will be made for one tnt.insert request. The “close look” method says that 200k + 100k = 300k read / write system calls will be made to insert one hundred thousand records. And the profiler (I used cProfile and kcachegrind to interpret the results) confirms our conclusions:
What can be changed in this scheme? First of all, of course, I want to reduce the number of system calls, that is, operations with a Tarantool socket. This can be done by grouping tnt.insert requests into a “bundle” and calling socket.sendall for all requests at once. Likewise, you can read a “packet” of responses from Tarantool for one socket.recv from the socket. With the usual classical programming style, this is not so easy: you need a buffer for the data, a delay to accumulate data into the buffer, and you still need to return the results of the queries without delay. And what to do if there were a lot of requests and suddenly there was very little? There will again be delays that we are trying to avoid. In general, a fundamentally new approach is needed, but most importantly, I want to leave the source code of the original task as simple as it was originally. Asynchronous frameworks come to the rescue of our task.
Gevent and Python 2.7
I had to deal with several asynchronous frameworks: twisted , tornado , gevent, and others. On Habré, the question of comparison and benchmarks of these tools, for example, once and twice , has been raised many times .
My choice fell on gevent. The main reason is the efficiency of working with I / O operations and the simplicity of writing code. A good tutorial on using this library can be found here . And in this tutorial there is a classic example of a fast crawler:
import time import gevent.monkey gevent.monkey.patch_socket() import gevent import urllib2 import json def fetch(pid): url = 'http://json-time.appspot.com/time.json' response = urllib2.urlopen(url) result = response.read() json_result = json.loads(result) return json_result['datetime'] def synchronous(): for i in range(1,10): fetch(i) def asynchronous(): threads = [] for i in range(1,10): threads.append(gevent.spawn(fetch, i)) gevent.joinall(threads) t1 = time.time() synchronous() t2 = time.time() print('Sync:', t2 - t1) t1 = time.time() asynchronous() t2 = time.time() print('Async:', t2 - t1) On my virtual machine for this test, the following results were obtained:
Sync: 1.529 Async: 0.238 A good performance boost! To make the synchronous code work asynchronously using gevent, it was necessary to wrap the fetch call into gevent.spawn , as if parallelizing the downloading of the URLs themselves. It also took monkey.patch_socket () , after which all calls for working with sockets become cooperative. Thus, while one URL is being downloaded and the program is waiting for a response from a remote service, the gevent engine switches to other tasks and instead of useless waiting, tries to download other available documents. In the depths of Python, all gevent threads are executed sequentially, but due to the fact that there are no expectations ( wait system calls), the final result is faster.
It looks good, and most importantly - this approach is very well suited for our task. However, the tarantool-python driver does not know how to work with a gevent out of the box, and I had to write a gtarantool connector on top of it.
Gevent and Tarantool
The gtarantool connector works with gevent and Tarantool 1.6 and is now available on pypi:
$ pip install gtarantool In the meantime, the new solution to our problem takes the following form:
import gevent import gtarantool import string mod_len = len(string.printable) data = [string.printable[it] * 1536 for it in range(mod_len)] cnt = 0 def insert_job(tnt): global cnt for i in range(10000): cnt += 1 tnt.insert("tester", (cnt, data[it % mod_len])) tnt = gtarantool.connect("127.0.0.1", 3301) jobs = [gevent.spawn(insert_job, tnt) for _ in range(10)] gevent.joinall(jobs) What has changed compared to synchronous code? We divided the insertion of 100k records between ten asynchronous "green" threads, each of which makes about 10k calls to tnt.insert in a loop, and all this through one connection to Tarantool. The program execution time was reduced to 12 seconds, which is almost 3 times more efficient than the synchronous version, and the number of data inserts in the database increased to 8 thousand per second. Why does such a scheme work faster? What is the trick?
The gtarantool connector internally uses a buffer of requests to the Tarantool socket and separate “green streams” of read / write to this socket. We try to look at the results in the profiler (this time I used the Greenlet Profiler - this is an adapted profiler for greenlets yappi):
Analyzing the results in kcachegrind, we see that the number of calls to socket.recv decreased from 100k to 10k, and the number of calls to socket.send dropped from 200k to 2.5k. Actually, this makes working with Tarantool more efficient: less heavy system calls due to lighter and “cheaper” grinlets. And the most important and pleasant thing is that the source program code remained, in fact, “synchronous”. There are no ugly twisted-callbacks in it.
We successfully use this approach in our project. What is the profit:
- We refused to fork. You can use several Python processes, and in each process use one gtarantool connection (or connection pool).
- Inside greenlets, switching is much faster and more efficient than switching between Unix processes.
- Reducing the number of processes has greatly reduced memory consumption.
- The reduction in the number of operations with a Tarantool socket has increased the efficiency of working with the Tarantool itself, it has begun to consume less CPU.
And what about Python 3 and Tarantool?
One of the differences between different asynchronous frameworks is the ability to work under Python 3. For example, gevent does not support it. Moreover, the tarantool-python library will not work under Python 3 either (they have not had time to port yet). How so?
The path of the Jedi is thorny. I really wanted to compare asynchronous work with tarantool from under the second and third versions of Python, and then I decided to rewrite everything in Python 3.4. After Python 2.7 it was a bit unusual to write code:
- print does not work “foo”
- all strings are objects of class str
- no type long
- ...
But the addiction was successful, and now I try to write the code for Python 2.7 right away so that it works in Python 3 without any changes.
The tarantool-python connector had to be slightly modified:
- StandartError replaced by Exception
- basestring replaced by str
- xrange replaced by range
- long - deleted
It turned out fork of the synchronous connector working under Python 3.4. After a thorough check, this code may be poured into the main branch of the library, but for now you can install it directly from GitHub:
$ pip install git+https://github.com/shveenkov/tarantool-python.git@for_python3.4 The first results of benchmarks did not cause delight. The usual synchronous version of inserting 100k records, 1.5 KB in size, began on average a little more than a minute — twice as long as the same code under the second version of Python! Profiling again comes to the rescue:
Wow! Well, where did 400k call socket.recv come from ? Where did the 200k socket.sendall calls come from ? I had to dive into the tarantool-python connector code again: as it turned out, this is the result of the work of Python strings and bytes as dict keys. For example, you can compare this code:
Python 3.4:
>>> a=dict() >>> a[b"key"] = 1 >>> a["key"] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'key' Python 2.7:
>>> a=dict() >>> a[b"key"] = 1 >>> a["key"] 1 These little things are a vivid example of the complexity of porting code to Python 3, and even tests here do not always help, because formally everything works, but works twice as slowly, and for our realities this is a significant difference. Replacing the code, adding “a couple of bytes” to the connector (link to changes in the connector code , as well as another change ) - there is a result!
Well, now not bad! The synchronous version of the connector began to cope with the task in an average of 35 seconds, which is slightly slower than Python 2.7, but you can live with it.
Moving to asyncio in Python 3
Asyncio is Cortina for Python 3 out of the box. There is documentation , there are examples, there are ready-made libraries for asyncio and Python 3. At first glance, everything is quite complicated and confusing (at least compared to gevent), but upon further consideration everything falls into place. And so, after some effort, I wrote a version of the connector for Tarantool for asyncio - aiotarantool .
This connector is also available via pypi:
$ pip install aiotarantool I want to note that the code of our original task on asyncio has become a bit more complicated than its original version. There were designs yield from , decorators @ asyncio.coroutine appeared , but in general I like it, and there are not so many differences from gevent:
import asyncio import aiotarantool import string mod_len = len(string.printable) data = [string.printable[it] * 1536 for it in range(mod_len)] cnt = 0 @asyncio.coroutine def insert_job(tnt): global cnt for it in range(10000): cnt += 1 args = (cnt, data[it % mod_len]) yield from tnt.insert("tester", args) loop = asyncio.get_event_loop() tnt = aiotarantool.connect("127.0.0.1", 3301) tasks = [asyncio.async(insert_job(tnt)) for _ in range(10)] loop.run_until_complete(asyncio.wait(tasks)) loop.close() This option copes with the task, on average, in 13 seconds (it turns out about 7.5k inserts per second), which is slightly slower than the version in Python 2.7 and gevent, but much better than all synchronous versions. Aiotarantool has one small, but very important difference from other libraries available on asyncio.org : the tarantool.connect call is made outside of asyncio.event_loop . In fact, this call does not create a real connection: it will be made later, inside one of the corutins when you first call yield from tnt.insert . This approach seemed to me easier and more convenient when programming in asyncio.
By tradition, the results of profiling (I used the yappi profiler, but there is a suspicion that he does not quite correctly count the number of function calls when working with asyncio):
As a result, we see 5k calls of StreamReader.feed_data and StreamWriter.write , which is undoubtedly much better than 200k of socket.recv calls and 100k of socket.sendall calls in a synchronous version.
Comparison of approaches
I present the results of the comparison of the considered options for working with Tarantool. Benchmark code can be found in the tests directory of the gtarantool and aiotrantool libraries . The benchmark performs the insertion, search, modification and deletion of 100,000 records 1.5 KB in size. Each test was run ten times, the tables show the average rounded value, since it is not the exact figures that are important (they depend on the particular iron), but their ratio.
Are compared:
- synchronous tarantool-python under Python 2.7;
- synchronous tarantool-python under Python 3.4;
- asynchronous version with gtarantool under Python 2.7;
- asynchronous version with aiotarantool under Python 3.4.
Test run time in seconds (less is better):
| Operation (100k records) | tarantool-python 2.7 | tarantool-python 3.4 | gtarantool (gevent) | aiotarantool (asyncio) |
|---|---|---|---|---|
| insert | 34 | 38 | eleven | 13 |
| select | 23 | 23 | ten | 13 |
| update | 34 | 33 | ten | 14 |
| delete | 35 | 35 | ten | 13 |
| Operation (100k records) | tarantool-python 2.7 | tarantool-python 3.4 | gtarantool (gevent) | aiotarantool (asyncio) |
|---|---|---|---|---|
| insert | 3000 | 2600 | 9100 | 7700 |
| select | 4300 | 4300 | 10,000 | 7700 |
| update | 2900 | 3000 | 10,000 | 7100 |
| delete | 2900 | 2900 | 10,000 | 7700 |
We squeeze the maximum out of the server
To maximize the use of resources of our server, we will try to complicate the code of our benchmark a little. We make simultaneous deletion, insertion, modification and selection of data (a fairly common load profile) in one Python process, and we will create several, say, 22 (magic number) such processes. If there are 24 total cores on the machine, then we will leave one core to the system (just in case), give one core to Tarantool (that's enough for it!), And take the remaining 22 to the Python processes. We will do the comparison on gevent, and on asyncio, the benchmark code can be found here for gtarantool, and here for aiotarantool.
It is very important to visually and beautifully display the results for later comparison. It's time to evaluate the capabilities of the new version of Tarantool 1.6: in fact, it is a Lua interpreter, which means that we can run absolutely any Lua code directly in the database. We write the simplest program, and our Tarantool is already able to send any of its statistics to the graphite . Add the code to our Tarantool init script (in a real project, of course, it’s better to put such things into a separate module):
fiber = require('fiber') socket = require('socket') log = require('log') local host = '127.0.0.1' local port = 2003 fstat = function() local sock = socket('AF_INET', 'SOCK_DGRAM', 'udp') while true do local ts = tostring(math.floor(fiber.time())) info = { insert = box.stat.INSERT.rps, select = box.stat.SELECT.rps, update = box.stat.UPDATE.rps, delete = box.stat.DELETE.rps } for k, v in pairs(info) do metric = 'tnt.' .. k .. ' ' .. tostring(v) .. ' ' .. ts sock:sendto(host, port, metric) end fiber.sleep(1) log.info('send stat to graphite ' .. ts) end end fiber.create(fstat) Run Tarantool and automatically get graphs with statistics. Cool? I really liked this feature!
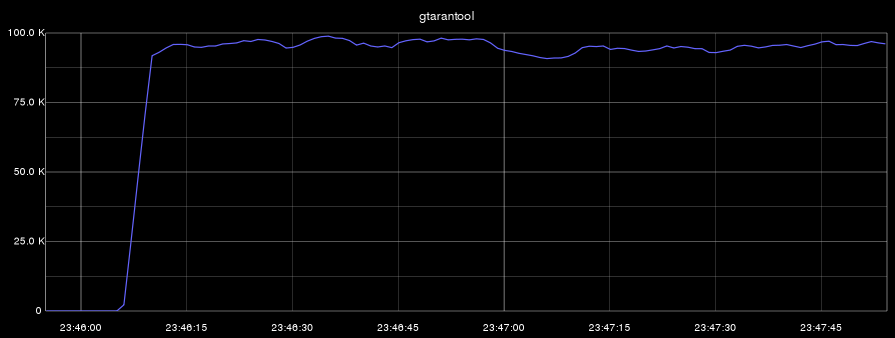
Now we will conduct two benchmarks: in the first we will perform simultaneous deletion, insertion, modification and selection of data. In the second benchmark we will perform only the sample. On all graphs, the abscissa is time, and the ordinate is the number of operations per second:
- gtarantool (insert, select, update, delete):

- aiotarantool (insert, select, update, delete):

- gtarantool (select only):
- aiotarantool (select only):
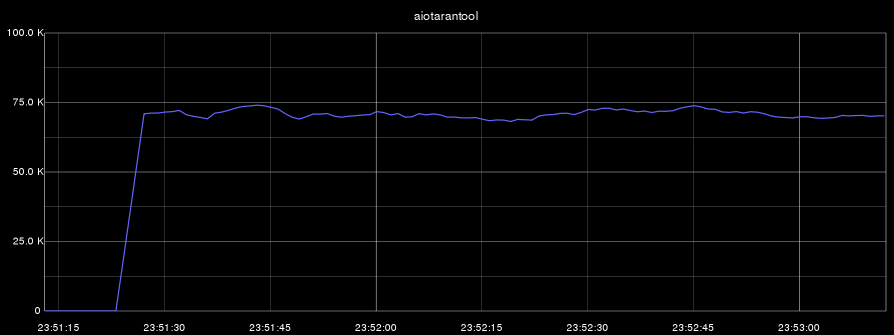
Let me remind you that the process Tarantool used only one core. In the first benchmark, the CPU load (of this core) at the same time was 100%, and in the second test, the Tarantool process only recycled its core by 60%.
The results obtained allow us to conclude that the techniques discussed in the article are suitable for working with large loads in our projects.
findings
Examples in the article are, of course, artificial. The real tasks are a bit more complicated and diverse, but their solutions in the general case look exactly as shown in the above code. Where can I apply this approach? Where “many, many, many requests per second” are required: in this case, asynchronous code is needed to work effectively with Tarantool. Korutiny are effective where there is an expectation of events (system calls), and the classic example of such a task is the crawler.
Writing code in asyncio or gevent is not as difficult as it seems, but you should definitely pay a lot of attention to code profiling: often asynchronous code does not work at all as expected.
Tarantool and its protocol are very well suited for working with asynchronous development style. One has only to plunge into the world of Tarantool and Lua, and one can be endlessly surprised at their powerful capabilities. Python code can work effectively with Tarantool, and in Python 3 there is a good potential for developing on asyncio quiches.
I hope that the material of this article will benefit the community and expand the knowledge base about Tarantool and about asynchronous programming. I think that asyncio and aiotarantool will be used in production and in our projects, and I will have something to share with Habr's readers.
Links that were used when writing the article:
- tarantool.org
- habrahabr.ru/company/mailru/blog/252065 - Tarantool 1.6 first-person
- habrahabr.ru/post/254533 - Tarantool 1.6 - let's start
- emptysqua.re/blog/greenletprofiler - profiler for gevent
- code.google.com/p/yappi - another profiler
- habrahabr.ru/company/mailru/blog/202832 - article about profiling Python code
- docs.python.org/3/library/asyncio.html - documentation for asyncio
- asyncio.org - examples of ready-made libraries
- www.gevent.org - gevent
And, of course, versions of connectors for Tarantool:
It's time to try them in your case!
Source: https://habr.com/ru/post/254727/
All Articles