Files are different or the story about the "file" for java programs
In java programmer's practice, it happens that you really want to change the program's behavior or tweak a couple of classes without repacking the application, compile metrics or test a java application in the depths of a third-party library or jdbc driver without source code. There are several ways to do this. I will tell about the open source aspectj-scripting project, which allows you to solve such problems in jvm.

The story about aspectj-scripting will be in several publications. Let's start with practice! Under the cat, the modification of the maven-changes-plugin behavior without rebuilding it and recompiling it to upload the task list from JIRA to the xml and json files
')
But before rushing into battle, I assume you are in general familiar with the theory of aspect-oriented programming, working with the AspectJ library or other AOP frameworks. I am interested in your opinion in the comments, how true my guess is and whether I should describe the basic things in more detail in the following publications.
Important note: Aspectj-scripting in its current form will not work under JEE or OSGI containers. But at the same time, microservices and standalone java applications get along perfectly and work with his agent.
Aspectj-scripting is a java-based AspectJ-based Load-time weaving (LTW) agent that allows you to describe aspects in the MVEL script language, load and instantiate classes from maven repositories in runtime, use AspectJ syntax to describe pointcut, and supports the life cycle for scripting aspects .
Now a few words about the part for file processing. One of the convenient functions of the maven-changes-plugin is the generation of a report on new features in the release, corrected errors based on information from JIRA, github or track.
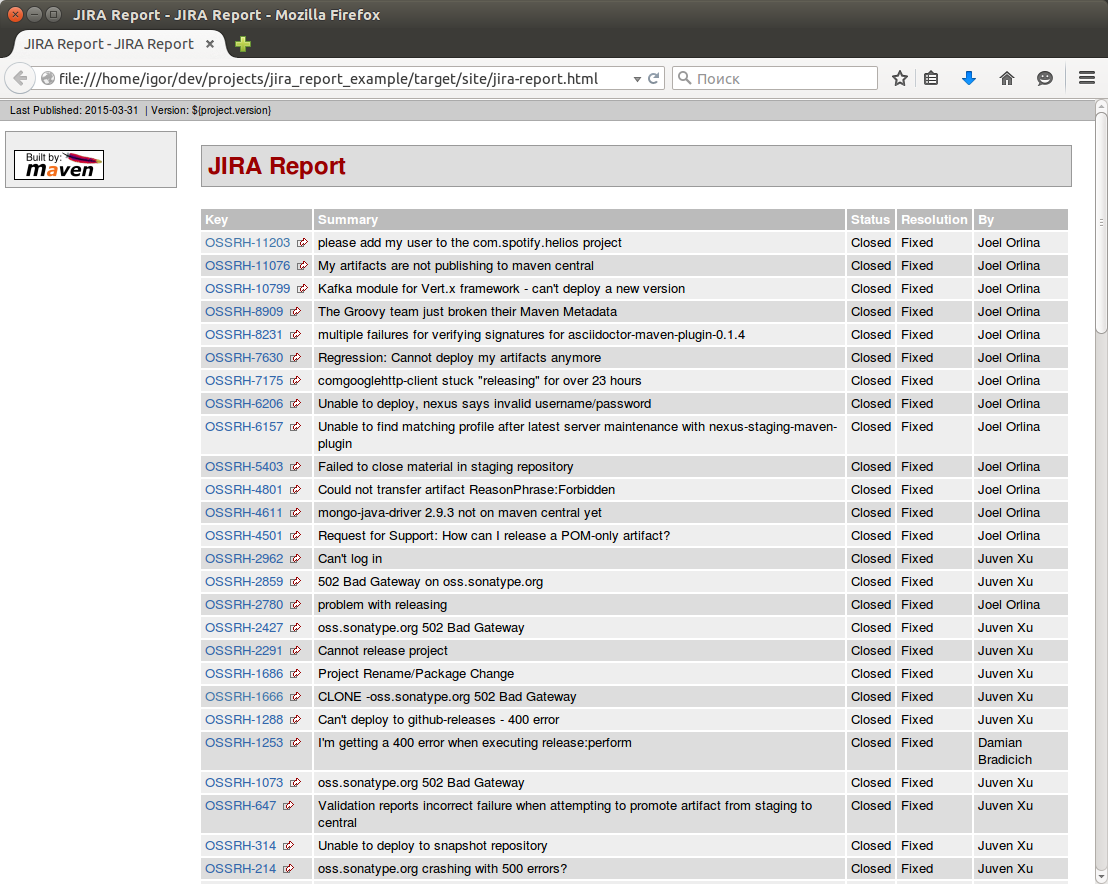
And everything would be fine in the maven-changes-plugin if this plugin would save not only the html report, but also the source data from which it costs it. On the basis of this data from JIRA and the version control system logs for a specific branch, you can make excellent release notes. Avoid manual work and not be afraid that something escaped when writing a report based only on JIRA.
Studying the plug-in code showed that earlier, before using JIRA REST services, it was possible to generate such a file in XML format. But in version 2.11 for REST and jql requests there is no such possibility. But at the same time, the task list returns the list of tasks from the org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList () method and it would be great to serialize it and save it to a file.
No sooner said than done! We write the configuration for the agent in the aspect.xml file. And after describing the process I will tell it works.
For those who prefer json it is possible to describe the configuration in this format. It’s more convenient for me to do multiline aspect descriptions in xml.
Download aspectj-scripting-1.0-agent.jar to the directory where our pom.xml file is located
I set the maven environment variable in the console to load the aspectj-scripting agent in jvm and use the configuration from aspect.xml
After that, launch the maven plugin
And in the same directory after BUILD SUCCESS there are already two files with a list of tasks from JIRA: report.json, report.xml
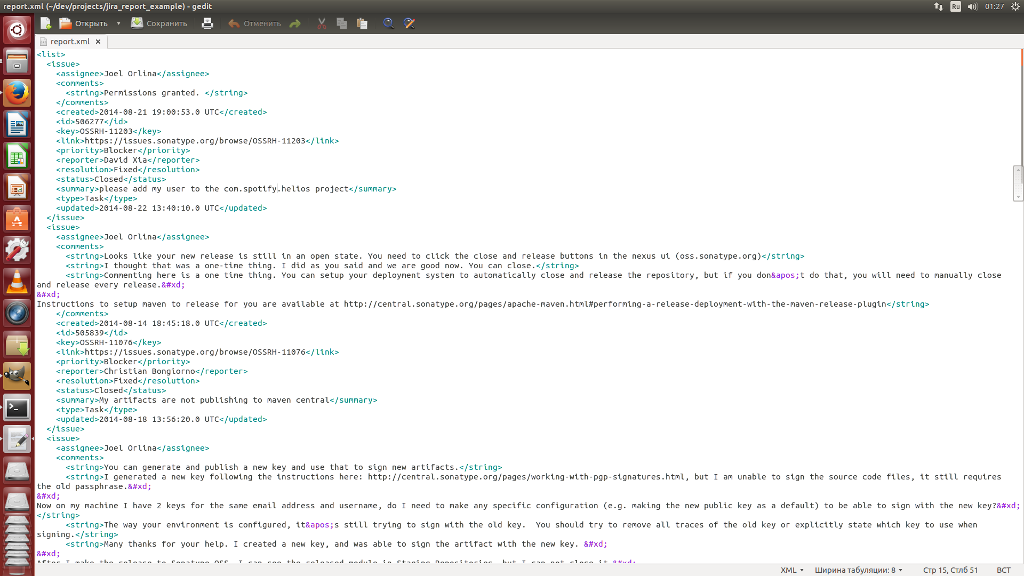
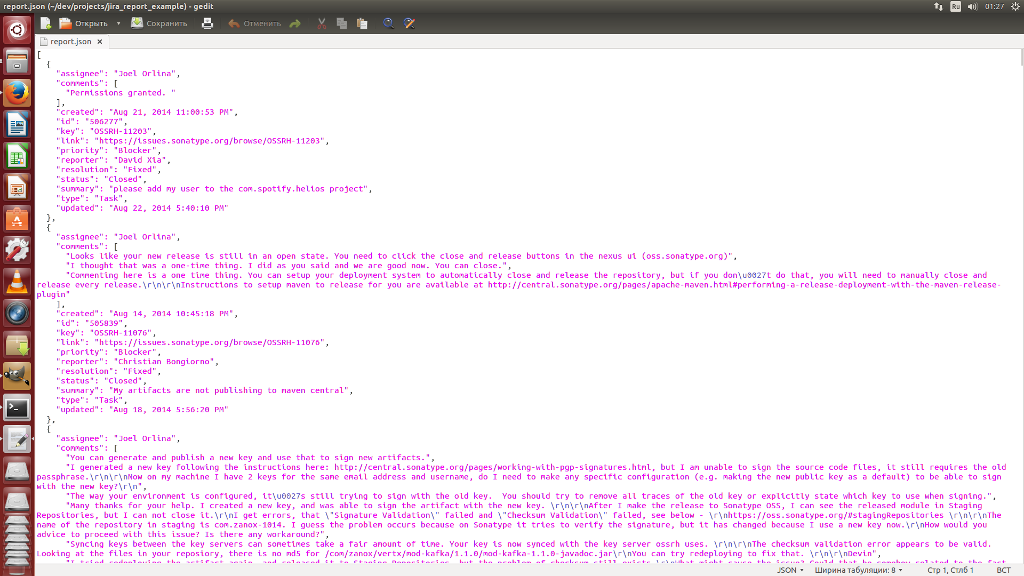
So, how did it come about? First, org.maven.plugin.changes.Dump will be called as the around aspect when calling the getIssueList () method specified in the aspect pointcut.
Using the Sonatype Aether library, 3 artifacts and their transitive dependencies will be downloaded from the central maven repository com.google.code.gson, com.thoughtworks.xstream, commons-io. For each artifact using the dropship library will create its own isolated classloader.
Classesloaders load classes and save to GsonBuilder, XStream, and FileUtils variables. These variables are available in the MVEL script, the syntax of which strongly resembles java. The script allows you to manipulate these classes and serialize the result of the getIssueList () method into XML and JSON format, and write the results to files.
The agent is available as an artifact in the central maven repository.
We specify the jvm java agent at startup and its configuration. Configuration can be loaded from http server or file. The agent downloads dependencies from the maven repository, instruments the code and intercepts the method call from the plugin, saves the task list from JIRA in json and xml format. That's all the magic!
I hope that aspectj-scripting will be useful for your projects!
The story about aspectj-scripting will be in several publications. Let's start with practice! Under the cat, the modification of the maven-changes-plugin behavior without rebuilding it and recompiling it to upload the task list from JIRA to the xml and json files
')
But before rushing into battle, I assume you are in general familiar with the theory of aspect-oriented programming, working with the AspectJ library or other AOP frameworks. I am interested in your opinion in the comments, how true my guess is and whether I should describe the basic things in more detail in the following publications.
Important note: Aspectj-scripting in its current form will not work under JEE or OSGI containers. But at the same time, microservices and standalone java applications get along perfectly and work with his agent.
Aspectj-scripting is a java-based AspectJ-based Load-time weaving (LTW) agent that allows you to describe aspects in the MVEL script language, load and instantiate classes from maven repositories in runtime, use AspectJ syntax to describe pointcut, and supports the life cycle for scripting aspects .
Now a few words about the part for file processing. One of the convenient functions of the maven-changes-plugin is the generation of a report on new features in the release, corrected errors based on information from JIRA, github or track.
And everything would be fine in the maven-changes-plugin if this plugin would save not only the html report, but also the source data from which it costs it. On the basis of this data from JIRA and the version control system logs for a specific branch, you can make excellent release notes. Avoid manual work and not be afraid that something escaped when writing a report based only on JIRA.
Studying the plug-in code showed that earlier, before using JIRA REST services, it was possible to generate such a file in XML format. But in version 2.11 for REST and jql requests there is no such possibility. But at the same time, the task list returns the list of tasks from the org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList () method and it would be great to serialize it and save it to a file.
No sooner said than done! We write the configuration for the agent in the aspect.xml file. And after describing the process I will tell it works.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <configuration> <aspects> <name>org.maven.plugin.changes.Dump</name> <type>AROUND</type> <pointcut>execution(* org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList(..))</pointcut> <artifacts> <artifact>com.google.code.gson:gson:2.3.1</artifact> <classRefs> <variable>GsonBuilder</variable> <className>com.google.gson.GsonBuilder</className> </classRefs> </artifacts> <artifacts> <artifact>com.thoughtworks.xstream:xstream:1.4.8</artifact> <classRefs> <variable>XStream</variable> <className>com.thoughtworks.xstream.XStream</className> </classRefs> </artifacts> <artifacts> <artifact>commons-io:commons-io:2.4</artifact> <classRefs> <variable>FileUtils</variable> <className>org.apache.commons.io.FileUtils</className> </classRefs> </artifacts> <process> <expression> import java.io.File; res = joinPoint.proceed(); gson = new GsonBuilder().setPrettyPrinting().create(); FileUtils.writeStringToFile(new File("report.json"), gson.toJson(res)); xstream = new XStream(); xstream.alias("issue", org.apache.maven.plugin.issues.Issue); FileUtils.writeStringToFile(new File("report.xml"), xstream.toXML(res)); res; </expression> </process> </aspects> </configuration> For those who prefer json it is possible to describe the configuration in this format. It’s more convenient for me to do multiline aspect descriptions in xml.
Download aspectj-scripting-1.0-agent.jar to the directory where our pom.xml file is located
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.igor_suhorukov</groupId> <artifactId>jira_report_example</artifactId> <packaging>jar</packaging> <version>1.0-SNAPSHOT</version> <issueManagement> <system>jira</system> <url>https://issues.sonatype.org/browse/OSSRH</url> </issueManagement> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-changes-plugin</artifactId> <version>2.11</version> <configuration> <useJql>true</useJql> <jiraUser>*** ***</jiraUser> <jiraPassword>*** ***</jiraPassword> </configuration> </plugin> </plugins> </build> </project> I set the maven environment variable in the console to load the aspectj-scripting agent in jvm and use the configuration from aspect.xml
export MAVEN_OPTS="-Dorg.aspectj.weaver.loadtime.configuration=config:file:aspect.xml -javaagent:aspectj-scripting-1.0-agent.jar" After that, launch the maven plugin
mvn changes:jira-report And in the same directory after BUILD SUCCESS there are already two files with a list of tasks from JIRA: report.json, report.xml
So, how did it come about? First, org.maven.plugin.changes.Dump will be called as the around aspect when calling the getIssueList () method specified in the aspect pointcut.
<type>AROUND</type> <pointcut>execution(* org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList(..))</pointcut> Using the Sonatype Aether library, 3 artifacts and their transitive dependencies will be downloaded from the central maven repository com.google.code.gson, com.thoughtworks.xstream, commons-io. For each artifact using the dropship library will create its own isolated classloader.
<artifacts> <artifact>com.google.code.gson:gson:2.3.1</artifact> <classRefs> <variable>GsonBuilder</variable> <className>com.google.gson.GsonBuilder</className> </classRefs> </artifacts> <artifacts> <artifact>com.thoughtworks.xstream:xstream:1.4.8</artifact> <classRefs> <variable>XStream</variable> <className>com.thoughtworks.xstream.XStream</className> </classRefs> </artifacts> <artifacts> Classesloaders load classes and save to GsonBuilder, XStream, and FileUtils variables. These variables are available in the MVEL script, the syntax of which strongly resembles java. The script allows you to manipulate these classes and serialize the result of the getIssueList () method into XML and JSON format, and write the results to files.
res = joinPoint.proceed(); // org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList() // List<org.apache.maven.plugin.issues.Issue> gson = new GsonBuilder().setPrettyPrinting().create(); // json FileUtils.writeStringToFile(new File("report.json"), gson.toJson(res)); // pojo json commons-io report.json xstream = new XStream(); // xml xstream.alias("issue", org.apache.maven.plugin.issues.Issue); // FileUtils.writeStringToFile(new File("report.xml"), xstream.toXML(res)); // pojo xml commons-io report.xml res; // getIssueList() The agent is available as an artifact in the central maven repository.
We specify the jvm java agent at startup and its configuration. Configuration can be loaded from http server or file. The agent downloads dependencies from the maven repository, instruments the code and intercepts the method call from the plugin, saves the task list from JIRA in json and xml format. That's all the magic!
I hope that aspectj-scripting will be useful for your projects!
Source: https://habr.com/ru/post/254571/
All Articles