Under the hood of the educational project Hekslet
Hi, Habr!

In the last article I talked about the new version of the educational project Hekslet . In the voting, you decided that the next article will be about the technical implementation of the platform.
')
Let me remind you, Hekslet is a platform for creating practical lessons on programming in this development environment. By this development environment, we mean a complete machine connected to the network. This important detail distinguishes Hekslet from other educational projects (for example, Codecademy or CodeSchool) - we have no simulators, everything is for real. This allows you to train and learn not only programming, but also work with databases, servers, network, frameworks, and so on. In general, if it runs on a Unix machine, it can be trained in Hexlet. At the same time, knowing it or not, users use Test-Driven Development (TDD), because their solutions are checked by unit tests.
In this post I will talk about the architecture of the Hekslet platform and the tools we use. How to create practical lessons on this platform - in the next article.

Almost the whole backend is written in Rails. Everything works on Amazon Web Services (AWS). Initially, we tried not to get too attached to the AWS infrastructure, but gradually we began to use more of their services. In RDS (Relational Database Service), PostgreSQL (main base) and Redis rotate. Thanks to him, we can not worry about backups, replication, updating - everything works automatically. Also in RDS we use automatic failover - multiAZ. In the case of the fall of the main machine, a synchronous replica automatically rises in another availability zone, and within a couple of minutes the DNS record is bound to the new IP address.
SQS (Simple Queue Service) for building queues. All mail is sent through SES, domains live in Route53. Amazon Simple Notification Service (SNS) sends email delivery status messages to our SQS queue. Pictures and files are stored in S3. Recently we use Cloudfront, CDN from Amazon.
The cornerstone of the whole platform is Docker .
Each service works in our container. One container = one service. Most container images are ready-made images from tutum.co . We store the repository for your application in the Docker Registry . For staging, the image is compiled automatically when you commit to Dockerfile. The code itself is stored in Github. For production, we collect images via Ansible on a separate server. The build takes considerable time, 20-60 minutes, depending on the conditions, so the option “quickly fix production” is impossible. But it turned out not to be a problem, on the contrary - it disciplines. When something goes wrong with production delay for production, we just kill one container and the previous one. Our base grows only horizontally (which is typical for projects with, ahem, ahem, good architecture), which allows us to use the base with different versions of code and not get conflicts. Therefore, a rollback is almost always a simple version replacement code.
At first, for deployment, we use Capistrano, but eventually abandoned it in favor of Ansible. It’s a bit unusual, but Ansible just delivers configs to a remote server and starts upstart, which in turn updates the images. In this scheme, we do not need to install anything special on the server, for Ansible only ssh access is needed. Tags are used for versioning (v64, v65, and so on), and staging always uses the latest version of the latest code.
By the way, we love Ansible so much that we did a practical course on it - “Ansible: Introduction” .

A big plus - locally when developing we use almost identical Ansible playbooks as for production. So, the infrastructure is run around locally, as far as possible, which minimizes errors like “And it worked on LAN”. As a result, the deployment process looks like this: a new commit in the Dockerfile in the githaba -> launching a new build in the docker registry -> launching the Ansible playlist -> updated configs on the server -> running upstart -> getting new images.
We also use the Amazon balancer, and in the case of habraeffect we can raise additional machines in 10-20 minutes. An important condition of such a scheme is that the final web servers do not store state (stateless), no data is stored on them. This allows you to scale quickly.
We also love Amazon, about Route53 (domain management / DNS) and about the balancer, we have lessons in the “Distributed Systems” cycle .
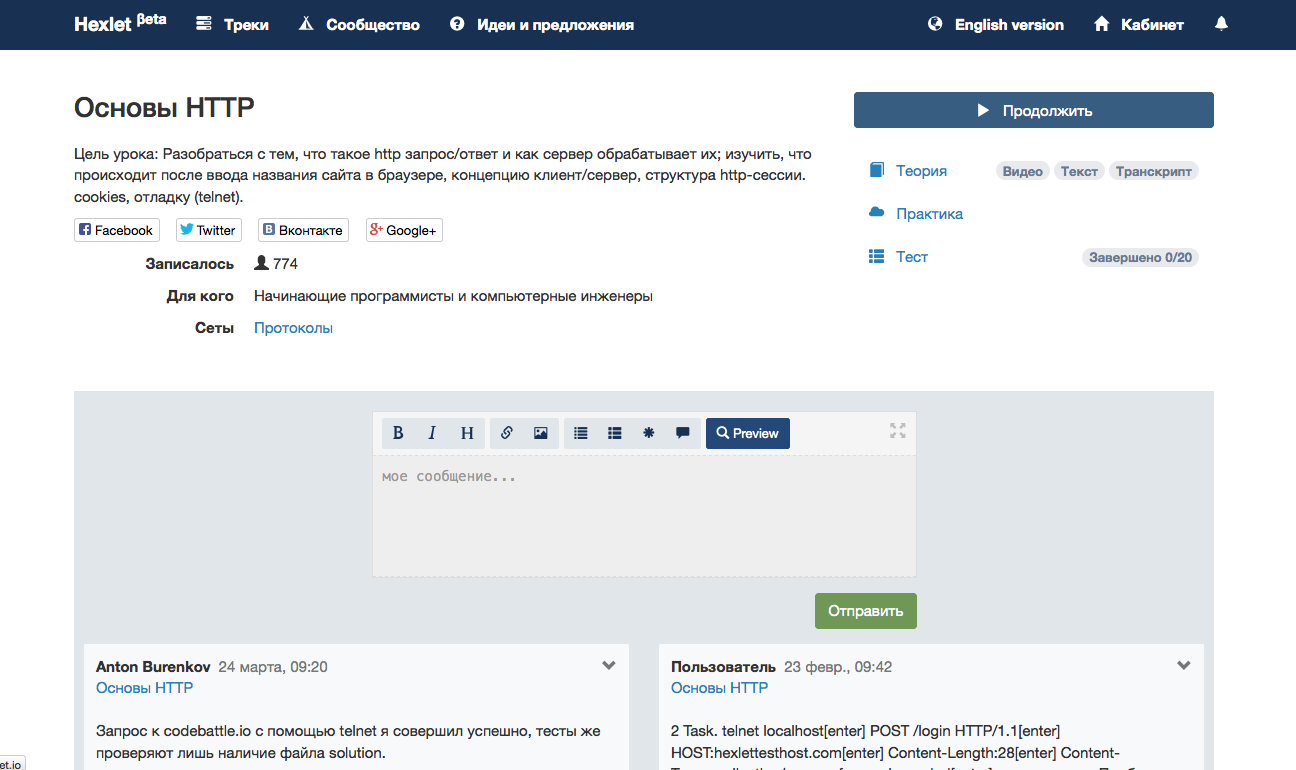
Popular lesson page.
The essence of the project is to allow people to study in a real environment; for this, we raise a container for each user in which he performs a practical exercise. These containers are lifted on a special “eval” server. It has only Docker and can access it only from Shoryuken , asynchronously.
In the first prototypes of Hexlet, the system required users to work on practical tasks on their computers, but now all the work is done in the browser, there is nothing to download and install. For this, we needed a browser-based development environment that would allow users to edit files and run programs. There are many cloud IDEs, and we, like any self-respecting startup, wanted to use ready-made solutions to the maximum. They found a cool IDE with a bunch of functions (even with integration with Git), but then they estimated the cost of maintaining someone else's code (complete invented bicycles) and decided to write their own simple IDE. Here we were saved by another new technology - ReactJS and the Flux concept. A couple of weeks ago a new version of Hexlet IDE was released with a bunch of functional and visual improvements.
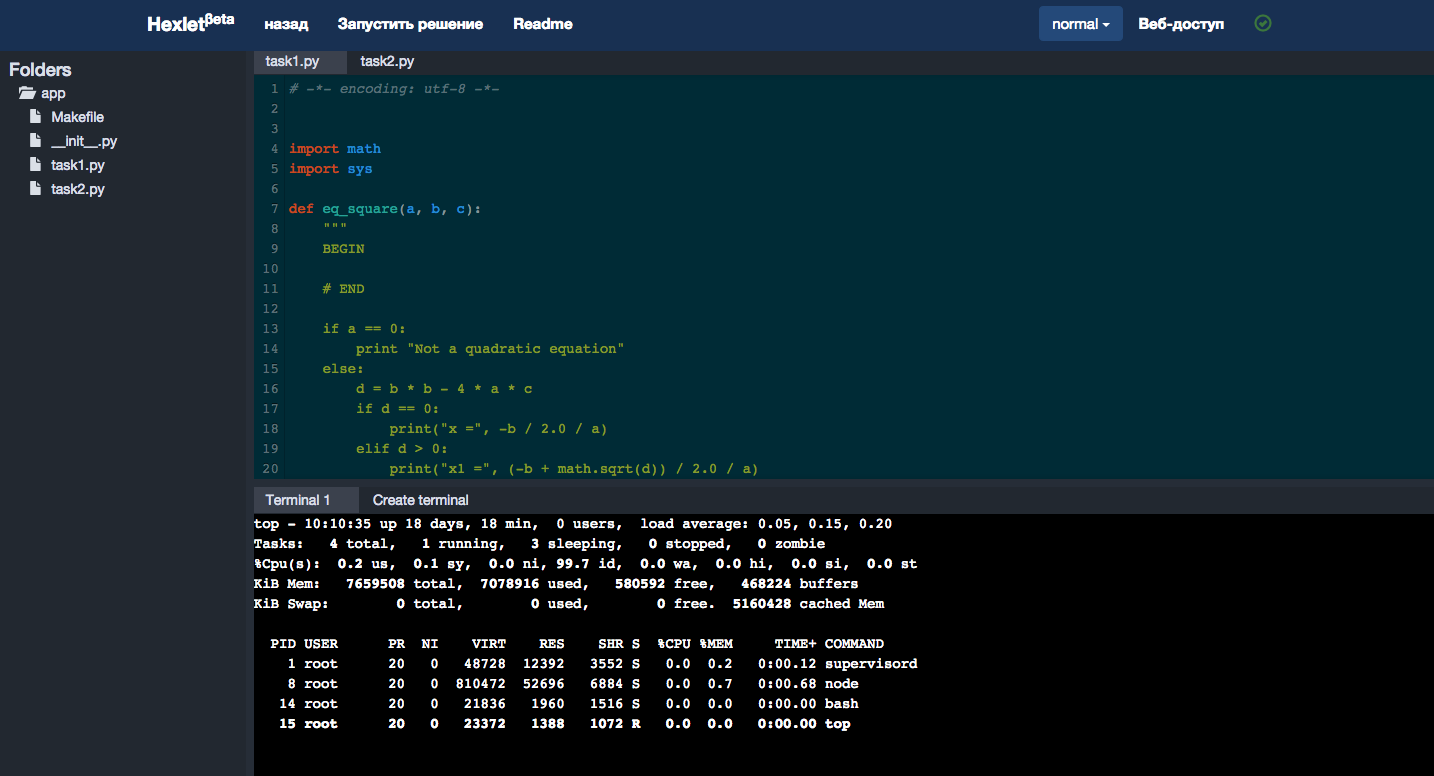
New version of Hexlet IDE in action.
In the first weeks, all the metrics (both system, such as the load on the machines, and business metrics, such as registration and payment) were sent to our database InfluxDB, and rendered graphs in Grafana. But now we are switching to third-party services, for example, Datadog . He is able to integrate with AWS, set up alerts when incidents occur.
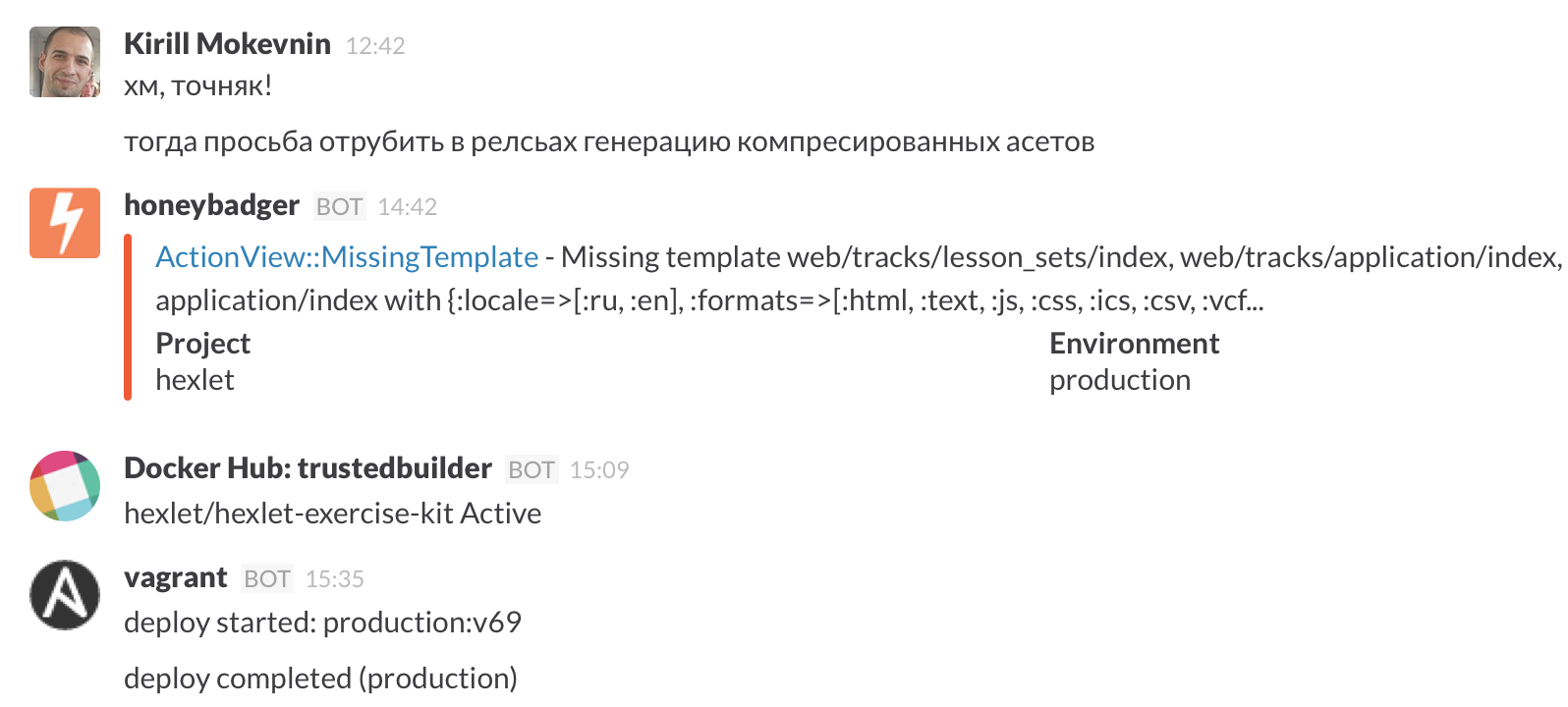
The whole team of Heksleta is sitting in Slack , there in the special #operations chat room we see everything that happens on the project: deployment, errors, builds, etc.
Our team itself creates lessons, and also invites authors from among professional developers. Any person or company can become authors of lessons, both public and for internal use, for example, for training within their development department or for workshops.
If you are interested in it, write to info@hexlet.io and join our group for authors on Facebook .
Thank!
In the last article I talked about the new version of the educational project Hekslet . In the voting, you decided that the next article will be about the technical implementation of the platform.
')
Let me remind you, Hekslet is a platform for creating practical lessons on programming in this development environment. By this development environment, we mean a complete machine connected to the network. This important detail distinguishes Hekslet from other educational projects (for example, Codecademy or CodeSchool) - we have no simulators, everything is for real. This allows you to train and learn not only programming, but also work with databases, servers, network, frameworks, and so on. In general, if it runs on a Unix machine, it can be trained in Hexlet. At the same time, knowing it or not, users use Test-Driven Development (TDD), because their solutions are checked by unit tests.
In this post I will talk about the architecture of the Hekslet platform and the tools we use. How to create practical lessons on this platform - in the next article.
Almost the whole backend is written in Rails. Everything works on Amazon Web Services (AWS). Initially, we tried not to get too attached to the AWS infrastructure, but gradually we began to use more of their services. In RDS (Relational Database Service), PostgreSQL (main base) and Redis rotate. Thanks to him, we can not worry about backups, replication, updating - everything works automatically. Also in RDS we use automatic failover - multiAZ. In the case of the fall of the main machine, a synchronous replica automatically rises in another availability zone, and within a couple of minutes the DNS record is bound to the new IP address.
SQS (Simple Queue Service) for building queues. All mail is sent through SES, domains live in Route53. Amazon Simple Notification Service (SNS) sends email delivery status messages to our SQS queue. Pictures and files are stored in S3. Recently we use Cloudfront, CDN from Amazon.
The cornerstone of the whole platform is Docker .
Each service works in our container. One container = one service. Most container images are ready-made images from tutum.co . We store the repository for your application in the Docker Registry . For staging, the image is compiled automatically when you commit to Dockerfile. The code itself is stored in Github. For production, we collect images via Ansible on a separate server. The build takes considerable time, 20-60 minutes, depending on the conditions, so the option “quickly fix production” is impossible. But it turned out not to be a problem, on the contrary - it disciplines. When something goes wrong with production delay for production, we just kill one container and the previous one. Our base grows only horizontally (which is typical for projects with, ahem, ahem, good architecture), which allows us to use the base with different versions of code and not get conflicts. Therefore, a rollback is almost always a simple version replacement code.
At first, for deployment, we use Capistrano, but eventually abandoned it in favor of Ansible. It’s a bit unusual, but Ansible just delivers configs to a remote server and starts upstart, which in turn updates the images. In this scheme, we do not need to install anything special on the server, for Ansible only ssh access is needed. Tags are used for versioning (v64, v65, and so on), and staging always uses the latest version of the latest code.
By the way, we love Ansible so much that we did a practical course on it - “Ansible: Introduction” .
A big plus - locally when developing we use almost identical Ansible playbooks as for production. So, the infrastructure is run around locally, as far as possible, which minimizes errors like “And it worked on LAN”. As a result, the deployment process looks like this: a new commit in the Dockerfile in the githaba -> launching a new build in the docker registry -> launching the Ansible playlist -> updated configs on the server -> running upstart -> getting new images.
We also use the Amazon balancer, and in the case of habraeffect we can raise additional machines in 10-20 minutes. An important condition of such a scheme is that the final web servers do not store state (stateless), no data is stored on them. This allows you to scale quickly.
We also love Amazon, about Route53 (domain management / DNS) and about the balancer, we have lessons in the “Distributed Systems” cycle .
Popular lesson page.
The essence of the project is to allow people to study in a real environment; for this, we raise a container for each user in which he performs a practical exercise. These containers are lifted on a special “eval” server. It has only Docker and can access it only from Shoryuken , asynchronously.
In the first prototypes of Hexlet, the system required users to work on practical tasks on their computers, but now all the work is done in the browser, there is nothing to download and install. For this, we needed a browser-based development environment that would allow users to edit files and run programs. There are many cloud IDEs, and we, like any self-respecting startup, wanted to use ready-made solutions to the maximum. They found a cool IDE with a bunch of functions (even with integration with Git), but then they estimated the cost of maintaining someone else's code (complete invented bicycles) and decided to write their own simple IDE. Here we were saved by another new technology - ReactJS and the Flux concept. A couple of weeks ago a new version of Hexlet IDE was released with a bunch of functional and visual improvements.
New version of Hexlet IDE in action.
In the first weeks, all the metrics (both system, such as the load on the machines, and business metrics, such as registration and payment) were sent to our database InfluxDB, and rendered graphs in Grafana. But now we are switching to third-party services, for example, Datadog . He is able to integrate with AWS, set up alerts when incidents occur.
The whole team of Heksleta is sitting in Slack , there in the special #operations chat room we see everything that happens on the project: deployment, errors, builds, etc.
Our team itself creates lessons, and also invites authors from among professional developers. Any person or company can become authors of lessons, both public and for internal use, for example, for training within their development department or for workshops.
If you are interested in it, write to info@hexlet.io and join our group for authors on Facebook .
Thank!
Source: https://habr.com/ru/post/254475/
All Articles