RapidMiner - Data Mining and BigData in your home, quickly and without preparation (almost)
So far, marketers are daubed with BigData and run in this form at press conferences, I suggest simply downloading a free tool with test datasets, process templates and start working.
Download, install and get the first results - 20 minutes maximum.
')
I’m talking about RapidMiner , an open-source environment that, for all its free of charge, doesn’t “do” commercial competitors. True, I’ll say right away that the developers still sell it, and only the penultimate versions give it to the open source. You can try at home because there are generally free assemblies with all-logic with only two restrictions - the maximum amount of memory used is 1 GB and work only with regular files (csv, xls, etc.) as a data source. Naturally, in a small business is also not a problem.
What you need to know about RapidMiner
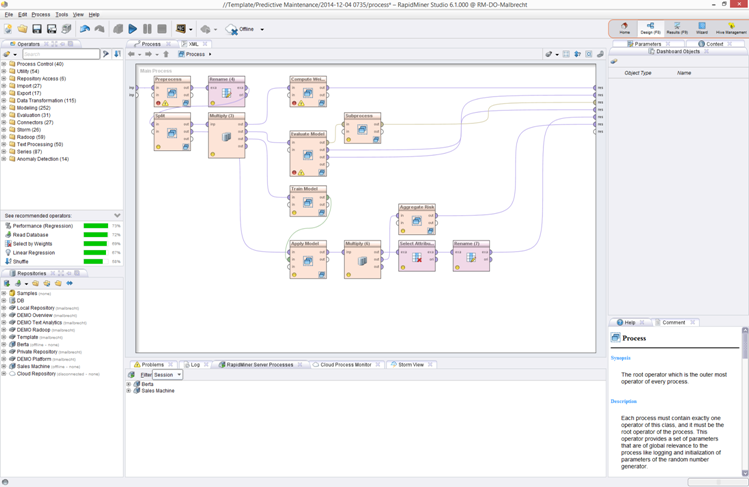
Here is the interface. You drop the data, and then simply drag the operators into the GUI, forming the data processing process. From you - just an understanding of what you are doing. All code takes on the environment. "Under the hood," you can, of course, climb, but in most cases it is just not necessary.
Important features
- Good GUI. In fact, each functional block is assembled into a cube. Nothing new in the approach, but very cool performance. Usually the difference between classic programming and visual beats heavily in functionality. For example, in SPSS Modeler there are only 50 nodes, and here there are as many as 250 in the base load.
- There are good data preparation tools. It is usually assumed that data is being prepared somewhere else, but there is already a ready-made ETL. In the same commercial SPSS, there are far fewer training opportunities.
- Extensibility There is a good old language R. The operators of the WEKA system are fully integrated. In general, this is not a "kindergarten" and not a closed framework. It will be necessary to go down to a low level - no problem.
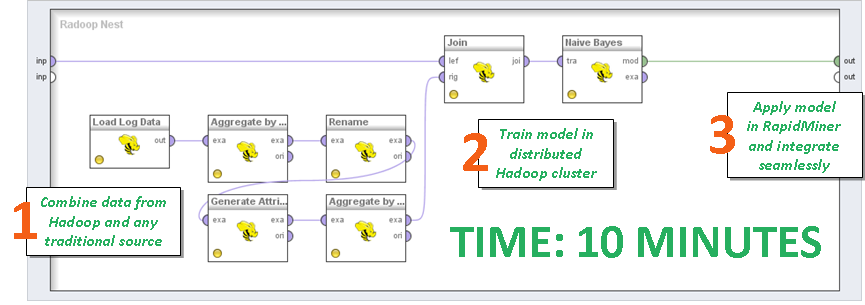
- He is friends with Hadoop (a separate paid extension with the straightforward name Radoop), and with both clean and commercial implementations. That is, when you decide to thresh not the XLS tablet with a demo data set, but the combat database, and even with the help of the modern Apache Spark, everything will immediately rise as it should. The most pleasant thing is that you do not need to write code. You can in the analyst miner write a script through the same GUI and give it to processing.
- Architecturally the data is outside . We set up the platform, load the data and start looking at where some correlations are, what we can predict. This is a plus and a minus, why - below.
- In addition to the IDE there is another server. Rapid Miner Studio creates processes, and you can publish them on the server. Something like a scheduler - the server knows which process to run, from which part, what to do, if something has fallen off somewhere, who is responsible for each of the processes, who needs to give resources to, where to unload the results. In general, all-all-all modern buns.
- And the server is also able to immediately build minimal reports. You can upload not in XLS, but draw graphics right there. This is popular with small companies and is convenient for small projects. And, of course, it is very inexpensive (even in the commercial version) compared to Modeller and SAS. But - immediately I say - they have different uses.
- Rapid development . Only serious noise arose around Apache Spark - in a couple of months there was a release about supporting basic functionality.
Minuses
- Money Since 2011, the penultimate version of the product goes into open source. With the release of the new one, the previous one becomes open source. Starter does not allow to build processes, processing of which will eat more gigabyte of RAM. Trial two weeks.
- The Gartner Company is not the biggest . This is bad for implementation and support, because they cannot do it on their own. On the other hand, all of this for big businesses according to company policy is given to integrators (that is, just us).
- The authority of the company has not yet been gained - there are not many implementations, young. No one has been fired for SAS, even if the budget is three times higher, but here the name is not known.
- Poor consulting, no formalized technical support processes . It is assumed that all this is done, again, by integrators. We are doing it, but from the point of view of big business one cannot but mention this feature.
- Not all things are analyzed on the server, in some cases the platform tries to aggregate data on the local machine . This is bad when the model requires the entire database, that is, when it is impossible to take and run the algorithm on a small piece of data. It is assumed that you use Hadoop or equivalent to solve this problem. Everything is there.
- Analytics of classical databases (what is not Big Data by the criterion of diversity) are one step behind the classical solutions. That is, if you want to make a pre-aggregation before unloading in-database, then you need to specify this explicitly with the handles, RapidMiner itself will not guess before.

RapidMiner vs IBM SPSS Modeler
RM has a much broader processing capabilities, trite more nodes. On the other hand, SPSS has “autopilot” modes. Auto-models (Auto Numeric, Auto Classifier) - go through several possible models with different parameters, choose some of the best. A not very experienced analyst can build on such an adequate model. It will almost certainly be inferior in accuracy built by an experienced specialist, but there is a fact - you can build a model without understanding this. RM has a counterpart (Loop and Deliver Best), but it still requires at least a choice of models and selection criteria for the best. Automatic data preprocessing (Auto Data Prep) is another well-known SPSS chip, a different way and a little more dreary implemented in RapidMiner.

In SPSS, data is collected by a single Automated Data Preparation node, ticked out what to do with the data. In RapidMiner - is assembled from atomic sites in an arbitrary sequence.
RapidMiner vs SAS
By the possibilities of “doing anything”, RM is higher, but, ultimately, with the help of some mother and some complications, you can get the same result in SAS. But here is a completely different approach - you have to relearn if you are used to SAS. SAS also provides many vertical solutions - banks, retail. The platform speaks to the user in his business language. RM is more abstract, it will have to articulate what is what.
RapidMiner vs Demantra
It’s not quite right to compare these two packages, but it’s important to illustrate how RM works. Oracle Demantra (and, very roughly, all similar products for a specific industry or task) is a complete package, tailored for specific procurement and supply tasks. There are specific operations there - they downloaded the sales data, received a forecast for the purchase of goods. One model, a lot of ready-made templates. Expensive, cool and big business.
On the other hand, in RM you can repeat the same thing, but half of the logic will have to be reinvented. This is very convenient for data scientists in terms of customization and flexibility of the final solution, but it is extremely difficult for business users - they simply will not see familiar words and tools.
Architecture

Tasks
So, we have a clear field for solving any problems. The most frequent in Russia, decided by such tools are:
- Analysis of transactions (for example, banking) to counter fraud.
- Client analytics . This is the hottest topic. The easiest and most advantageous way is to build a model of customer churn and flag those who are ready for this. For the telecom market, for example, the transfer of a subscriber to something else is a tragedy, because people are no longer becoming. Therefore, they are ready to pay real money for the “client can escape” checkbox.
- Personal recommendations . It loves retail - what to offer. Just the case when you just didn’t buy condoms , and you have already been remembered that in a few months you should give discounts on baby food.
- Forecasting shipments and sales . Given that there are ready-made packages for this, RapidMiner is stupidly cheaper. Do not buy Boeing, if you have a medium business. And do not buy the same JDA (it costs like two Boeing). No, everything is very cool there both by possibilities and by integration - but very few people can afford to buy it.
- Text analytics - what people write about. For example, the analysis of the emotional tint of reviews or comments in automatic mode. This is “50 complained about the connection in Volgograd along Victory Street”, “20 praised the service”, “The main reason for the discontent of subscribers is the frequent connection breaks” and so on.
- Often you need a ready-made integration at the level of the base and web services. In fact, there is no need to write anything, only the frequency of the survey is set, which model and process to use, and who the consumer is. For asynchronous or monthly reports, it is even easier; there are even pull-ups of data from Dropbox for a very small business and ready-made integration with Amazon services.
- Commercial RapidMiner works very well with big data . Exadata and Vertica - classic databases 2.0 or massively parallel DBMS - are supported "hard".

And this is my (and not only my) favorite topic - metamodeling. For those who are a little apart from this - different models often find different relationships, forming different results on the same sample. And they often make mistakes in different places too. And it needs to be used - to make an ensemble of models (Model Ensemble). For example, the Vote operator (vote) takes into account the “opinions” of all the models included in the ensemble and the result is given, the result with the most “votes”. Or one of the most popular among “advanced” data scientists the Bagging method (Bootstrap Aggregation) is to train several models on different subsamples of initial data with the subsequent averaging of their results.
Migration
What can I say from the experience of several transitions to RapidMiner: it is important to note that from the point of view of Data Science, the impressions are positive. Technologically, a little bit worse - data cleansing is more difficult, we have become accustomed to the paradigm and simplicity of SPSS and SAS. Here it was necessary to rebuild the brain more - everything is done very differently. Very different architectural implementations, so I immediately say that it will be quite difficult to migrate independently in terms of the competence of specialists. Need to learn again. But for us and customers the result was worth it.
A lot of nice small chips. For example, it makes sense to say about "macros" - these are the parameters of the process that can be used at any of its points. For example, as a macro, you can use the file name, the date of its creation, the average value of any data attribute, the best achieved accuracy, the iteration number, the last time the process started. Often helps out when creating non-trivial processing operations. For example, using a macro can be limited to the time of the operation, while the time threshold is not fixed, but is a calculated parameter - it depends on the size of the data, the time of day (nighttime optimizations can take longer).
From the recent - a model was built to predict passenger traffic. Here we have already used RM 100%, because built everything “from scratch” and there was nowhere to look around; there was no need to transfer existing processes and try to repeat them on another tool.
What to do to get started
Here is a link to download the collected release from the official site.
If you have little data - just use it until you get tired, the company is well aware that only medium and large business buys their full version. If there is not enough data, it will be important for you to know that prices are fixed, do not depend on the customer.
If you feel that the thing is cool, but you want to learn quickly - come to our training center . We are an official partner of RapidMiner, and certificates are issued on the basis of the courses. You will have basic knowledge of statistics (at least to understand what emissions are, average value, normal distribution and dispersion) and basic knowledge of a computer. We will give our datasets from one German telecom, if you do not have your own (or bring it in an impersonal form too) and collect the case for forecasting customer churn. And then we will model the model based on how much money there is to hold them. For example, there are 10 thousand rubles and 100,000 customers - you need to choose from them those who are cheaper to keep, and who will bring more money to the company in the future. Get into the most likely client and maximize the final benefit (by the way, this is called Uplift Modeling or, if you are more accustomed to SAS terminology, Incremental Response Modeling).
And once again: the Starter version is full-fledged in terms of analytical functionality, and, therefore, your company can make a proof-of-concept for your company absolutely free.
Source: https://habr.com/ru/post/254467/
All Articles