How to cross the border: cross-platform in a mobile application

Today, more and more applications are being created for several mobile platforms at once, and applications created initially for one platform are actively ported to others. Theoretically, you can completely write an application “from scratch” for each platform (that is, in fact, only the idea of the application is “cross-platform”). But this means that the labor costs for its development and development will grow in proportion to the number of supported platforms. If, on the other hand, multiplicity is initially incorporated into the application architecture, then these costs (plus, in particular, support costs) can be significantly reduced. You develop a common cross-platform code once - it means that you use it on current (and future) platforms. But in this case several interrelated questions arise immediately:
- Should there be a border between common (cross-platform) and native (platform-specific) code?
- If so, where and how to draw this boundary?
- How to make it so convenient to use the cross-platform code on all platforms, both on those that need to be supported now and on those whose support is likely to be needed in the future?
Of course, the answers to these questions depend on the specific application, the requirements placed on it and the restrictions imposed; therefore, a universal answer cannot be found. In this article, we will describe how we looked for our answers to these questions during the development of the Parallels Access mobile client for iOS and Android, which architectural decisions were made and what happened in the end.
I want to immediately warn you that there are many letters in this post, but I didn’t want to split the topic into pieces. Therefore, be patient.
Should there be a cross-platform border?
Today, there are many frameworks (for example, Xamarin, Cordova / PhoneGap, Titaniun, Qt, and others), which, in principle, allow you to write code once, and then compile it for different platforms and get applications with more (or depending on the capabilities of the framework, less) native for this platform UI and its “look-n-feel”.
')
But if it is important for you that the application is perceived and behaved in a manner familiar to users on this platform, then it should “play by the rules” established by the Human Interface Guidelines of this platform. And for the perception of “nativeness” of an application, “trifles” are extremely important for users - the type and behavior of the UI control elements, the type and timing of animation of transitions between UI elements, reactions to gestures, the location of the standard controls for this platform, etc. etc. If you write the application completely on one of the cross-platform frameworks, then the native behavior of your application will depend on how well it is implemented in this framework. And here, as is often the case, "the devil is in the details."
Where is the devil hiding in the framework?
1. In bugs. No matter how good the framework would be, unfortunately, there will inevitably be bugs in one way or another affecting the “look-n-feel” and behavior of the application.
2. In speed. The speed with which mobile platforms are developing and changing directly affects the native “look-n-feel” and the speed at which new “chips” appear on a given platform.
In any of these cases, you either become dependent on the speed of the output and the quality of the framework updates, or (if you have access to its sources) you will have to fix the bugs yourself or add the missing, but urgently needed features. We fully encountered these problems during the development of our other solution - Parallels Desktop for Mac, which widely uses the Qt library (at one time Parallels Desktop for Mac developed on a common code base with Parallels Workstation for Windows / Linux). At some point in time, we realized that the time and effort involved in finding problems related to bugs or implementation features in Qt of platform-specific code, fixing them, or searching for workarounds became too great.
When developing Parallels Access, we decided not to step on the same rake a second time, so we decided to use frameworks native to each platform for developing the UI.
Where and how to draw the line between cross-platform and native code?
So, we decided that the UI will be written natively, i.e. on Objective-C (later added Swift) for iOS and Java for Android. But besides the actual UI in Parallels Access, as well as, probably, in the absolute majority of applications, there is a rather large layer of “business logic”. In Parallels Access, he is responsible for such things as authorizing users, exchanging data with Parallels Access cloud infrastructure, organizing and, as necessary, restoring encrypted connections with remote user computers, receiving various data, as well as video and audio streams from a remote computer, sending commands for launching and activating applications, sending keyboard and mouse actions to a remote computer, and much more. Obviously, this logic does not depend on the platform, and is a natural candidate for a cross-platform “core” application.
The choice of writing a cross-platform “core” was simple for us: C ++ plus a subset of Qt modules (QtCore + QtNetwork + QtXml + QtConcurrent). Why all the same Qt? In fact, this library has long been much more than just a means for writing cross-platform UI. The Qt meta-object system provides many extremely convenient things. For example, to get "out of the box" means for thread-safe communication between objects using signals and slots, add dynamic properties to objects, and in a couple of lines of code organize a dynamic factory of objects on a line with the name of the class. In addition, it provides a very convenient cross-platform API for organizing and working with the event loop, streams, network and many others.
The second reason is historical. We did not want to refuse to use the Parallels Mobile SDK library, which was thoroughly tested and tested with C ++ / Qt, which was created during the development of several of our other products and which took several man-years of work.
How to make the cross-platform kernel convenient to use from Objective-C and Java?
How to use C ++ library from Objective-C and Java? The “head on” solution is to make Objective-C ++ wrappers on C ++ classes for use in Objective-C and JNI wrappers for use in Java. But with wrappers there is an obvious problem: if the API of the C ++ library is actively developed, then the wrappers will require constant updating. It is clear that keeping the wrappers up to date manually is a routine, unproductive and inevitably error-prone path. It would be reasonable to simply generate the wrappers and the necessary boiler plate code for calling methods in C ++ classes and accessing data. But again, the generator must either be written, or you can try to use ready-made (for example, SWIG could be used for Java. And with the generators, the probability remains that the wrapped C ++ API will not work too hard and you will need to dance with tambourines to generate correctly working wrapper.
How to eliminate such a problem on the vine, “by design”? To do this, we wondered what, in fact, is the communication between the “platform” code in Objective-C / Java and the cross-platform code in C ++? Globally, from “bird's-eye view” is a certain set of data (model objects, command parameters, notification parameters) and the exchange of this data between Objective-C / Java and C ++ according to a specific protocol.
How to describe data so that its presentation in C ++, Objective-C, Java would be guaranteed possible and mutually convertible? As a solution, it is suggested to use an even more basic language for describing data structures, and to generate from this description data types “native” for each of the three languages (C ++, Objective-C, Java). In addition to the generation of data types, it was important for us the possibility of their efficient serialization and deserialization into byte arrays (below we will tell you why). To solve such problems, there are a number of ready-made options, for example:
- Google Protocol Buffers which, in fact, have become “data language” in Google
- Apache Thrift , which was originally developed on Facebook, is donated to Open Source in 2007, and is now under the wing of Apache.
- Messagepack
- etc.
We chose Google Protocol Buffers, because at that time (2012), it was slightly superior to competitors in performance, more compactly serialized data, and, moreover, was well documented and supplied with examples.
An example of how the data in the .proto file is described:
message MouseEvent { optional sint32 x = 1; optional sint32 y = 2; optional sint32 z = 3; optional sint32 w = 4; repeated Button buttons = 5; enum Button { LEFT = 1; RIGHT = 2; MIDDLE = 4; } } The generated code, of course, will be much more complicated, since in addition to the usual getters and setters, it contains methods for serializing and deserializing data, auxiliary methods for determining the presence of fields in the protobuffer, methods for combining data from two protobuffers of the same type, etc. These methods will be useful to us in the future, but now it is important for us how the code using the cross-platform "core" and the code in the "core" itself can write and read data. And it looks very simple. Below, as an example, the code for writing (in Objective-C and Java) and reading data (in C ++) about a mouse event is shown - pressing the left mouse button at the point with coordinates (100, 100):
a) Creating and writing data to an object in Objective-C:
RCMouseEvent *mouseEvent = [[[[[RCMouseEvent builder] setX:100] setY:100] addButtons:RCMouseEvent_ButtonLeft] build]; int size = [mouseEvent serializedSize]; void *buffer = malloc(size); memcpy(buffer, [[mouseEvent data] bytes], size); b) Creating and writing data to an object in Java:
final MouseEvent mouseEvent = MouseEvent.newBuilder().setX(100).setY(100).addButtons(MouseEvent.Button.LEFT).build(); final byte[] buffer = mouseEvent.toByteArray(); c) reading data in C ++:
MouseEvent* mouseEvent = new MouseEvent(); mouseEvent->ParseFromArray(buffer, size); int32_t x = mouseEvent->x(); int32_t y = mouseEvent->y(); MouseEvent_Button button = mouseEvent->buttons().Get(0); But how to transfer data recorded in protobuffers to the C ++ library side and back, given that the code that sends requests (Objective-C / Java) to the cross-platform “core” and the code that directly processes them (C ++) live in different streams? Using standard synchronization methods for this requires constant attention to where and how synchronization primitives are used, otherwise it is easy to get a code with a non-optimal performance, dead lock or race that is difficult to detect with un-synchronized reading / writing of data. Is it possible to build a communication scheme between Objective-C / Java and C ++ so that this problem can be solved by “design”? Here we again wondered what, in fact, the types of communications we need:
• First, the API of our cross-platform “kernel” should provide methods for querying model objects (for example, get a list of all remote computers registered in this account).
• Secondly, the “kernel” API should provide the ability to subscribe to notifications about the addition, deletion and modification of properties of objects (for example, about changing the connection state with a remote computer or about the appearance of a new window of an application on a remote computer.)
• Third, the API must have methods for executing commands by the “kernel” itself (for example, establish a connection with this remote computer using the specified login credentials), and for sending commands to a remote computer (for example, to emulate keystrokes on the keyboard). on a remote computer when the user is typing on a mobile device). The result of the command may be changing the properties or deleting a model object (for example, if it was a command to close the last application window on a remote computer).
Those. we have only two characteristic communication patterns:
1. Request-response from Objective-C / Java in C ++ for requesting / receiving data and sending commands with an optional completion handler
2. Notification events from C ++ to Objective-C / Java
(NB: Processing of audio and video streams is implemented separately and is not covered in this article).
The implementation of these patterns fits well with the asynchronous message mechanism. But, as in the case of data description, we need an asynchronous queue mechanism that allows us to exchange messages between three languages (Objective-C, Java and C ++), and, moreover, easily integrates with the threads and event loops native to each platform. .
We did not reinvent the bicycle here, but used the ZeroMQ library. It provides an efficient transport for exchanging messages between so-called “nodes”, which can be threads within the same process, processes on one computer, processes on several computers connected to a network.
The use of zero-copy algorithms and a lock-free model for message exchange in this library makes it a convenient, efficient and scalable means for transferring data blocks between nodes. At the same time, depending on the location of the nodes, messages can be transmitted via shared memory (for threads within one process), IPC mechanisms, TCP sockets, etc., and this is transparent for code using the library: it is enough when creating "sockets" through which the "nodes" communicate, to set the "exchange medium" in one line, that's all. In addition to the “low-level” C ++ library libzmq, for ZeroMQ there are a number of high-level binding-s for a large number of languages, including C (czmq), Java (jeromq), C #, etc., which allow for more compact and efficient use of the patterns provided by ZeroMQ for organization communications between the "nodes". By configuring the exchange environment, we can, for example, create and transmit ZeroMQ messages from Java (using jeromq) and receive and read them in the native way on the C ++ side (using czmq).
ZeroMQ is a transport that implements the scheduling of messages between the “nodes” according to the configured communication pattern, but does not impose restrictions on the “payload”. It is here that the above-mentioned fact comes in handy that protobuffers are not only a means for a generalized description of data structures, but also a mechanism for efficient (both in time and in the required memory size) serialization and deserialization of data.
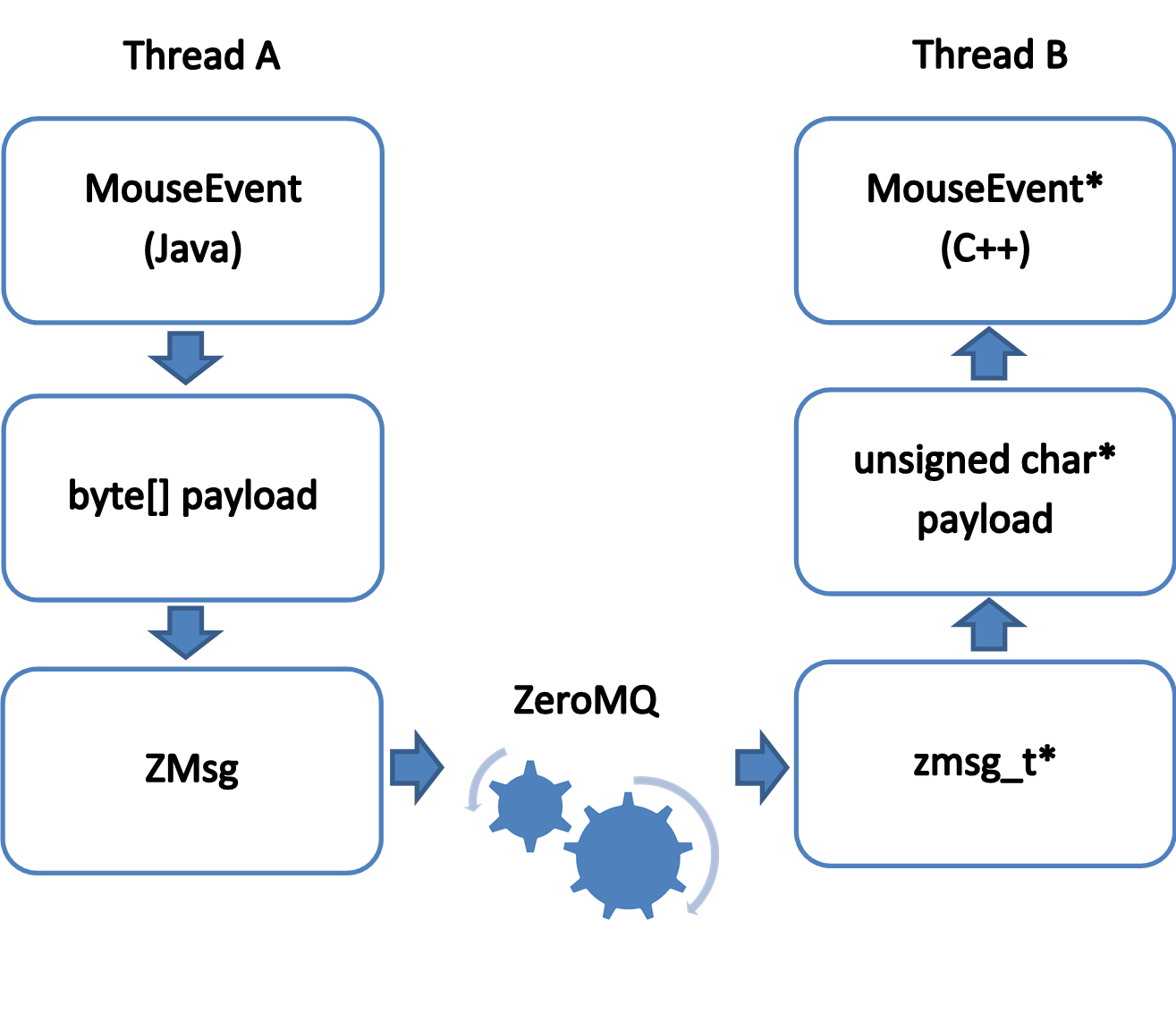
Thus, using the Google Protocol Buffers + ZeroMQ bundle, we obtained a language-independent means for describing data and a thread-safe means for exchanging data and commands between the “platform” and “cross-platform” code.
Using this bundle:
- Transparent to Objective-C, Java, and C ++ developers. Work with data and operations is carried out completely in the "native" language
- Frees the developers of the client UI-code from having to remember about synchronization when accessing data. A serialized and deserialized object is the essence of different objects, shared memory (under certain conditions) is needed only when transferred via ZeroMQ.
Conclusion
Summing up, we can say the following: first, when studying a task, you should always “rise” above it and see the overall picture of what is and what you want to get in the end - this sometimes helps to simplify the task. Secondly, you should not reinvent the wheel and undeservedly forget all that helped to work effectively in previous decisions.
And how did you write your cross-platform application - from scratch for each platform and immediately put into architecture? Let's discuss the pros and cons in the comments.
Source: https://habr.com/ru/post/254325/
All Articles