Assembler for simulation tasks. Part 2: core simulation
HCF, n. Mnemonic for 'Halt and Catch Fire', any of several undocumented and semi-mythical machine instructions with destructive side-effects <...>In a previous post, I began to talk about the areas of assembly application in the development of software models of computer simulators. I described the operation of the software decoder, and also speculated on the method of testing the simulator using unit tests.
Jargon file
This article will explain why the programmer needs knowledge about the structure of the machine code when creating an equally important component of the simulator - the kernel responsible for simulating individual instructions.
Until now, the discussion mainly concerned the assembler of the guest system. The time has come to talk about the assembler master.
With the assembler in the heart - the core of the simulator
A serious simulator product should have a multi-chamber “heart”: several ways to execute guest code. The most efficient of them is used at any given time.
In general, there are three technologies: interpretation, binary translation and direct execution. And in each of them there is a place for machine code and assembler.
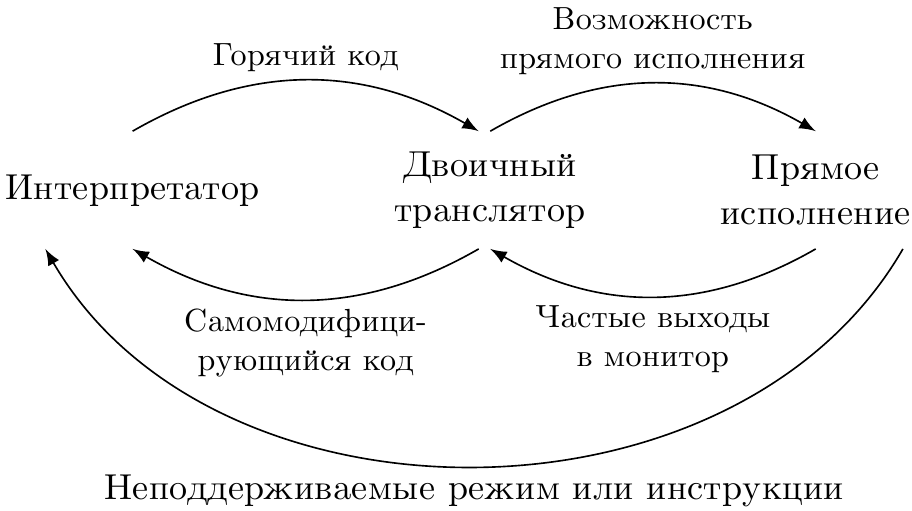
Interpreter and intrinsic
The simplest interpreter-based simulator is written in a portable high-level language. This means that each procedure describing a statement simply implements its logic in C.
A large proportion of machine instructions have fairly simple semantics, which is easily expressed in C: add two numbers, compare them with the third, shift left and right, and so on.
Privileged instructions are usually more difficult due to the need to perform various access checks and throwing exceptions. However, they are relatively few.
Difficulties appear further. There are instructions that work with numbers according to the IEEE 754 standard, i.e. floating point, "buoy". It will be necessary to correctly handle several formats of these numbers, from float16 through float32, float64, sometimes semi-standard float80 and even float82; no architecture seems to support float128 directly, although the standard describes them. Maintain non-NaN numbers, denormalized numbers, consider rounding modes and exception signaling. And also to realize all sorts of arithmetic, like sines, roots, inverse values.
Some help is the open-source Softfloat library, which implements quite a lot of the standard.
Another example of a class of instructions that are difficult to simulate is vector, SIMD. They perform one operation immediately on the vector of similar arguments. Firstly, they also often work with buoyers, although with integer operands too. Secondly, there are many such instructions due to the combinatorial effect: for each operation there are several vector lengths and element formats, mask formats, the optional use of “mixing” operations of broadcast, gather / scatter, etc.
Having successfully implemented the emulation procedures for all the required guest instructions, the creator of the model will most likely encounter an extremely low interpreter speed. And this is not surprising: what is done on a real machine in one instruction will be represented in the model as a procedure with a loop inside and nontrivial logic that calculates all the edge scenarios! Now, if something for us implemented the semantics of instructions, and did it quickly! ..
Wait a minute, but there must be exactly the same or at least very similar instructions in the host processor! Let not for everyone, but at least for the part. Moreover, popular compilers provide an interface for including machine instructions in the code - intrinsic (eng. Intrinsic - internal) - descriptions of functions that wrap machine instructions. Example description of intrinsics for LZCNT instruction from Intel SDM :
Intel C / C ++ Compiler Intrinsic Equivalent
LZCNT:
unsigned __int32 _lzcnt_u32 (unsigned __int32 src);
LZCNT:
unsigned __int64 _lzcnt_u64 (unsigned __int64 src);
These intrinsics also work in GCC. Below I did a little experiment:
$ cat lzcnt1.c #include <stdint.h> #include <immintrin.h> int main(int argc, char **argv) { int64_t src = argc; int64_t dst = _lzcnt_u64(src); return (int)dst; } $ gcc -O3 -mlzcnt lzcnt1.c # , .. LZCNT $ objdump -d a.out <......> Disassembly of section .text: 00000000004003c0 <main>: 4003c0: 48 63 c7 movslq %edi,%rax 4003c3: f3 48 0f bd c0 lzcnt %rax,%rax 4003c8: c3 retq 4003c9: 90 nop 4003ca: 90 nop 4003cb: 90 nop <......> ')
With the optimization flag
-O3 compiler did everything _lzcnt_u64() : from the “function” _lzcnt_u64() there is neither a prologue nor an epilogue, only one machine instruction, which we need.Like machine instructions, intrinsics are usually many (but still less than instructions). Each compiler provides its own set, something similar, somewhat different from the rest.
- Intrinsics present in Microsoft compilers are described in MSDN separately for x86 and x64 .
- Intel C / C ++ compiler intrusion documentation has been available for several years in a convenient, interactive format on a web page . It’s quite convenient to filter them by extension class (SSE2, SSE3, AVX, etc.) and by functionality (bit operations, logical, cryptographic, etc.), and also get help on semantics and speed of operation (in cycles).
- Intrinsics of the GCC compiler for IA-32 mostly coincide with those described for ICC.
- For Clang, I did not find any clear documentation on the available intrinsics for any architecture. If the reader has relevant information on this issue, then please share it in the comments.
Compared to handwritten sections of inline-assembler, intrinsics have the following advantages.
- Calling a function is much more familiar, it is easier to understand and less likely to bungle on it when writing. Intrinsics transfer work on the allocation of input and output registers to the compiler, and also allow it to carry out syntax checking, type consistency and other useful things and, if necessary, report problems. In the case of inline-code, assembler diagnostics will be much more mysterious. Those who often have to write out the clobber specifications for GNU as (and err in them) will agree with me.
- Intrinsics are not for the compiler "black boxes" of inline-assembler, in which unknown register and memory updates occur. Accordingly, its register allocation algorithms can take this into account when processing the procedure code. As a result, it is easier to get faster code.
- Intrinsics have, though weak, portability between compilers (but not master architectures). In the extreme case, you can write a prototype of your own implementation if the host architecture does not directly support the instruction. Example from practice: SSE2 instruction
CVTSI2SD xmm, r/m64does not have valid coding in 32-bit processor mode. Accordingly, there is no intrinsica, whereas in the 64-bit mode, for which a certain tool was originally developed, it was, and the code used it. When compiling code on a 32-bit host, an error was generated. Since the procedure tied to this intrinsic was not “hot” (the speed of the application depended weakly on it), its own implementation of_mm_cvtsi64_sd()on C was written, which was substituted for the 32-bit build.
For these or other reasons, Microsoft has discontinued support for inline assembly in MS Visual Studio 2010 and later for x64 architecture. In this case, only intrinsics are available for inserting machine code into C / C ++ files.
However, I would go against the truth, saying that using intrinsics is a panacea. Nevertheless, it is necessary to look after the code generated by the compiler, especially when you need to squeeze the maximum performance out of it.
Binary translator and code generation
The binary translator (hereinafter DT) usually works faster than the interpreter, because it converts entire blocks of the guest machine code into their equivalent blocks of the host machine code, which then, in the case of a hot code, are repeatedly launched. The interpreter (if it does not implement caching) is forced to process each encountered guest instruction from scratch, even if it has recently worked with it.
And, unlike the interpreter, which can be written from beginning to end, without delving into the particular architecture of the host, DT will require knowledge of both the assembler and encodings of machine instructions. When transferring your simulator to a new master system, a significant part of it, which is responsible for code generation, will have to be rewritten. This is the price of speed work.
In this article I will describe one of the easiest ways to build a so-called template translator . If there is interest, then some other time I will try to talk about a more advanced binary translation method.
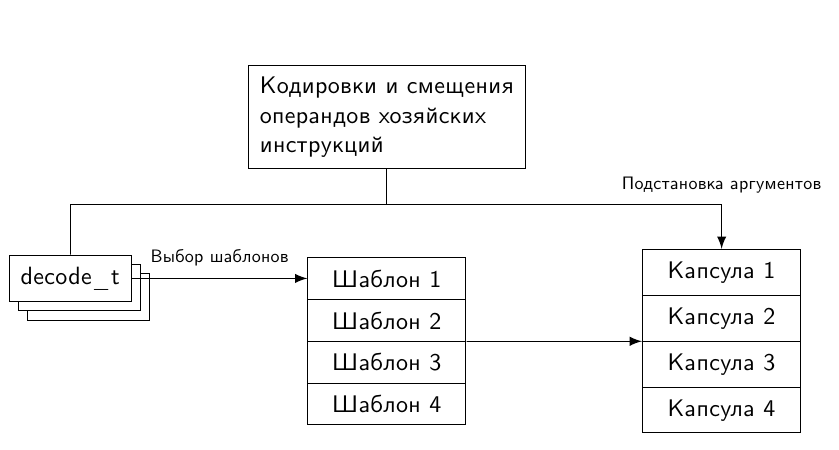
Having received from the decoder information about the guest instructions, DT generates for it a piece of machine code - a capsule . For several instructions executed sequentially, a translation block is created, consisting of their capsules recorded sequentially. As a result, when in the guest system control is transferred to the first translated instruction, to simulate this and subsequent commands, it is enough to execute the code from the translation block.
How to generate code for guest instructions, knowing its opcode and operand values? According to the opcode, the simulator selects a template — a master machine code preset that implements the desired semantics. From the procedures usually created by the compiler, it is distinguished by the lack of a prologue and an epilogue, since we directly “glue” such templates into a single translation block. However, this is still not enough to mark the broadcast unit as ready.
One more task remained unfulfilled - transfer the operand values as arguments to the pattern, thus specializing it and turning it into a capsule. Moreover, operands are most often transmitted at the broadcast stage: they are already known. That is, it is necessary to “sew” them directly into the master code of the capsule. With implicit operands (for example, values lying on the stack) this will not work, and they, of course, will have to be processed at the simulation stage, while wasting time.
If the dimension of the set (= number of combinations) of explicit operands is small, then they can be “sewn” into the group of patterns for this instruction — one for each combination. As a result, for each guest opcode, you will have to choose from N patterns according to what values the operands took in each specific case.
Unfortunately, not everything is so simple. In practice, it is often impossible to generate patterns for all possible values of operands due to a combinatorial explosion of their number. Thus, a three-operand instruction on an architecture with 32 registers will require 32 × 32 × 32 = 2¹⁵ blocks of code. And if the guest architecture has operands-literals (and all important ones have) 32 bits wide, then you have to store 2³² capsule options. Need to come up with something.
In fact, there is no need to keep a bunch of almost identical templates - they all contain the same host instructions. When variations of guest operands, they only change some host operands (but sometimes the length of the instruction, see my previous post ), describing where the simulated state is stored or which literal is passed. When forming a capsule from a template, it is necessary to “just” patch the bits or bytes at the corresponding offsets:

A question for connoisseurs: which architectures in the example above are used as guest and master?
Thus, for each guest instruction as part of a simulator with DT, one master machine code template and one procedure correcting the source operands for the correct ones are sufficient. Naturally, for the pattern to be patched correctly, it is necessary to know the displacements of all operands relative to its beginning, that is, to understand the coding of the commands of the host system. In fact, you must either implement your own encoder, or somehow learn to isolate the necessary information from the work of a third-party tool.
In general, the template translation process is presented in the following figure.
Direct execution and virtualization
The third simulation mechanism I consider is direct execution. The principle of its operation directly follows from the name - to simulate a guest code, launching it on the host without changes. Obviously, this method potentially gives the highest simulation speed; however, he is the most "capricious." The following requirements must be met.
- The architecture of the guest and the host must be the same. In other words, it will not be possible to directly model the code for ARM on MIPS and vice versa; In any case, it will not be a direct performance.
- The host architecture must meet the conditions for efficient virtualization .
Assume that the guest architecture meets the specified conditions, for example, this is Intel IA-32 / Intel 64 with Intel® VT-x extensions. The next task that arises when adding support for direct execution to the simulator is writing the kernel module (driver) of the operating system. You can't do without it: the simulator will need to execute privileged instructions and manipulate system resources, such as page tables, physical memory, interrupts, and so on. From the user space to them do not reach. On the other hand, completely “digging in” in the kernel is harmful: programming and debugging drivers is much more time-consuming and nerve-consuming than writing application programs. Therefore, only the very minimum of the functionality of a simulator, which is accessed through the interfaces of system calls, is usually carried into the kernel. All the virtual machines and simulators I know that use direct execution are arranged like this: a kernel module + a custom application that uses it.
Since the kernel module is written to a specific OS, you need to understand that when transferring an application to another OS, you will have to rewrite it, perhaps quite strongly. This is another reason to minimize its size.
In principle, the use of the assembler in the core is justified in about the same conditions as in the userland - that is, when not to do without it. Virtual machines work with system structures, such as VMCS (virtual machine control structure), control, debug, and model-specific registers, which are available only through specialized instructions. The most sensible thing would be to use intrinsics for them, but ...
Not all machine instructions have ready intrinsics. In compilers designed to build primarily user-defined code, drivers somehow forget about the needs of driver writers. For the appeal to them it is necessary to use the built-in (inline) assembler. In the source code of the KVM virtual machine, for example, there is such a definition for the function of reading VMCS fields:
#define ASM_VMX_VMREAD_RDX_RAX ".byte 0x0f, 0x78, 0xd0" static __always_inline unsigned long vmcs_readl(unsigned long field) { unsigned long value; asm volatile (__ex_clear(ASM_VMX_VMREAD_RDX_RAX, "%0") : "=a"(value) : "d"(field) : "cc"); return value; } To be honest, I expected to see here a VMREAD call on the vmread mnemonic, but for some reason its “raw” representation in the form of bytes is used. Perhaps, in this way, the authors wanted to support the build with compilers that are not aware of such an instruction.
By the way, an example with an intrinsic for LZCNT from the example above can be rewritten using the inline-assembler format in the following form. The machine code in this simple case is generated the same.
#include <stdint.h> int main(int argc, char **argv) { int64_t src = argc; int64_t dst; __asm__ volatile( "lzcnt %1, %0\n" :"=r"(dst) :"r"(src) :"cc" ); return (int)dst; } Although initially I planned to describe in this article in detail the features of the GNU-inline format of the assembler, I decided not to do this, because There is a lot of information on this topic on the Internet. If there is a need, I can do it in my next article.
It happens that it is more profitable to assemble the entire assembler in one file than to try to fit it among the C code. I did not find examples for KVM, but they were for Xen . I note that in this file the assembler itself is no more than a quarter in volume, the rest is preprocessor directives and comments documenting what this code does and what its interface is.
Results
Assembly language plays a key role in the development of simulation solutions. It is used in various components of models, as well as in the process of their testing.
The assembler code itself in a complex project that also uses high-level languages can be represented in three ways.
- Intrinsiki - wrappers for individual machine instructions with the interface of ordinary functions C / C ++.
- Assembler inserts — fragments of assembler code specific to the selected compiler / assembler, consistent with the high-level code surrounding them.
- Files written entirely in assembly language are used in those (rare) cases where it is more convenient to express a certain sequence of actions entirely in assembly language. They interact with the outside world either through the interface of functions (independently implementing the ABI of the platform for which they are intended) or without any interaction (in the case of independent unit tests).
Source: https://habr.com/ru/post/254027/
All Articles