DotHill 4824 storage overview
The hero of this review will be the modest DotHill 4824 storage system. Surely many of you have heard that DotHill as an OEM partner is producing entry-level storage for Hewlett-Packard — the most popular HP MSA (Modular Storage Array) already existing in the fourth generation. The DotHill 4004 line corresponds to the HP MSA2040 with a few differences, which will be described in detail below.
DotHill is a classic entry level storage system. Form factor, 2U, two options for different drives and with a large variety of host interfaces. Mirrored cache, two controllers, asymmetric active-active with ALUA. Last year, a new functionality was added: disk pools with three-level tiering (tier data storage) and SSD cache.

')
For those who are not familiar with the theory, it is worthwhile to talk about the principles of operation of disk pools and longline storage. More precisely, about specific implementation in DotHill.
Before the advent of pools, we had two limitations:
A disk pool in a DotHill storage system is a collection of several disk groups with load distribution between them. From the point of view of performance, the pool can be considered as a RAID-0 of several subarrays, i.e. we are already solving the problem of short disk groups. In total, only two disk pools are supported on the storage system, A and B, one for the controller), each pool can have up to 16 disk groups. The main architectural difference is the maximum use of free placement of stripe on disks. Several features and features are based on this feature:
Connection was made through one controller, direct, through 4 8Gbps FC ports. Naturally, the mapping of volumes to the host was through 4 ports, and multipath was configured on the host.
This test is a three-hour (180 cycles of 60 seconds) load with random access by 8KiB blocks (8 threads with a queue depth of 16 each) with a different read / write ratio. The entire load is focused on the 0-20GB area, which is guaranteed to be less than the amount of performance tier or cache on an SSD (800GB) - this is done to quickly fill the cache or tier in a reasonable time.
Before each test run, the volume was created anew (to clear the SSD-tier or SSD cache), was filled with random data (sequential write in 1MiB blocks), the volume was not read ahead. The values of IOPS, average and maximum delay were determined within each 60-second cycle.
Tests with 100% reading and 65/35 reading + writing were performed both with SSD-tier (a disk group of 4x400GB SSD in RAID-10 was added to the pool) and with SSD cache (2x400GB of SSD in RAID-0, storage does not allow adding more than two SSDs to the cache for each pool). The volume was created on a pool of two RAID-6 disk groups of 10 46-GB disks of 15 thousand SPS rpm (that is, in fact, this is RAID-60 according to the 2x10 scheme). Why not 10 or 50? To intentionally complicate random storage for storage systems.
The results were quite predictable. As the vendor claims, the advantage of SSD cache over SSD tier is in filling the cache faster, i.e. DSS reacts faster to the appearance of “hot” areas with an intense load on random access: 100% reading IOPS grow together with a drop in delay faster than using tier'ing.
This advantage ends as soon as a significant write load is added. RAID-60, to put it mildly, is not very suitable for random recording in small blocks, but this configuration was chosen specifically to show the essence of the problem: DSS cannot cope with the recording, because it bypasses the cache for a slow RAID-60, the queue is quickly clogged, there is little time to service read requests, even taking into account caching. Some blocks get there all the same, but quickly become invalid, because there is a record. This vicious circle leads to the fact that with such a load profile, the cache that works only on reading becomes ineffective. Exactly the same situation could be observed with the early versions of the SSD cache (before the appearance of Write-Back) in PCI-E RAID controllers LSI and Adaptec. The solution is to use an initially more productive volume, i.e. RAID-10 instead of 5/6/50/60 and / or SSD-tier instead of cache.
This graph uses a logarithmic scale. In case of 100% SSD cache usage, you can see a more stable delay value - after filling the cache, the peak values do not exceed 20ms.

What can be summed up in the dilemma of "caching versus long-term storage (tiering)"?
What to choose?
The volume was tested on a linear disk group - RAID-10 out of four 400GB SSDs. In this delivery of DotHill, HGST HUSML4040ASS600 turned out to be abstract “400GB SFF SAS SSD”. This is an Ultrastar SSD400M SSD with a fairly high declared performance (56000/24000 IOPS 4KiB read / write), and most importantly - a resource of 10 overwrites per day for 5 years. Of course, now in the arsenal of HGST there are more productive SSD800MM and SSD1600MM, but for DotHill 4004 there is quite enough of these.
We used tests designed for single SSDs - “IOPS Test” and “Latency Test” from the SNIA Solid State Storage Performance Test Specification Enterprise v1.1:
The test consists of a series of measurements - 25 rounds of 60 seconds. Preload - sequential recording in blocks of 128KiB until reaching 2x capacity. The steady state window (4 rounds) is checked by plotting. Criteria of steady state: linear approximation within the window should not exceed the limits of 90% / 110% of the average value.

As expected, the stated limit of the performance of a single small block IOPS controller was achieved. For some reason, DotHill indicates 100000 IOPS for reading, and HP for MSA2040 - more realistic 80000 IOPS (40 thousand per controller), which we see on the graph.
For the test, a single HGST HGST HUSML4040ASS600 SSD was tested with a SAS HBA. On the 4KiB block, about 50 thousand IOPS were received for reading and writing, with saturation (SNIA PTS Write Saturation Test) the record was dropped to 25-26 thousand IOPS, which corresponds to the characteristics stated by HGST.
Average delay (ms):
Maximum delay (ms):
The average and peak delay values are only 20-30% higher than those for a single SSD when connected to the SAS HBA.
Of course, the article turned out to be somewhat chaotic and does not answer the several important questions:
DotHill is a classic entry level storage system. Form factor, 2U, two options for different drives and with a large variety of host interfaces. Mirrored cache, two controllers, asymmetric active-active with ALUA. Last year, a new functionality was added: disk pools with three-level tiering (tier data storage) and SSD cache.
Specifications
- Form factor: 2U 24x 2.5 "or 12x 3.5"
- Interfaces (per controller): 4524C / 4534C - 4x SAS3 SFF-8644, 4824C / 4834C - 4x FC 8 Gbit / s / 4x FC 16 Gbit / s / 4x iSCSI 10 Gbit / s SFP + (depending on the used transceivers)
- Scaling: 192 2.5 "disks or 96 3.5" disks, supports up to 7 additional disk shelves
- RAID support: 0, 1, 3, 5, 6, 10, 50
- Cache (per controller): 4GB with flash protection
- Functionality: snapshots, volume cloning, asynchronous replication (except SAS), thin provisioning, SSD cache, 3-level tiering (SSD, 10 / 15k HDD, 7.2k HDD)
- Configuration limits: 32 arrays (vDisk), up to 256 volumes per array, 1024 volumes per system
- Management: CLI, Web-interface, SMI-S support
')
Disk pools in DotHill
For those who are not familiar with the theory, it is worthwhile to talk about the principles of operation of disk pools and longline storage. More precisely, about specific implementation in DotHill.
Before the advent of pools, we had two limitations:
- The maximum size of the disk group. RAID 10, 5 and 6 can have a maximum of 16 drives. RAID-50 - up to 32 drives. If you need a volume with a large number of spindles (for the sake of performance and / or volume), then you had to combine LUNs on the host side.
- Non-optimal use of fast drives. You can create a large number of disk groups for several load profiles, but with a large number of hosts and services on them, constantly monitor performance, volume and periodically make changes becomes difficult.
A disk pool in a DotHill storage system is a collection of several disk groups with load distribution between them. From the point of view of performance, the pool can be considered as a RAID-0 of several subarrays, i.e. we are already solving the problem of short disk groups. In total, only two disk pools are supported on the storage system, A and B, one for the controller), each pool can have up to 16 disk groups. The main architectural difference is the maximum use of free placement of stripe on disks. Several features and features are based on this feature:
- Thin Provisioning (thin allocation of resources). The technology is not new, even those who have not seen a single storage system have seen it, for example, in desktop hypervisors. On top of the pool or a regular linear disk group, volumes are created, which are then presented to the hosts. Disk space under the “thin” volume is not reserved immediately, but only as it is filled with data. This allows you to pre-allocate the necessary disk space, taking into account growth forecasts and allocate more space than it actually is. In the future, either expanding the system will not be necessary at all (not all volumes will actually use the allocated volume), or we will be able to add the required number of disks without resorting to complex manipulations (data transfer, an increase in LUNs and file systems on them, etc. ). If you are afraid of a possible situation with a lack of capacity, you can disable over-provisioning in the pool settings, and allocate more disk space than is available, it will not work.
When using Thin Provisioning, it is important to ensure a reverse process — returning unused disk space back to the pool (space reclamation). When deleting a storage file, it will not be able to learn about the release of the corresponding blocks, unless additional steps are taken. Once, storage systems with space reclamation support could only rely on periodic zeros from the host (for example, using SDelete), but now almost all (and, of course, DotHill) support the SCSI UNMAP command (similar to the well-known TRIM in the ATA command set ). - The ability to transparently add and remove pool elements . In traditional RAID arrays, it is often possible to expand the array by adding disks, but most disk pool implementations, including those from DotHill, allow you to add or remove a disk group without losing data. Blocks from this group will be redistributed to the remaining groups in the pool. Naturally, provided there are enough free blocks.
- Tiering (tiered data storage). Instead of distributing volumes with different performance requirements across different disk groups, you can combine volumes on disks with different capacities into a common pool and rely on automatic block migration between three tiers with different capacities. The criterion for migration is the load intensity with random access. More often requested blocks “float up”, rarely used “settle” on slow disks.
There are three fixed tiers in the DotHill storage system: Archive (archived, 7200 rpm disks), Standard (standard, “real” SAS disks 10/15 thousand rpm) and Performance (productive, SSD). In this regard, there is a chance to get an incorrectly working configuration, consisting, for example, of a dozen 7200 disks and a pair of 15k disks. DotHill will consider a mirror from a pair of 15k-disks as more productive and transfer “hot” data to it.
When planning a configuration with tiering, you should take into account that you will always get a performance boost with some delay - the system needs time to move the blocks to the desired tier. The second point is the primitiveness of organizing tiering in DotHill 4004, i.e. the inability to assign volumes to priorities. There are no complicated structures with profiles and tier affinity , as in DataCore or some midrange class storage systems, there is no entry level storage system. Want guaranteed performance immediately and always? Use regular disk groups. Another alternative to tiering in DotHill is SSD cache, the details of which will be implemented below.
DotHill 4004 has a simple and visual tool for analyzing pool utilization efficiency: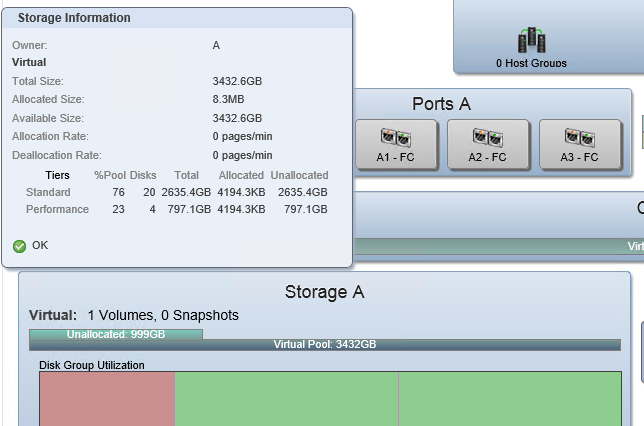
This is a screenshot from the Pools tab of the new Storage Management Console (SMC) v3 web interface (this is called SMU for HP). You can see a pool consisting of two tiers: Standard (2 disk groups) and Performance. You can immediately understand how the data is distributed in the pool, and how much space is allocated on each tier: one volume has just been created and it is not filled with real data, so only 8 with a small MB are actually allocated.
The second screenshot, performance:
Currently running load test after pre-filling the volume. We can see how much each layer in the pool gives in IOPS and throughput. The space for new units initially stands out on the Standard tier, and here the migration process on the Performance tier is already visible under the influence of the load.
Differences from HP MSA2040
- MSA 2040 is an HP product , with all the consequences and benefits. First of all - an extensive network of service centers and the ability to purchase various packages of extended support. Only the distributors and their partners are engaged in the Russian-language support and maintenance of DotHill. All that remains is the optional 8x5 support with the next business day response and the delivery of spare parts the next business day.
Documentation is completely identical to HP's, with the exception of names and logos, i.e. equally high quality and detailed. Of course, HP has many additional FAQs, best practices, descriptions of reference architectures involving MSA2040. The HP web interface (HP SMU) differs only in a company font and icons.
Price Of course, nothing is given in vain. The price for MSA2040 in common configurations (two controllers, 24 450-600GB 10k disks, 8Gbit FC transceivers) is about 30% higher than the DotHill 4004. Of course, without CarePacks. Also excluding HP's separately expanding number of snapshots (from 64 to 512) and asynchronous replication (Remote Snap), which add several thousand USD to the cost of the solution. Our statistics show that additional CarePacks for MSA in the territory of the Russian Federation are extremely rarely bought, after all, this is a budget segment. The implementation in most cases is carried out on its own, sometimes it is carried out by the supplier within the framework of a common project, extremely rarely by HP engineers. - Discs . DotHill and HP have “their own”, that is, HDD and SSD with non-standard firmware are used, the slide comes with disks. DotHill offers only nearline SAS from 3.5 "disks, i.e., with a spindle speed of 7200 rpm, i.e.
all fast disks - only 2.5"*. HP offers 300, 450 and 600GB 15,000 rpm disks in a 3.5 "version.
* Update 03/25/2015: 10k and 15k disks in the 3.5 "version of DotHill are still available on request. - Related products . HP MSA 1040 is a budget version of MSA 2040 with certain limitations:
- No SSD support. Optional auto-tiering is still there, it's just 2-level.
- Smaller host ports - 2 per controller instead of 4. There is no support for 16Gbps FC and SAS.
- Fewer disks - only 3 additional disk shelves instead of 7.
So if you do not need all the features of MSA 2040, then you can save about 20% and get very close to the cost of the "original" (but full-featured).
DotHill has another variation - the AssuredSAN Ultra series. These are storage systems with exactly the same controllers, functionality and control interface as the 4004 series, but with a high disk density: Ultra48 - 48x 2.5 "in 2U and Ultra56 - 56x 3.5" in 4U.

Performance
Storage configuration
- DotHill 4824 (2U, 24x2.5 ")
- Firmware Version: GL200R007 (last at the time of testing)
- RealTier 2.0 Activated License
- Two controllers with CNC ports (FC / 10GbE), 4 8Gbit FC transceivers (installed in the first controller)
- 20x 146GB 15 thousand rpm SAS HDD (Seagate ST9146852SS)
- 4x 400GB SSD (HGST HUSML4040ASS600)
Host configuration
- Platform Supermicro 1027R-WC1R
- 2x Intel Xeon E5-2620v2
- 8x 8GB DDR3 1600MHz ECC RDIMM
- 480GB SSD Kingston E50
- 2x Qlogic QLE2562 (2-port 8Gbps FC HBA)
- CentOS 7, fio 2.1.14
Connection was made through one controller, direct, through 4 8Gbps FC ports. Naturally, the mapping of volumes to the host was through 4 ports, and multipath was configured on the host.
Pool with tier-1 and SSD cache
This test is a three-hour (180 cycles of 60 seconds) load with random access by 8KiB blocks (8 threads with a queue depth of 16 each) with a different read / write ratio. The entire load is focused on the 0-20GB area, which is guaranteed to be less than the amount of performance tier or cache on an SSD (800GB) - this is done to quickly fill the cache or tier in a reasonable time.
Before each test run, the volume was created anew (to clear the SSD-tier or SSD cache), was filled with random data (sequential write in 1MiB blocks), the volume was not read ahead. The values of IOPS, average and maximum delay were determined within each 60-second cycle.
Tests with 100% reading and 65/35 reading + writing were performed both with SSD-tier (a disk group of 4x400GB SSD in RAID-10 was added to the pool) and with SSD cache (2x400GB of SSD in RAID-0, storage does not allow adding more than two SSDs to the cache for each pool). The volume was created on a pool of two RAID-6 disk groups of 10 46-GB disks of 15 thousand SPS rpm (that is, in fact, this is RAID-60 according to the 2x10 scheme). Why not 10 or 50? To intentionally complicate random storage for storage systems.
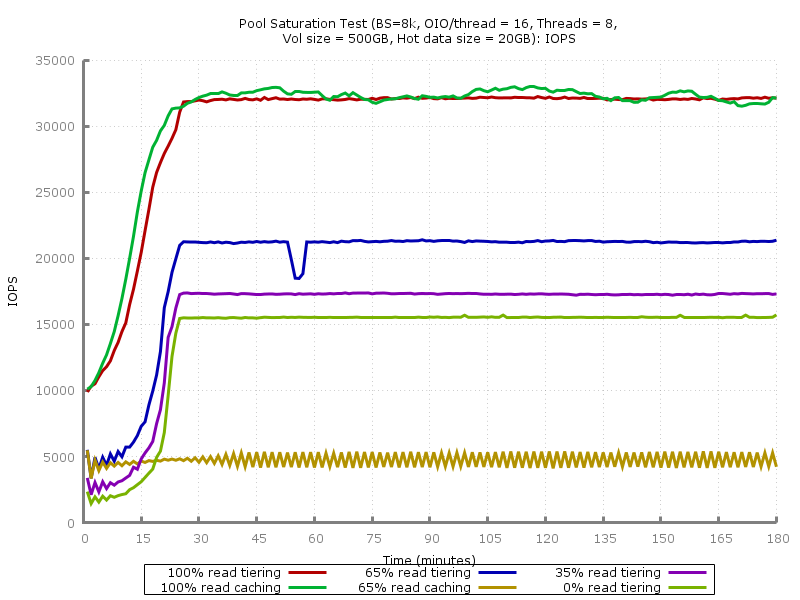
Iops
The results were quite predictable. As the vendor claims, the advantage of SSD cache over SSD tier is in filling the cache faster, i.e. DSS reacts faster to the appearance of “hot” areas with an intense load on random access: 100% reading IOPS grow together with a drop in delay faster than using tier'ing.
This advantage ends as soon as a significant write load is added. RAID-60, to put it mildly, is not very suitable for random recording in small blocks, but this configuration was chosen specifically to show the essence of the problem: DSS cannot cope with the recording, because it bypasses the cache for a slow RAID-60, the queue is quickly clogged, there is little time to service read requests, even taking into account caching. Some blocks get there all the same, but quickly become invalid, because there is a record. This vicious circle leads to the fact that with such a load profile, the cache that works only on reading becomes ineffective. Exactly the same situation could be observed with the early versions of the SSD cache (before the appearance of Write-Back) in PCI-E RAID controllers LSI and Adaptec. The solution is to use an initially more productive volume, i.e. RAID-10 instead of 5/6/50/60 and / or SSD-tier instead of cache.
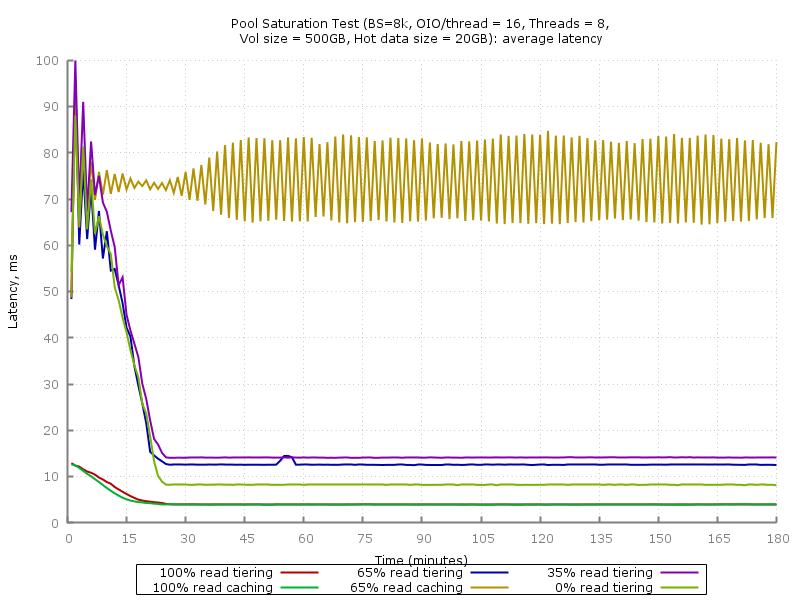
Average delay
Maximum delay
This graph uses a logarithmic scale. In case of 100% SSD cache usage, you can see a more stable delay value - after filling the cache, the peak values do not exceed 20ms.
What can be summed up in the dilemma of "caching versus long-term storage (tiering)"?
What to choose?
- Filling cache is faster. If your load consists of primary random reading and at the same time the area of "hot" periodically changes, then you should choose a cache.
- Saving "fast" volume. If the “hot” data fits entirely in the cache, but not in the SSD-tier, then the cache may be more efficient. The SSD cache in DotHill 4004 is read-only, so a RAID-0 disk group is created for it. For example, with 4 SSDs of 400GB, you can get 800GB of cache for each of the two pools (1600GB total) or 2 times less with tiering (800GB for one pool or 400GB for two). Of course, there is another option 1200GB in RAID-5 for one pool, if the second does not need SSD.
On the other hand, the total net pool size when using tiering will be greater due to the storage of only one copy of the blocks. - The cache does not affect the performance of sequential access. When caching does not move blocks, only copying. With a suitable load profile (random reading in small blocks with repeated access to the same LBA), the DSS issues data from the SSD cache, if they are there, or from the HDD and copies them to the cache. When a load with sequential access appears, the data will be read from the HDD. Example: a pool of 20 10 or 15k HDD can give about 2000MB / s for sequential reading, but if the required data is on a disk group from a pair of SSDs, we will get about 800MB / s. Whether it is critical or not depends on the actual storage usage scenario.
4x SSD 400GB HGST HUSML4040ASS600 RAID-10
The volume was tested on a linear disk group - RAID-10 out of four 400GB SSDs. In this delivery of DotHill, HGST HUSML4040ASS600 turned out to be abstract “400GB SFF SAS SSD”. This is an Ultrastar SSD400M SSD with a fairly high declared performance (56000/24000 IOPS 4KiB read / write), and most importantly - a resource of 10 overwrites per day for 5 years. Of course, now in the arsenal of HGST there are more productive SSD800MM and SSD1600MM, but for DotHill 4004 there is quite enough of these.
We used tests designed for single SSDs - “IOPS Test” and “Latency Test” from the SNIA Solid State Storage Performance Test Specification Enterprise v1.1:
- IOPS Test . The number of IOPS (I / O operations per second) is measured for blocks of various sizes (1024KiB, 128KiB, 64KiB, 32KiB, 16KiB, 8KiB, 4KiB) and random access with different read / write ratio (100/0, 95/5, 65/35, 50/50, 35/65, 5/95, 0/100). 8 threads were used with a queue depth of 16.
- Latency Test . The average and maximum delay values are measured for different block sizes (8KiB, 4KiB) and read / write ratios (100/0, 65/35, 0/100) at the minimum queue depth (1 flow with QD = 1).
The test consists of a series of measurements - 25 rounds of 60 seconds. Preload - sequential recording in blocks of 128KiB until reaching 2x capacity. The steady state window (4 rounds) is checked by plotting. Criteria of steady state: linear approximation within the window should not exceed the limits of 90% / 110% of the average value.
SNIA PTS: IOPS test
As expected, the stated limit of the performance of a single small block IOPS controller was achieved. For some reason, DotHill indicates 100000 IOPS for reading, and HP for MSA2040 - more realistic 80000 IOPS (40 thousand per controller), which we see on the graph.
For the test, a single HGST HGST HUSML4040ASS600 SSD was tested with a SAS HBA. On the 4KiB block, about 50 thousand IOPS were received for reading and writing, with saturation (SNIA PTS Write Saturation Test) the record was dropped to 25-26 thousand IOPS, which corresponds to the characteristics stated by HGST.
SNIA PTS: Latency Test
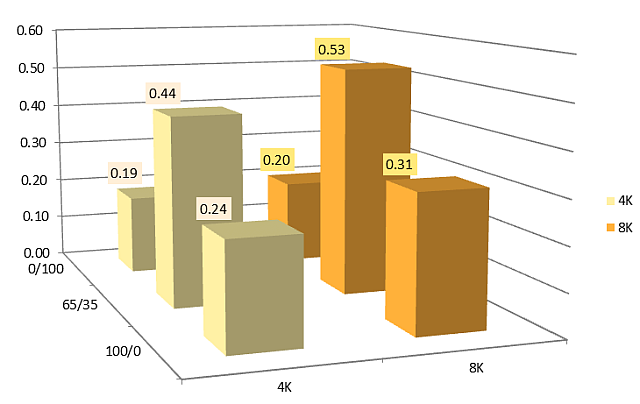
Average delay (ms):
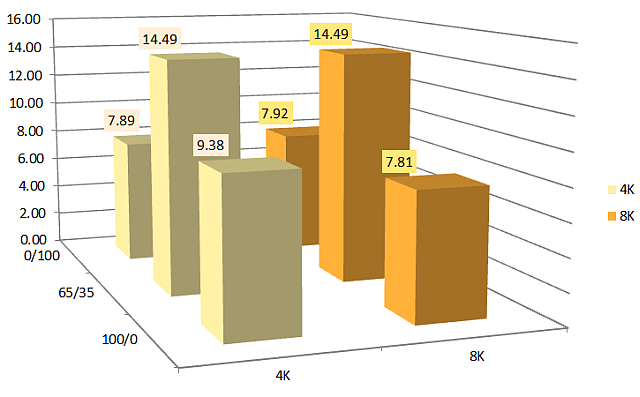
Maximum delay (ms):
The average and peak delay values are only 20-30% higher than those for a single SSD when connected to the SAS HBA.
Conclusion
Of course, the article turned out to be somewhat chaotic and does not answer the several important questions:
- Comparison in a similar configuration with products of other vendors: IBM v3700, Dell PV MD3 (and other descendants of LSI CTS2600), Infrotrend ESDS 3000, etc. The storage systems come to us in different configurations and, as a rule, not for long - you need to load and / or to introduce.
- The storage bandwidth limit has not been tested. We managed to see about 2100MB / s (RAID-50 from 20 disks), but I didn’t test the sequential load due to insufficient number of disks. I am sure that the claimed 3200/2650 MB / s for reading / writing would be possible to get.
- There is no useful, in many cases, IOPS vs latency graphics, where by varying the queue depth you can see how much IOPS can be obtained with an acceptable delay value. Alas, not enough time.
- Best Practices. I did not want to reinvent the wheel, as there is a good document for HP MSA 2040 . To it you can add only recommendations for the proper use of disk pools (see above).
Links
Source: https://habr.com/ru/post/253907/
All Articles