How to deal with OutOfMemoryError in practice, or oh, these databases
Greetings, Habr!
In this article I will try to chew on what to do with dumps in Java, how to understand the reason or get closer to the cause of OOM, look at the tools for analyzing dumps, the tool (one, yes) for monitoring the hip, and in general go into this matter for common development . Such tools as JVisualVM (I will consider some plug-ins to it and OQL Console), Eclipse Memory Analyzing Tool are investigated.
I have written a lot, but I hope that everything is only in business :)
First you need to understand how OOM arises. Someone may not yet know.
Imagine that there is some upper limit of the RAM for the application. Let it be gigabytes of RAM.
In itself, the occurrence of OOM in one of the threads does not mean that it is this thread that “devoured” all the free memory, and in general does not mean that the particular piece of code that led to the OOM is to blame for this.
The situation is quite normal when some kind of flow was engaged in something, eating memory, “got busy” with this to the state “a little more, and I would burst”, and completed the execution, pausing. At that time, some other thread decided to request some more memory for its little work, the garbage collector tried, of course, but I did not find any garbage in my memory. In this case, just the OOM, which is not related to the source of the problem, occurs when the glass flow shows the wrong cause of the application crash.
There is another option. For about a week, I explored how to improve the lives of a couple of our applications so that they stop being unstable. And another week or two spent on it in order to bring them in order. In total, a couple of weeks of time, which stretched for a month and a half, because I was engaged not only in these problems.
From the found: a third-party library, and, of course, some unaccounted things in calls to stored procedures.
In one application, the symptoms were as follows: depending on the load on the service, it could fall in a day, and could in two. If you monitor the state of the memory, it was clear that the application gradually gained "size", and at a certain moment it simply went down.
With another application is somewhat more interesting. It may behave well for a long time, and could stop responding 10 minutes after the reboot, or suddenly fall down, devouring all the free memory (I can already see it, watching it). And after updating the version, when the Tomcat version was changed from 7th to 8th, and the JRE, it suddenly on one of Fridays (having worked before that, as many as 2 weeks) started doing such things that it was embarrassing to admit it. :)
In both stories, dumps turned out to be very useful, thanks to them they managed to find all the causes of falls, making friends with tools like JVisualVM (I’ll call it JVVM), Eclipse Memory Analyzing Tool (MAT) and OQL (maybe I don’t know how to properly prepare it). MAT, but it turned out to be easier for me to make friends with the implementation of OQL in the JVVM).
You also need a free RAM in order to download dumps. Its volume should be commensurate with the size of the dump being opened.
')
So, I will begin to slowly reveal the cards, and I will begin with the JVVM.
This tool in conjunction with jstatd and jmx allows you to remotely monitor the life of an application on a server: Heap, processor, PermGen, the number of threads and classes, the activity of threads, allows profiling.
JVVM is also expandable, and I didn’t fail to take advantage of this opportunity by installing some plugins that allowed a lot more things, for example, to monitor and interact with MBeans, watch the details of the hip, keep a long look at the application, holding much more period of metrics than the hour provided by the Monitor tab.
Here is a set of installed plugins.
Visual GC (VGC) allows you to see the metrics associated with the heap.
So, two things happened right away:
1) after switching to newer libraries / tomkety / java on one of Fridays, the application, which I have been running for a long time, suddenly began to behave badly two weeks after the exhibit.
2) I was given a refactoring project, which also behaved until some time is not very good.
I don’t remember exactly in what order these events took place, but after the “Black Friday” I decided to finally deal with memory dumps in more detail, so that it would no longer be a black box for me. I warn you that I could already forget some details.
On the first occasion, the symptoms were as follows: all the threads responsible for processing requests were burned out, only 11 connections were open to the database, and they did not say that they were used, the base said that they were able to recv sleep, that is, they were waiting for them will start to use.
After the reboot, the application came to life, but it could not live long, on the evening of the same Friday it lived the longest, but after the end of the working day it fell again. The picture was always the same: 11 connections to the base, and only one, it seems, is doing something.
Memory, by the way, was at a minimum. I cannot say that OOM led me to search for causes, but the knowledge gained in searching for causes allowed me to begin an active struggle against OOM.
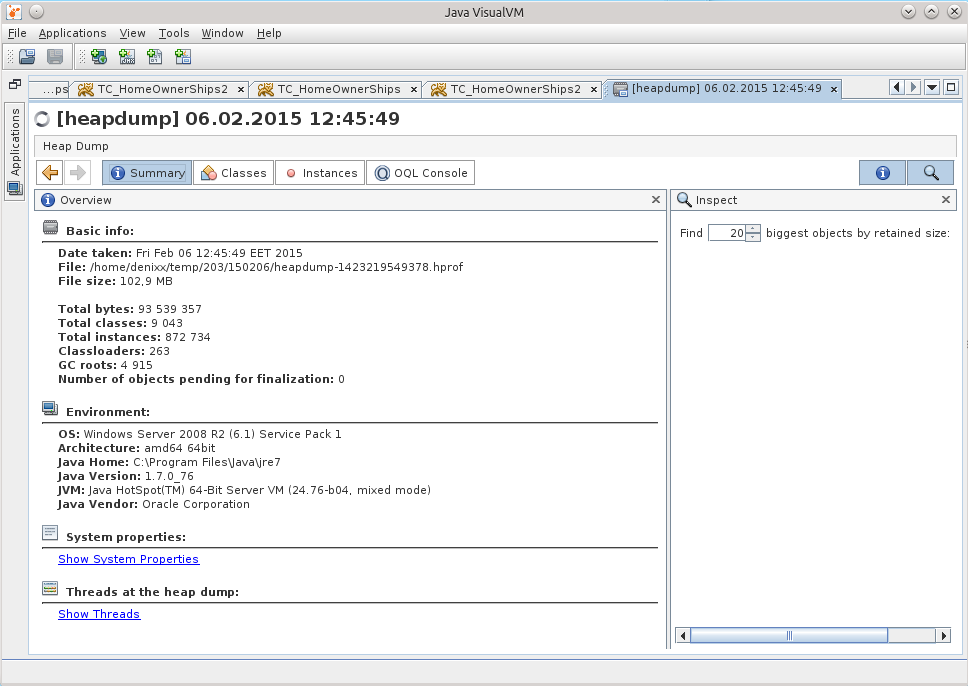
When I opened the dump in JVVM, it was difficult to understand anything from it.
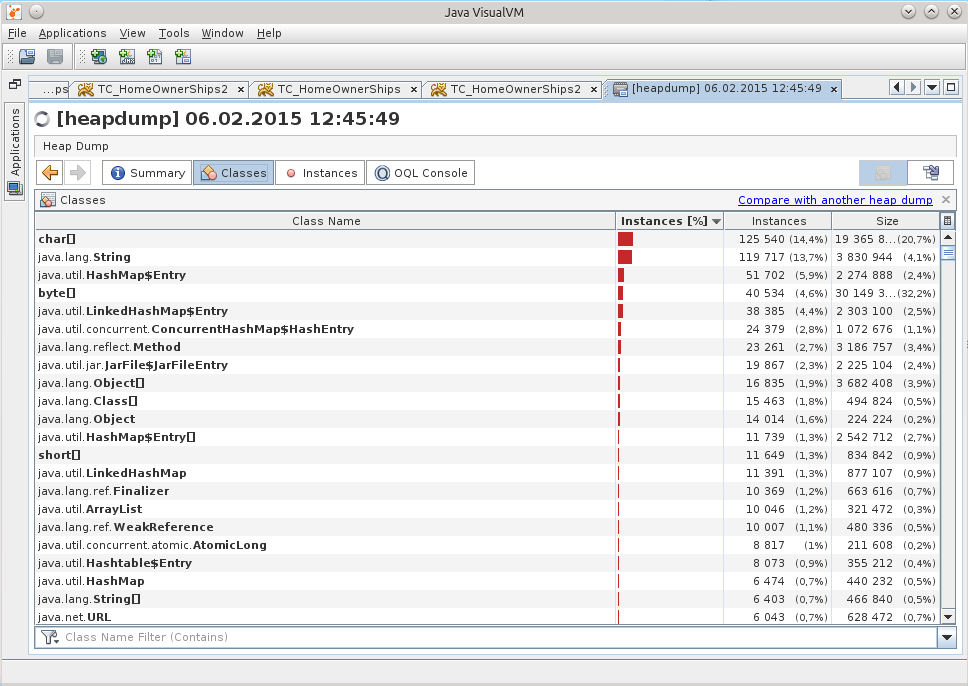
Subconsciousness suggested that the reason was somewhere in the work with the base.
A search among the classes told me that there are already 29 DataSource in memory, although there should be a total of 7.
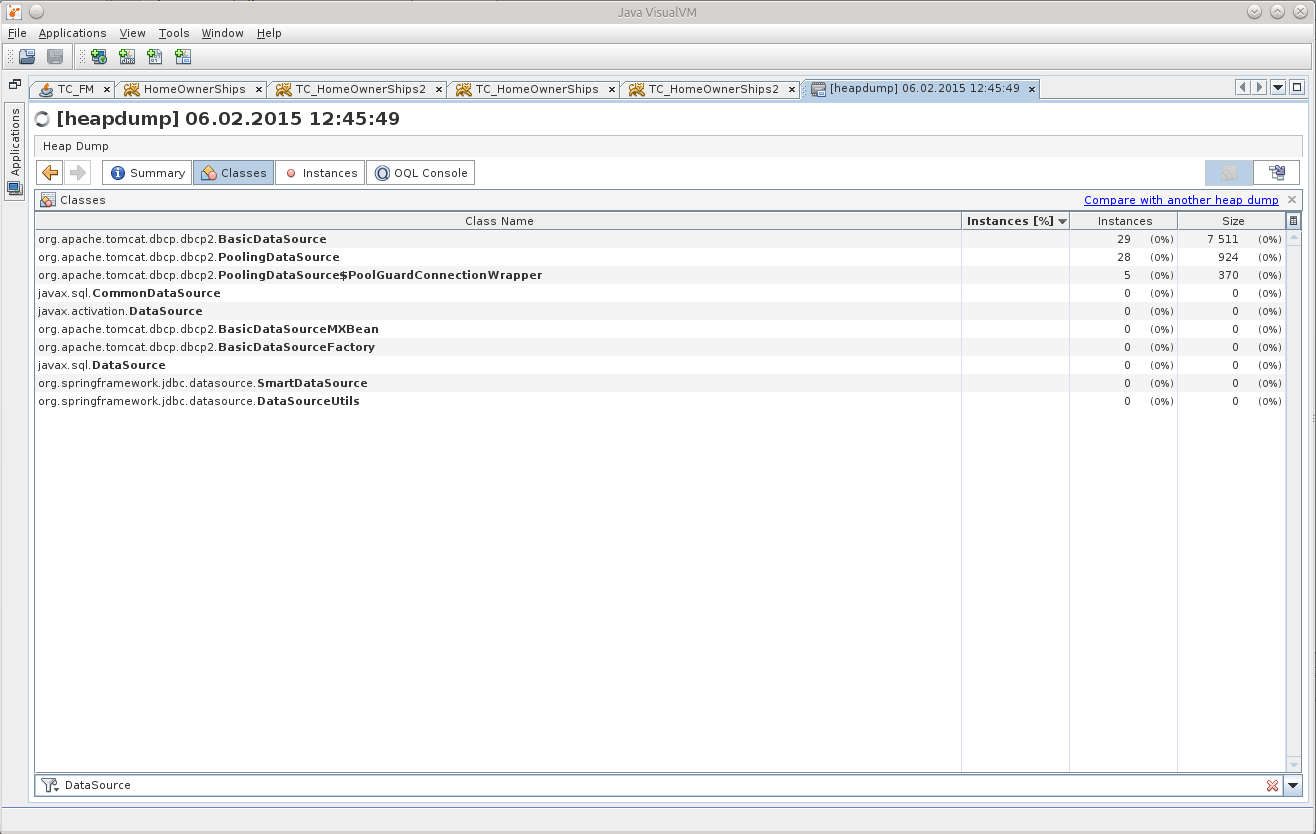
This gave me a point from which it would be possible to push off, to begin to unravel the tangle.
There was no time to sit around pereklitsyvat in the viewer, and my attention was finally attracted by the OQL Console tab, I thought that here it is, the moment of truth - either I will start using it to its fullest, or I will score on all of this.
Before starting, of course, Google was asked a question, and he kindly provided a cheat sheet on how to use OQL in the JVVM: http://visualvm.java.net/oqlhelp.html
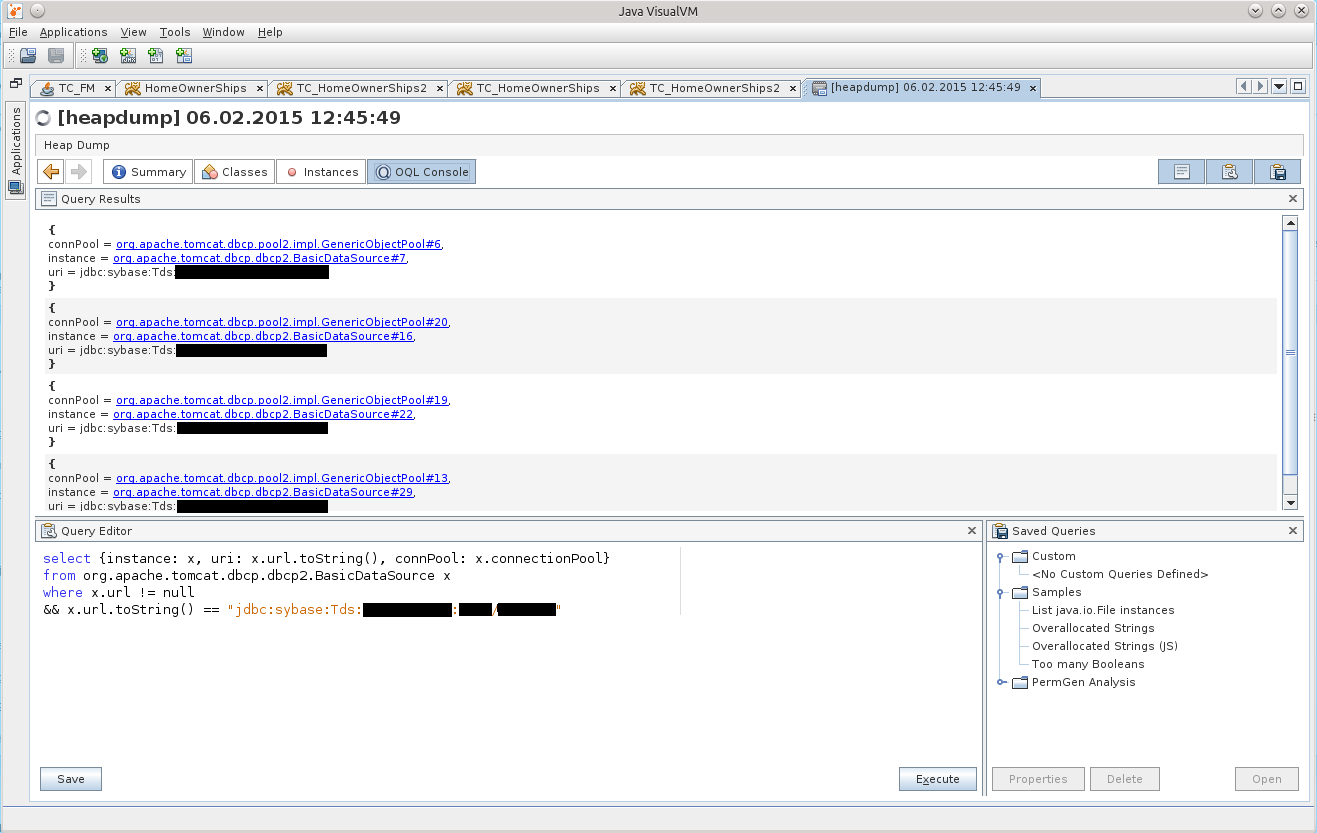
At first, the abundance of compressed information disheartened me, but after using Google-Fu, the following OQL query appeared:
This is a revised and updated final version of this request :)
The result can be seen in the screenshot:
After clicking on BasicDataSource # 7 we get to the desired object in the Instances tab:
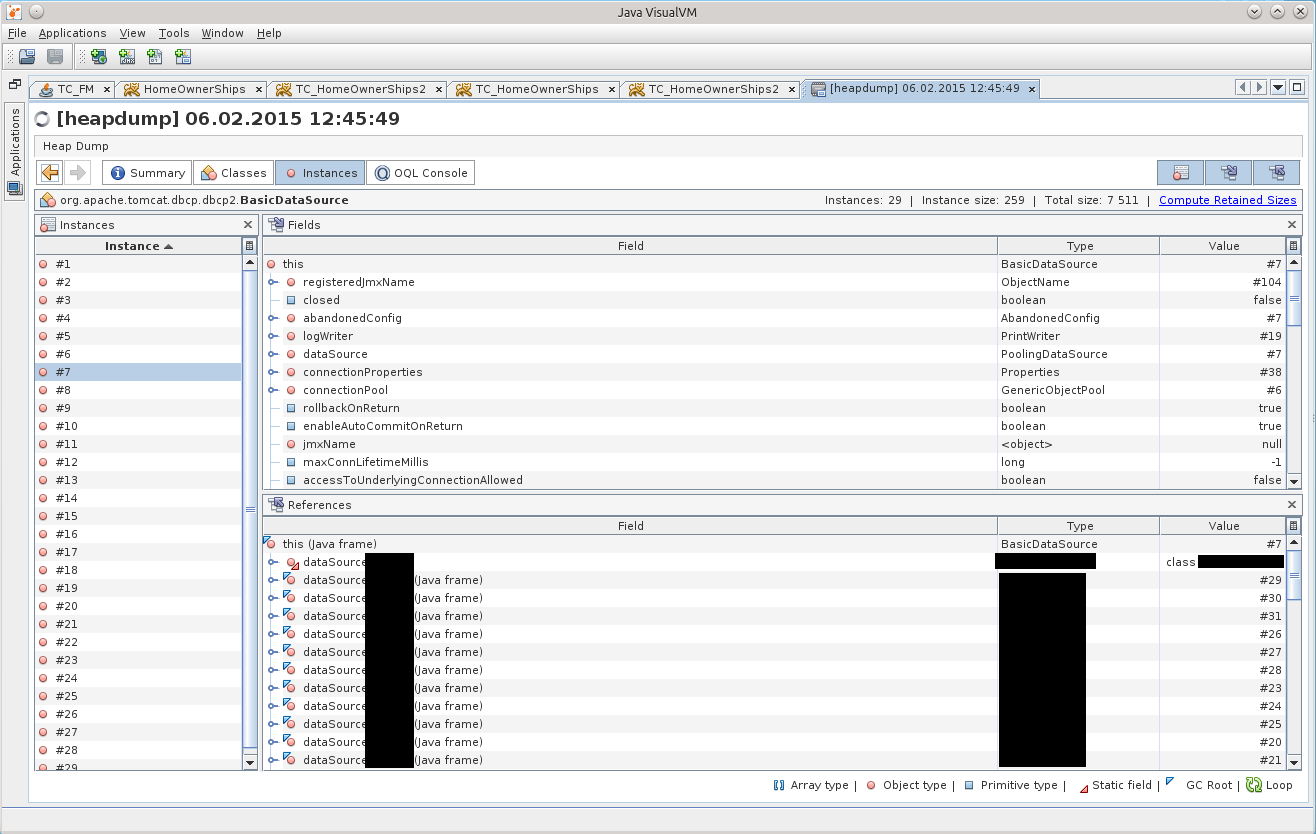
After some time, it dawned on me that there is one incompatibility with the configuration specified in the Resource tag in the volume in the /conf/context.xml file. Indeed, in the dump, the maxTotal parameter is set to 8, while we specified maxActive equal to 20 ...
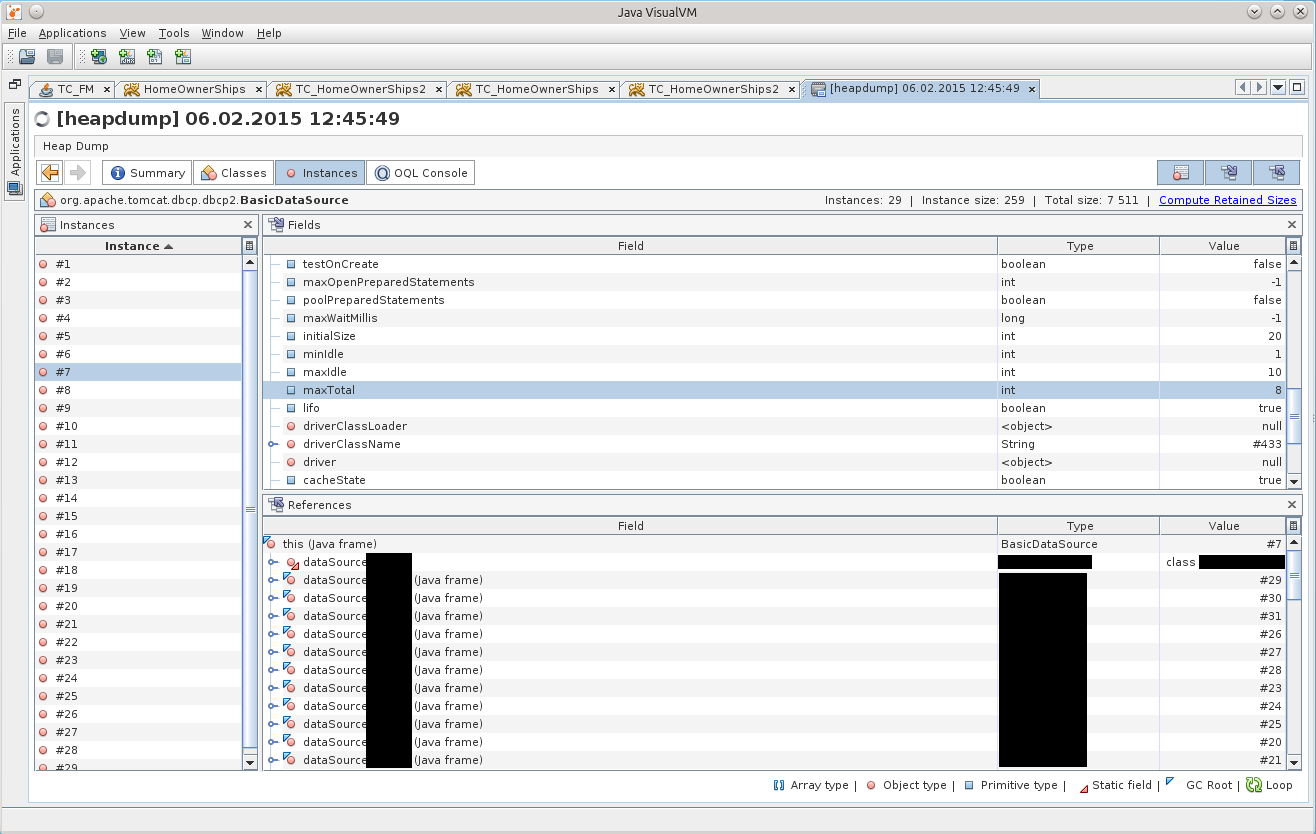
It was then that it began to come to me that the application lived with the wrong configuration of the connection pool all these two weeks!
For the sake of brevity, I’ll write here that if you use Tomcat and DBCP as a connection pool, DBCP version 1.4 is used in the 7th volume, and DBCP 2.0, which I later found out, decided to rename some of them in the 8th volume. options! And about maxTotal in general on the main page of the site is written :)
http://commons.apache.org/proper/commons-dbcp/
"Users should also be aware of this option."
I called them in every way, calmed down, and decided to figure it out.
As it turned out, the BasicDataSourceFactory class simply simply receives this very Resource, looks at whether it has the necessary parameters, and takes them into the generated BasicDataSource object, silently ignoring everything that it does not interest.
So it happened that they renamed the most fun parameters, maxActive => maxTotal, maxWait => maxWaitMillis, removeAbandoned => removeAbandonedOnBorrow & removeAbandonedOnMaintenance.
By default, maxTotal, as before, is equal to 8; removeAbandonedOnBorrow, removeAbandonedOnMaintenance = false, maxWaitMillis is set to "wait forever."
It turned out that the pool was configured with a minimum number of connections; if free connections end - the application silently waits for them to be released; and finishes all silence in the logs about the "abandoned" connections - something that could immediately show exactly where theprogrammer asshole code lacks the connection, but does not give it back at the end of their work.
It is now the entire mosaic has developed quickly, and this knowledge has been extracted longer.
“It shouldn’t be like that,” I decided, and patched down the patch ( https://issues.apache.org/jira/browse/DBCP-435 , put it in http://svn.apache.org/viewvc/commons/proper/ dbcp / tags / DBCP_2_1 / src / main / java / org / apache / commons / dbcp2 / BasicDataSourceFactory.java? view = markup ), the patch was accepted and entered into the version of DBCP 2.1. When and if Tomcat 8 updates the DBCP version to 2.1+, I think that admins will open many secrets about their configuration Resource :)
Regarding this incident, I just had to tell one more detail - what the heck in the dump was already 29 DataSource instead of just 7 pieces. The answer lies in the banal arithmetic, 7 * 4 = 28 + 1 = 29.
After that, everything became clear: 11 connections were because in one, active DataSource 8 connections were eaten (maxTotal = 8), and another by minIdle = 1 in three other unused DataSource copies.
That Friday we rolled back to Tomcat 7, which lay side by side, and waited to get rid of it, it gave time to calmly figure everything out.
Plus, later, on TC7, there was a leak of connections, thanks to removeAbandoned + logAbandoned. DBCP happily reported to catalina.log that
This one here is a bad Bad Method has Connection con in the signature, but inside was the construction “con = getConnection ();”, which became a stumbling block. Superclass is rarely called, so it was not paid attention to him for so long. Plus, the calls did not happen during the working day, as I understand it, so even if something was hanging, no one was concerned about it. And at TusamPayutnitsa just the stars came together, the head of the department of the customer needed to see something :)
As for the "event number 2" - they gave me the application for refactoring, and it immediately dared to crash on the servers.
Dumps came to me already, and I decided to try to pick them up too.
Opened a dump in the JVVM, and "something desponded":
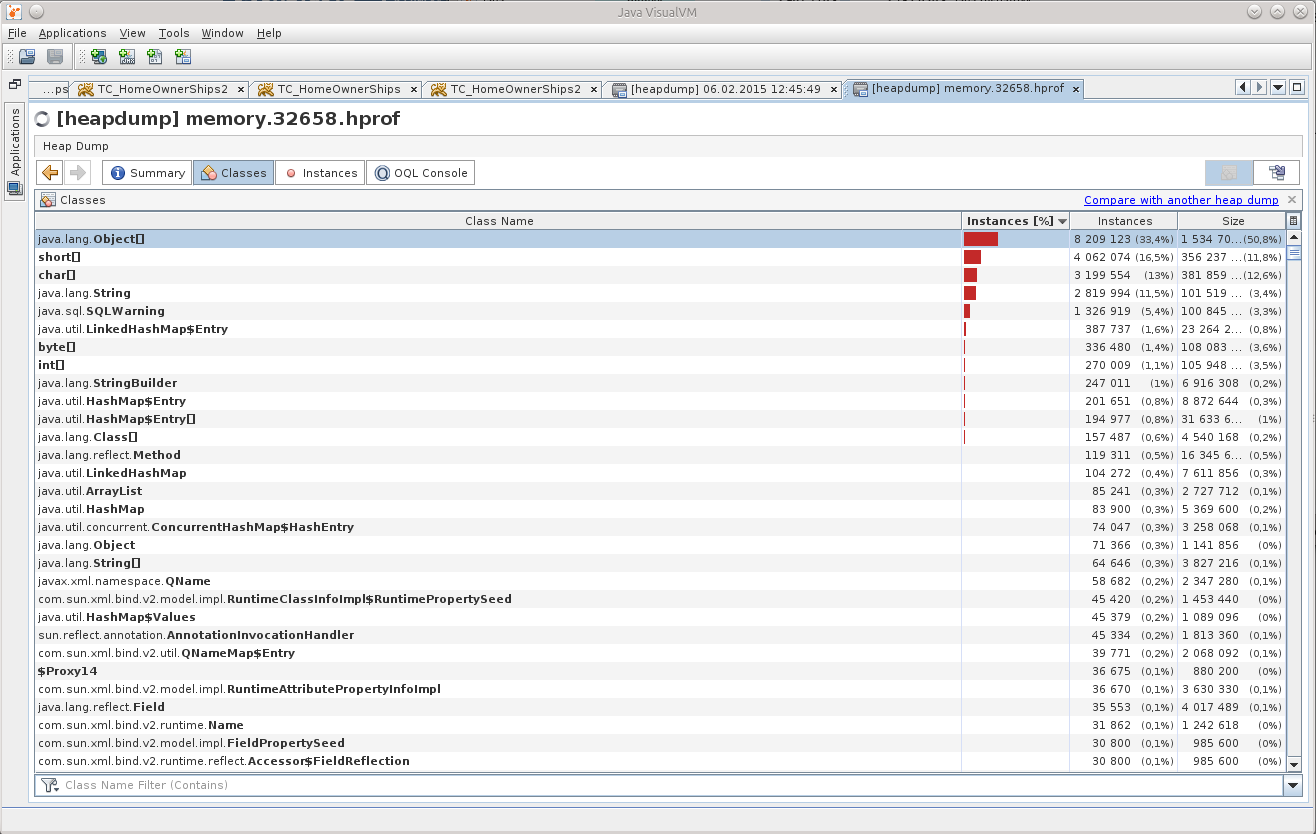
What can be understood from Object [], and even in such numbers?
(An experienced person, of course, already saw the reason, right? :))
So, the thought “I didn’t really have done it before, because I probably already have a finished tool!” So I came across this question on StackOverflow: http://stackoverflow.com/questions/2064427/recommendations-for-a-heap-analysis-tool-for-java .
Having looked at the proposed options, I decided to stop at MAT, I had to try at least something, and this is an open project, and even with a much larger number of votes than the other points.
So MAT.
I recommend downloading the latest version of Eclipse, and installing the MAT there, because the independent version of the MAT behaves badly, there is some kind of devilry with the dialogues, they do not see the contents in the fields. Maybe someone will tell in the comments what he is missing, but I solved the problem by installing the MAT in Eclipse.
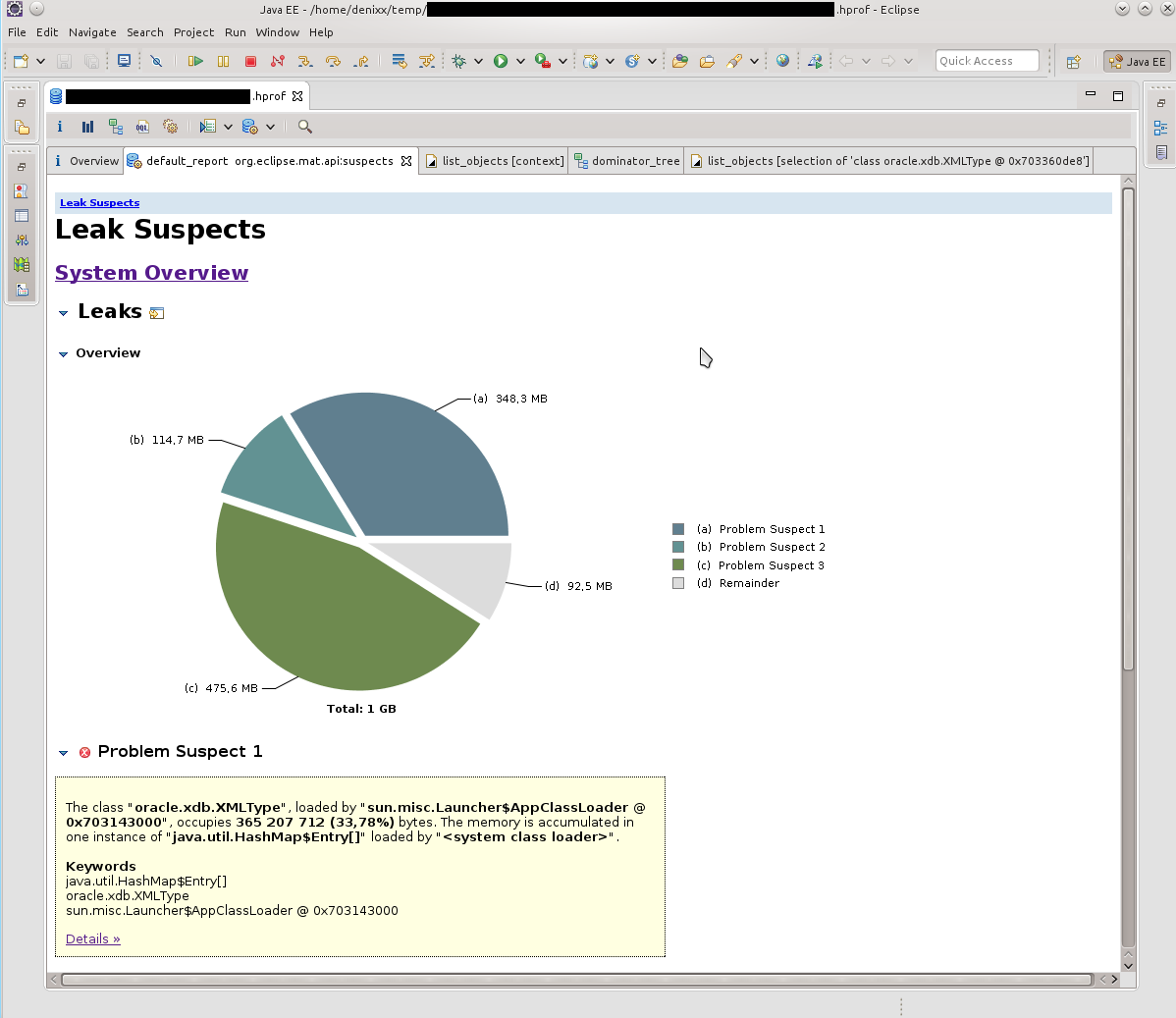
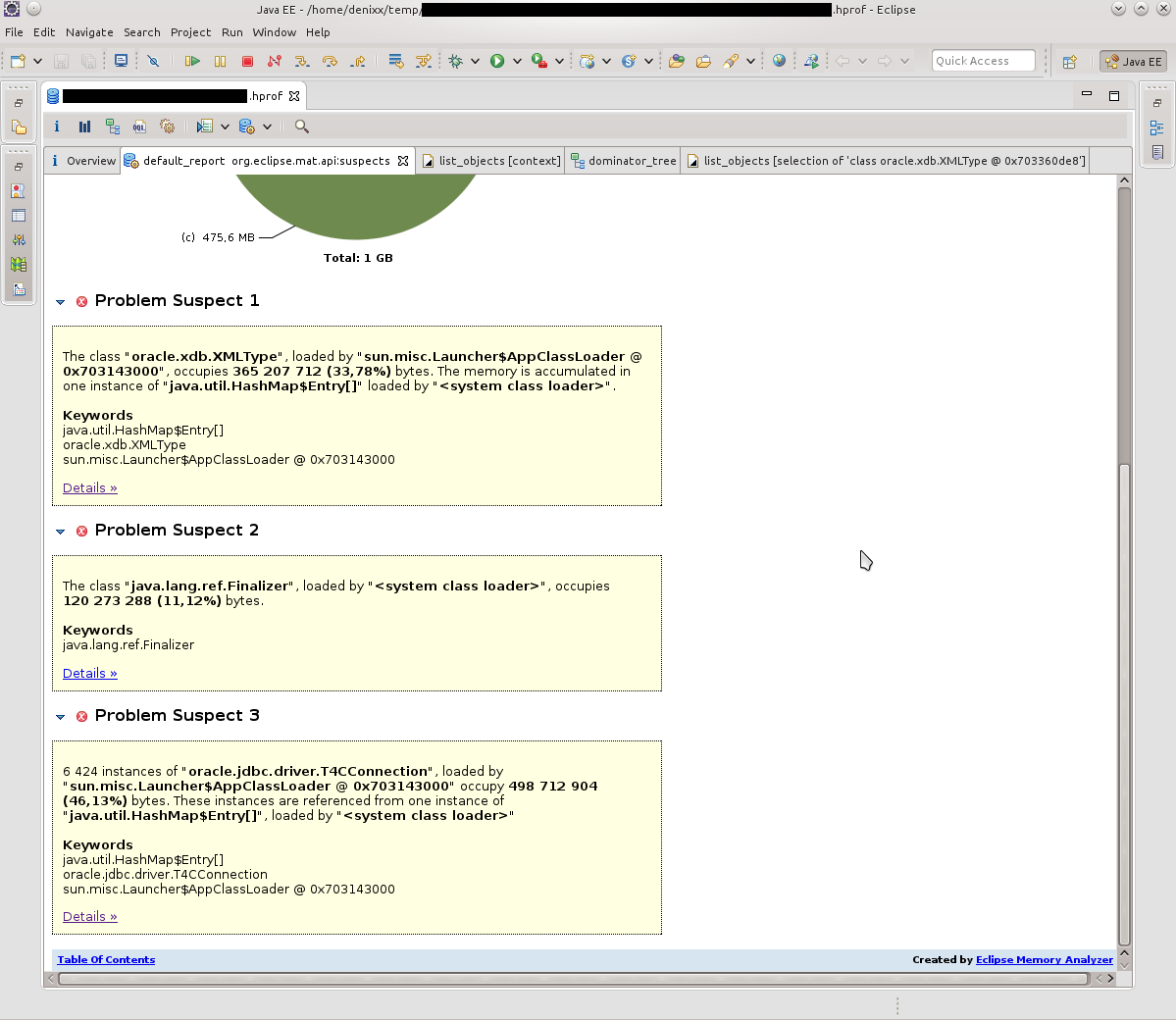
Having opened a dump in MAT, I requested the execution of the Leak Suspects Report.


Surprise knew no bounds, to be honest.
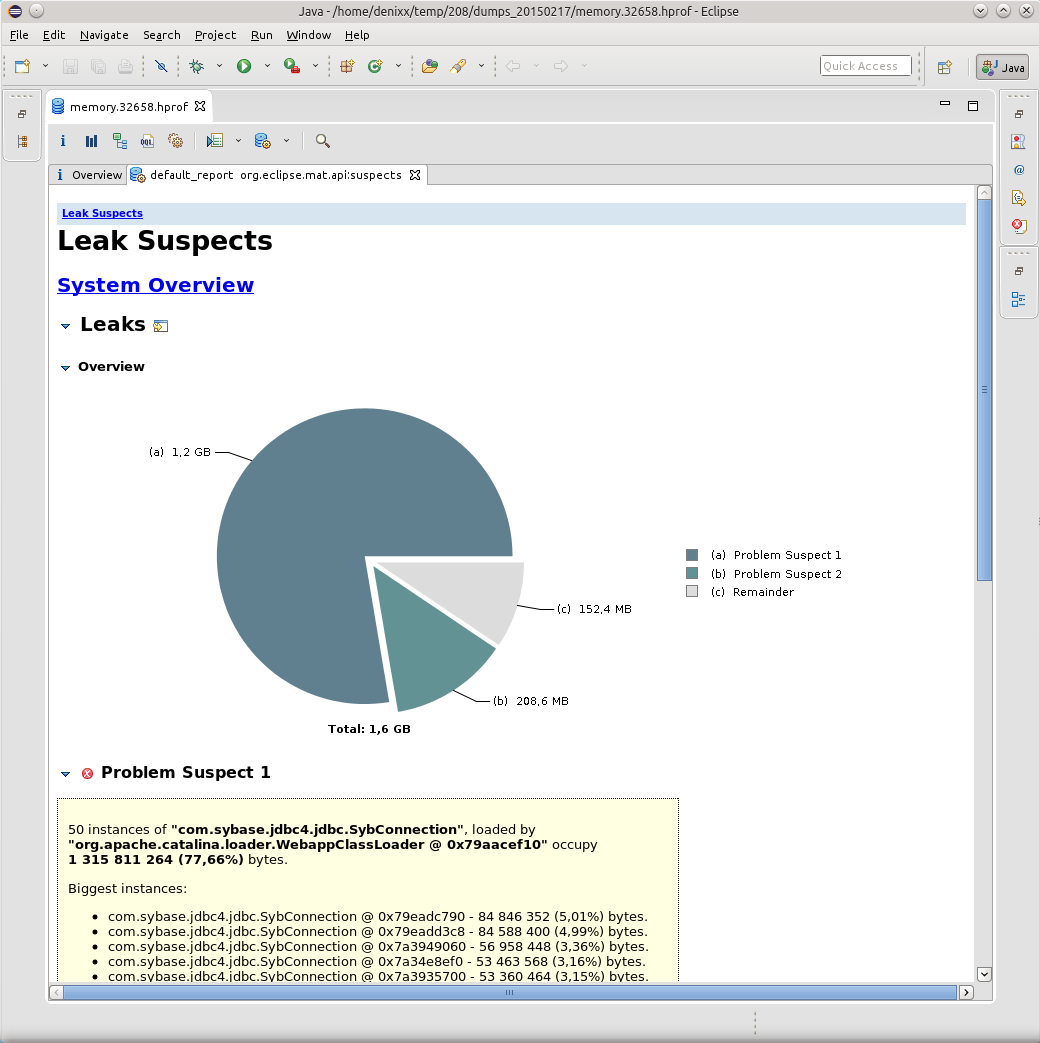
1.2 gigabytes weigh connections to the base.
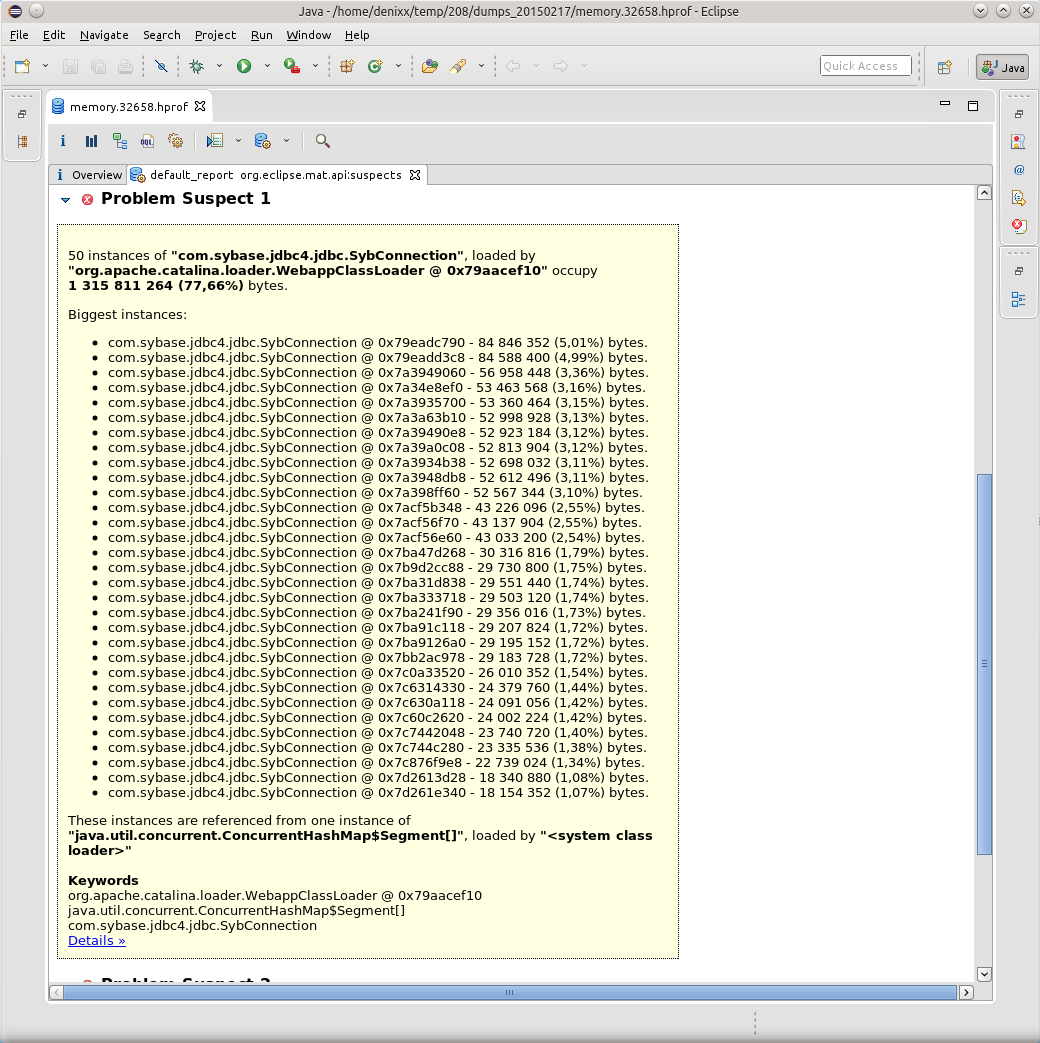
Each connection weighs from 17 to 81 megabytes.
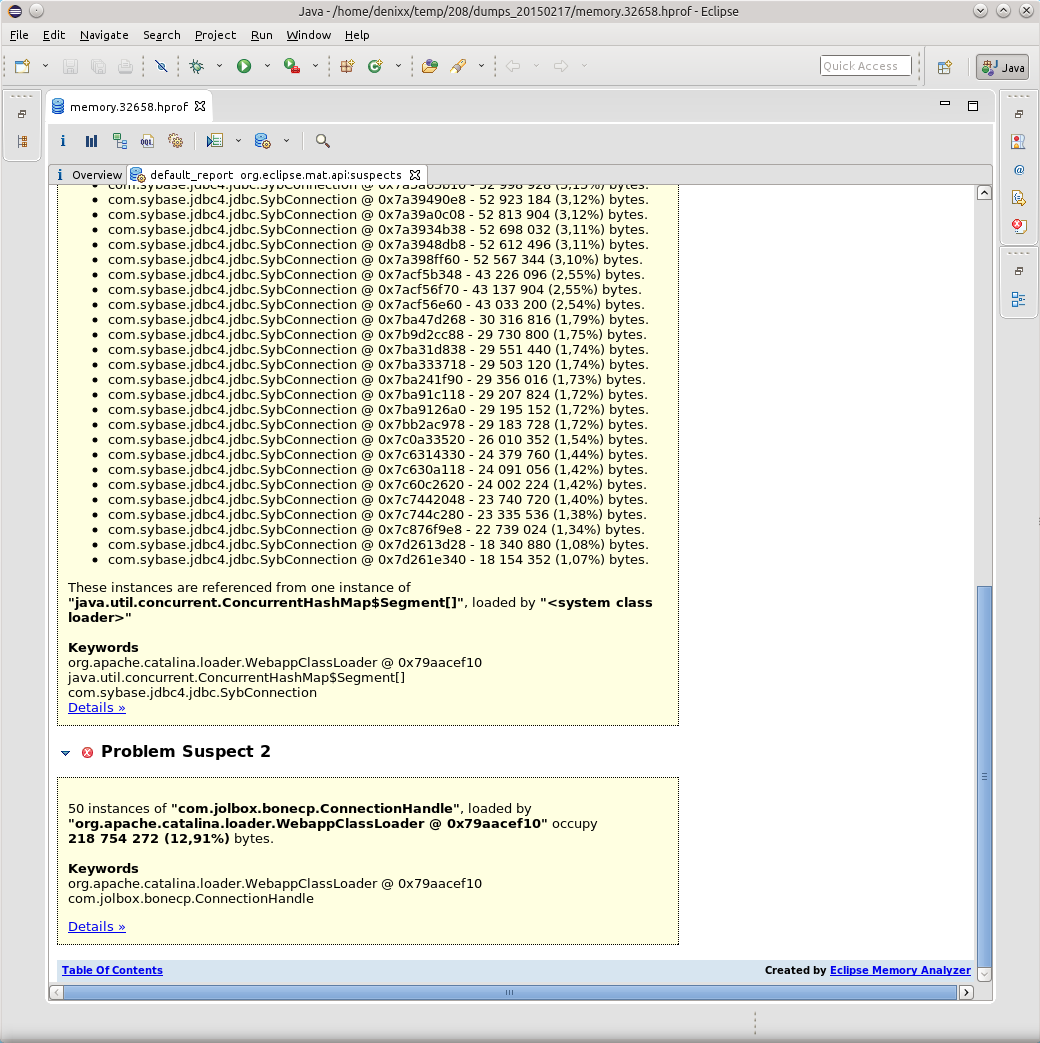
Well, another "little" pool itself.
The Dominator Tree report helped to visualize the problem:
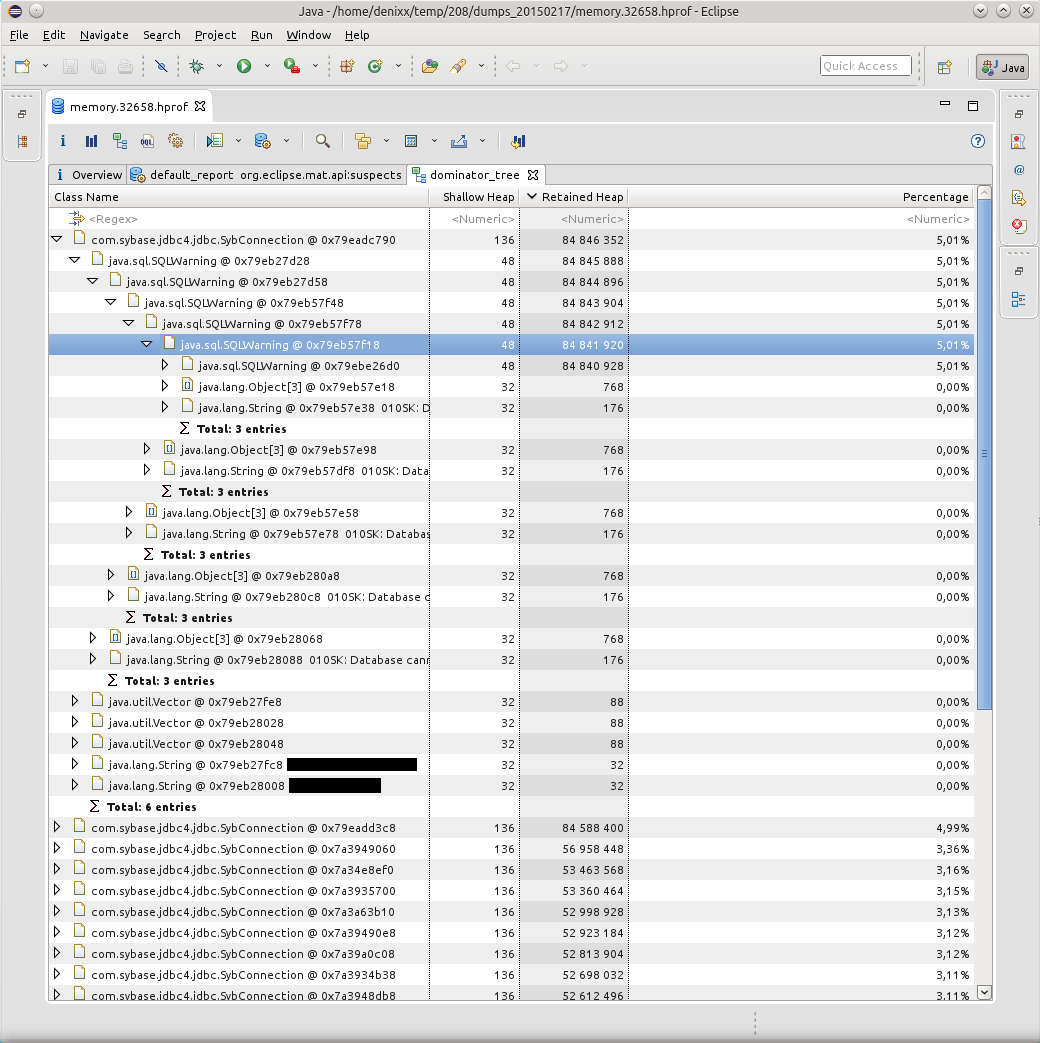
The cause of all the drops was the kilometers of SQLWarning, the base tried hard to make it clear that “010SK: Database cannot set connection option SET_READONLY_TRUE.” And the BoneCP connection pool does not clear SQLWarning after it is released and the connections are returned to the pool (maybe this is where- Can I configure it? Tell me, if anyone knows).
Google said that this problem with Sybase ASE has been known since 2004: https://forum.hibernate.org/viewtopic.php?f=1&t=932731
In short, “Sybase ASE doesn't require any optimizations, therefore setReadOnly () produces a SQLWarning.”, And these solutions still work.
However, this is not exactly the solution to the problem, because the solution to the problem is when all the database notifications are cleared when the connection to the pool returns, because no one will ever need them.
And DBCP can do it: http://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_1_4/src/java/org/apache/commons/dbcp/PoolableConnectionFactory.java?view=markup , method passivateObject (Object obj), in line 687 you can see conn.clearWarnings () ;, this call saves you from kilometers of SQLWarning in memory.
I learned about this from the ticket: https://issues.apache.org/jira/browse/DBCP-102
Also, I was prompted about such a ticket in the bug tracker: https://issues.apache.org/jira/browse/DBCP-234 , but it already concerns the version of DBCP 2.0.
As a result, I transferred the application to DBCP (albeit version 1.4). Let the load on the service and rather big (from 800 to 2k requests per minute), but still the application behaves well, and this is important. And I did it right, because BoneCP has not been supported for five months already, however, HikariCP came to replace it. It will be necessary to see how things are in his source ...
Impressed by how MAT laid everything out for me, I decided not to throw this effective tool, and later it came in handy for me, because the first application still had all sorts of “unrecognized” things unaccounted for in the application code or stored procedure code that sometimes result to the fact that the application glues fins. I still catch them.
Armed with both tools, I began to pick each sent dump in search of the reasons for the fall of the OOM.
As a rule, all OOM led me to TaskThread.
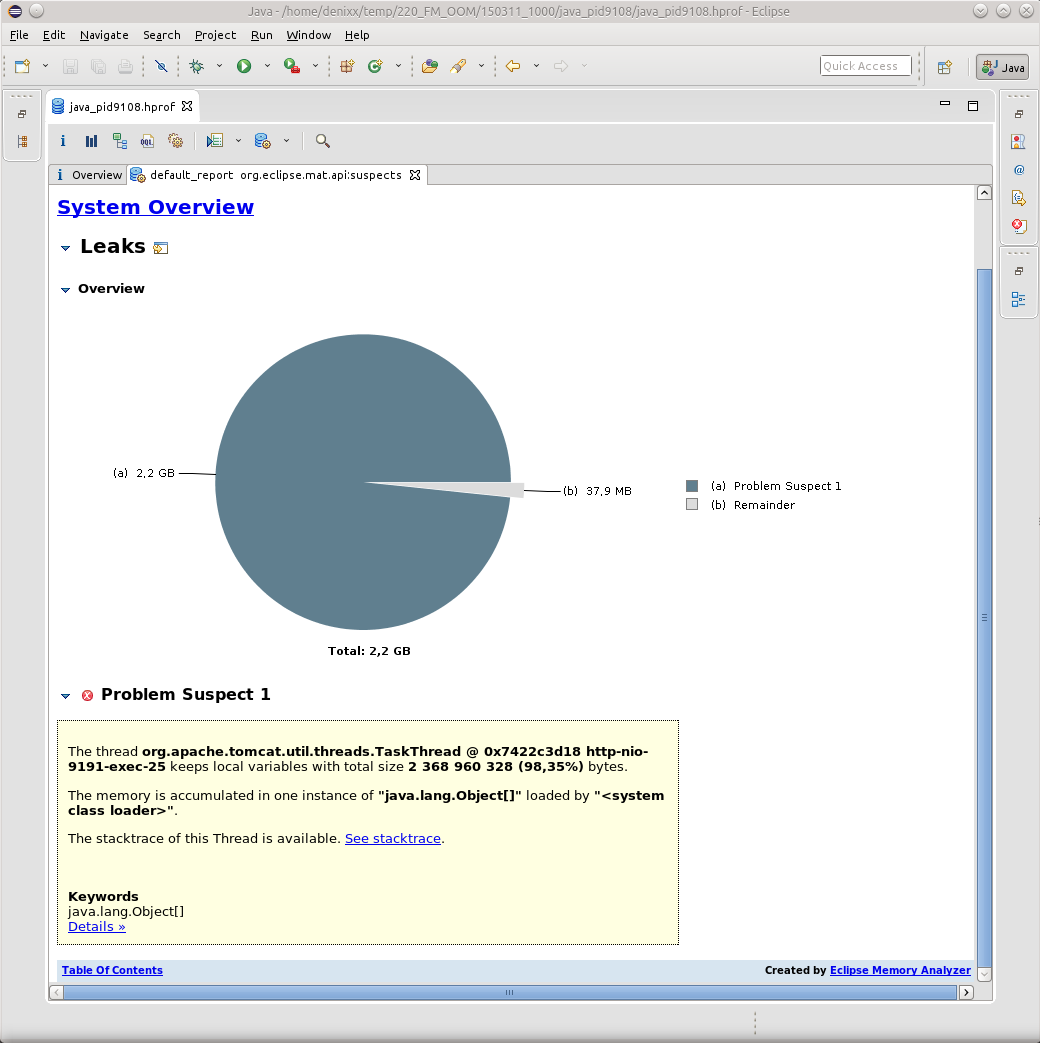
And if you click on the See stacktrace sign, then yes, it will be just a banal case, when some thread suddenly fell down while trying to marshal the result of your work.
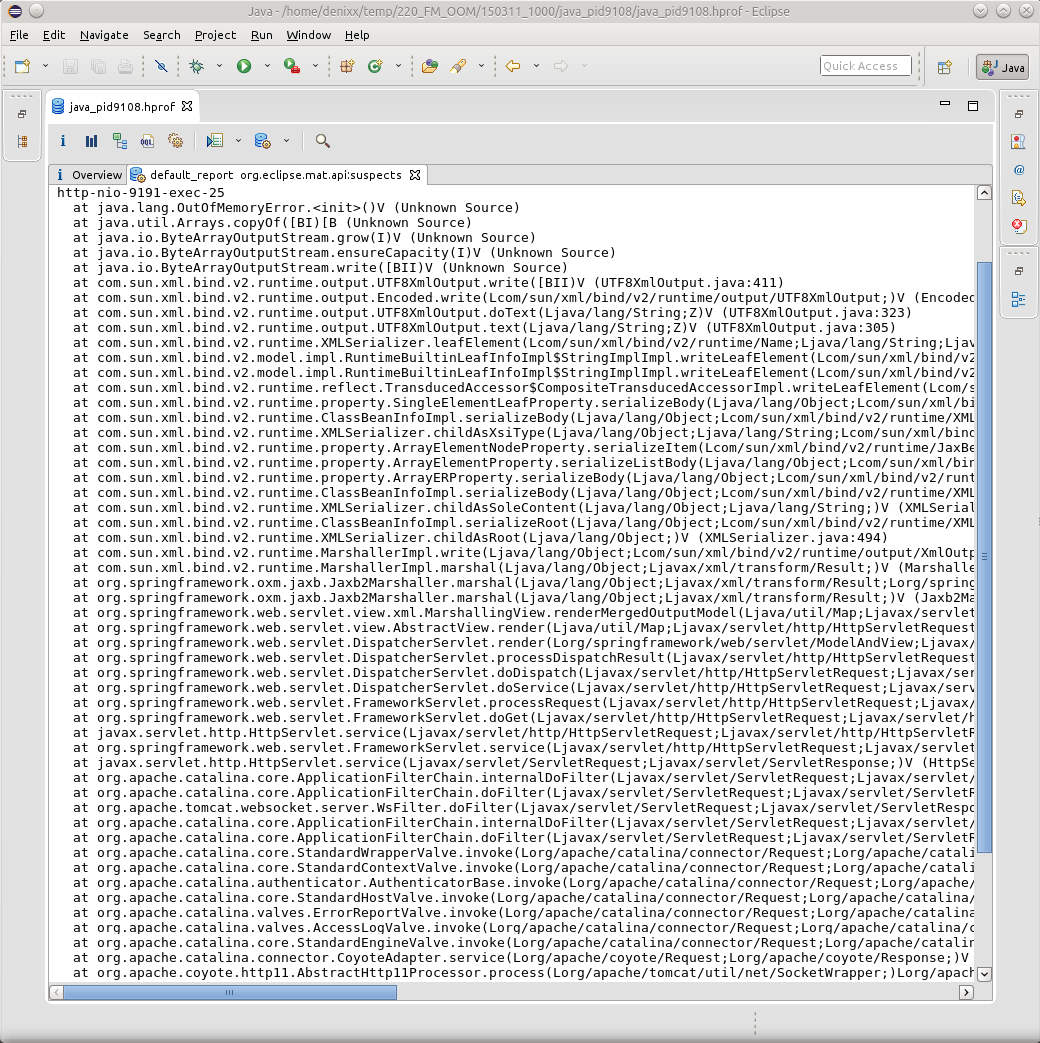
However, here nothing indicates the cause of the OOM, here only the result. Find the reason for me so far, because of the ignorance of all the OQL magic in MAT, it is JVVM that helps.
Download the dump there, and try to find the cause!
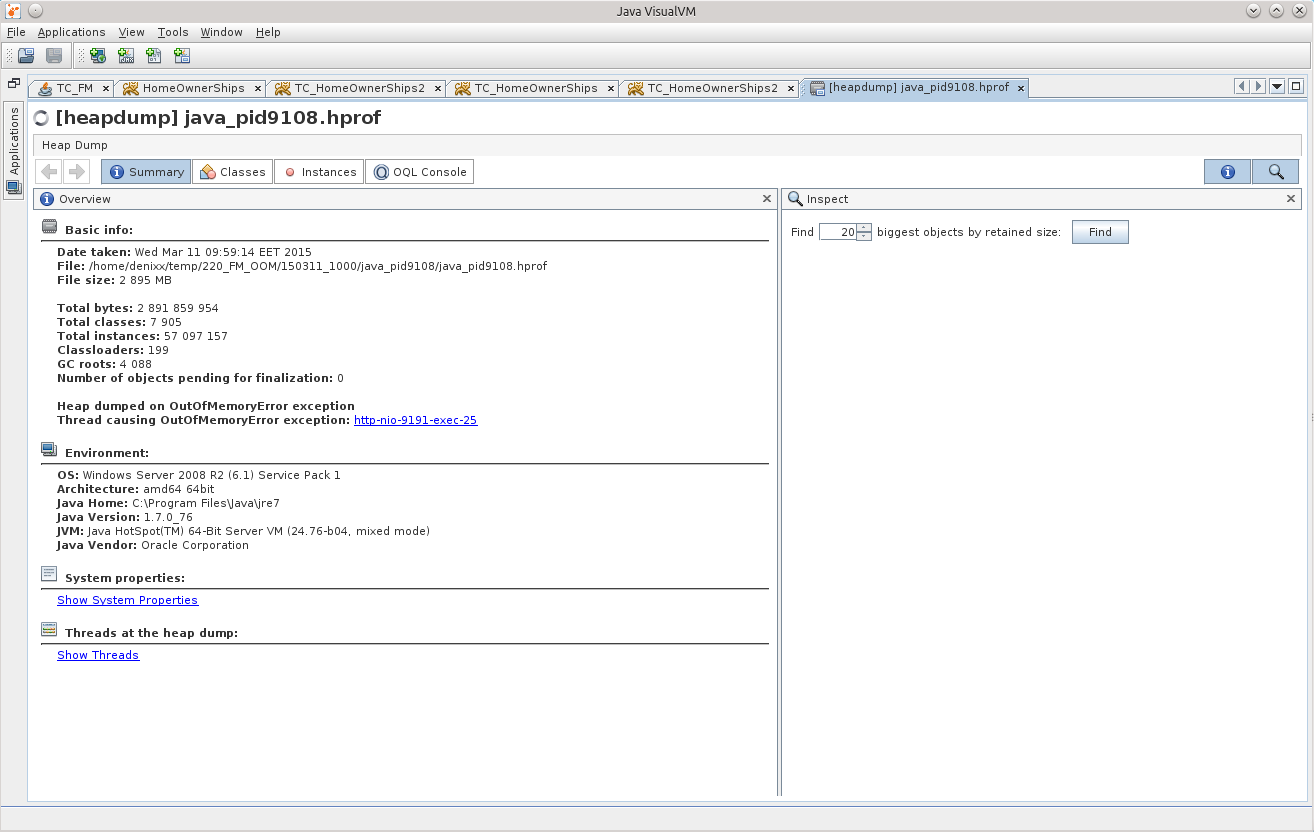
I should, of course, look for exactly the things associated with the database, and therefore we will first try to see if there are statements in memory.
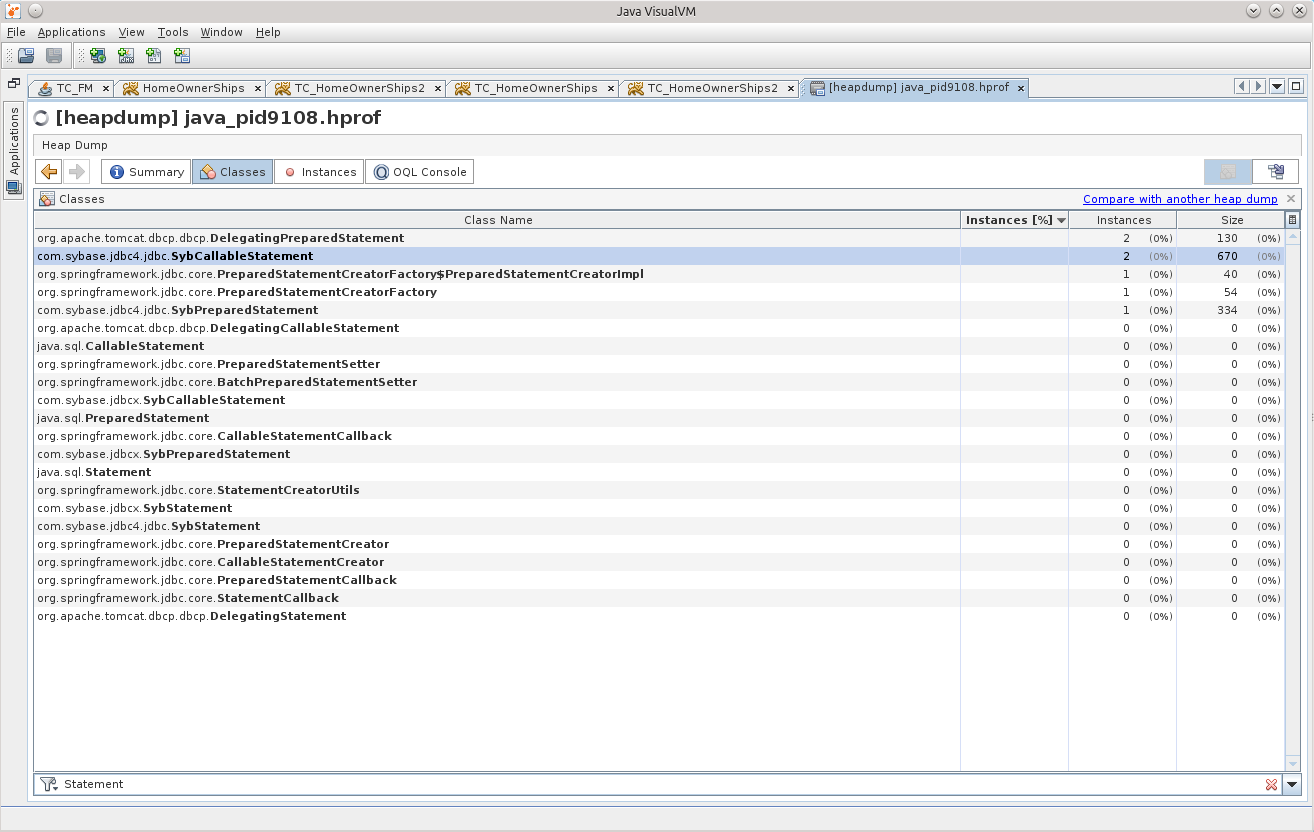
Two SybCallableStatement, and one SybPreparedStatement.
I think that the matter will become more complicated if the statements are much more, but having slightly edited one of the following queries, specifying the necessary conditions in where, I think everything will work out for you. Plus, of course, it’s worth a good look at MAT, what kind of results a stream is trying to stream, which object, and it will become clearer which particular Statement should be searched for.
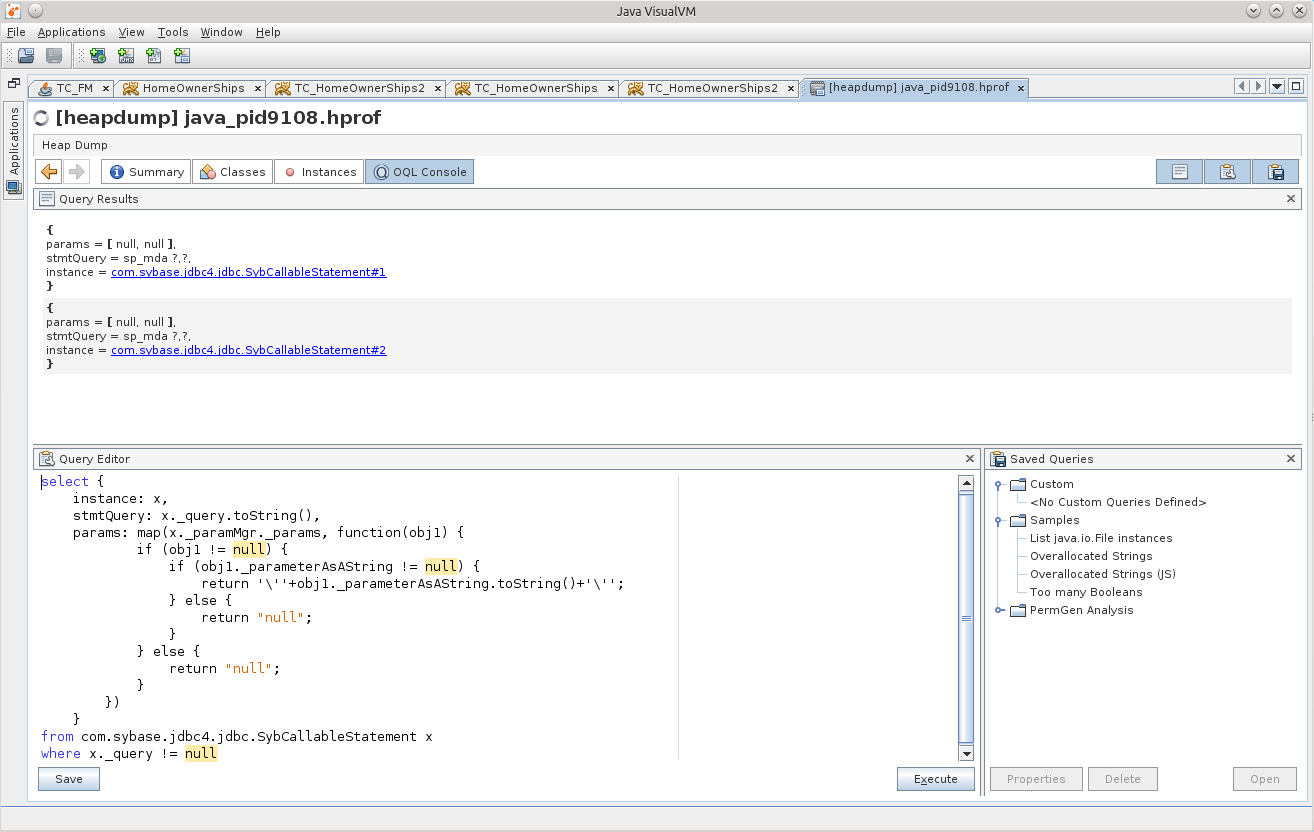
This is not the "internal" calls.
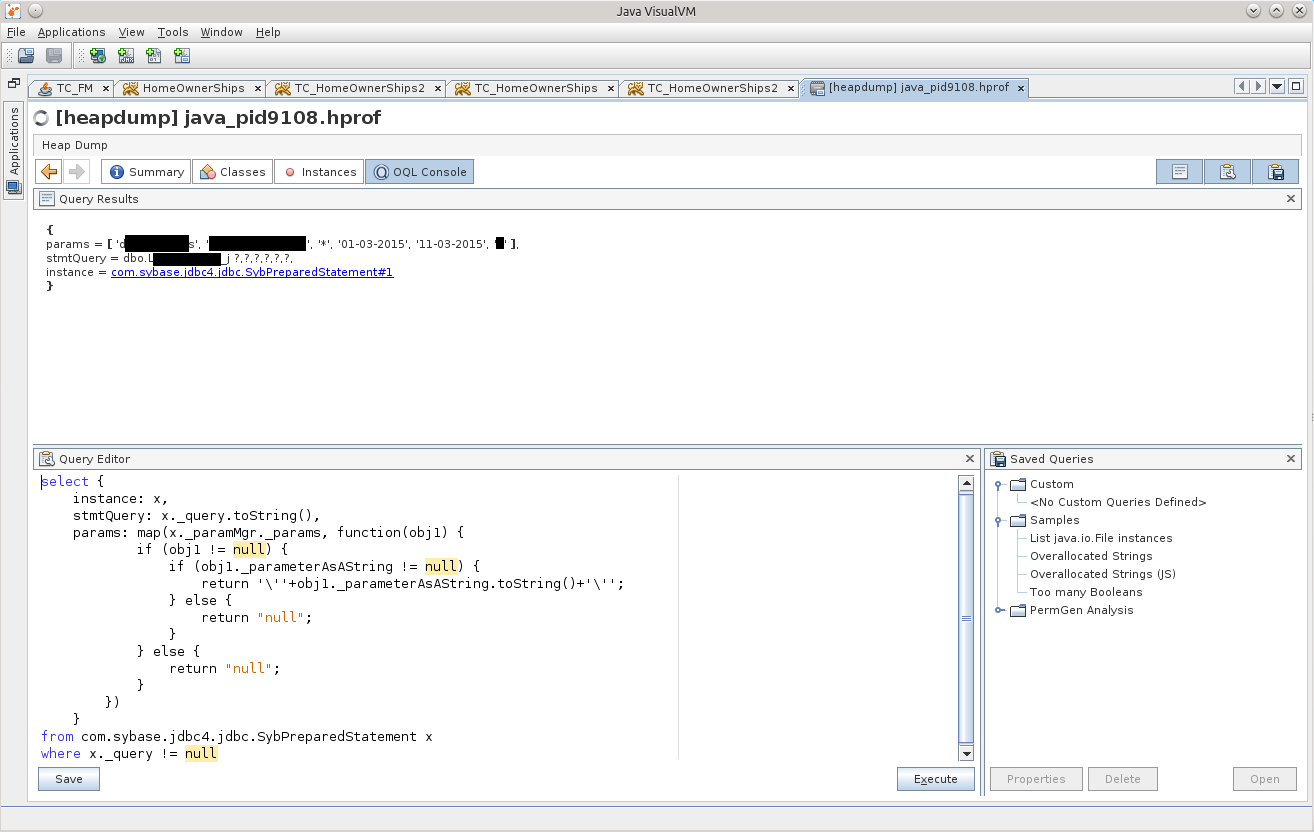
And here is the game!
For the purity of the experiment, you can throw the same query in your favorite DB-IDE, and it will work for a very long time, and if you dig into the depths of the storehouse, it will be clear that there simply 2 million lines are selected from the base that does not belong to us with such parameters. These two million even intermeddle in the memory of the application, but the attempt to marshal the result becomes fatal for the application. Such a hara-kiri. :)
In this case, the GC diligently removes all the evidence, but it did not save it, yet the source remained in the memory, and he will be punished.
For some reason, after all this story, I felt that I was still a loser.
That ended my story, I hope you enjoyed it :)
I would like to thank my boss, he gave me time to figure it all out. I think this new knowledge is very useful.
Thanks to the girls from Scorini for the invariably delicious coffee, but they will not read these words of gratitude - I even doubt that they know about the existence of Habrahabr :)
I would like to see in the comments even more useful information and additions, I will be very grateful.
I think it's time to read the documentation for the MAT ...
UPD1 : Yes, I forgot to tell you about such useful things as creating memory dumps.
docs.oracle.com/javase/7/docs/webnotes/tsg/TSG-VM/html/clopts.html#gbzrr
Options
-XX: + HeapDumpOnOutOfMemoryError
-XX: HeapDumpPath = / disk2 / dumps
very useful for generating dumps when an application crashes using OutOfMemoryError,
and there is also the possibility to remove a memory dump from the application “profitably”, in the middle of its work.
For this there is a utility jmap.
Example call for Windows:
"C: \ install \ PSTools \ PsExec.exe" -s "C: \ Program Files \ Java \ jdk1.7.0_55 \ bin \ jmap.exe" -dump: live, format = b, file = C: \ dump. hprof 3440
the last parameter is the PID of the java process. The PsExec application from the PSTools suite allows you to run other applications with system privileges, for this the "-s" key is used. The live option is useful so that before saving the dump, call the GC, clearing the memory of garbage. In the case when an OOM occurs, there is no need to clean the memory, there is no more garbage left, so do not look for how to set the live option in case of an OOM.
UPD2 (2015-10-28) | Case numbertwo three
(It was decided to add it here as an update, and not to cut a new article about the same):
Another interesting case, but already with the Oracle base.
One of the projects uses a feature with XML, conducts searches on the contents of a saved XML document. In general, this project sometimes made itself felt by the fact that suddenly one of the instances ceased to show signs of life.
Sensing a "good" case to practiceon cats , I decided to watch its memory dumps.
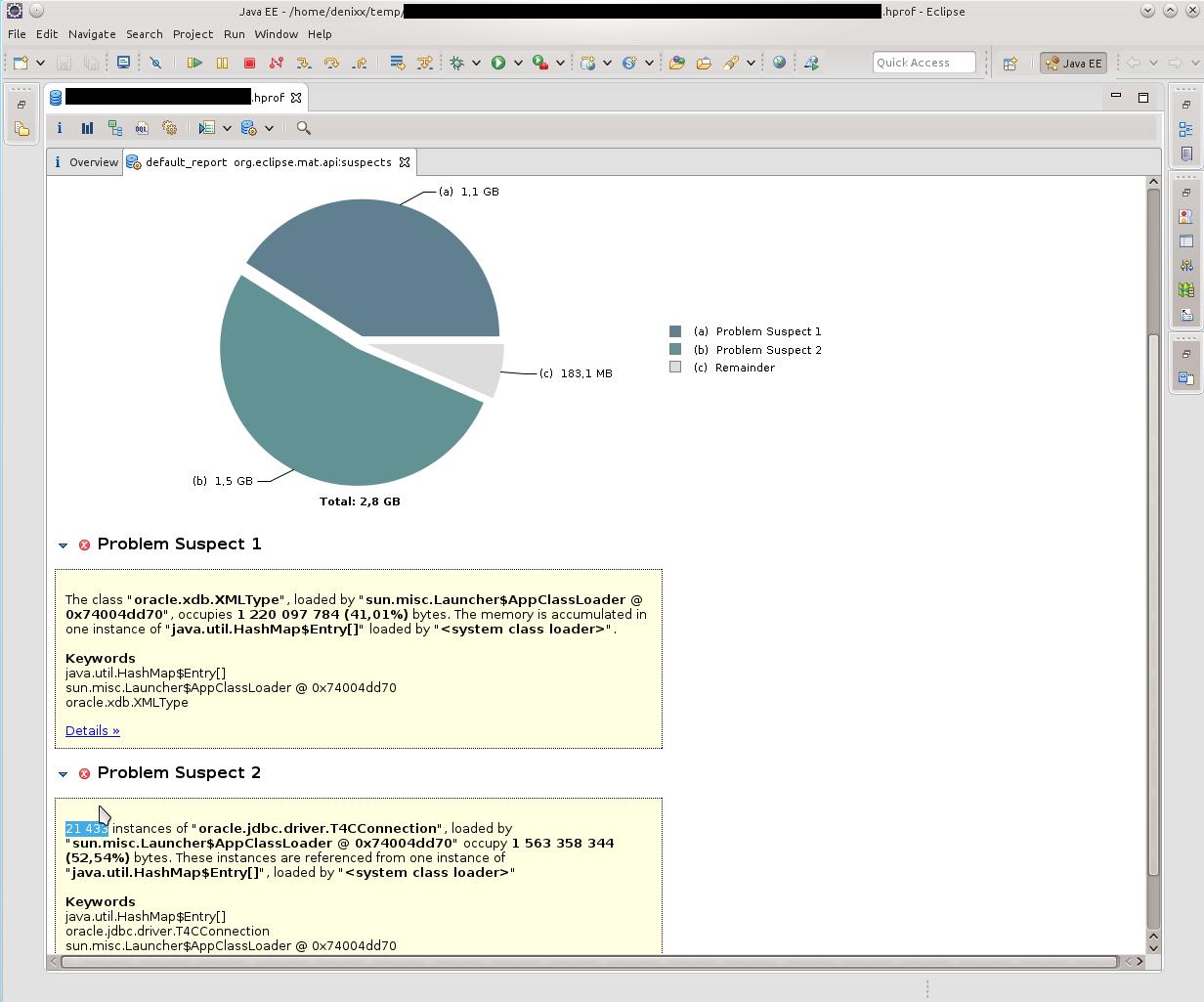
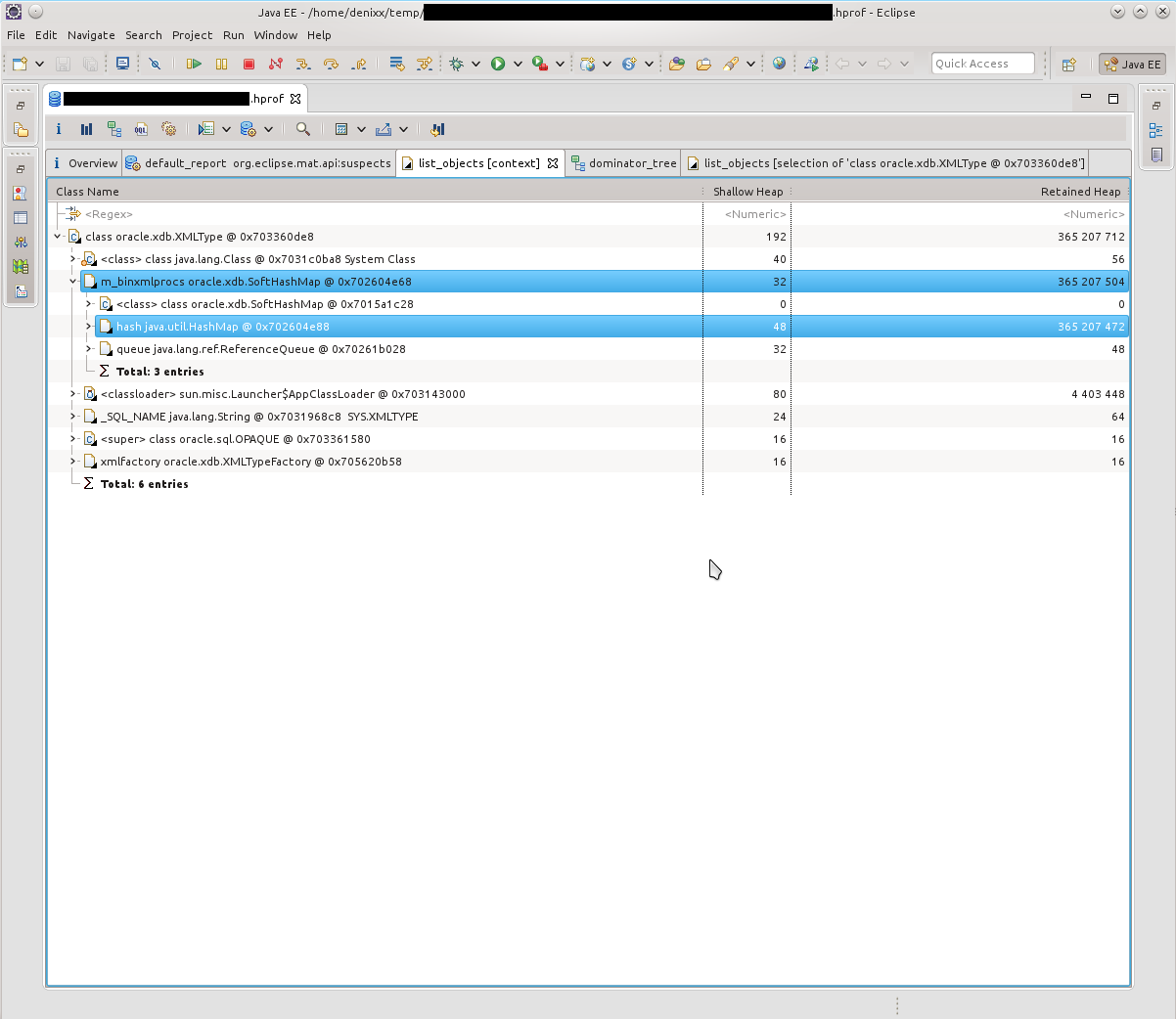
The first thing I saw was “you have a lot of connections left in your memory”. 21k !!! And some interesting oracle.xdb.XMLType also gave heat. “But this is Orakl!”, It turned in my head. Looking ahead I will say that yes, he is guilty.
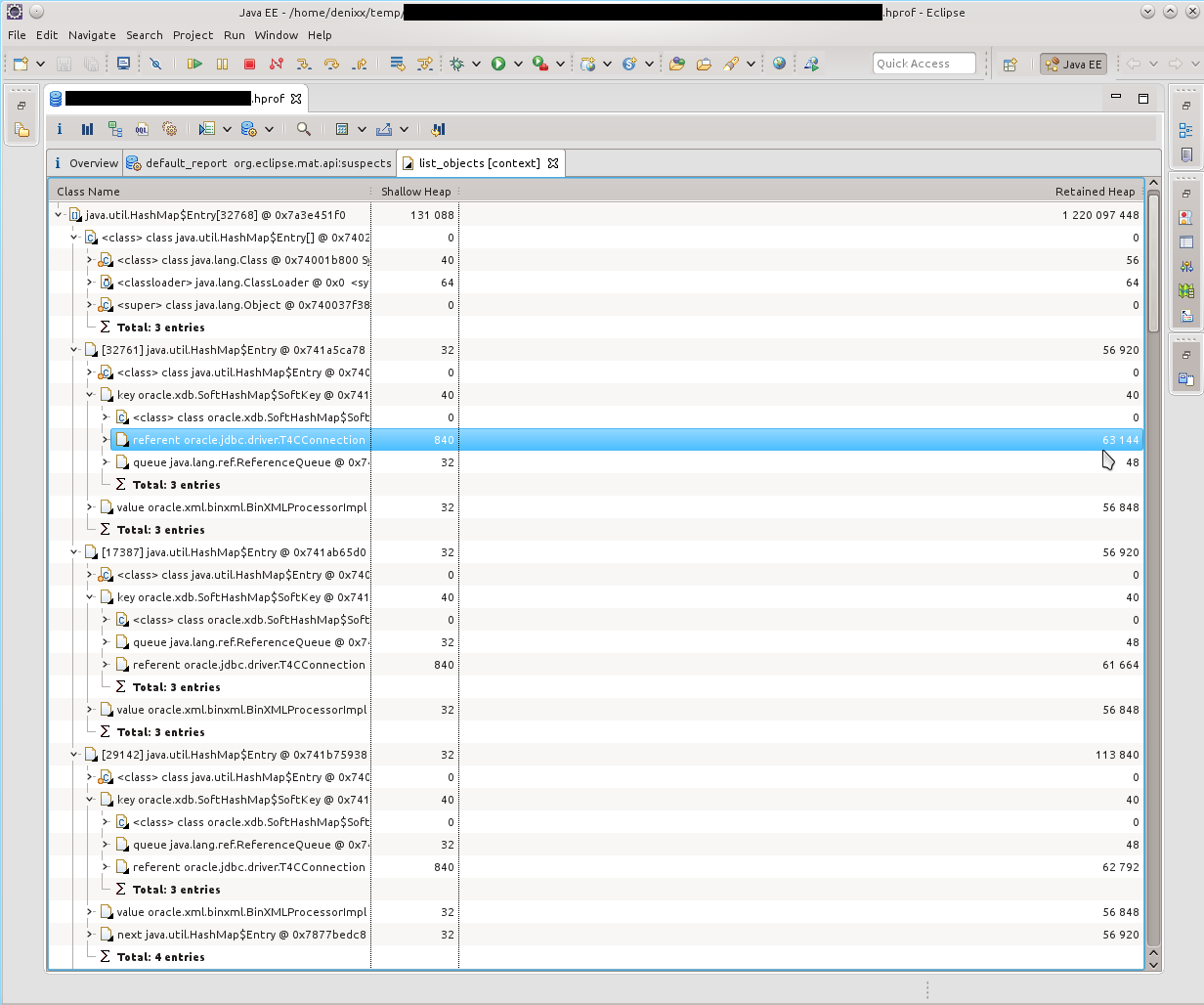
So, we see a bunch of T4CConnection, which are in the HashMap $ Entry. Immediately I noticed that it seems like SoftHashMap, which, it seems, should mean that it should not grow to such size. But you can see the result yourself - 50-60 kilobytes in a connection, and there are really a LOT of them.
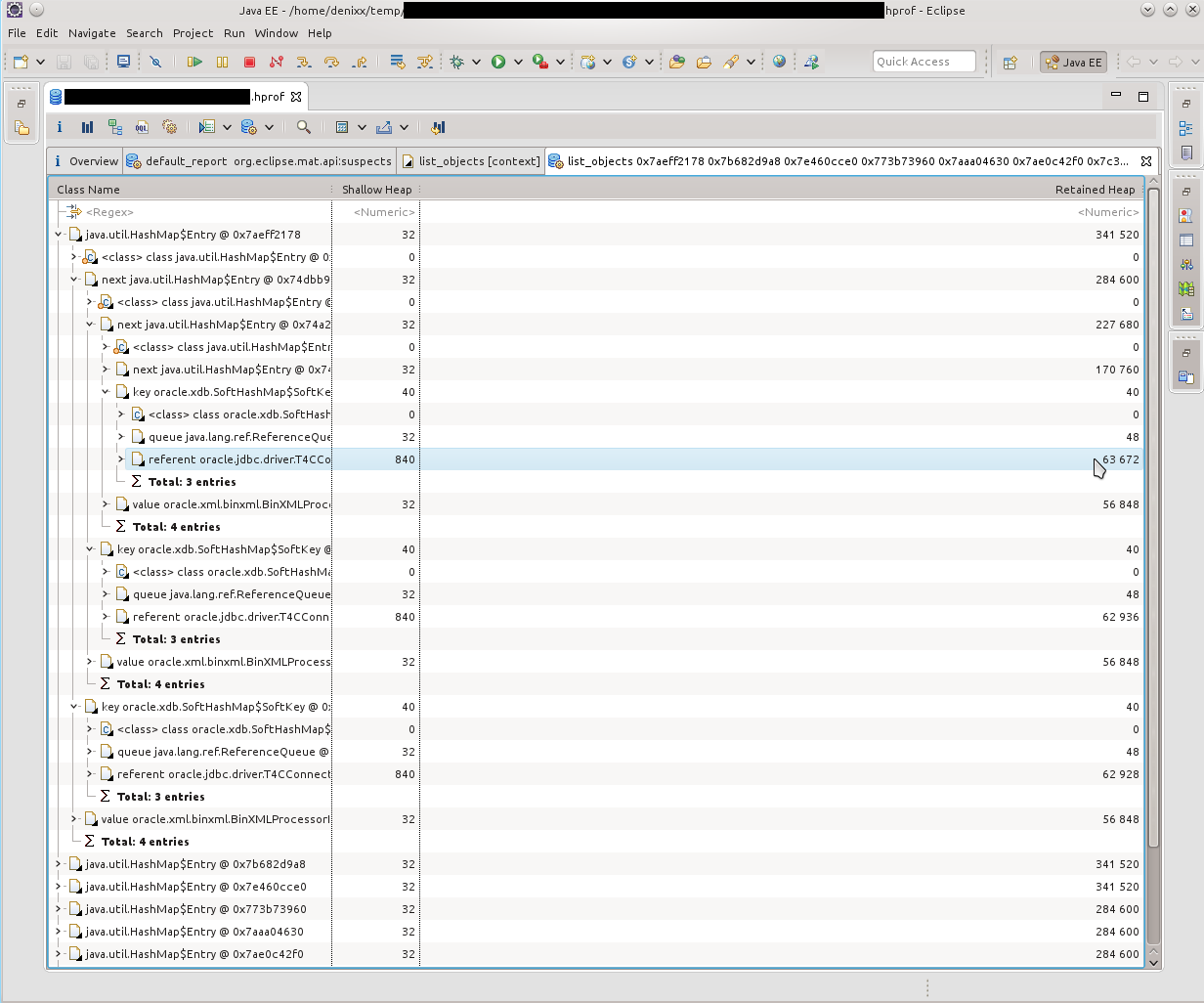
Having looked at what HashMap $ Entry represents, I saw that the picture is about the same, everything is connected with SoftHashMap, with Oracle connections.
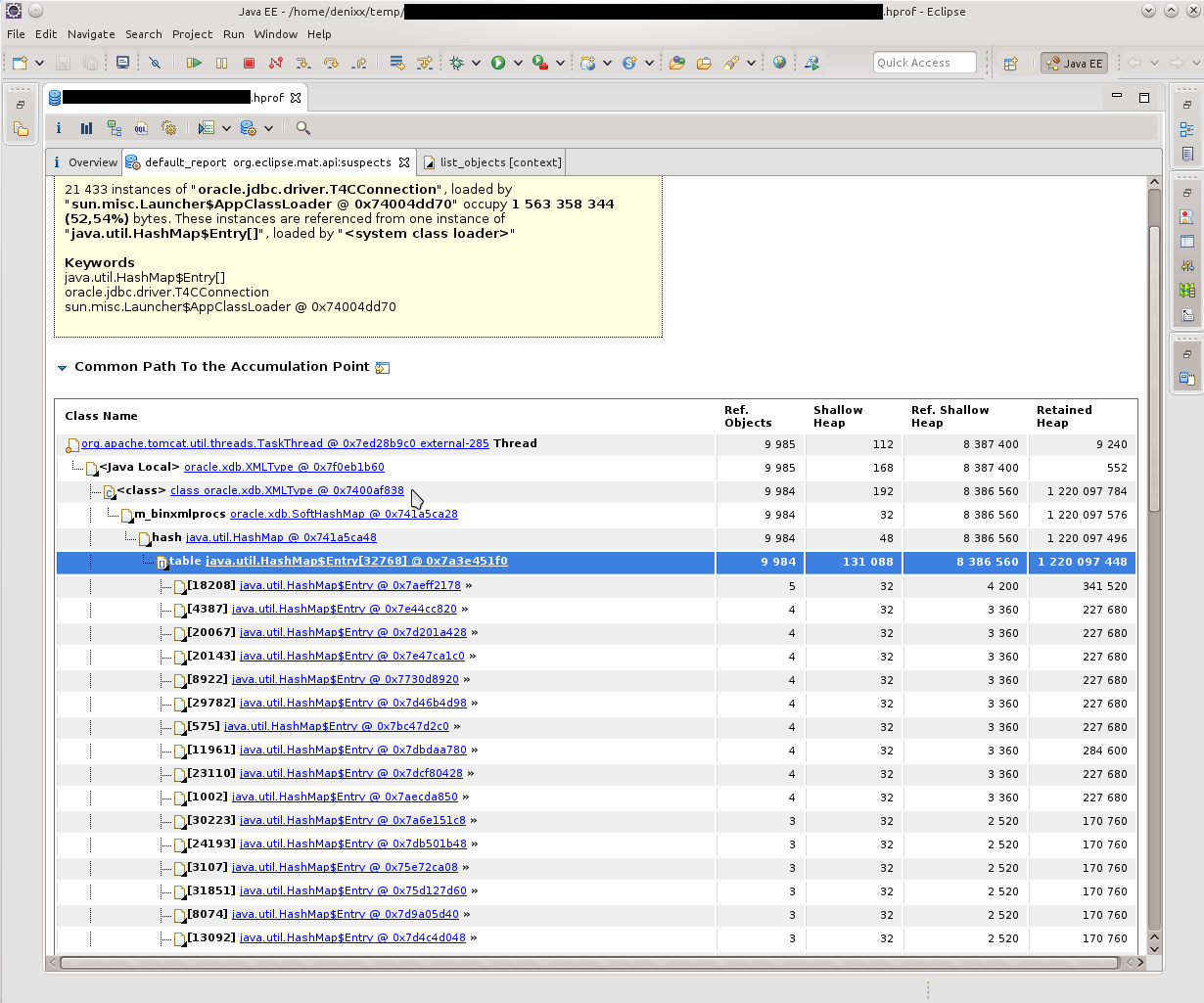
What, in fact, was confirmed by such a picture. HashMap $ Entry was just a sea, and they more or less sakummulirovalis inside oracle.xdb.SoftHashMap.
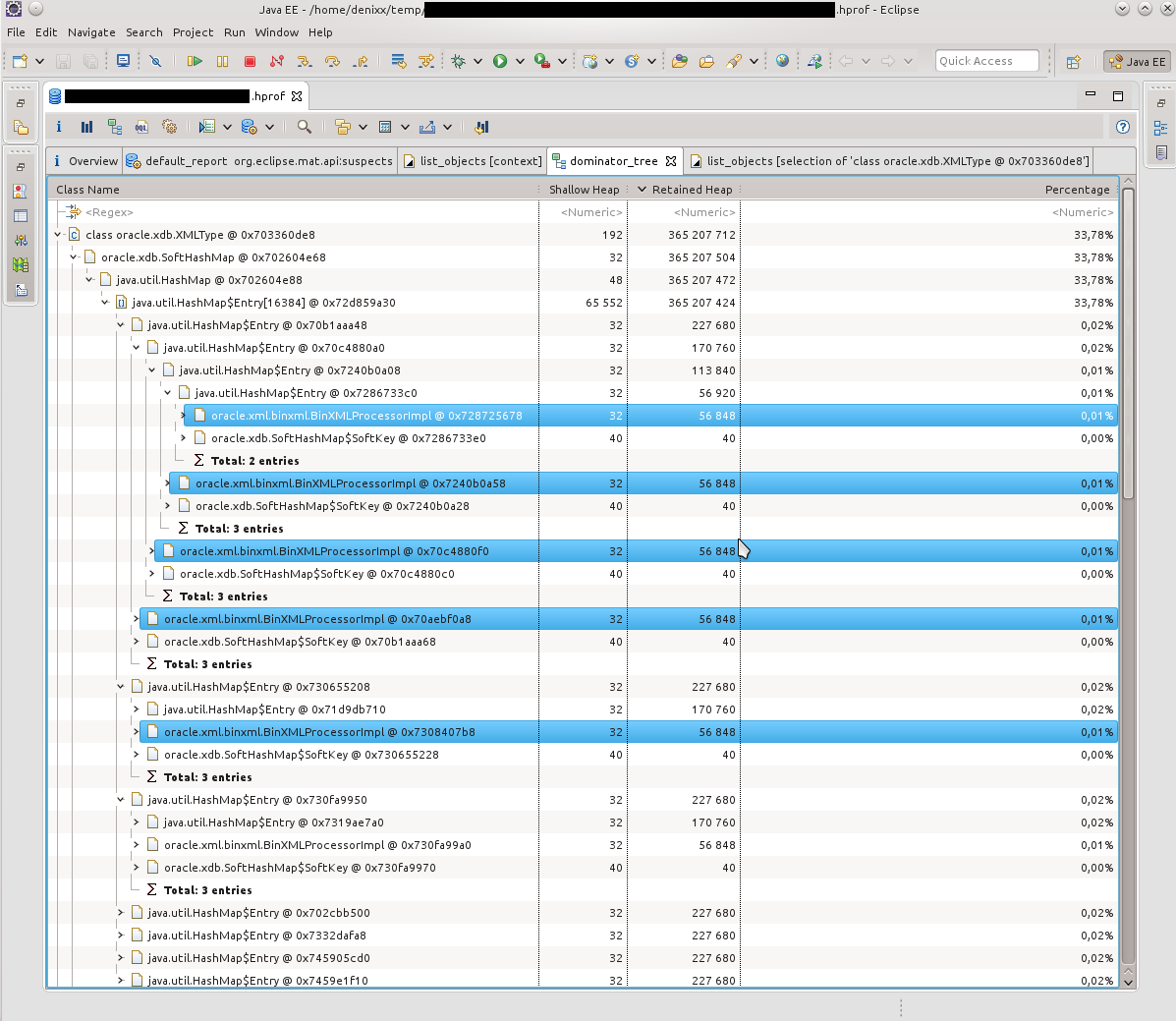
In the next dump, the picture was about the same. According to the Dominator Tree, it was obvious that inside each Entry there is a heavy BinXmlProcessorImpl.
- = - = -
If we consider that at that moment I was not strong in what xdb is and how it is related to XML, then, somewhat confused, I decided that it would be necessary to google it, maybe someone already knows that with all this needs to be done. And the flair did not deceive, on request "oracle.xdb.SoftHashMap T4CConnection" was found
times piotr.bzdyl.net/2014/07/memory-leak-in-oracle-softhashmap.html
and two leakfromjavaheap.blogspot.com/2014/02/memory-leak-detection-in-real-life.html
Having established that there is still a jamb at Orakla, the matter remained for small.
I asked the database administrator to look at the information on the detected problem:
Here is a description of the fix: updates.oracle.com/Orion/Services/download?type=readme&aru=18629243 (access requires Oracle accounting).
- = - = -
After applying fixes, instances of our application have been living for a month, and so far without excesses * tapped the tree * * spat over the left shoulder *
Successes you in search!
Some lyrics
Today, 2015-03-21, I decided to do half the work, and still start writing an article about how to start to understand what to do with OOM, and generally learn how to pick heap-dumps ( I’ll just call them dumps for ease of speech. I’ll also try to avoid Anglicisms where possible).
The amount of “work” I have planned on writing this article seems to me not a one-day, and therefore the article should appear onlya couple of weeks later a day.
The amount of “work” I have planned on writing this article seems to me not a one-day, and therefore the article should appear only
In this article I will try to chew on what to do with dumps in Java, how to understand the reason or get closer to the cause of OOM, look at the tools for analyzing dumps, the tool (one, yes) for monitoring the hip, and in general go into this matter for common development . Such tools as JVisualVM (I will consider some plug-ins to it and OQL Console), Eclipse Memory Analyzing Tool are investigated.
I have written a lot, but I hope that everything is only in business :)
Prehistory
First you need to understand how OOM arises. Someone may not yet know.
Imagine that there is some upper limit of the RAM for the application. Let it be gigabytes of RAM.
In itself, the occurrence of OOM in one of the threads does not mean that it is this thread that “devoured” all the free memory, and in general does not mean that the particular piece of code that led to the OOM is to blame for this.
The situation is quite normal when some kind of flow was engaged in something, eating memory, “got busy” with this to the state “a little more, and I would burst”, and completed the execution, pausing. At that time, some other thread decided to request some more memory for its little work, the garbage collector tried, of course, but I did not find any garbage in my memory. In this case, just the OOM, which is not related to the source of the problem, occurs when the glass flow shows the wrong cause of the application crash.
There is another option. For about a week, I explored how to improve the lives of a couple of our applications so that they stop being unstable. And another week or two spent on it in order to bring them in order. In total, a couple of weeks of time, which stretched for a month and a half, because I was engaged not only in these problems.
From the found: a third-party library, and, of course, some unaccounted things in calls to stored procedures.
In one application, the symptoms were as follows: depending on the load on the service, it could fall in a day, and could in two. If you monitor the state of the memory, it was clear that the application gradually gained "size", and at a certain moment it simply went down.
With another application is somewhat more interesting. It may behave well for a long time, and could stop responding 10 minutes after the reboot, or suddenly fall down, devouring all the free memory (I can already see it, watching it). And after updating the version, when the Tomcat version was changed from 7th to 8th, and the JRE, it suddenly on one of Fridays (having worked before that, as many as 2 weeks) started doing such things that it was embarrassing to admit it. :)
In both stories, dumps turned out to be very useful, thanks to them they managed to find all the causes of falls, making friends with tools like JVisualVM (I’ll call it JVVM), Eclipse Memory Analyzing Tool (MAT) and OQL (maybe I don’t know how to properly prepare it). MAT, but it turned out to be easier for me to make friends with the implementation of OQL in the JVVM).
You also need a free RAM in order to download dumps. Its volume should be commensurate with the size of the dump being opened.
')
Start
So, I will begin to slowly reveal the cards, and I will begin with the JVVM.
This tool in conjunction with jstatd and jmx allows you to remotely monitor the life of an application on a server: Heap, processor, PermGen, the number of threads and classes, the activity of threads, allows profiling.
JVVM is also expandable, and I didn’t fail to take advantage of this opportunity by installing some plugins that allowed a lot more things, for example, to monitor and interact with MBeans, watch the details of the hip, keep a long look at the application, holding much more period of metrics than the hour provided by the Monitor tab.
Here is a set of installed plugins.
Visual GC (VGC) allows you to see the metrics associated with the heap.
Learn more about what hip is made of in our Java.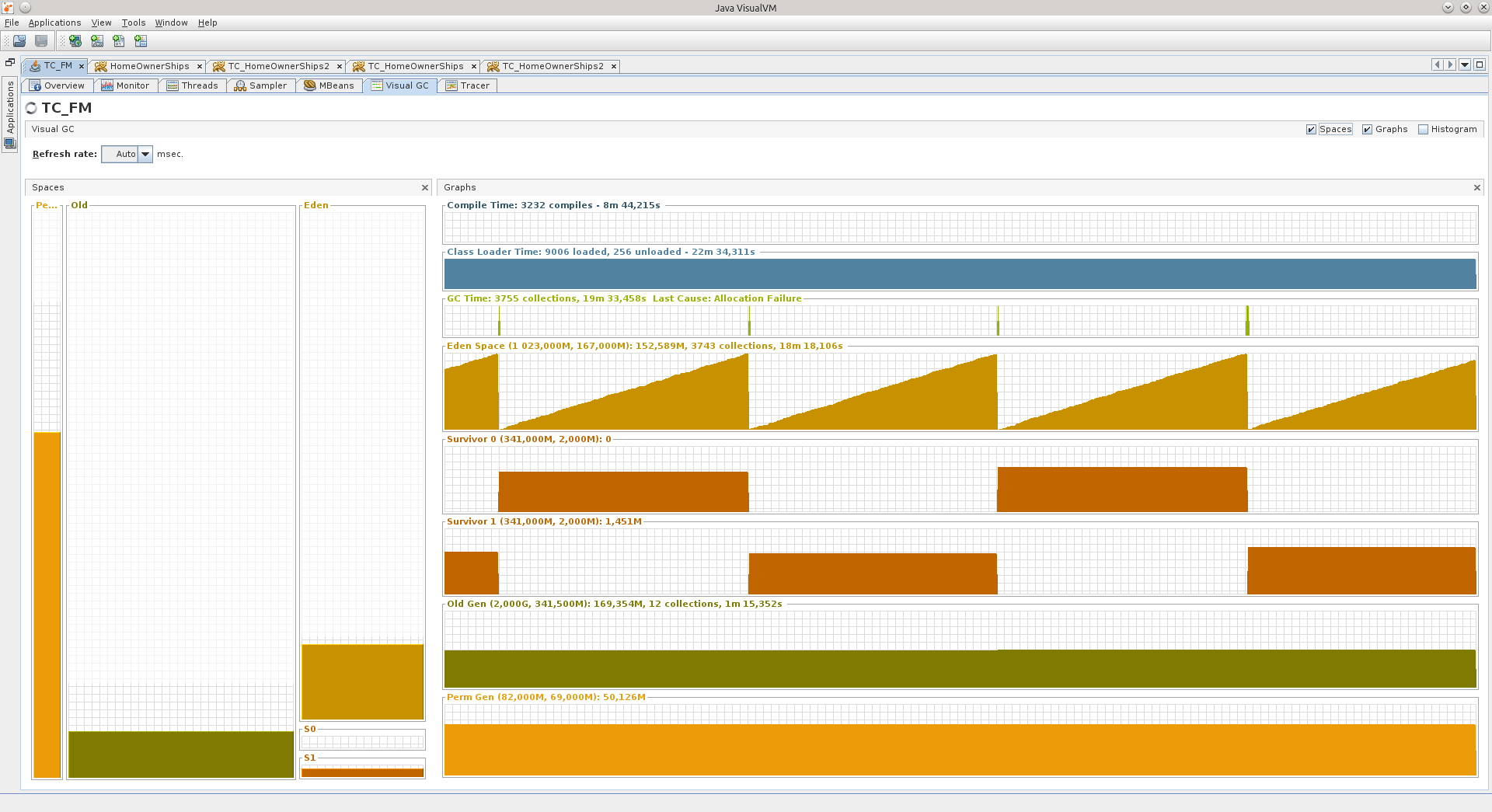
Here are two screenshots of the VGC tab that show how two different applications behave.
On the left, you can see the heap sections such as Perm Gen, Old Gen, Survivor 0, Survivor 1, and Eden Space.
All these components are areas in the RAM, into which the objects are added.
PermGen - Permanent Generation is a JVM memory area for storing descriptions of Java classes and some additional data.
The Old Gen is a memory area for fairly old objects that have experienced several shifts from place to place in Survivor-areas, and at the time of some regular transfusion they fall into the area of “old” objects.
Survivor 0 and 1 are areas in which objects that, after creating an object in Eden Space, survived its cleaning, that is, did not become rubbish at the time when Eden Space started cleaning with Garbage Collector (GC). Each time you start Eden Space cleaning, objects from the currently active Survivor are transferred to the passive, plus new ones are added, and after that the Survivors change their status, the passive becomes active and the active passive.
Eden Space is the memory area in which new objects are spawned. If there is not enough memory in this area, the GC cycle starts.
Each of these areas can be adjusted in size while the application is running by the virtual machine itself.
If you specify -Xmx in 2 gigabytes, for example, this does not mean that all 2 gigabytes will be immediately occupied (if you do not immediately start something actively eaten memory, of course). The virtual machine will first try to keep itself "in check."
The third screenshot shows the inactive stage of the application, which is not used at the weekend - Eden grows evenly, Survivors are shifted at regular intervals, Old practically does not grow. The application has worked for more than 90 hours, and in principle the JVM believes that the application does not need too much, about 540 MB.
There are peak situations where a virtual machine even allocates much more memory for the hip, but I think these are some other “unrecognized” ones, which I will discuss in more detail below, or maybe the virtual machine allocated more memory for Eden, for example so that the objects in it have time to become trash before the next cleaning cycle.
The areas that I marked in red in the next screenshot are just the growth of Old, when some objects do not have time to become garbage to be removed from memory earlier, and still get into Old. The blue patch is an exception. Over the red areas you can see the comb - this is what Eden behaves like.
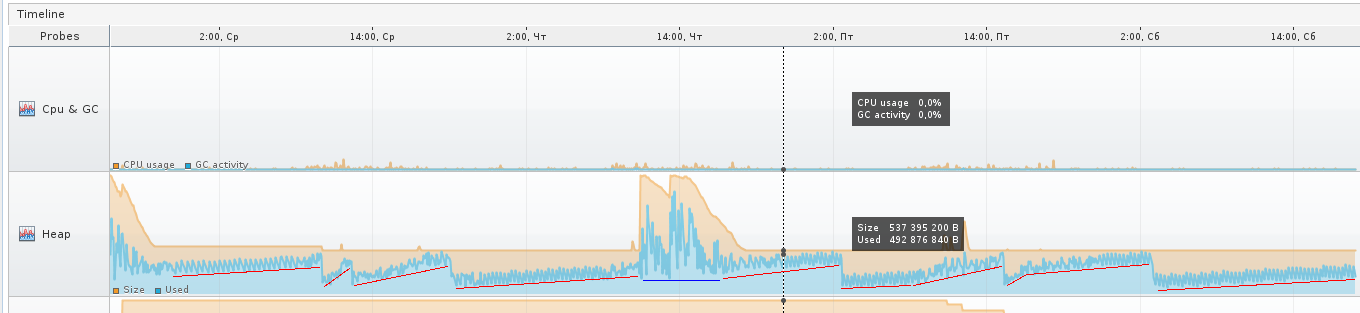
Throughout the blue area, the virtual machine most likely decided that it was necessary to increase the size of the Eden-region, because when you increase the scale in Tracer, it is clear that the GC stopped “dividing” and such small oscillations as before, now no, the oscillations became slow and rare.
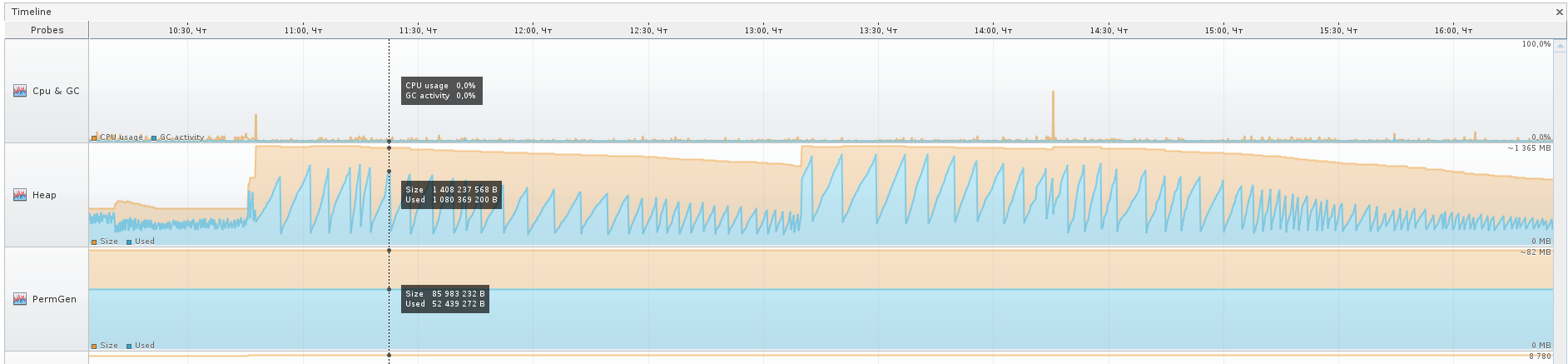
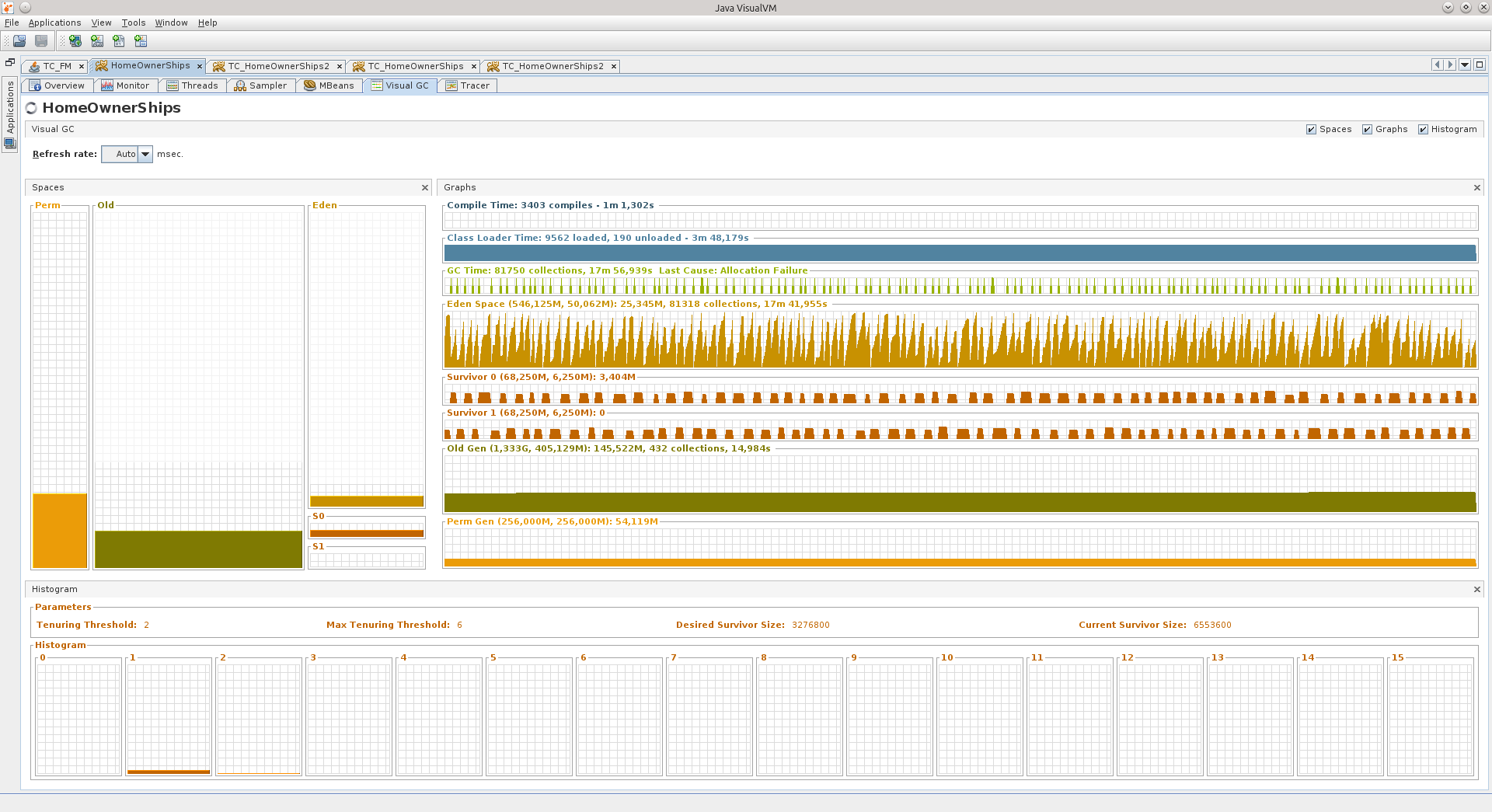
Let's move to the second application:
In it, Eden reminds me of a level from Mortal Kombat, a spiked arena. It was such, it seems ... And the Graph GC - spikes from NFS Hot Pursuit, here they are, flat yet.
The numbers to the right of the area names indicate:
1) that Eden has a size of 50 megabytes, and what is drawn at the end of the graph, the last of the current values is 25 megabytes. In total, it can grow up to 546 megabytes.
2) that Old can grow up to 1.333 gigabytes, now occupies 405 MB, and is scored at 145.5 MB.
Also for Survivor-areas and Perm Gen.
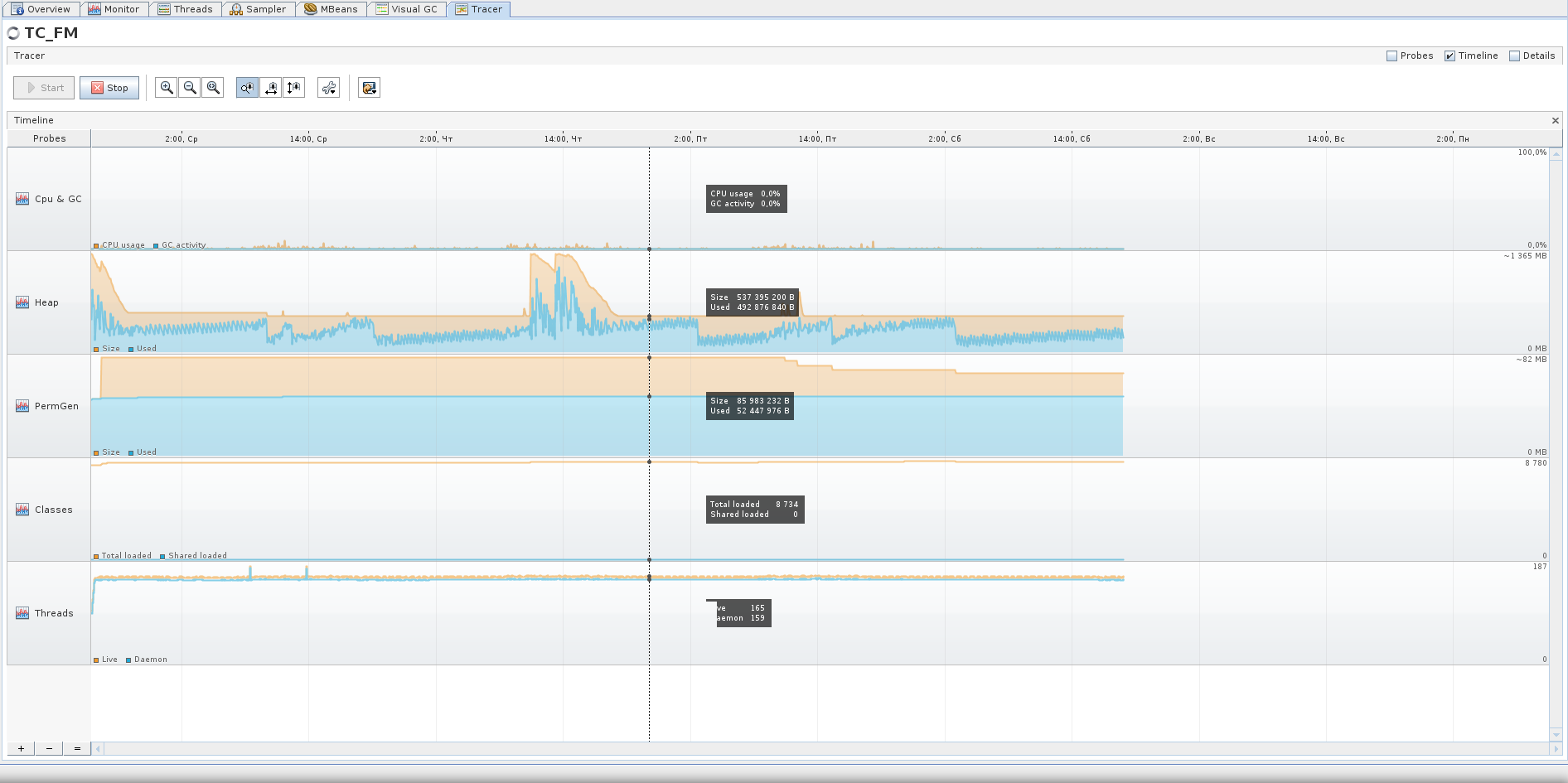
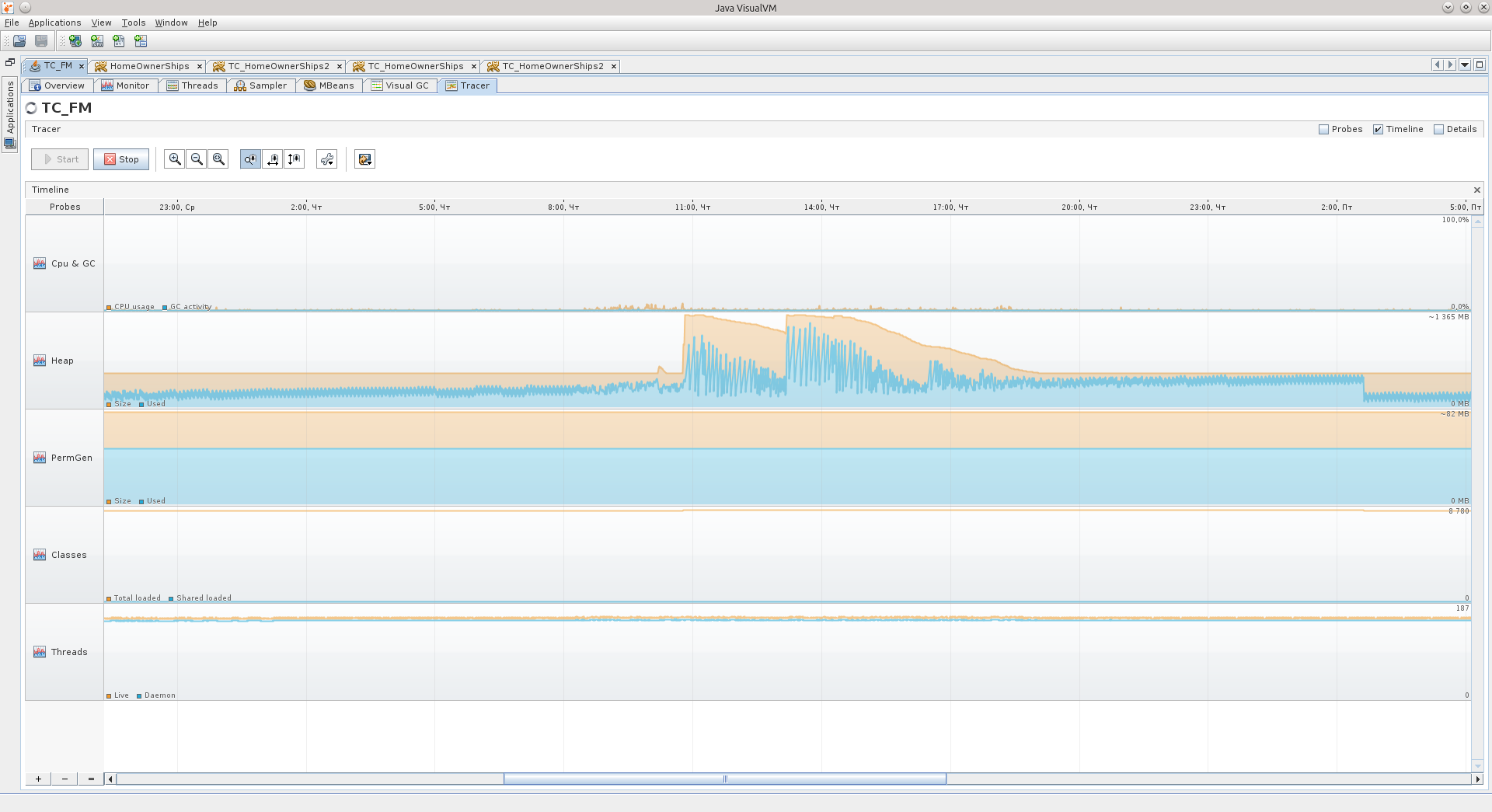
For comparison - here you have the Tracer-schedule for 75 hours of the second application, I think you can draw some conclusions from it. For example, that the active phase of this application is from 8:30 to 17:30 on weekdays, and that even on the weekend it also works :)

If you suddenly see in your application that the Old-area is full - try to just wait until it overflows, most likely it is already filled with garbage.
Garbage is objects that are not actively referenced from other objects, or whole complexes of such objects (for example, some kind of “cloud” of interrelated objects can become garbage, if a set of links points only to objects inside this “cloud”, and neither one object in this “cloud” nothing refers to “outside”).
It was a brief retelling of what I learned about the structure of the hip during the time while I was googling.
Here are two screenshots of the VGC tab that show how two different applications behave.
On the left, you can see the heap sections such as Perm Gen, Old Gen, Survivor 0, Survivor 1, and Eden Space.
All these components are areas in the RAM, into which the objects are added.
PermGen - Permanent Generation is a JVM memory area for storing descriptions of Java classes and some additional data.
The Old Gen is a memory area for fairly old objects that have experienced several shifts from place to place in Survivor-areas, and at the time of some regular transfusion they fall into the area of “old” objects.
Survivor 0 and 1 are areas in which objects that, after creating an object in Eden Space, survived its cleaning, that is, did not become rubbish at the time when Eden Space started cleaning with Garbage Collector (GC). Each time you start Eden Space cleaning, objects from the currently active Survivor are transferred to the passive, plus new ones are added, and after that the Survivors change their status, the passive becomes active and the active passive.
Eden Space is the memory area in which new objects are spawned. If there is not enough memory in this area, the GC cycle starts.
Each of these areas can be adjusted in size while the application is running by the virtual machine itself.
If you specify -Xmx in 2 gigabytes, for example, this does not mean that all 2 gigabytes will be immediately occupied (if you do not immediately start something actively eaten memory, of course). The virtual machine will first try to keep itself "in check."
The third screenshot shows the inactive stage of the application, which is not used at the weekend - Eden grows evenly, Survivors are shifted at regular intervals, Old practically does not grow. The application has worked for more than 90 hours, and in principle the JVM believes that the application does not need too much, about 540 MB.
There are peak situations where a virtual machine even allocates much more memory for the hip, but I think these are some other “unrecognized” ones, which I will discuss in more detail below, or maybe the virtual machine allocated more memory for Eden, for example so that the objects in it have time to become trash before the next cleaning cycle.
The areas that I marked in red in the next screenshot are just the growth of Old, when some objects do not have time to become garbage to be removed from memory earlier, and still get into Old. The blue patch is an exception. Over the red areas you can see the comb - this is what Eden behaves like.
Throughout the blue area, the virtual machine most likely decided that it was necessary to increase the size of the Eden-region, because when you increase the scale in Tracer, it is clear that the GC stopped “dividing” and such small oscillations as before, now no, the oscillations became slow and rare.
Let's move to the second application:
In it, Eden reminds me of a level from Mortal Kombat, a spiked arena. It was such, it seems ... And the Graph GC - spikes from NFS Hot Pursuit, here they are, flat yet.
The numbers to the right of the area names indicate:
1) that Eden has a size of 50 megabytes, and what is drawn at the end of the graph, the last of the current values is 25 megabytes. In total, it can grow up to 546 megabytes.
2) that Old can grow up to 1.333 gigabytes, now occupies 405 MB, and is scored at 145.5 MB.
Also for Survivor-areas and Perm Gen.
For comparison - here you have the Tracer-schedule for 75 hours of the second application, I think you can draw some conclusions from it. For example, that the active phase of this application is from 8:30 to 17:30 on weekdays, and that even on the weekend it also works :)
If you suddenly see in your application that the Old-area is full - try to just wait until it overflows, most likely it is already filled with garbage.
Garbage is objects that are not actively referenced from other objects, or whole complexes of such objects (for example, some kind of “cloud” of interrelated objects can become garbage, if a set of links points only to objects inside this “cloud”, and neither one object in this “cloud” nothing refers to “outside”).
It was a brief retelling of what I learned about the structure of the hip during the time while I was googling.
Prerequisites
So, two things happened right away:
1) after switching to newer libraries / tomkety / java on one of Fridays, the application, which I have been running for a long time, suddenly began to behave badly two weeks after the exhibit.
2) I was given a refactoring project, which also behaved until some time is not very good.
I don’t remember exactly in what order these events took place, but after the “Black Friday” I decided to finally deal with memory dumps in more detail, so that it would no longer be a black box for me. I warn you that I could already forget some details.
On the first occasion, the symptoms were as follows: all the threads responsible for processing requests were burned out, only 11 connections were open to the database, and they did not say that they were used, the base said that they were able to recv sleep, that is, they were waiting for them will start to use.
After the reboot, the application came to life, but it could not live long, on the evening of the same Friday it lived the longest, but after the end of the working day it fell again. The picture was always the same: 11 connections to the base, and only one, it seems, is doing something.
Memory, by the way, was at a minimum. I cannot say that OOM led me to search for causes, but the knowledge gained in searching for causes allowed me to begin an active struggle against OOM.
When I opened the dump in JVVM, it was difficult to understand anything from it.
Subconsciousness suggested that the reason was somewhere in the work with the base.
A search among the classes told me that there are already 29 DataSource in memory, although there should be a total of 7.
This gave me a point from which it would be possible to push off, to begin to unravel the tangle.
Oql
There was no time to sit around pereklitsyvat in the viewer, and my attention was finally attracted by the OQL Console tab, I thought that here it is, the moment of truth - either I will start using it to its fullest, or I will score on all of this.
Before starting, of course, Google was asked a question, and he kindly provided a cheat sheet on how to use OQL in the JVVM: http://visualvm.java.net/oqlhelp.html
At first, the abundance of compressed information disheartened me, but after using Google-Fu, the following OQL query appeared:
select {instance: x, uri: x.url.toString(), connPool: x.connectionPool} from org.apache.tomcat.dbcp.dbcp2.BasicDataSource x where x.url != null && x.url.toString() == "jdbc:sybase:Tds::/" This is a revised and updated final version of this request :)
The result can be seen in the screenshot:
After clicking on BasicDataSource # 7 we get to the desired object in the Instances tab:
After some time, it dawned on me that there is one incompatibility with the configuration specified in the Resource tag in the volume in the /conf/context.xml file. Indeed, in the dump, the maxTotal parameter is set to 8, while we specified maxActive equal to 20 ...
It was then that it began to come to me that the application lived with the wrong configuration of the connection pool all these two weeks!
For the sake of brevity, I’ll write here that if you use Tomcat and DBCP as a connection pool, DBCP version 1.4 is used in the 7th volume, and DBCP 2.0, which I later found out, decided to rename some of them in the 8th volume. options! And about maxTotal in general on the main page of the site is written :)
http://commons.apache.org/proper/commons-dbcp/
"Users should also be aware of this option."
The reasons
I called them in every way, calmed down, and decided to figure it out.
As it turned out, the BasicDataSourceFactory class simply simply receives this very Resource, looks at whether it has the necessary parameters, and takes them into the generated BasicDataSource object, silently ignoring everything that it does not interest.
So it happened that they renamed the most fun parameters, maxActive => maxTotal, maxWait => maxWaitMillis, removeAbandoned => removeAbandonedOnBorrow & removeAbandonedOnMaintenance.
By default, maxTotal, as before, is equal to 8; removeAbandonedOnBorrow, removeAbandonedOnMaintenance = false, maxWaitMillis is set to "wait forever."
It turned out that the pool was configured with a minimum number of connections; if free connections end - the application silently waits for them to be released; and finishes all silence in the logs about the "abandoned" connections - something that could immediately show exactly where the
It is now the entire mosaic has developed quickly, and this knowledge has been extracted longer.
“It shouldn’t be like that,” I decided, and patched down the patch ( https://issues.apache.org/jira/browse/DBCP-435 , put it in http://svn.apache.org/viewvc/commons/proper/ dbcp / tags / DBCP_2_1 / src / main / java / org / apache / commons / dbcp2 / BasicDataSourceFactory.java? view = markup ), the patch was accepted and entered into the version of DBCP 2.1. When and if Tomcat 8 updates the DBCP version to 2.1+, I think that admins will open many secrets about their configuration Resource :)
Regarding this incident, I just had to tell one more detail - what the heck in the dump was already 29 DataSource instead of just 7 pieces. The answer lies in the banal arithmetic, 7 * 4 = 28 + 1 = 29.
More details about why you can not throw the Resource in the file /conf/context.xml tomket
Each subfolder inside the / webapps folder has its own copy of /conf/context.xml, which means that the number of Resource that is there should be multiplied by the number of applications to get the total number of pools raised in the tomkette memory. To the question “what to do in this case?” The answer will be this: you need to move all the Resource declarations from /conf/context.xml to the /conf/server.xml file, inside the GlobalNamingResources tag. There you can find one, available by default, Resource name = "UserDatabase", here below it and place your pools. Next, you need to use the ResourceLink tag, it is desirable to put it in the application, in the project, inside the file /META-INF/context.xml - this is the so-called "per-app context", that is, the context that contains the component declarations that will be available only for deployable application. In ResourceLink, the name and global parameters can contain the same values.
For example:
This link will grab from the globally declared DataSource resource named "jdbc / MyDB", and the resource will be available to the application.
ResourceLink can (but does not have to) be placed in /conf/context.xml, but in this case all applications will have access to globally declared resources, even if there are not so many copies of the DataSource in memory.
You can see the details here: GlobalNamingResources - http://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Environment_Entries , ResourceLink - http://tomcat.apache.org/tomcat-7.0-doc /config/globalresources.html#Resource_Links , also see this page: tomcat.apache.org/tomcat-7.0-doc/config/context.html .
For TC8, the same pages: http://tomcat.apache.org/tomcat-8.0-doc/config/globalresources.html and http://tomcat.apache.org/tomcat-8.0-doc/config/context.html .
For example:
<ResourceLink name="jdbc/MyDB" global="jdbc/MyDB" type="javax.sql.DataSource"/> This link will grab from the globally declared DataSource resource named "jdbc / MyDB", and the resource will be available to the application.
ResourceLink can (but does not have to) be placed in /conf/context.xml, but in this case all applications will have access to globally declared resources, even if there are not so many copies of the DataSource in memory.
You can see the details here: GlobalNamingResources - http://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Environment_Entries , ResourceLink - http://tomcat.apache.org/tomcat-7.0-doc /config/globalresources.html#Resource_Links , also see this page: tomcat.apache.org/tomcat-7.0-doc/config/context.html .
For TC8, the same pages: http://tomcat.apache.org/tomcat-8.0-doc/config/globalresources.html and http://tomcat.apache.org/tomcat-8.0-doc/config/context.html .
After that, everything became clear: 11 connections were because in one, active DataSource 8 connections were eaten (maxTotal = 8), and another by minIdle = 1 in three other unused DataSource copies.
That Friday we rolled back to Tomcat 7, which lay side by side, and waited to get rid of it, it gave time to calmly figure everything out.
Plus, later, on TC7, there was a leak of connections, thanks to removeAbandoned + logAbandoned. DBCP happily reported to catalina.log that
"org.apache.tomcat.dbcp.dbcp.AbandonedTrace$AbandonedObjectException: DBCP object created 2015-02-10 09:34:20 by the following code was never closed: at org.apache.tomcat.dbcp.dbcp.AbandonedTrace.setStackTrace(AbandonedTrace.java:139) at org.apache.tomcat.dbcp.dbcp.AbandonedObjectPool.borrowObject(AbandonedObjectPool.java:81) at org.apache.tomcat.dbcp.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:106) at org.apache.tomcat.dbcp.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044) at ...getConnection(.java:100500) at ...(.java:100800) at ...2(.java:100700) at ...1(.java:100600) ..." This one here is a bad Bad Method has Connection con in the signature, but inside was the construction “con = getConnection ();”, which became a stumbling block. Superclass is rarely called, so it was not paid attention to him for so long. Plus, the calls did not happen during the working day, as I understand it, so even if something was hanging, no one was concerned about it. And at TusamPayutnitsa just the stars came together, the head of the department of the customer needed to see something :)
Appendix №2
As for the "event number 2" - they gave me the application for refactoring, and it immediately dared to crash on the servers.
Dumps came to me already, and I decided to try to pick them up too.
Opened a dump in the JVVM, and "something desponded":
What can be understood from Object [], and even in such numbers?
(An experienced person, of course, already saw the reason, right? :))
So, the thought “I didn’t really have done it before, because I probably already have a finished tool!” So I came across this question on StackOverflow: http://stackoverflow.com/questions/2064427/recommendations-for-a-heap-analysis-tool-for-java .
Having looked at the proposed options, I decided to stop at MAT, I had to try at least something, and this is an open project, and even with a much larger number of votes than the other points.
Eclipse Memory Analyzing Tool
So MAT.
I recommend downloading the latest version of Eclipse, and installing the MAT there, because the independent version of the MAT behaves badly, there is some kind of devilry with the dialogues, they do not see the contents in the fields. Maybe someone will tell in the comments what he is missing, but I solved the problem by installing the MAT in Eclipse.
Having opened a dump in MAT, I requested the execution of the Leak Suspects Report.
Surprise knew no bounds, to be honest.
1.2 gigabytes weigh connections to the base.
Each connection weighs from 17 to 81 megabytes.
Well, another "little" pool itself.
The Dominator Tree report helped to visualize the problem:
The cause of all the drops was the kilometers of SQLWarning, the base tried hard to make it clear that “010SK: Database cannot set connection option SET_READONLY_TRUE.” And the BoneCP connection pool does not clear SQLWarning after it is released and the connections are returned to the pool (maybe this is where- Can I configure it? Tell me, if anyone knows).
Google said that this problem with Sybase ASE has been known since 2004: https://forum.hibernate.org/viewtopic.php?f=1&t=932731
In short, “Sybase ASE doesn't require any optimizations, therefore setReadOnly () produces a SQLWarning.”, And these solutions still work.
However, this is not exactly the solution to the problem, because the solution to the problem is when all the database notifications are cleared when the connection to the pool returns, because no one will ever need them.
And DBCP can do it: http://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_1_4/src/java/org/apache/commons/dbcp/PoolableConnectionFactory.java?view=markup , method passivateObject (Object obj), in line 687 you can see conn.clearWarnings () ;, this call saves you from kilometers of SQLWarning in memory.
I learned about this from the ticket: https://issues.apache.org/jira/browse/DBCP-102
Also, I was prompted about such a ticket in the bug tracker: https://issues.apache.org/jira/browse/DBCP-234 , but it already concerns the version of DBCP 2.0.
As a result, I transferred the application to DBCP (albeit version 1.4). Let the load on the service and rather big (from 800 to 2k requests per minute), but still the application behaves well, and this is important. And I did it right, because BoneCP has not been supported for five months already, however, HikariCP came to replace it. It will be necessary to see how things are in his source ...
Fighting OOM
Impressed by how MAT laid everything out for me, I decided not to throw this effective tool, and later it came in handy for me, because the first application still had all sorts of “unrecognized” things unaccounted for in the application code or stored procedure code that sometimes result to the fact that the application glues fins. I still catch them.
Armed with both tools, I began to pick each sent dump in search of the reasons for the fall of the OOM.
As a rule, all OOM led me to TaskThread.
And if you click on the See stacktrace sign, then yes, it will be just a banal case, when some thread suddenly fell down while trying to marshal the result of your work.
However, here nothing indicates the cause of the OOM, here only the result. Find the reason for me so far, because of the ignorance of all the OQL magic in MAT, it is JVVM that helps.
Download the dump there, and try to find the cause!
I should, of course, look for exactly the things associated with the database, and therefore we will first try to see if there are statements in memory.
Two SybCallableStatement, and one SybPreparedStatement.
I think that the matter will become more complicated if the statements are much more, but having slightly edited one of the following queries, specifying the necessary conditions in where, I think everything will work out for you. Plus, of course, it’s worth a good look at MAT, what kind of results a stream is trying to stream, which object, and it will become clearer which particular Statement should be searched for.
select { instance: x, stmtQuery: x._query.toString(), params: map(x._paramMgr._params, function(obj1) { if (obj1 != null) { if (obj1._parameterAsAString != null) { return '\''+obj1._parameterAsAString.toString()+'\''; } else { return "null"; } } else { return "null"; } }) } from com.sybase.jdbc4.jdbc.SybCallableStatement x where x._query != null This is not the "internal" calls.
select { instance: x, stmtQuery: x._query.toString(), params: map(x._paramMgr._params, function(obj1) { if (obj1 != null) { if (obj1._parameterAsAString != null) { return '\''+obj1._parameterAsAString.toString()+'\''; } else { return "null"; } } else { return "null"; } }) } from com.sybase.jdbc4.jdbc.SybPreparedStatement x where x._query != null And here is the game!
For the purity of the experiment, you can throw the same query in your favorite DB-IDE, and it will work for a very long time, and if you dig into the depths of the storehouse, it will be clear that there simply 2 million lines are selected from the base that does not belong to us with such parameters. These two million even intermeddle in the memory of the application, but the attempt to marshal the result becomes fatal for the application. Such a hara-kiri. :)
In this case, the GC diligently removes all the evidence, but it did not save it, yet the source remained in the memory, and he will be punished.
For some reason, after all this story, I felt that I was still a loser.
Parting
That ended my story, I hope you enjoyed it :)
I would like to thank my boss, he gave me time to figure it all out. I think this new knowledge is very useful.
Thanks to the girls from Scorini for the invariably delicious coffee, but they will not read these words of gratitude - I even doubt that they know about the existence of Habrahabr :)
I would like to see in the comments even more useful information and additions, I will be very grateful.
I think it's time to read the documentation for the MAT ...
UPD1 : Yes, I forgot to tell you about such useful things as creating memory dumps.
docs.oracle.com/javase/7/docs/webnotes/tsg/TSG-VM/html/clopts.html#gbzrr
Options
-XX: + HeapDumpOnOutOfMemoryError
-XX: HeapDumpPath = / disk2 / dumps
very useful for generating dumps when an application crashes using OutOfMemoryError,
and there is also the possibility to remove a memory dump from the application “profitably”, in the middle of its work.
For this there is a utility jmap.
Example call for Windows:
"C: \ install \ PSTools \ PsExec.exe" -s "C: \ Program Files \ Java \ jdk1.7.0_55 \ bin \ jmap.exe" -dump: live, format = b, file = C: \ dump. hprof 3440
the last parameter is the PID of the java process. The PsExec application from the PSTools suite allows you to run other applications with system privileges, for this the "-s" key is used. The live option is useful so that before saving the dump, call the GC, clearing the memory of garbage. In the case when an OOM occurs, there is no need to clean the memory, there is no more garbage left, so do not look for how to set the live option in case of an OOM.
UPD2 (2015-10-28) | Case number
(It was decided to add it here as an update, and not to cut a new article about the same):
Another interesting case, but already with the Oracle base.
One of the projects uses a feature with XML, conducts searches on the contents of a saved XML document. In general, this project sometimes made itself felt by the fact that suddenly one of the instances ceased to show signs of life.
Sensing a "good" case to practice
The first thing I saw was “you have a lot of connections left in your memory”. 21k !!! And some interesting oracle.xdb.XMLType also gave heat. “But this is Orakl!”, It turned in my head. Looking ahead I will say that yes, he is guilty.
So, we see a bunch of T4CConnection, which are in the HashMap $ Entry. Immediately I noticed that it seems like SoftHashMap, which, it seems, should mean that it should not grow to such size. But you can see the result yourself - 50-60 kilobytes in a connection, and there are really a LOT of them.
Having looked at what HashMap $ Entry represents, I saw that the picture is about the same, everything is connected with SoftHashMap, with Oracle connections.
What, in fact, was confirmed by such a picture. HashMap $ Entry was just a sea, and they more or less sakummulirovalis inside oracle.xdb.SoftHashMap.
In the next dump, the picture was about the same. According to the Dominator Tree, it was obvious that inside each Entry there is a heavy BinXmlProcessorImpl.
- = - = -
If we consider that at that moment I was not strong in what xdb is and how it is related to XML, then, somewhat confused, I decided that it would be necessary to google it, maybe someone already knows that with all this needs to be done. And the flair did not deceive, on request "oracle.xdb.SoftHashMap T4CConnection" was found
times piotr.bzdyl.net/2014/07/memory-leak-in-oracle-softhashmap.html
and two leakfromjavaheap.blogspot.com/2014/02/memory-leak-detection-in-real-life.html
Having established that there is still a jamb at Orakla, the matter remained for small.
I asked the database administrator to look at the information on the detected problem:
xxx: Keywords: SoftHashMap XMLType
yyy: Bug 17537657 Memory leak from XDB in oracle.xdb.SoftHashMap
yyy: The fix for 17537657 is first included in
12.2 (Future Release)
12.1.0.2 (Server Patch Set)
12.1.0.1.4 Database Patch Set Update
12.1.0.1 Patch 11 on Windows Platforms
yyy: nda. Description
Description
When you call getDocument () using the thin driver, or getBinXMLStream ()
memory leaks occur in the oracle.xdb.SoftHashMap class.
BinXMLProcessorImpl classes accumulate in this SoftHashMap, but are never
removed.
xxx: That's right :)
Here is a description of the fix: updates.oracle.com/Orion/Services/download?type=readme&aru=18629243 (access requires Oracle accounting).
- = - = -
After applying fixes, instances of our application have been living for a month, and so far without excesses * tapped the tree * * spat over the left shoulder *
Successes you in search!
Source: https://habr.com/ru/post/253683/
All Articles