Intel® Graphics Technology. Part III: Efficient Calculations on a Graph
In the comments to the previous post , a very important question was raised - will there be any performance gains from uploading calculations to the integrated graphics, as compared to running only on the CPU? Of course, it will, but you need to follow certain programming rules for effective computing on the GFX + CPU.
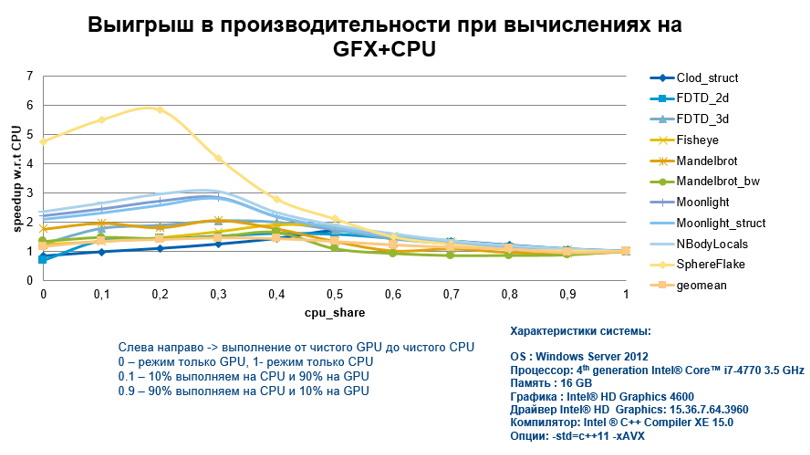
In confirmation of my words, I will immediately present the graph of acceleration obtained when performing calculations on an integrated graph, for various algorithms and with varying degrees of CPU involvement. At KDPV, we see that the gain is more than significant.
Many will say that it’s not at all clear what these algorithms are and what they did with this code to get such results.
Therefore, consider how to achieve such impressive results for effective implementation on the GFX.
To begin with, we will try to collect all the features and methods together, taking into account our knowledge of the specifics of the piece of hardware, and then proceed to the implementation of a specific example using Intel Graphics Technology. So, what to do to get high performance:
- We increase the iteration space by using nested cilk_for. As a result, we have a greater resource for parallelism and more threads on the GPU may be busy.
- For vectorization of the code (yes, for the GPU it is just as important as for the CPU), which will be offloaded using the pragma simd directive or the Intel® Cilk ™ Plus array notation.
- We use the __restrict__ and __assume_aligned () keywords so that the compiler does not create different versions of code (code paths). For example, it can generate two versions for working with aligned and non-aligned memory, which will be checked in runtime and the execution will follow the required “branch”.
- Do not forget that the pin in the pragma offload directive avoids the overhead of copying data between DRAM and card memory and allows you to use shared memory for CPU and GPU.
- We prefer to work with 4-byte elements than 1-or 2-byte elements, because gather / scatter operations with this size are much more efficient. For the case of 1.2 bytes, they are much slower.
- Even better is to avoid gather / scatter instructions. To do this, use the SoA data structure (Structure of Arrays) instead of AoS (Array of Structures). Here everything is extremely simple - it is better to store data in arrays, then memory access will be consistent and efficient.
- One of the greatest strengths of GFX is its 4 KB register file for each stream. If local variables exceed this size, you will have to work with much slower memory.
- When working with the array int buf [2048], allocated in the register file (GRF), the indexed access to the register will be performed in a loop of the form for (i = 0.2048) {... buf [i] ...}. In order to work with direct addressing, we loop the loop (loop unrolling) with the pragma unroll directive.
Now let's see how it all works. I did not take the simplest example of matrix multiplication, but modified it a little using the Cilk Plus array notation for vectorization and cache blocking optimization.
I decided to honestly change the code and see how the performance changes.
void matmul_tiled(float A[][K], float B[][N], float C[][N]) { for (int m = 0; m < M; m += TILE_M) { // iterate tile rows in the result matrix for (int n = 0; n < N; n += TILE_N) { // iterate tile columns in the result matrix // (c) Allocate current tiles for each matrix: float atile[TILE_M][TILE_K], btile[TILE_N], ctile[TILE_M][TILE_N]; ctile[:][:] = 0.0; // initialize result tile for (int k = 0; k < K; k += TILE_K) { // calculate 'dot product' of the tiles atile[:][:] = A[m:TILE_M][k:TILE_K]; // cache atile in registers; for (int tk = 0; tk < TILE_K; tk++) { // multiply the tiles btile[:] = B[k + tk][n:TILE_N]; // cache a row of matrix B tile for (int tm = 0; tm < TILE_M; tm++) { // do the multiply-add ctile[tm][:] += atile[tm][tk] * btile[:]; } } } C[m:TILE_M][n:TILE_N] = ctile[:][:]; // write the calculated tile to back memory } } } The advantages of this algorithm with block work with matrices are clear - we are trying to avoid problems with the cache, and for this we change the sizes of TILE_N, TILE_M and TILE_K. Having collected this example by the Intel compiler with optimization and matrix sizes M and K equal to 2048, and N - 4096, I launch the application. The rendering time is 5.12 seconds. In this case, we used only vectorization by means of Cilk (and, moreover, a set of SSE instructions on default). We need to implement parallelism on tasks. To do this, you can use cilk_for:
cilk_for(int m = 0; m < M; m += TILE_M) ... Reassemble the code and run it again. Expected, we get almost linear acceleration. On my system with a 2 core processor, the time was 2.689 seconds. It's time to use offload on the schedule and see what we can win in performance. So, using the pragma offload directive and adding the nested cilk_for loop, we get:
#pragma offload target(gfx) pin(A:length(M)) pin(B:length(K)) pin(C:length(M)) cilk_for(int m = 0; m < M; m += TILE_M) { cilk_for(int n = 0; n < N; n += TILE_N) { ... The offload application ran 0.439 seconds, which is pretty good. In my case, additional modifications with unroll cycles did not show a serious increase in performance. But the key role was played by the algorithm for working with matrices. The sizes TILE_M and TILE_K were chosen equal to 16, and TILE_N - 32. Thus the sizeof (atile) was 1 KB, the sizeof (btile) - 128 B, and the sizeof (ctile) - 2 KB. I think it is clear why I did all this. That's right, the total size of 1 KB + 2 KB + 128 B turned out to be less than 4 KB, which means we worked with the fastest memory (register file) available to each stream on the GFX.
By the way, the usual algorithm worked much longer (about 1.6 seconds).
For the sake of experiment, I turned on the generation of AVX instructions and sped up a few more on the CPU only to 4.098 seconds, and the Cilk version of the tasks to 1.784. However, it was the offload on the GFX that made it possible to significantly increase performance.
I was not lazy and decided to see what the VTune Amplfier XE can do in such an application.
I collected the code with debug information and launched Basic Hotspot analysis with a checkmark 'Analyze GPU usage':

It is interesting that for OpenCL there is a separate option. Having collected the profile and climbed the tabs of Vtune, I found the following information:
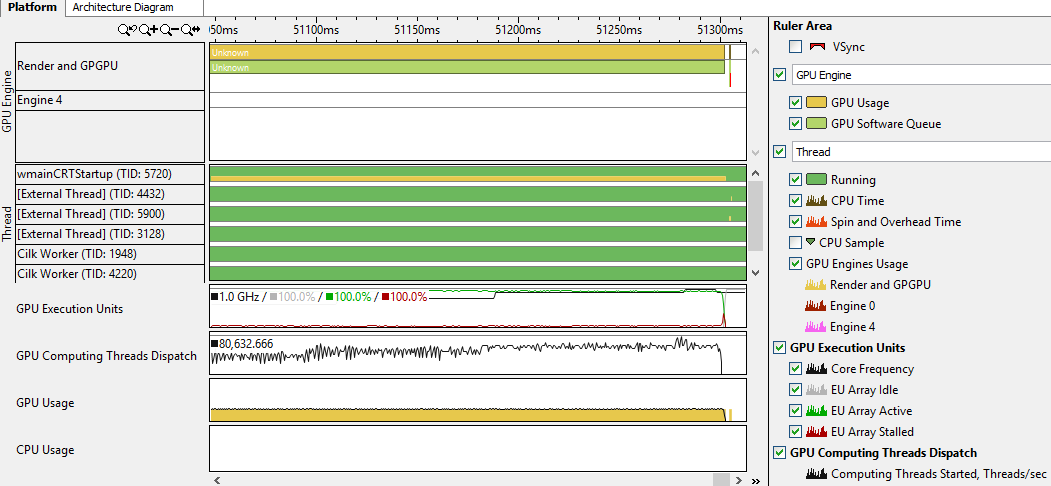
To say that I learned from this much useful, I can not. Nevertheless, I saw that the application uses the GPU, and even noticed on the timeline when the offload began. In addition, it is possible to determine how efficiently (as a percentage) all the cores on the graph (GPU EU) were used over time, and generally evaluate the use of the GPU. I think that if necessary it is worthwhile to dig a little longer, especially if the code was not written by you. Colleagues assured that you can still find a lot of useful things with VTune when working with the GPU.
As a result, it should be said that there is a gain from using offload on the graphics integrated into the processor, and it is quite substantial, subject to certain code requirements, which we talked about.
')
Source: https://habr.com/ru/post/253425/
All Articles