New Yandex.Disk sync algorithm: how not to choke 900,000 files
Yandex.Disk is one of the few Yandex services, of which desktop software is a part. And one of its most important components is the algorithm for synchronizing local files with their copy in the cloud. Recently, we had to completely change it. If the old version hardly digested even several tens of thousands of files and, moreover, did not react quickly enough to some “complex” user actions, then the new one, using the same resources, copes with hundreds of thousands of files.
In this post, I’ll tell you why it happened: what we couldn’t foresee when we thought out the first version of Yandex.Disk software, and how we created a new one.

')
First of all, about the task of synchronization. Technically speaking, it consists in having the same file set in the Yandex.Disk folder on the user's computer and in the cloud. That is, such user actions as renaming, deleting, copying, adding and modifying files should be synchronized with the cloud automatically.
Theoretically, the task may seem simple enough, but in reality we are faced with various difficult situations. For example, a person renamed a folder on his computer, we detected this and sent a command to the backend. However, none of the users waits until the backend confirms the renaming success. The person immediately opens his locally renamed folder, creates a subfolder in it, and, for example, transfers part of the files to it. We are in a situation in which it is impossible to immediately perform all the necessary synchronization operations in the cloud. First you need to wait for the completion of the first operation and only then you can continue.
The situation may become even more difficult if several users work with the same account at the same time or they have a shared folder. And this happens quite often in organizations that use Yandex.Disk. Imagine that in the previous example, at the moment when we received confirmation of the first rename from the backend, another user takes and renames this folder again. In this case, again, you cannot immediately perform the actions that the first user has already performed on his computer. The folder in which he worked locally, on the backend at this time is already called differently.
There are cases when a file on a user's computer cannot be called the same as it is called in the cloud. This can happen if the name has a character that cannot be used by the local file system, or if the user is invited to a shared folder and has his own folder with that name. In such cases, we have to use local pseudonyms and track their connection with objects in the cloud.
In the previous version of the Yandex.Disk desktop software, the tree comparison algorithm was used to search for changes. Any other solution at that time did not allow for the search for displacements and renames, since the backend did not have unique object identifiers.
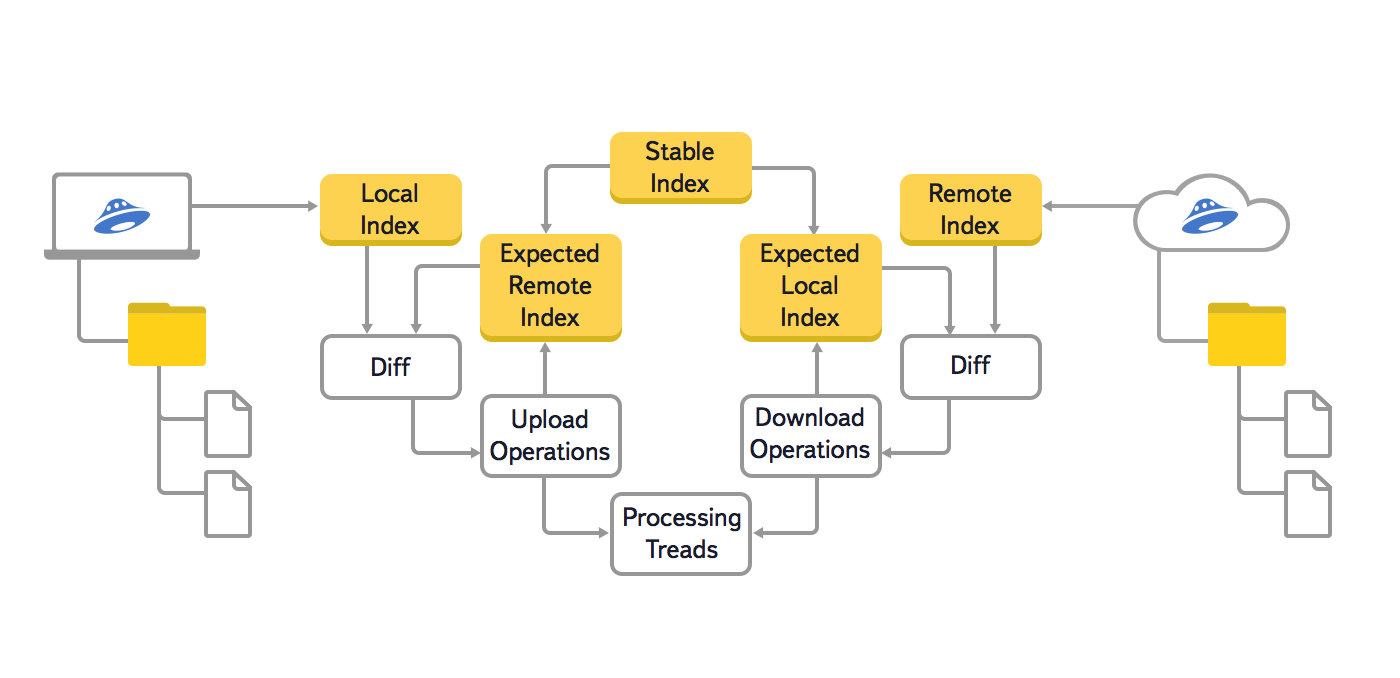
In this version of the algorithm, we used three main trees: the local (Local Index), the cloud (Remote Index) and the last synchronized (Stable Index). In addition, in order to prevent the repeated generation of already queued synchronization operations, two more auxiliary trees were used: the local expected and cloud expected (Expected Remote Index and Expected Local Index). In these auxiliary trees, the expected state of the local file system and the cloud was stored, after performing all the synchronization operations that have already been queued.
The procedure for comparing trees in the old algorithm was as follows:
The main problems of the tree comparison algorithm are high memory consumption and the need to compare the entire tree even with small changes, which led to a heavy load on the processor. During the processing of changes to even one file, the use of RAM increased by approximately 35%. Suppose a user has 20,000 files. Then, with a simple renaming of a single file of 10Kb in size, the memory consumption grew abruptly - from 116MB to 167MB.
We also wanted to increase the maximum number of files with which the user can work without problems. Several dozens and even hundreds of thousands of files may be, for example, a photographer who stores the results of photo shoots on Yandex.Disk. This task has become especially urgent when people have the opportunity to buy additional space on Yandex.Disk.
In the development, too, I wanted to change something. Debugging of the old version caused difficulties, since the data on the states of one element were in different trees.
By this time, id objects appeared on the backend, with the help of which it was possible to more effectively solve the problem of motion detection — earlier we used paths.
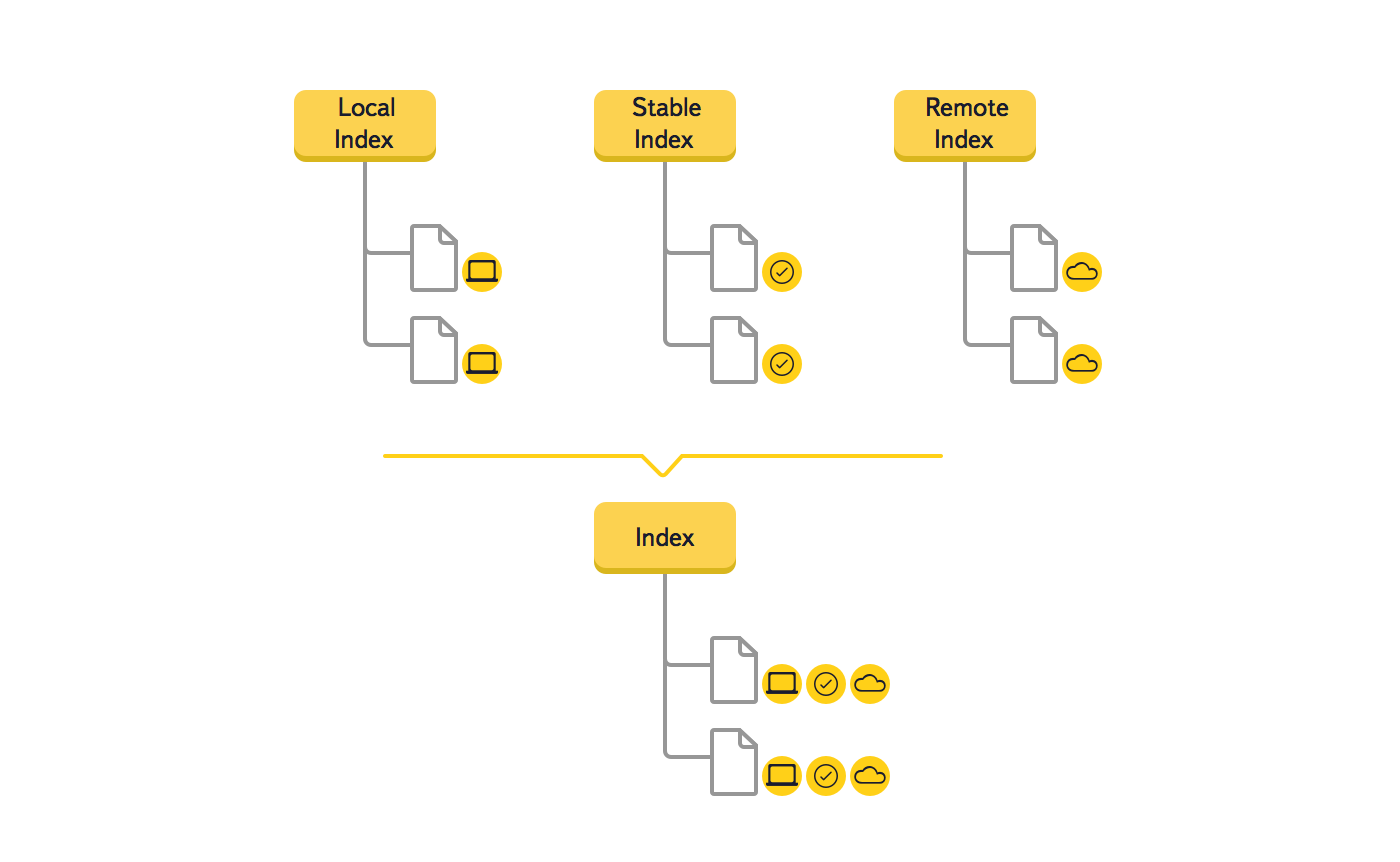
We decided to change the data storage structure and replace the three trees (Local Index, Remote Index, Stable Index) with one, which should lead to a decrease in redundancy in the main data structure. Due to the fact that the key in the tree is the path to the file system element, as a result of the merger, the amount of RAM used is significantly reduced.
We also refused to use auxiliary trees during synchronization, because each element of the tree in the new version stores all the necessary data. This structure change greatly simplified debugging code.
Since we understood that this was a major change, we created a prototype that confirmed the effectiveness of the new solution. Consider the example of how to change the data in the tree during the synchronization of a new file.

This example shows that the new synchronization algorithm processes only those elements and events, data on changes in which were received from the file system or the cloud, and not the entire tree, as it was before. If necessary, parent or child nodes will be processed (for example, in the case of moving a folder).
In the new version we have worked on other improvements that have affected the performance. Saving the tree made incremental, which allows you to write to the file only the latest changes.
Yandex.Disk uses sha256 and MD5 digests to check the integrity of files, detect changed fragments and deduplicate files on the backend. Since this task heavily loads the CPU, in the new version the implementation of the digest calculations has been significantly optimized. The speed of the file digest is about doubled.
Synchronization of unique 20,000 files of 10K
Calculation of digests unique 20000 files of 10kb (indexing)
Run from 20,000 synchronized files at 10K
Upload 1Gb. 10 Mbps Wi-Fi connection
From the examples it is clear that the new version of Yandex.Disk software uses about 3 times less RAM and about 2 times less CPU load. Handling minor changes does not increase the amount of memory used.
As a result of the changes made, the number of files with which the program handles without problems has significantly increased. In the Windows version - 300,000, and on Mac OS X - 900,000 files.
In this post, I’ll tell you why it happened: what we couldn’t foresee when we thought out the first version of Yandex.Disk software, and how we created a new one.
')
First of all, about the task of synchronization. Technically speaking, it consists in having the same file set in the Yandex.Disk folder on the user's computer and in the cloud. That is, such user actions as renaming, deleting, copying, adding and modifying files should be synchronized with the cloud automatically.
Why is it not as simple as it seems at first glance?
Theoretically, the task may seem simple enough, but in reality we are faced with various difficult situations. For example, a person renamed a folder on his computer, we detected this and sent a command to the backend. However, none of the users waits until the backend confirms the renaming success. The person immediately opens his locally renamed folder, creates a subfolder in it, and, for example, transfers part of the files to it. We are in a situation in which it is impossible to immediately perform all the necessary synchronization operations in the cloud. First you need to wait for the completion of the first operation and only then you can continue.
The situation may become even more difficult if several users work with the same account at the same time or they have a shared folder. And this happens quite often in organizations that use Yandex.Disk. Imagine that in the previous example, at the moment when we received confirmation of the first rename from the backend, another user takes and renames this folder again. In this case, again, you cannot immediately perform the actions that the first user has already performed on his computer. The folder in which he worked locally, on the backend at this time is already called differently.
There are cases when a file on a user's computer cannot be called the same as it is called in the cloud. This can happen if the name has a character that cannot be used by the local file system, or if the user is invited to a shared folder and has his own folder with that name. In such cases, we have to use local pseudonyms and track their connection with objects in the cloud.
Past version of the algorithm
In the previous version of the Yandex.Disk desktop software, the tree comparison algorithm was used to search for changes. Any other solution at that time did not allow for the search for displacements and renames, since the backend did not have unique object identifiers.
In this version of the algorithm, we used three main trees: the local (Local Index), the cloud (Remote Index) and the last synchronized (Stable Index). In addition, in order to prevent the repeated generation of already queued synchronization operations, two more auxiliary trees were used: the local expected and cloud expected (Expected Remote Index and Expected Local Index). In these auxiliary trees, the expected state of the local file system and the cloud was stored, after performing all the synchronization operations that have already been queued.
The procedure for comparing trees in the old algorithm was as follows:
- If the local expected tree and the cloudy expected tree are empty, initialize them by copying the last synchronized tree;
- We compare the local tree with the cloud expected and, by comparing the individual nodes, we add synchronization operations in the cloud to the queue (creating collections, transferring files to the cloud, moving and deleting in the cloud);
- For all operations that are queued at the previous step, we fix their future effect in the expected cloud tree;
- We compare the cloud tree with the local expected one and, by comparing the individual nodes, we add synchronization operations with the local file system to the queue (creating directories, downloading files from the cloud, moving and deleting local files and directories);
- For all operations that are queued at the previous step, we fix their future effect in the expected local tree;
- If simultaneous operations with the same file or directory are in the queue (for example, transferring a file to the cloud and downloading the same file from the cloud), then we fix the conflict - the file has changed in two places;
- After the synchronization operation is performed in the cloud or with the local file system, we put its result in the last synchronized tree;
- When the queue of synchronization operations becomes empty, we delete the local expected and cloudy expected tree. Synchronization is finished, and we will no longer need them.
Why we had to invent a new algorithm
The main problems of the tree comparison algorithm are high memory consumption and the need to compare the entire tree even with small changes, which led to a heavy load on the processor. During the processing of changes to even one file, the use of RAM increased by approximately 35%. Suppose a user has 20,000 files. Then, with a simple renaming of a single file of 10Kb in size, the memory consumption grew abruptly - from 116MB to 167MB.
We also wanted to increase the maximum number of files with which the user can work without problems. Several dozens and even hundreds of thousands of files may be, for example, a photographer who stores the results of photo shoots on Yandex.Disk. This task has become especially urgent when people have the opportunity to buy additional space on Yandex.Disk.
In the development, too, I wanted to change something. Debugging of the old version caused difficulties, since the data on the states of one element were in different trees.
By this time, id objects appeared on the backend, with the help of which it was possible to more effectively solve the problem of motion detection — earlier we used paths.
New algorithm
We decided to change the data storage structure and replace the three trees (Local Index, Remote Index, Stable Index) with one, which should lead to a decrease in redundancy in the main data structure. Due to the fact that the key in the tree is the path to the file system element, as a result of the merger, the amount of RAM used is significantly reduced.
We also refused to use auxiliary trees during synchronization, because each element of the tree in the new version stores all the necessary data. This structure change greatly simplified debugging code.
Since we understood that this was a major change, we created a prototype that confirmed the effectiveness of the new solution. Consider the example of how to change the data in the tree during the synchronization of a new file.
- After the user added a new file to the Disk folder, the program found it and added a new element to the tree. This element has only one state known - local. Since the stable and remote states are absent, no memory is allocated for them;
- The program performs the upload file. A push comes from the cloud confirming the appearance of a new file, and the remote state is added to the tree;
- The local and remote states are compared. Since they match, the stable state is added;
- The local and remote states are removed. They are no longer needed, since all the information is in stable.
This example shows that the new synchronization algorithm processes only those elements and events, data on changes in which were received from the file system or the cloud, and not the entire tree, as it was before. If necessary, parent or child nodes will be processed (for example, in the case of moving a folder).
Other improvements
In the new version we have worked on other improvements that have affected the performance. Saving the tree made incremental, which allows you to write to the file only the latest changes.
Yandex.Disk uses sha256 and MD5 digests to check the integrity of files, detect changed fragments and deduplicate files on the backend. Since this task heavily loads the CPU, in the new version the implementation of the digest calculations has been significantly optimized. The speed of the file digest is about doubled.
Numbers
Synchronization of unique 20,000 files of 10K
| Software version | Download to CPU. Calculation of digests | CPU load upload | RAM usage, MB |
|---|---|---|---|
| Yandex.Disk 1.3.3 | 28% (1 core 100%) | Approximately 1% | 102 |
| Yandex.Disk 1.2.7 | 48% (2 cores 100%) | Approximately 10% | 368 |
Calculation of digests unique 20000 files of 10kb (indexing)
| Software version | CPU load | Time, sec | RAM usage, MB |
|---|---|---|---|
| Yandex.Disk 1.3.3 | 25% (1 core 100%) | 190 | 82 |
| Yandex.Disk 1.2.7 | 50% (2 cores 100%) | 200 | 245 |
Run from 20,000 synchronized files at 10K
| Software version | CPU load | Time, sec | RAM usage, MB |
|---|---|---|---|
| Yandex.Disk 1.3.3 | 25% (1 core 100%) | ten | 55 |
| Yandex.Disk 1.2.7 | 50% (2 cores 100%) | 22 | 125 |
Upload 1Gb. 10 Mbps Wi-Fi connection
| Software version | CPU load | Time, sec |
|---|---|---|
| Yandex.Disk 1.3.3 | five% | 1106 |
| Yandex.Disk 1.2.7 | five% | 2530 |
What happened
From the examples it is clear that the new version of Yandex.Disk software uses about 3 times less RAM and about 2 times less CPU load. Handling minor changes does not increase the amount of memory used.
As a result of the changes made, the number of files with which the program handles without problems has significantly increased. In the Windows version - 300,000, and on Mac OS X - 900,000 files.
Source: https://habr.com/ru/post/253171/
All Articles