Goodbye MongoDB Hello PostgreSQL
Our startup Olery was founded almost 5 years ago. We started with a single product, Olery Reputation, which was created by a Ruby development agency. All this has grown into a variety of different products. Today, we also have Olery Feedback, API for Hotel Review Data, widgets for insertion into websites and much more.
In total, we have 25 applications (all in Ruby) - some of them are on the web (Rails or Sinatra), but mostly they are background applications for data processing.
Although we have something to be proud of, we have one problem that always hung somewhere in the background - the database. Initially, we used MySQL for sensitive data (users, contracts, etc.) and MongoDB to store reviews and other data that could easily be recovered if lost. At first everything worked well, but as we grew, we began to experience problems, especially with MongoDB. Some of them arose in the field of database interaction with applications, some directly at the database itself.
')
For example, at some point we had to delete a million documents from MongoDB, and later insert. As a result, the work base has stalled for several hours. Then we had to run repairDatabase. And the repair itself also took several hours.
Another time, we noticed the brakes and determined that they were caused by a MongoDB cluster. But we could not figure out what exactly slows down in the database. No matter what means we tried to debug and collect statistics. We had to (here I don’t know how to translate, tell me in the comments: "until we replaced the primaries of the cluster"), so that the speed would return to normal.
These are just two examples, and there were many. The problem was not only that the database was naughty, but also that we could not understand why this was happening.
Another fundamental problem we faced is the main feature of MongoDB, namely, the lack of a schema. In some cases, this gives advantages. But in many cases this leads to the problem of implicit schemes. They are not determined by the data storage engine, but based on application behavior and predictions.
For example, you may have a set of pages in which an application expects to find a title field of type string. The scheme is, although not explicitly specified. Problems begin if the data structure changes over time, and old data is not transferred to the new structure (which is rather difficult to do in the case of databaseless systems). Suppose you have this code:
This will work for all documents that have a title field that returns a String. If the documents have a field with a different name, or no string field at all, it will break. To handle such cases, you need to rewrite the code:
Another way is to set the schema in the database. For example, Mongoid, the popular MongoDB ODM for Ruby, allows you to do this. But why set the scheme through such tools, if you can set the scheme in the database itself? It would be reasonable for reuse. If you have only one application working with the database, it is not scary. And if there are a dozen of them, then it all quickly turns into a mess.
Storing data without schemas is meant to make your life easier. You do not need to invent schemes. In fact, in this case, you are shifting the responsibility for maintaining data connectivity. In some cases it works, but I bet that in most cases it only causes more difficulties.
And we come to the question of what a good database should be. We at Olery appreciate the following:
- connectivity
- data and system behavior can be seen from the outside
- correct and unambiguous
- scalability
Connectivity helps the system to ensure that what is expected of it is accomplished. If the data is always stored in a certain way, then the system becomes easier. If a field is necessary, then the application should not check its presence. BB must ensure the completion of certain operations, even under load. There is nothing more disappointing than inserting data and expecting it to appear in the database within a few minutes.
Visibility from the outside describes both the system itself and how easy it is to extract data from it. If the system is buggy, it should be easy to debug. Data requests should also be simple.
Correctness implies that the system meets expectations. If the field is defined as numeric, you should not be able to insert text there. MySQL is extremely weak in this regard. You can insert text into a numeric field and get some sort of nonsense in the data.
Scalability is important not only for speed, but also from a financial point of view, and from the point of view of how the system responds to changing requirements. The system should work well without unreasonable financial costs, and not slow down the development cycle of systems that depend on it
After thinking about all this, we went in search of a replacement for MongoDB. Since our queries clearly fit traditional relational databases, we looked at two candidates: MySQL and PostgreSQL.
MySQL was the first, in particular, because we already used it in some cases. But he has his own problems. For example, by setting the field as int (11), you can insert text there, and MySQL will try to convert it. Examples:
Although MySQL issues warnings, warnings are often simply ignored.
The second problem is that any change in the table leads to its reading and writing. So, after each operation, changes have to wait for its completion. For large tables, this may take hours, and as a result, the entire project will slow down. Companies like SoundCloud developed special tools like lhm because of this.
Therefore, we began to look closely at PostgreSQL. She has many advantages. For example, you cannot insert text into a numeric field:
PostgreSQL also has the ability to change tables, which does not lead to their entry. For example, the operation to add a column that does not have a default value, and which can be filled with NULL, does not freeze the table.
There are other interesting features, namely: index and trigram-based search, full-text search, support for JSON requests, support for querying and storing key-value pairs, support for pub / sub, and much more.
And most importantly, PostgreSQL has a balance between speed, reliability, correctness and connectivity.
So, we decided to stop at PostgreSQL. The migration process with MongoDB was a daunting task. We broke it into three stages:
- PostgreSQL database preparation, migration of a small part of data
- update of applications that work with MongoDB to work with PostgreSQL, including any refactoring
- migration of production to a new database and placement on a new platform
Although there are tools for migration, due to the peculiarities of our data, we had to independently make such tools. These were one-time Ruby-scripts, each of which was engaged in a separate task - transfer of reviews, cleanup of encodings, editing of main keys and other things.
Most of the time was spent on updating applications, especially those that depended heavily on MongoDB. It took a few weeks. The process consisted of the following:
- Replacing the driver / code / model of MongoDB with the code for PostgreSQL
- test run
- correction of tests
- repeat point 2
For non-Rails applications, we stopped using Sequel. For Rails, they took ActiveRecord. Sequel is a handy toolkit that supports almost all of the special features of PostgreSQL. In building queries, he wins against ActiveRecord, although in some places there is too much text.
For example, you need to calculate the number of users using a particular locale as a percentage of the total. On simple SQL, such a query might look like this:
In our case, we get the following result:
Sequel allows you to write such a request in pure Ruby without string fragments (which are sometimes required for ActiveRecord):
If you do not want to use Sequel.lit ('*'), you can do this:
The text is a bit much, but they can easily be redone in the future.
In the plans we want to translate Rails applications to Sequel. But it is not yet clear whether this is worth the time spent.
There are two ways to do this:
- stop the entire project, migrate data, raise the project
- migrate in parallel with a working project
The first option implies that the project will not work for some time. The second is complex in execution. It is necessary to take into account all the new data that will be added during the migration in order not to lose them.
Fortunately, in Olery everything is so cleverly tuned that database operations occur at approximately equal intervals. Data that changes more often is easier to transfer because there are very few of them.
The plan is:
- transfer critical data - users, contracts, etc.
- transfer less critical data (which can then be recalculated or restored)
- check that everything works on a set of separate servers
- transfer production to new servers
- transfer all critical data that appeared from the first step
The second step took a day. The first and fifth - 45 minutes each.
It has been almost a month since we transferred all the data, and everything suits us. Changes occurred only for the better. Increased application performance. API feedback time has decreased.
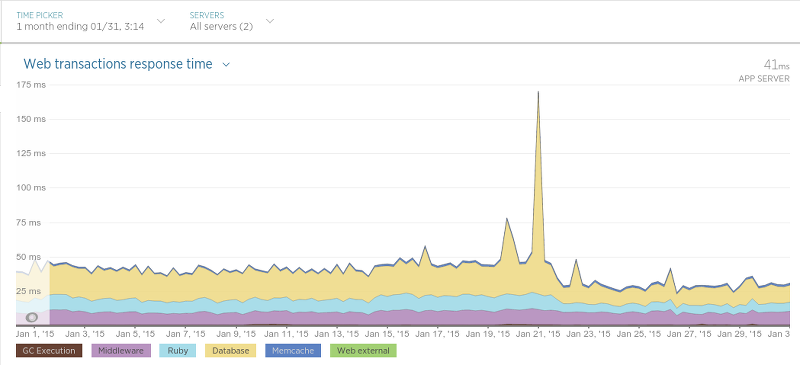
We moved on January 21. The peak on the graph is the restart of the application, which led to a temporary increase in response time. After the 21st, the response time has almost halved.
Where we have noticed a serious increase in speed, so it is in the application, which saved the data from the reviews and ratings.
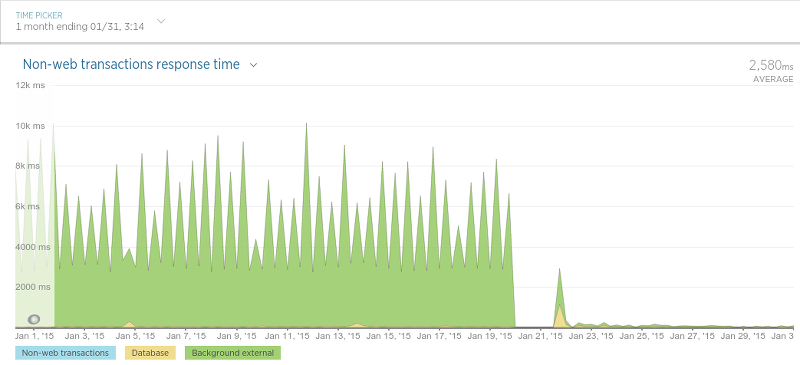
Our data collectors also sped up.
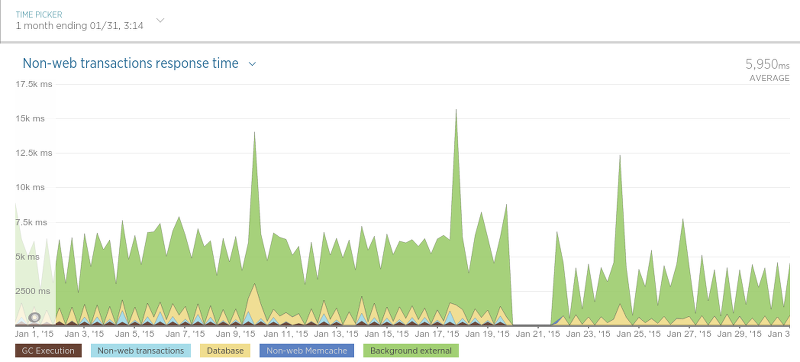
The difference came out not so much, but collectors do not use the database so much.
And finally, the application that distributes the data collector's work schedule (“scheduler”):
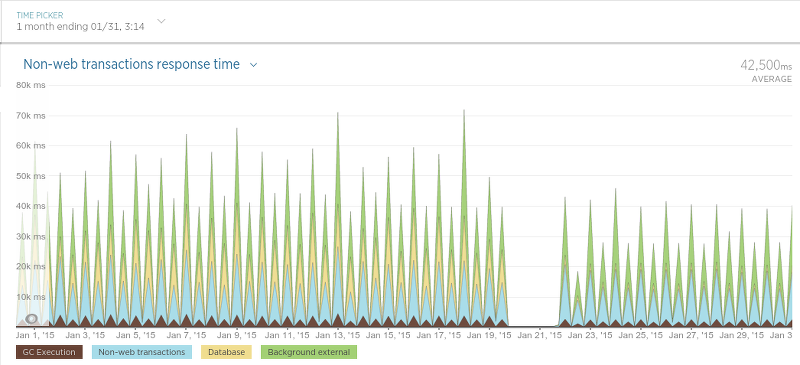
Since it works at regular intervals, the schedule is difficult to read, but in general there is a clear decrease in response time.
So, we are completely satisfied with the results of the move, and we are not going to miss MongoDB. The speed is excellent, the tools for working with the database are very convenient, queries to the data have become much easier compared to MongoDB. The only service that still uses it is Olery Feedback. He works on his own cluster. But we are also going to transfer it to PostgreSQL in the future.
In total, we have 25 applications (all in Ruby) - some of them are on the web (Rails or Sinatra), but mostly they are background applications for data processing.
Although we have something to be proud of, we have one problem that always hung somewhere in the background - the database. Initially, we used MySQL for sensitive data (users, contracts, etc.) and MongoDB to store reviews and other data that could easily be recovered if lost. At first everything worked well, but as we grew, we began to experience problems, especially with MongoDB. Some of them arose in the field of database interaction with applications, some directly at the database itself.
')
For example, at some point we had to delete a million documents from MongoDB, and later insert. As a result, the work base has stalled for several hours. Then we had to run repairDatabase. And the repair itself also took several hours.
Another time, we noticed the brakes and determined that they were caused by a MongoDB cluster. But we could not figure out what exactly slows down in the database. No matter what means we tried to debug and collect statistics. We had to (here I don’t know how to translate, tell me in the comments: "until we replaced the primaries of the cluster"), so that the speed would return to normal.
These are just two examples, and there were many. The problem was not only that the database was naughty, but also that we could not understand why this was happening.
Problem of lack of a scheme
Another fundamental problem we faced is the main feature of MongoDB, namely, the lack of a schema. In some cases, this gives advantages. But in many cases this leads to the problem of implicit schemes. They are not determined by the data storage engine, but based on application behavior and predictions.
For example, you may have a set of pages in which an application expects to find a title field of type string. The scheme is, although not explicitly specified. Problems begin if the data structure changes over time, and old data is not transferred to the new structure (which is rather difficult to do in the case of databaseless systems). Suppose you have this code:
post_slug = post.title.downcase.gsub(/\W+/, '-') This will work for all documents that have a title field that returns a String. If the documents have a field with a different name, or no string field at all, it will break. To handle such cases, you need to rewrite the code:
if post.title post_slug = post.title.downcase.gsub(/\W+/, '-') else # ... end Another way is to set the schema in the database. For example, Mongoid, the popular MongoDB ODM for Ruby, allows you to do this. But why set the scheme through such tools, if you can set the scheme in the database itself? It would be reasonable for reuse. If you have only one application working with the database, it is not scary. And if there are a dozen of them, then it all quickly turns into a mess.
Storing data without schemas is meant to make your life easier. You do not need to invent schemes. In fact, in this case, you are shifting the responsibility for maintaining data connectivity. In some cases it works, but I bet that in most cases it only causes more difficulties.
Requirements for a good database
And we come to the question of what a good database should be. We at Olery appreciate the following:
- connectivity
- data and system behavior can be seen from the outside
- correct and unambiguous
- scalability
Connectivity helps the system to ensure that what is expected of it is accomplished. If the data is always stored in a certain way, then the system becomes easier. If a field is necessary, then the application should not check its presence. BB must ensure the completion of certain operations, even under load. There is nothing more disappointing than inserting data and expecting it to appear in the database within a few minutes.
Visibility from the outside describes both the system itself and how easy it is to extract data from it. If the system is buggy, it should be easy to debug. Data requests should also be simple.
Correctness implies that the system meets expectations. If the field is defined as numeric, you should not be able to insert text there. MySQL is extremely weak in this regard. You can insert text into a numeric field and get some sort of nonsense in the data.
Scalability is important not only for speed, but also from a financial point of view, and from the point of view of how the system responds to changing requirements. The system should work well without unreasonable financial costs, and not slow down the development cycle of systems that depend on it
Avoiding MongoDB
After thinking about all this, we went in search of a replacement for MongoDB. Since our queries clearly fit traditional relational databases, we looked at two candidates: MySQL and PostgreSQL.
MySQL was the first, in particular, because we already used it in some cases. But he has his own problems. For example, by setting the field as int (11), you can insert text there, and MySQL will try to convert it. Examples:
mysql> create table example ( `number` int(11) not null ); Query OK, 0 rows affected (0.08 sec) mysql> insert into example (number) values (10); Query OK, 1 row affected (0.08 sec) mysql> insert into example (number) values ('wat'); Query OK, 1 row affected, 1 warning (0.10 sec) mysql> insert into example (number) values ('what is this 10 nonsense'); Query OK, 1 row affected, 1 warning (0.14 sec) mysql> insert into example (number) values ('10 a'); Query OK, 1 row affected, 1 warning (0.09 sec) mysql> select * from example; +--------+ | number | +--------+ | 10 | | 0 | | 0 | | 10 | +--------+ 4 rows in set (0.00 sec) Although MySQL issues warnings, warnings are often simply ignored.
The second problem is that any change in the table leads to its reading and writing. So, after each operation, changes have to wait for its completion. For large tables, this may take hours, and as a result, the entire project will slow down. Companies like SoundCloud developed special tools like lhm because of this.
Therefore, we began to look closely at PostgreSQL. She has many advantages. For example, you cannot insert text into a numeric field:
olery_development=# create table example ( number int not null ); CREATE TABLE olery_development=# insert into example (number) values (10); INSERT 0 1 olery_development=# insert into example (number) values ('wat'); ERROR: invalid input syntax for integer: "wat" LINE 1: insert into example (number) values ('wat'); ^ olery_development=# insert into example (number) values ('what is this 10 nonsense'); ERROR: invalid input syntax for integer: "what is this 10 nonsense" LINE 1: insert into example (number) values ('what is this 10 nonsen... ^ olery_development=# insert into example (number) values ('10 a'); ERROR: invalid input syntax for integer: "10 a" LINE 1: insert into example (number) values ('10 a'); PostgreSQL also has the ability to change tables, which does not lead to their entry. For example, the operation to add a column that does not have a default value, and which can be filled with NULL, does not freeze the table.
There are other interesting features, namely: index and trigram-based search, full-text search, support for JSON requests, support for querying and storing key-value pairs, support for pub / sub, and much more.
And most importantly, PostgreSQL has a balance between speed, reliability, correctness and connectivity.
Switch to PostgreSQL
So, we decided to stop at PostgreSQL. The migration process with MongoDB was a daunting task. We broke it into three stages:
- PostgreSQL database preparation, migration of a small part of data
- update of applications that work with MongoDB to work with PostgreSQL, including any refactoring
- migration of production to a new database and placement on a new platform
Migration of a small part of the data
Although there are tools for migration, due to the peculiarities of our data, we had to independently make such tools. These were one-time Ruby-scripts, each of which was engaged in a separate task - transfer of reviews, cleanup of encodings, editing of main keys and other things.
Application update
Most of the time was spent on updating applications, especially those that depended heavily on MongoDB. It took a few weeks. The process consisted of the following:
- Replacing the driver / code / model of MongoDB with the code for PostgreSQL
- test run
- correction of tests
- repeat point 2
For non-Rails applications, we stopped using Sequel. For Rails, they took ActiveRecord. Sequel is a handy toolkit that supports almost all of the special features of PostgreSQL. In building queries, he wins against ActiveRecord, although in some places there is too much text.
For example, you need to calculate the number of users using a particular locale as a percentage of the total. On simple SQL, such a query might look like this:
SELECT locale, count(*) AS amount, (count(*) / sum(count(*)) OVER ()) * 100.0 AS percentage FROM users GROUP BY locale ORDER BY percentage DESC; In our case, we get the following result:
locale | amount | percentage --------+--------+-------------------------- en | 2779 | 85.193133047210300429000 nl | 386 | 11.833231146535867566000 it | 40 | 1.226241569589209074000 de | 25 | 0.766400980993255671000 ru | 17 | 0.521152667075413857000 | 7 | 0.214592274678111588000 fr | 4 | 0.122624156958920907000 ja | 1 | 0.030656039239730227000 ar-AE | 1 | 0.030656039239730227000 eng | 1 | 0.030656039239730227000 zh-CN | 1 | 0.030656039239730227000 (11 rows) Sequel allows you to write such a request in pure Ruby without string fragments (which are sometimes required for ActiveRecord):
star = Sequel.lit('*') User.select(:locale) .select_append { count(star).as(:amount) } .select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) } .group(:locale) .order(Sequel.desc(:percentage)) If you do not want to use Sequel.lit ('*'), you can do this:
User.select(:locale) .select_append { count(users.*).as(:amount) } .select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) } .group(:locale) .order(Sequel.desc(:percentage)) The text is a bit much, but they can easily be redone in the future.
In the plans we want to translate Rails applications to Sequel. But it is not yet clear whether this is worth the time spent.
Workflow Migration
There are two ways to do this:
- stop the entire project, migrate data, raise the project
- migrate in parallel with a working project
The first option implies that the project will not work for some time. The second is complex in execution. It is necessary to take into account all the new data that will be added during the migration in order not to lose them.
Fortunately, in Olery everything is so cleverly tuned that database operations occur at approximately equal intervals. Data that changes more often is easier to transfer because there are very few of them.
The plan is:
- transfer critical data - users, contracts, etc.
- transfer less critical data (which can then be recalculated or restored)
- check that everything works on a set of separate servers
- transfer production to new servers
- transfer all critical data that appeared from the first step
The second step took a day. The first and fifth - 45 minutes each.
Conclusion
It has been almost a month since we transferred all the data, and everything suits us. Changes occurred only for the better. Increased application performance. API feedback time has decreased.
We moved on January 21. The peak on the graph is the restart of the application, which led to a temporary increase in response time. After the 21st, the response time has almost halved.
Where we have noticed a serious increase in speed, so it is in the application, which saved the data from the reviews and ratings.
Our data collectors also sped up.
The difference came out not so much, but collectors do not use the database so much.
And finally, the application that distributes the data collector's work schedule (“scheduler”):
Since it works at regular intervals, the schedule is difficult to read, but in general there is a clear decrease in response time.
So, we are completely satisfied with the results of the move, and we are not going to miss MongoDB. The speed is excellent, the tools for working with the database are very convenient, queries to the data have become much easier compared to MongoDB. The only service that still uses it is Olery Feedback. He works on his own cluster. But we are also going to transfer it to PostgreSQL in the future.
Source: https://habr.com/ru/post/253075/
All Articles