Risk Protection Machine Learning System Architecture

Our business is largely built on mutual trust between Airbnb, homeowners and travelers. Therefore, we try to create one of the most trusted communities . One of the tools for building such a community has become a review system that helps users find members who have earned a high reputation.
We all know that users periodically come across the net trying to deceive other people. Therefore, in Airbnb, a separate development team deals with security. The tools they create are aimed at protecting our user community from deceivers, with a lot of attention being paid to “quick response” mechanisms so that these people don’t have time to harm the community.
Any networked business faces a wide variety of risks. Obviously, they need to be protected, otherwise you risk the very existence of your business. For example, Internet providers make great efforts to protect users from spam, and payment services - from fraudsters.
')
We also have a number of opportunities to protect our users from malicious intent.
- Changes in the product . Some problems can be avoided by introducing additional user verification. For example, requiring confirmation of your mail account or implementing two-factor authentication to prevent account theft.
- Deviation detection . Some attacks can often be detected by changing some parameters during a short time span. For example, an unexpected 1000% increase in booking volumes may be the result of either an excellent marketing campaign or a scam.
- Model built on the basis of heuristics and machine learning . Fraudsters often act on some well-known schemes. Knowing some kind of scheme, you can apply heuristic analysis to recognize such situations and prevent them. In complex and multi-stage schemes, the heuristic becomes too cumbersome and inefficient, so machine learning should be used here.
If you are interested in a deeper look at online risk management, then you can refer to the book by Ohad Samet.
Machine learning architecture
Different risk vectors may require different architectures. For example, for a number of situations, time is not critical, but for detection it is necessary to use large computational resources. In such cases, the offline architecture is best suited. However, within the framework of this post we will consider only systems operating in real time and close to it. In general, a machine learning pipeline for these types of risks depends on two conditions:
- The framework should be fast and reliable . It is necessary to reduce to zero the possible downtime and inoperability, and the framework itself should constantly provide feedback. Otherwise, fraudsters may take advantage of insufficient performance or the glitchiness of the framework by simultaneously launching several attacks or continuously attacking in some relatively simple way, waiting for an imminent overload or system shutdown. Therefore, the framework should work, ideally, in real time, and the choice of model should not depend on the speed of evaluation or other factors.
- The framework must be flexible . Since fraud vectors are constantly changing, it is necessary to be able to quickly test and implement new detection and response models. The process of building models should allow engineers to freely solve problems.
Optimizing real-time computing during transactions primarily concerns speed and reliability, while optimizing model building and iteration should be more focused on flexibility. Our engineering and data processing teams jointly developed a framework that meets the above requirements: it is fast, reliable in detecting attacks and has a flexible model building pipeline.
Feature highlighting
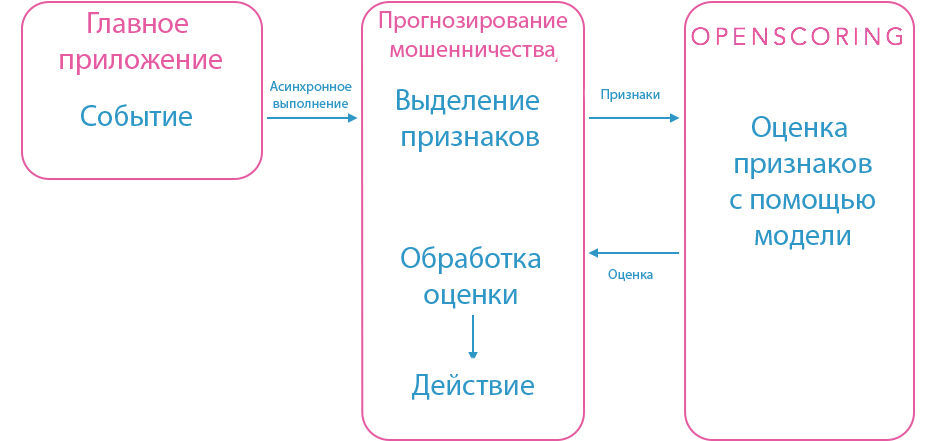
In order to preserve our service-oriented architecture, we have created a separate fraud forecasting service, which highlights all the necessary features for a particular model. When the system registers any critical event, for example, housing is reserved, a processing request is sent to the fraud forecasting service. After that, the event highlights the signs in accordance with the “housing reservation” model and sends them to our Openscoring- service. That gives an assessment and the decision on the basis of the put criteria. All this information can use the forecasting service.
These processes must proceed quickly in order to have time to react in case of danger. The forecasting service is written in Java, like many of our other back-end services for which performance is critical. Database queries are parallelized. At the same time, we need freedom in cases when heavy calculations are made in the process of feature extraction. Therefore, the prediction service is executed asynchronously, so as not to block the booking procedures, etc. The asynchronous model works well in cases where a delay of a few seconds does not play a special role. However, there are situations when you need to instantly respond and block the transaction. In these cases, apply synchronous requests and evaluation of pre-calculated signs. Therefore, the forecasting service consists of various modules and an internal API that allows you to easily add new events and models.
Openscoring
This is a Java service that provides the JSON REST interface for the JPMML-Evaluator . JPMML and Openscoring are open source projects and are distributed under the AGPL 3.0 license. The JPMML backend uses PMML , an XML language that encodes several common machine learning models, including tree-like, logit, SVM, and neural networks. We implemented Openscoring in our production-environment, adding additional features: logging Kafka, monitoring statsd, etc.
What, from our point of view, are the advantages of Openscoring:
- Open project . This allows us to modify it to your requirements.
- Supports various sets of trees . We tested several training methods and found that random aggregates provide a suitable level of accuracy.
- High speed and reliability . During load testing, most of the responses were received in less than 10 ms.
- Multiple models . After our refinement, Openscoring allows you to simultaneously run many different models.
- PMML format . PMML allows our analysts and developers to use any compatible machine learning packages (R, Python, Java, etc.). The same PMML files can be used with the Cascading Pattern to evaluate groups of large-scale distributed models.
But Openscoring has drawbacks:
- PMML does not support some kinds of models . Only relatively standard ML models are supported, so we cannot launch new models or significantly modify the standard ones.
- There is no native support for online learning . Models cannot train themselves on the fly. An additional mechanism is needed for automatic access to new situations.
- Rudimentary error handling . PMML is difficult to debug, manual editing of the XML file is a risky job. JPMML is known for giving cryptic error messages when experiencing problems with PMML.
Model building conveyor
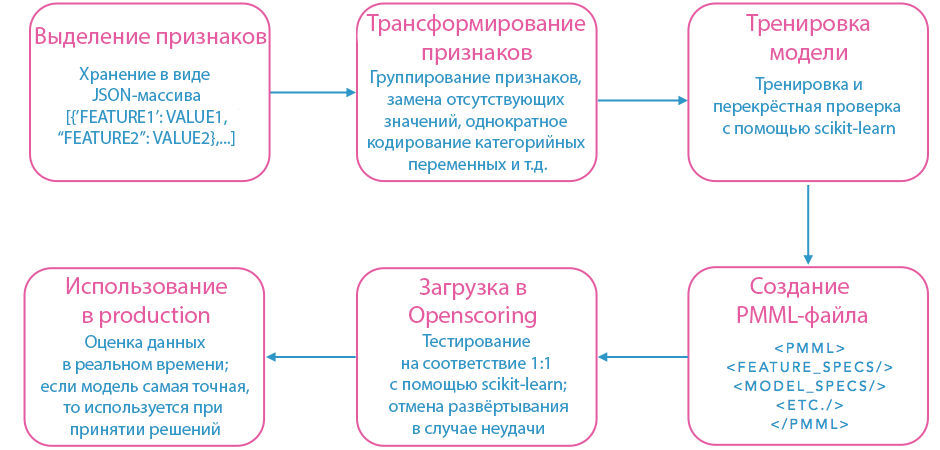
Above is a diagram of our model building pipeline using PMML. First, from the data stored on the site, highlighted the signs. Since the combinations of features that give the optimal signal are constantly changing, we store them in JSON format. This allows you to generalize the process of loading and transforming features based on their names and types. Then the signs are grouped, and to improve the signal instead of the missing variables are inserted suitable. Statistically unimportant signs are discarded. All these operations take considerable time, so you have to sacrifice many details for the sake of increased productivity. The transformed attributes are then used to train and cross-check the model using our favorite PMML-compatible machine learning library. After that, the resulting model is loaded into Openscoring. The final result is tested and used to make decisions if it shows the best results.
The model training stage can be performed in any language that has a PMML library. For example, the R PMML package is often used. It supports many types of transformations and ways to manipulate data, but it cannot be called a universal solution. We deploy the model in a separate stage, after its training, so you have to check it manually, which can take a lot of time. Another disadvantage of R is the low rate of implementation of the PMML exporter with a large number of features and trees. However, we found that simply rewriting the function export in C ++ reduces the execution time by about 10,000 times, from a few days to a few seconds.
We are quite able to bypass the disadvantages of R, while at the same time using its advantages in building a pipeline based on Python and scikit-learn . Scikit-learn is a package that supports many standard machine learning models. It also includes useful utilities for checking models and performing feature transformations.
For us, Python has become a more suitable language than R for situational data management and feature extraction. The automated extraction process relies on a set of rules encoded in the names and types of variables in JSON, so new features can be embedded in the pipeline without changing the existing code. Deployment and testing can also be performed automatically in Python using standard web libraries for interacting with Openscoring. Performance tests of the standard model (precision-recall, ROC curves, etc.) are performed using sklearn. It does not support out of box PMML export, so I had to rewrite the internal export mechanism for certain classifiers. When the PMML file is uploaded to Openscoring, it is automatically tested for the compliance of the model it presents to scikit-learn. Since all stages, such as transforming features, building a model and testing it, deploying and testing, are performed in a single script, developers can quickly iterate over a model based on new features or more recent data, and then quickly deploy it to production.
The main stages: the situation -> signs -> the choice of the algorithm
The process we have built has shown excellent results for some models, but with the rest we have a poor level of precision recall. At first we decided that the reason was the presence of errors, and tried to use more data and more signs. However, there was no improvement. We analyzed the data more deeply and found out that the problem was that the situations themselves were incorrect.
Take, for example, cases with the requirements of return payment. Reasons for returns may be situations where the product "does not match the description" (Not As Described, NAD) or fraud . But it was a mistake to group both of these reasons in the same model, since bona fide users can document the validity of NAD returns. This problem is solved easily, like a number of others. However, in many cases it is quite difficult to separate the behavior of fraudsters from the activities of normal users, it is necessary to create additional data warehouses and logging pipelines.
For most specialists working in the field of machine learning, they will consider it obvious, but we still want to emphasize once again: if your analyzed situations are not entirely correct, then you have already set the upper limit of accuracy of accuracy and completeness of the classification. If the situations are essentially erroneous, then this limit turns out to be rather low.
Sometimes it happens that until you come across a new type of attack, you don’t know what data you need to determine it, especially if you didn’t work in the conditions of possible risks. Or they worked, but in another field. In this case, you can advise to log everything that is possible. In the future, this information may not just be useful, but even prove invaluable for protection against a new attack vector.
Future prospects
We are constantly working to further improve and develop our fraud forecasting system. The current stage of the company's development and the amount of available resources are reflected in the current architecture. Often, smaller companies can afford to use only a few ML-models and a small team of analysts in production; they have to manually process the data and train the models in unusual cases. Larger firms can afford to create numerous models, widely automate processes and get substantial returns from training models online. Work in an extremely fast-growing company gives you the opportunity to work in a radically changing landscape from year to year, so the training pipelines need to be constantly modified.
With the development of our tools and techniques, investing in further improving learning algorithms is becoming increasingly important. Probably, our efforts will shift towards testing new algorithms, wider introduction of online learning models and modernizing the framework so that it can work with more voluminous data sets. Some of the most significant opportunities for improving models are based on the uniqueness of the information we accumulate, the sets of features and other aspects that we cannot voice for understandable reasons. Nevertheless, we are interested in sharing experience with other development teams. Write to us!
Source: https://habr.com/ru/post/252697/
All Articles