Adapt BDD for development on 1C together with cucumber and 1Script
Who pays for testing solutions? Especially in cases where the customer (internal or external) asks to start the accounting system, and does not indicate how bad the system needs it? This question causes a rather large wave of "holy wars" in any development, any decisions. They are written on 1C or not on 1C - this is the eternal “fight”: nobody likes to test, everyone loves to “code” new and interesting tasks.
But in order to at least try to get off the ground, it is necessary to understand that testing as a concept refers to the development process. So all the same will have to test the developers. But how to do it as convenient as possible?
')
Reflecting on the problem of testing, or rather on the problem of the quality of solutions, smart and not very people, basically break their spears. Over the following contradiction

“It is necessary to test, but it is necessary to develop, but not to test”.
Also added to this is another contradiction.
“All possible actions of the future user should be foreseen, but ALL actions of the future user cannot be foreseen”

Everything gets worse when we add to this a huge number of approaches to design and development. For example, how do I classify it when I need to explain the nature of the problem.
Domain DD is a development method when the customer’s goal is formulated as the basic entities of the future system: “I want Goods, Inventory, Acts of debiting and crediting”
Report DD - development method, when the goal of the customer is formulated in the form of final reports with data analysis: “I want a report on profits and losses”
User Interface DD is a development method when the goal of the customer is formulated as a final user interface: “I want just such a mold for an employee at the entrance hall to issue permits”
Behavior DD is a development method when the customer’s goal is formulated as the final process expected in the system, or even a group of interrelated processes: “When we fix the car shipment from Moscow, then the order status needs to be changed and the time of shipment is fixed, and indirect costs must be taken into account for transportation in the cost of the order ”
Separately, it is worth highlighting another 3 approaches that are usually not described anywhere.
Sabotage DD is a development method when the customer’s goal is formulated as an accelerated timeline requiring development directly in Production systems: “Urgently add the Boolean = Chamomile = props to the form” . Used when a customer attempts to build controlled chaos in a development team — used for political purposes.
Moratorium DD is a development method when the customer’s goal is not to launch the functionality, but to comply with the regulations and standards approved by the company: “Any change in the system must be coordinated with <Agreement Sheet>, any design, development and prototyping work cannot be carried out without project instructions and its feasibility study ” .
Pain DD is a transitional way of development when the goal of the customer is to improve the quality of solutions without reducing the timeline for functionality: “I want you to do comprehensive testing, but by the way, do not forget to launch the WMS system on the first day, God forbid you break the deadlines. And by the way, they cut us a payroll this year - you won't get dedicated testers. ”
The classification is of course clumsy and very down to earth, but it’s sufficient to prepare a specialist to read smart books on this issue.
There is also FeatureDD (development when the customer’s goal is formulated as a small lightweight functionality), and ModelDD (development when the customer’s goal is formulated as a final table with fields), but I don’t usually use them for the following reasons:
Suddenly, who does not know what these abbreviations are:
DD - Driven Development (development “through” or development “from the goal”) is one of the ways to organize the development process in software engineering. Included in en.wikipedia.org/wiki/Software_development_process as separate methodologies.
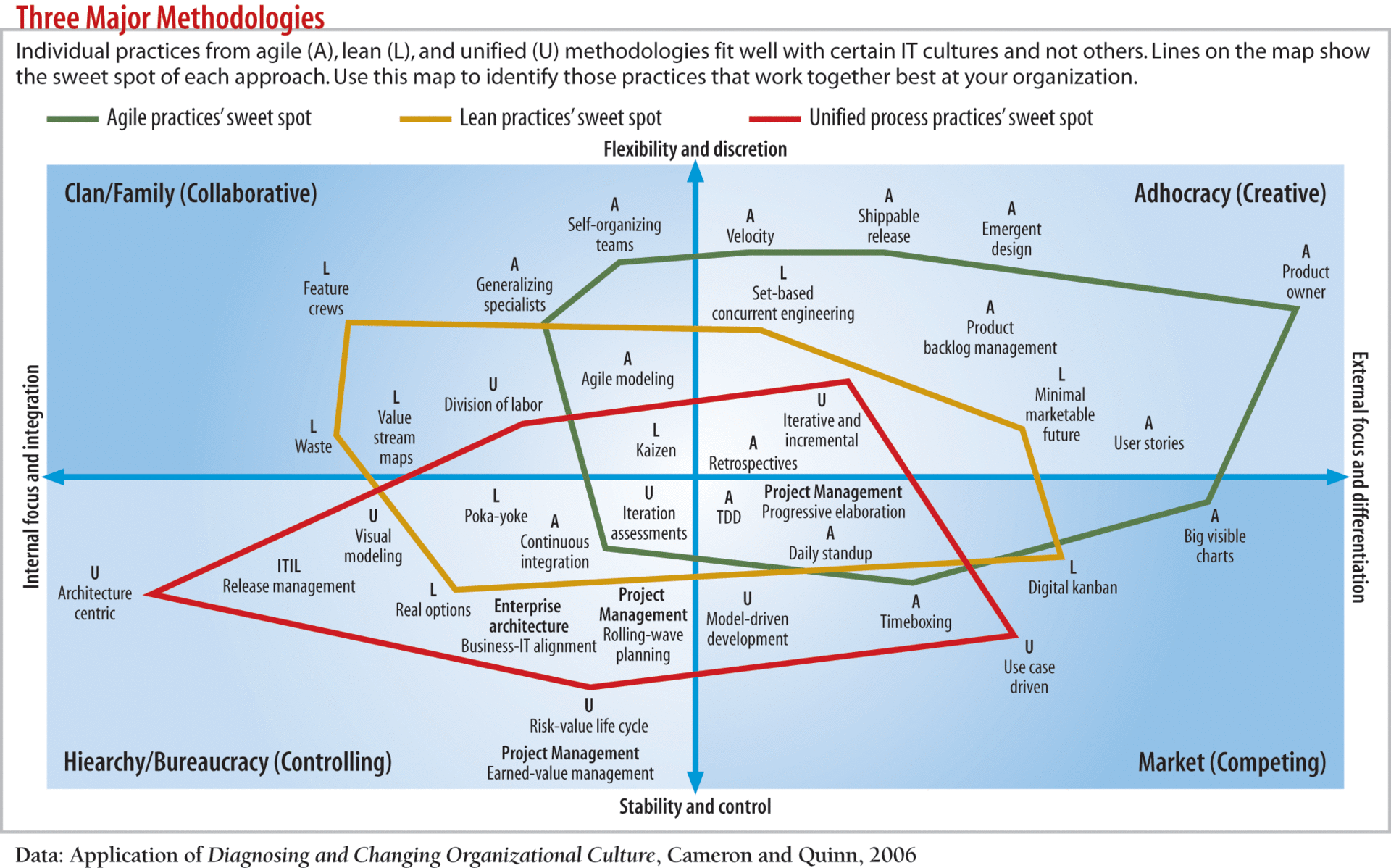
Those who are familiar with the eDSL world, and as I understood from the previous article, there are quite a lot of them on Habré, most likely guessed where I lead. For those who do not understand, I will say: in the 1C world, due to the fact that the customer is not the final businessman, but any user of the enterprise: any of the approaches will de facto apply. Someone wants a report, someone's behavior, someone in general is strange. Therefore, in the community of ordinary 1C specialists, they use the wording xDrivenDevelopment - where x : any approach, depending on the goal of the customer. Authorship belongs to one of the community members and initially sounded like yDrivenDeveloment , where y is a certain target function performed by the developer.
But back to testing. So, at the entrance we have the following data:
We want to try to create an opportunity to develop through behavior on the 1C platform.
To work we need:
as well as a conceptual reflective approach to testing a 1C solution through behavior:
as an additional submodule we will use
Having reached this place, some 1C specialists will make “wide-open eyes” and possibly close the article. For the rest we continue, I note the following points:
ruby we need to install "cucumber"
python - is used to work with git hooks (the fact is that to get the source files, we use interception to place binary 1C files in the repository: after all, the source code repository still has to be the source code).
For those who are currently in pain from the abrupt transition from theory to practical work, I propose to accept and continue reading:
The first thing you need to understand is that tests are code too. And for the code, we just have to make the code storage. Therefore:
now you just have to figure out where to store the tests on the git server
Let's go directly to the task. Here again you have to be distracted a little and say that when you launch the development of automated testing 1C, the main problem is just a misunderstanding of “how to test” the final business functionality. It is also possible that the name of the famous xUnit project is playing the “evil thing” - which refers us to en.wikipedia.org/wiki/XUnit , where we read a lot of buzzwords, but they are too far from the final testing of a business problem.
And here the novice developer who has been assigned the task of automated testing begins “breaking stereotypes”, the fact is that the 1C Configurator allows you to immediately implement the resulting expected behavior without needing to think about it and ask the question “why” and “who” need functionality. Initially, it is believed that all business customers and eDSL language specialists are as “as possible” as possible. For one behavior, this is most likely true, but for a set of expected behaviors and complex scenarios, no brain can keep the entire scenario in the context. This is exactly where we begin to treat the expected behavior as a code.
The task from the customer (in the task accounting system) sounds as follows:
Now let's see how it looks in reality and estimate what we need for BDD in 1C:
Next comes a rather important and very obligatory step in “developing through behavior” - we write the expected behavior scenario (or analysts for us, or a competent customer). In fact, Gherkin, and we will use it, will save us here, because we have a DSL language to describe a group of future test scenarios. Probably you were surprised that I said about future tests? But you have to reconcile - after using BusinessReadableDSL to describe the scenario, you understand what you really need to test, and what you really need to implement (you are looking for Martin Fowler’s article on this topic).
So, we have a feature file, which we write based on the original formulation of the problem, as follows:
Run vanessa-behavior.os with the “GenerateEpf” parameter and get the output processing file for testing:
and we get it for the sake of which all this was started - the processing of testing based on the behavior, which we then fill in using the code in the embedded language 1C

As you can see, the following happened:
A procedure was created for each line of the feature file.
The parameters for calling these procedures (number, string, date) were defined, and also so-called snippets were defined, for example:
Let's see what you can do with this good.
The first thing that catches the eye is that the name of the parameter ParamString is not very visual. Well, we take and change his name, say, on the Name of the Configuration . Yes, and the name of the procedure is replaceable with There is a Configuration .
It turns out:
But there may be a situation that if you try again to generate 1C processing for the same feature file, the program will not be able to find the procedure with the old name and everything will stop working. But here comes the snippet.
by which we can always determine which method to call (though for this we will have to parse the processing sources, and build a table of snippets and real procedure names, but such little things do not frighten us).
The second thing to notice is that there were two similar lines in the feature file:
But for them only one method was created:
This is not surprising, because for both lines the snippet will be the same. Thus, it may seem that code reuse is brewing here. Iiiiiiiii ... Yes! This is it! If somewhere in this feature file (or in any other of the same project) we write something like:
it turns out that this testing code has already been implemented in the method There is a ContractAgreement of the Agreement .
Moreover, it may turn out that this method was implemented by someone else before us. And we just reuse it. And it will happen by itself. Is this not the dream of any programmer! The customer writes what he wants (and this is our feature file) - and half of the code is already implemented, tested (ie, covered with a test) and will be picked up on the fly!
Welcome to the BDD, my friend!

Let's summarize the mini total.
Within the framework of one article it is difficult to cover such a large topic as BDD and how to adapt it to the world of 1C. I hope there will be a separate article entirely devoted to this subject, but with already more detailed examples.
Usually, those who study this material, as I said in the first article, refuse to start writing through tests.
This happens for two reasons:
FAQ
Q: I tried, I did not succeed. How to use it at all?
A: The project is working on the latest (develop) version of 1Script and is waiting for the release of release 1.0.9 , and will also be systematically refined for current tasks. So do not worry - everything will be.
Q: What to read on this topic?
A: There is a lot of materials, but:
Q: Why is Gherkin here?
A: DSL language Gherkin to describe requirements is a direct reference to the problem of requirements management and how it is solved automatically.
Q: Why test typical functionality of a typical 1C solution?
A: As I have repeatedly stated, automated testing is a “long game”. The presence of the expected behavior from the system being introduced will help simplify the update to the new version of the standard 1C configuration and also conduct its development based on the typical configuration. True, this problem is already from another “opera” (for those who know English) . At the same time, I strongly recommend to peep in the “lobby” , where there is already the possibility of expansion, which will have to be developed taking into account your tests.
Q: And when will the publication about xUnitFor1C?
A: after a long discussion, we decided that the xUnit publication should be done by a group of authors from the xDrivenDevelopment organization, we can only share the initial eight-hour video course and the Infostart publication, the xUnitFor1C publication should still be done by the leader of this product
Q: What is the next post?
A: It will still be a Docker for 1C, after the official release of docker-compose and docker-machine , as well as the development of docker to 1.5, now it will really be useful to the respected HabrCommunity.
But in order to at least try to get off the ground, it is necessary to understand that testing as a concept refers to the development process. So all the same will have to test the developers. But how to do it as convenient as possible?
')
BDD, DDD, TDD, PDD, SDD and the rest DD
Reflecting on the problem of testing, or rather on the problem of the quality of solutions, smart and not very people, basically break their spears. Over the following contradiction
“It is necessary to test, but it is necessary to develop, but not to test”.
Also added to this is another contradiction.
“All possible actions of the future user should be foreseen, but ALL actions of the future user cannot be foreseen”
Everything gets worse when we add to this a huge number of approaches to design and development. For example, how do I classify it when I need to explain the nature of the problem.
Domain DD is a development method when the customer’s goal is formulated as the basic entities of the future system: “I want Goods, Inventory, Acts of debiting and crediting”
Report DD - development method, when the goal of the customer is formulated in the form of final reports with data analysis: “I want a report on profits and losses”
User Interface DD is a development method when the goal of the customer is formulated as a final user interface: “I want just such a mold for an employee at the entrance hall to issue permits”
Behavior DD is a development method when the customer’s goal is formulated as the final process expected in the system, or even a group of interrelated processes: “When we fix the car shipment from Moscow, then the order status needs to be changed and the time of shipment is fixed, and indirect costs must be taken into account for transportation in the cost of the order ”
Separately, it is worth highlighting another 3 approaches that are usually not described anywhere.
Sabotage DD is a development method when the customer’s goal is formulated as an accelerated timeline requiring development directly in Production systems: “Urgently add the Boolean = Chamomile = props to the form” . Used when a customer attempts to build controlled chaos in a development team — used for political purposes.
Moratorium DD is a development method when the customer’s goal is not to launch the functionality, but to comply with the regulations and standards approved by the company: “Any change in the system must be coordinated with <Agreement Sheet>, any design, development and prototyping work cannot be carried out without project instructions and its feasibility study ” .
Pain DD is a transitional way of development when the goal of the customer is to improve the quality of solutions without reducing the timeline for functionality: “I want you to do comprehensive testing, but by the way, do not forget to launch the WMS system on the first day, God forbid you break the deadlines. And by the way, they cut us a payroll this year - you won't get dedicated testers. ”
And this is not “trolling”
If it seemed to someone that these last 3 approaches were singled out and described in the order of “banter”, then I will immediately say - this is not so: in certain cases, such approaches give a certain amount of efficiency, though not to the IT department. IT specialists, here “most often in loss”.
The classification is of course clumsy and very down to earth, but it’s sufficient to prepare a specialist to read smart books on this issue.
There is also FeatureDD (development when the customer’s goal is formulated as a small lightweight functionality), and ModelDD (development when the customer’s goal is formulated as a final table with fields), but I don’t usually use them for the following reasons:
- in the 1C world, more often the customer immediately formulates the expected behavior of “behavior” , and since “behavior” is always complex, the feature's arise by themselves in the decomposition / categorization of scenarios.
- In the 1C world, all domains / models are always complex (or rather complex-functional) and have more than two dependent entities and more than two functional connections. And the correct model's arise by themselves already within the framework of the decomposition of complex domains - otherwise one cannot construct a correct graph of domain dependencies. I advise everyone to take a closer look at v8.1c.ru/model - the DDD combined with MDD is reflected in the system, with a small adaptation of ChangeManagementSystem.
Suddenly, who does not know what these abbreviations are:
DD - Driven Development (development “through” or development “from the goal”) is one of the ways to organize the development process in software engineering. Included in en.wikipedia.org/wiki/Software_development_process as separate methodologies.
BDD Developer Environment for eDSL
Those who are familiar with the eDSL world, and as I understood from the previous article, there are quite a lot of them on Habré, most likely guessed where I lead. For those who do not understand, I will say: in the 1C world, due to the fact that the customer is not the final businessman, but any user of the enterprise: any of the approaches will de facto apply. Someone wants a report, someone's behavior, someone in general is strange. Therefore, in the community of ordinary 1C specialists, they use the wording xDrivenDevelopment - where x : any approach, depending on the goal of the customer. Authorship belongs to one of the community members and initially sounded like yDrivenDeveloment , where y is a certain target function performed by the developer.
But back to testing. So, at the entrance we have the following data:
- It is necessary to test (and where to go)
- It is necessary to develop (the eDSL platform is actually intended for this)
- The approach to the development process may be different. (And nothing can be done about it)
- All tests do not write (well, or write, but after 10 years of the life of the system)
- System requirements are rather chaotic, approaches to setting requirements are also
We want to try to create an opportunity to develop through behavior on the 1C platform.
To work we need:
- 1C users.v8.1c.ru/distribution => 8.3. *
- git-msgit msysgit.imtqy.com => 1.7
- ruby www.ruby-lang.org/en/downloads => 2.0
- python wiki.python.org/moin/Python2orPython3 => 2.5
as well as a conceptual reflective approach to testing a 1C solution through behavior:
as an additional submodule we will use
Having reached this place, some 1C specialists will make “wide-open eyes” and possibly close the article. For the rest we continue, I note the following points:
I expect that when installing msgit you made it so that it was installed in $ PATH not only by itself, but also with all utilities (this 1C-nick needs to get used to console utilities from * nix world - touch, mv, rm, grep and t .d.)
ruby we need to install "cucumber"
python - is used to work with git hooks (the fact is that to get the source files, we use interception to place binary 1C files in the repository: after all, the source code repository still has to be the source code).
For those who are currently in pain from the abrupt transition from theory to practical work, I propose to accept and continue reading:
The first thing you need to understand is that tests are code too. And for the code, we just have to make the code storage. Therefore:
$ mkdir EnterpriseAccounting $ cd EnterpriseAccounting $ git init./ $ mkdir features $ mkdir tests $ mkdir src $ touch README.md now you just have to figure out where to store the tests on the git server
$ git set origin https://dev.example.com/foobar/EnterpriseAccounting $ git push who is this touch and what is this team
if you have installed msgit correctly, then you have this command already present, help on it can be viewed via touch --help
All the rest are typical commands when working with source codes:
All the rest are typical commands when working with source codes:
- create local directory
- initialize the repository inside it
- create directory structure
- make a reserve for future documentation for the team
- specify the central server
- send to the center (share with the team)
Testing the final task, it is not testing the function algorithm
Let's go directly to the task. Here again you have to be distracted a little and say that when you launch the development of automated testing 1C, the main problem is just a misunderstanding of “how to test” the final business functionality. It is also possible that the name of the famous xUnit project is playing the “evil thing” - which refers us to en.wikipedia.org/wiki/XUnit , where we read a lot of buzzwords, but they are too far from the final testing of a business problem.
And here the novice developer who has been assigned the task of automated testing begins “breaking stereotypes”, the fact is that the 1C Configurator allows you to immediately implement the resulting expected behavior without needing to think about it and ask the question “why” and “who” need functionality. Initially, it is believed that all business customers and eDSL language specialists are as “as possible” as possible. For one behavior, this is most likely true, but for a set of expected behaviors and complex scenarios, no brain can keep the entire scenario in the context. This is exactly where we begin to treat the expected behavior as a code.
The usual typical process for the developer
The task from the customer (in the task accounting system) sounds as follows:
“It is necessary that the money was counted as an advance if the client paid more than we shipped to him”
Now let's see how it looks in reality and estimate what we need for BDD in 1C:
- The parser for the Gherkin language, which will perform two functions: help us generate procedures for tests and, in fact, run ready-made tests and generate a report on their passing. For these purposes, we will use Cucumber (the same "cucumber")
- It would be nice if there was a tool that, getting ready-made test names from Cucumber (along with parameters) would create us ready-made processing files in the 1C external processing format (we remember that everything that can be automated should be automated). Technically, this is a script written in 1Script . It allows you to connect Cucumber and 1C to each other through the wire protocol cucumber, 1Script Socket, and OLE connections to 1C . Those. At the entrance, we get a feature file - at the exit, ready-made 1C processing, which can be given to the developer. And all this in one click.
- Those treatments that we get - these are our tests. This is the code, and the code must be stored and versioned. For this we put git.
- After the developer fills these tests with code, they will need to be decomposed into source codes (and how, we will not store only binary files in the repository). For this purpose, we will take Precommit1c from the xDrivenDevelopment community. Now, when we put the finished file in Git, it will be parsed, decomposed, decompiled, declassified (select the one you need). And by itself automatically, in one click, well, you understand.
Next comes a rather important and very obligatory step in “developing through behavior” - we write the expected behavior scenario (or analysts for us, or a competent customer). In fact, Gherkin, and we will use it, will save us here, because we have a DSL language to describe a group of future test scenarios. Probably you were surprised that I said about future tests? But you have to reconcile - after using BusinessReadableDSL to describe the scenario, you understand what you really need to test, and what you really need to implement (you are looking for Martin Fowler’s article on this topic).
So, we have a feature file, which we write based on the original formulation of the problem, as follows:
$ touch ./feature/account_loan.feature $ notepad++ ./feature/account_loan.feature : , , : ' 3.0 ()' ' ' ' 1' 02.01.2014 ' 2' 03.01.2014 : ' ' 2 2 ' ' 1000 300 ' ' 1100 '62.01' ' 1' 1000 '62.01' ' 2' 100 '62.01' ' 2' 200 How I created such a feature file
I just answered a typical set of questions from Gherkin, a little more detailed by interrogating the customer on the following list:
- What is the functional
- What is the role
- What is the purpose
- What behavior scenarios are we expecting?
- In what context is this functionality necessary?
Run vanessa-behavior.os with the “GenerateEpf” parameter and get the output processing file for testing:
$ oscript.exe vanessa-behavior.os --GenerateEpf --ProjectPath="< Feature >" --1cConnectString="File=<1>" and we get it for the sake of which all this was started - the processing of testing based on the behavior, which we then fill in using the code in the embedded language 1C
As you can see, the following happened:
A procedure was created for each line of the feature file.
For example, the string' 3.0 ()'
evolved into(01)
The parameters for calling these procedures (number, string, date) were defined, and also so-called snippets were defined, for example:
//“@(01,02)” Let's see what you can do with this good.
The first thing that catches the eye is that the name of the parameter ParamString is not very visual. Well, we take and change his name, say, on the Name of the Configuration . Yes, and the name of the procedure is replaceable with There is a Configuration .
It turns out:
() But there may be a situation that if you try again to generate 1C processing for the same feature file, the program will not be able to find the procedure with the old name and everything will stop working. But here comes the snippet.
//@(01) by which we can always determine which method to call (though for this we will have to parse the processing sources, and build a table of snippets and real procedure names, but such little things do not frighten us).
The second thing to notice is that there were two similar lines in the feature file:
' 1' 02.01.2014 ' 2' 03.01.2014 But for them only one method was created:
(01,02) This is not surprising, because for both lines the snippet will be the same. Thus, it may seem that code reuse is brewing here. Iiiiiiiii ... Yes! This is it! If somewhere in this feature file (or in any other of the same project) we write something like:
'- ' '- ' it turns out that this testing code has already been implemented in the method There is a ContractAgreement of the Agreement .
Moreover, it may turn out that this method was implemented by someone else before us. And we just reuse it. And it will happen by itself. Is this not the dream of any programmer! The customer writes what he wants (and this is our feature file) - and half of the code is already implemented, tested (ie, covered with a test) and will be picked up on the fly!
Welcome to the BDD, my friend!
Let's summarize the mini total.
- We have what the customer wants: this is described in the declarative language of Gherkin.
- We start the generator - we receive ready-made test files that need to be filled with code.
- We write tests (or we generate through the new functionality a record of user actions), at the same time we write / configure the functionality that the customer wants to receive.
- We start vanessa-behavior.os - and our tests are being performed using the same feature from the customer.
- We receive a report on the passage of tests in json or, for example, in html ( let's not forget about the Allure project )
Within the framework of one article it is difficult to cover such a large topic as BDD and how to adapt it to the world of 1C. I hope there will be a separate article entirely devoted to this subject, but with already more detailed examples.
Inventory functionality and technical debt
Usually, those who study this material, as I said in the first article, refuse to start writing through tests.
This happens for two reasons:
- after the introduction of the rule “We take any task into work only after we understand how we will test it”, the main time costs are spent on building up tests for primary data and master data - like contractors, nomenclature, accounting policies, etc. At the same time, it is necessary to generate test data, since it becomes clear to everyone that the basis for automated testing must be clean. Not everyone is ready to do it - because you have to look back at everything that “we put on” before the moment X (transition to BDD). Such a problem is solved by the so-called “technical sprint” method - how to coordinate it with the customer (or not to coordinate it) is a separate song from Agile.
- it's hard ... after all, BDD | xDD comes from engineering practice, so it requires a high level of developer responsibility in the team. It is always difficult to become responsible when, before that, 6 years was irresponsible. This problem is solved in two ways - the so-called method of social presure and the introduction of the practice of release managment. That is, when “without tests to write fu-fu-fu” and when release without tests to production is not allowed by the engineers responsible for the working system. If you are one and “many-handed Shiva”, then only internal IT perfectionism will save you.
- In the general case, switching to “development through expected behavior” temporarily increases team costs. At the moment, we have the following numbers - an increase in the speed of development and a decrease in the number of errors (quality improvement) starts somewhere in 1 month, for a team of 5 people the level of ordinary programmers is 1C. Therefore, within 1 month the whole team must live in permanent stress and accept it ;-). Although again for managers we have to notice that it is possible and not to interrupt the development by the old way, by running the requirements collection phase as feature files separately, and only then start the testing phase (although this contradicts the concept itself, it is acceptable for the transition period).
A bit of history, for not at all knowledgeable
We should also say how it all began and how it developed. In my version it was like this (although older comrades can correct me).
Began to test the concept of xDD (or rather with TDD), back in 2004 and on the 1C 7.7 platform. It is believed that the leaders here are the Moscow School for Testing - including the project www.1cpp.ru and Izhevsk School for Testing www.kint.ru
With the release of version 1C 8. * no one was going to abandon the already established processes, but the closeness of the platform led to the inability to port things in a direct way. The process has stopped a bit.
But Yandex and the head of the testing department saved everyone here ;-) (Yes, yes - Yandex was also there or still has 1C).
As a result, the first draft of infostart.ru/public/15492 appeared to be very efficient, and already when several developments were combined, the project github.com/xDrivenDevelopment/xUnitFor1C was born, to develop the quality of its solutions developers on the 1C platform. The leader in this product is Arthur Ayuhanov with a team of like-minded people .
But one can not forget about the Izhevsk school testing 1C solutions. At the moment, the main frontman here is Izhevsk testing of systems - the team here has built a testing monetization scheme and is already developing its line of commercial products.
The vanessa-behavior project is a continuation of the development of the xDD concept, but with a different approach - now not from tests, but from the behavior requirement.
Began to test the concept of xDD (or rather with TDD), back in 2004 and on the 1C 7.7 platform. It is believed that the leaders here are the Moscow School for Testing - including the project www.1cpp.ru and Izhevsk School for Testing www.kint.ru
With the release of version 1C 8. * no one was going to abandon the already established processes, but the closeness of the platform led to the inability to port things in a direct way. The process has stopped a bit.
But Yandex and the head of the testing department saved everyone here ;-) (Yes, yes - Yandex was also there or still has 1C).
As a result, the first draft of infostart.ru/public/15492 appeared to be very efficient, and already when several developments were combined, the project github.com/xDrivenDevelopment/xUnitFor1C was born, to develop the quality of its solutions developers on the 1C platform. The leader in this product is Arthur Ayuhanov with a team of like-minded people .
But one can not forget about the Izhevsk school testing 1C solutions. At the moment, the main frontman here is Izhevsk testing of systems - the team here has built a testing monetization scheme and is already developing its line of commercial products.
The vanessa-behavior project is a continuation of the development of the xDD concept, but with a different approach - now not from tests, but from the behavior requirement.
FAQ
Q: I tried, I did not succeed. How to use it at all?
A: The project is working on the latest (develop) version of 1Script and is waiting for the release of release 1.0.9 , and will also be systematically refined for current tasks. So do not worry - everything will be.
Q: What to read on this topic?
A: There is a lot of materials, but:
- I draw attention to the fact that the key speaker at the nearest AgileDays2015 will be the author cucumber .
- The BDD In Action book by John Ferguson Smart was published a year ago.
- It is also highly recommended to read the article by Dan North
Q: Why is Gherkin here?
A: DSL language Gherkin to describe requirements is a direct reference to the problem of requirements management and how it is solved automatically.
Q: Why test typical functionality of a typical 1C solution?
A: As I have repeatedly stated, automated testing is a “long game”. The presence of the expected behavior from the system being introduced will help simplify the update to the new version of the standard 1C configuration and also conduct its development based on the typical configuration. True, this problem is already from another “opera” (for those who know English) . At the same time, I strongly recommend to peep in the “lobby” , where there is already the possibility of expansion, which will have to be developed taking into account your tests.
Q: And when will the publication about xUnitFor1C?
A: after a long discussion, we decided that the xUnit publication should be done by a group of authors from the xDrivenDevelopment organization, we can only share the initial eight-hour video course and the Infostart publication, the xUnitFor1C publication should still be done by the leader of this product
Q: What is the next post?
A: It will still be a Docker for 1C, after the official release of docker-compose and docker-machine , as well as the development of docker to 1.5, now it will really be useful to the respected HabrCommunity.
Source: https://habr.com/ru/post/252473/
All Articles