Fragmented video stream compression method
I decided to present my development to the court of the respected community - the method of fragmentary compression of the video stream. A feature of the proposed method is the full compliance of the compressed video stream with the original, that is, the method performs lossless compression.
Before describing the method itself, it is necessary to agree on the terminology used. All terms used are intuitive, but nevertheless, it is worth defining them strictly:
The main idea of the fragmentary compression method is to represent a video stream in the form of a chain of elements of length N f from the base of elements. Since the video stream is a set of meaningful images (frames), rather slowly varying in time, one should expect a significant correlation both between adjacent elements of one frame and between corresponding elements on neighboring frames. This should lead to two effects:
Thus, the main idea of the fragmentary compression method is to represent the video stream as a well-compressible sequence of elements from some specially compiled element base. The experiments conducted by the authors confirm this hypothesis.
The concept of the method allows the video stream to be compressed both lossless and lossy. In the case of lossy compression, both preprocessing (filtering) is possible, smoothing the original image, and post-processing, consisting in analyzing the element base and then isolating and removing both random noise and visually redundant information from the video stream. Sharing pre-and post-processing allows you to create a new compressed video stream with the desired properties.
The method of fragmented compression can be represented as a sequence of four steps:
These steps are discussed in more detail below.
The process of forming the base of elements is one of the most resource-intensive steps of the fragmentary compression method. The final compression rate depends largely on how effectively this stage is performed.
Due to the extremely high requirements for speed, the algorithm for forming the base of elements is performed in several stages, with different algorithms and data structures being used at each step.
The formation of the base elements of the frame - the first and easiest step. At this stage, the next frame is received from the video stream, pre-processed if necessary, and, depending on the type of element, the corresponding “pseudo frame” is formed.
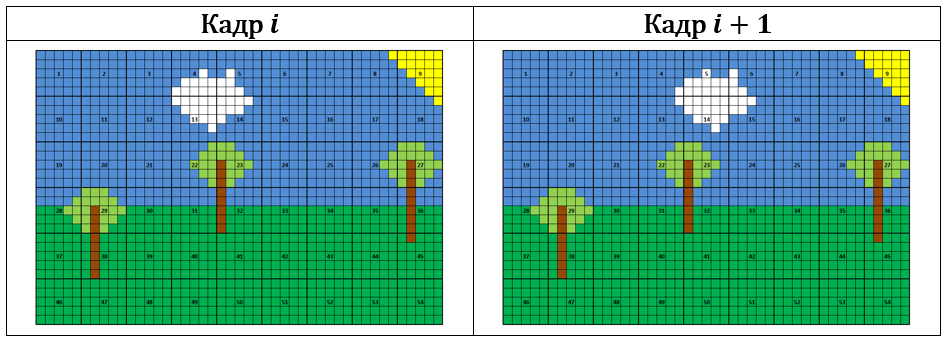
When viewing a pseudo frame, the window shifts n 2 pixels in width and n 1 pixels in height. The figure shows an example of a frame of N 1 = 30 rows on N 2 = 45 columns, the viewing is performed using the square window n 1 = n 2 = 5. The thin lines in the figure show individual pixels, the thick lines show the borders of the window, and the numbers inside the window show the sequence number when viewed.
If the elements are logical or arithmetic differences, then the scan will result in the following set of differences:
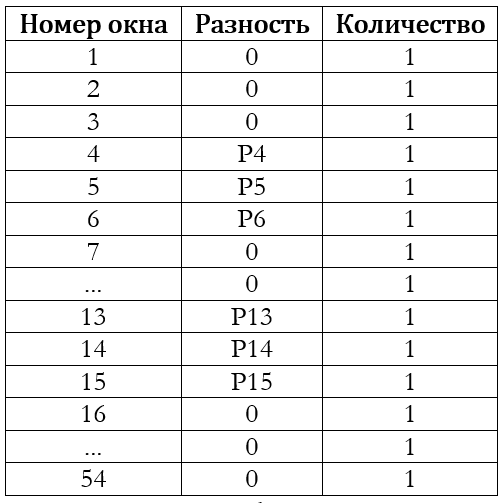
For most real-life movies, the assumption is that there is a significant correlation between the corresponding elements in the neighboring frames. This is also seen in the table: most of the elements correspond to zero differences. To save memory, the resulting base elements of the frame is compacted. First, sorting is performed by some efficient algorithm, and then the matching elements are combined into one record. That is, instead of 48 zero differences in the compacted base there will be only one record.
At the second stage, the compacted base elements of the frame are recorded in a special buffer of elements - a separate memory area where a plurality of frame bases are accumulated, and then one large block is written to the global storage. The peculiarity of the buffer is that any element can have random access by index, i.e. in fact, it’s just a large array of elements located in RAM:
It is also worth noting that the base elements of the frame are recorded in the buffer "as is" without any additional re-sorting. This leads to the fact that the buffer contains a lot of ordered sequences of elements, but it is not ordered:

When there is not enough space to record the next frame base, the procedure for updating the list of actually encountered items is called.
At the third stage, the elements accumulated in the buffer are moved to a special global storage, which is a simply connected list of elements, ordered by their values. The representation of the global storage in the form of a list does not allow performing random access in constant time, but it does allow adding and deleting elements in constant time.
Before adding the items from the buffer to the global storage, the procedure of sorting and compacting the buffer already discussed earlier is performed. This allows you to add items in a linear time relative to the size of the list:
Three considered stages operate with data placed in the RAM. The final stage involves working with data placed on hard drives. In the overwhelming majority of cases, a sufficiently powerful modern computer allows you to fully assemble the base of elements in RAM, but there are situations when there is not enough RAM to place the entire base there (for example, if a common base is formed for hundreds of hours of shooting). In this case, it is necessary to save the received bases to disk as the RAM is exhausted, and then perform the procedure of merging the databases.
Thus in the process of forming the base of elements the following sequence of steps is performed:

Analysis of the base of the elements involves the analysis of both the individual values of each element and the frequency characteristics of the base. This allows, firstly, to choose effective combinations of compression methods (building short codes and methods of their transmission), and, secondly, in the case of lossy compression, consciously reduce the base (filtering).
The base of elements includes an array of N b lines of length k bits and a table of frequencies of the appearance of these lines in a video stream (film). This information is sufficient for applying well-known entropy coding methods (Huffman tree, arithmetic coding, etc.). The listed algorithms have very high efficiency scores, but their actual use is associated with significant implementation difficulties.
For the construction of short codes of elements, the authors propose and use the method of constructing prefix codes proposed by them earlier with the help of cutting functions. In this method, the short codes of the elements of the base are based on the content of the rows of the elements themselves. The author proved that the average length of such codes does not exceed the value of H b * 1,049, where H b is the entropy of the base of elements, calculated from the frequency of occurrence of elements in the video stream. In numerical experiments with real films, H b never exceeded 20, which means that H b * 1,049 <H b +1, from which it follows that the average length of secant codes fits into the same prior estimates of redundancy that Shannon-Fano and Huffman At the same time, encoding with the help of secant functions is devoid of the disadvantages that arise when encoding and decoding the above-mentioned methods of large digital arrays (N b ≈ 10 7 -10 9 ).
In a compressed video stream, the elements are replaced with the previously received short codes. When playing a compressed video stream, a decoding problem arises. For decoding, it is necessary to have information on the compliance of short codes and base elements. The simplest way to transfer such information is the direct transfer of the element and its frequency (number of occurrences). This method involves the transfer of the base itself, as well as an additional 64 bits for each element. After receiving the data, the receiving party itself must build a code tree using a previously reported algorithm.
A method was proposed for recording and transmitting a tree, in whose leaves the entire base of elements is recorded. The volume of the transmission is equal to the base volume plus two additional bits for each base element ((k + 2) * N b ).
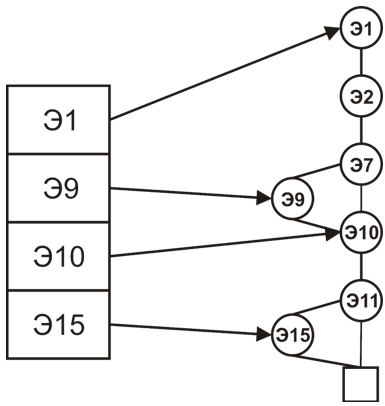
We agree on the tree traversal order: for example, we will use a wide traversal. If a dividing tree node is encountered, then bit 0 is transmitted, if a leaf was detected during the traversal, then bit 1 and the corresponding base element are transmitted. As a result, it is easy to show that only 2 extra bits are additionally transmitted to each base element. The figure shows the representation of a binary tree as a binary string using the described method:
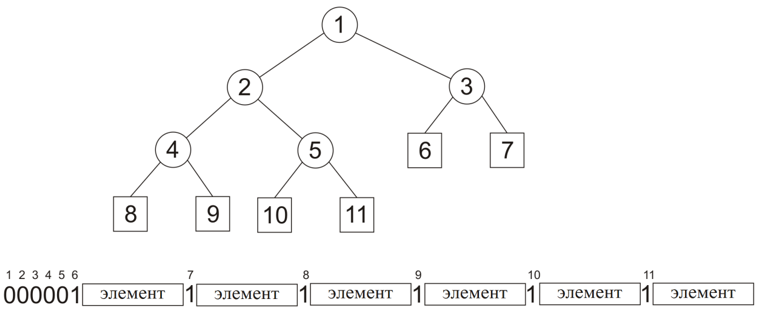
The specified representation is reversible: for each line constructed by the described method, it is possible to build an initial code tree. In addition to the obvious memory savings, the described transmission method eliminates the need to build a code tree during decoding (it is restored in a natural way). That is, a code tree is built only once during compression.
Thus, the paper proposes a scheme for transmitting a video stream consisting of two parts: a code tree with base elements and a chain of compressed element codes.
The approximate structure of the compressed video stream is shown in the figure:

The degree of compression provided by the fragmented compression algorithm largely depends on the properties and characteristics of the formed base of elements. The main characteristics of the base are the size (number of elements) and frequency characteristics (primarily entropy).
To estimate the achievable compression ratio, we use the following formulas. Let l cf - the average length of the codes of the elements of the base, then the volume of the compressed transmission is V s = N b (k + 2) + l cf * N f , and the volume of the uncompressed film is equal to V f = N f * k.
The compression ratio is the value:
R SG = V SG / V f . The inverse of the compression ratio is called the compression ratio and is denoted by K contra .
The main goal to strive for is maximization of K szh . In the formula above, N 1 , N 2 , M, bpp are the characteristics of the original video stream, which we cannot influence. And the values of l cf , N bases depend on the area and configuration of the scan window (n 1 , n 2 ). Those. The only variable parameters in the fragmented compression method are the geometric dimensions of the window.
For any window size, there is a maximum possible base volume of 2 bpp * n 1 * n 2 , and this value is growing extremely fast. Of course, in real films there are far from all possible elements, but with an increase in the window size, the number of bits needed to represent the corresponding base element also grows. In addition, a significant number (more than 70% of the total) of elements appears that occur in the video stream no more than once. In the end, all these effects lead to a decrease in the compression ratio.
On the other hand, too small a window size will lead to an increase in N f and a restriction on N b , which in turn will cause the elements to repeat more evenly and the “tilting” of frequencies will smooth out. The more evenly the elements of the base are repeated, the closer its entropy is to log 2 N b . This, in turn, also leads to a decrease in the compression ratio.
Consider the two extreme cases window 1 * 1 and window N 1 * N 2 . And in the first and in the second case, K szh ≈1. In the process of research, it was found that the dependence of K cr on the scan window area (n 1 * n 2 ) has approximately the following form:
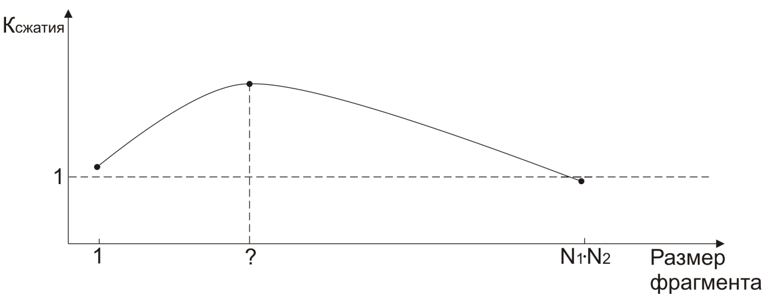
The task is to find the point where the compression level is maximum. Since the level of compression largely depends on the characteristics of the film; it is clear that there is no “ideal” configuration that will give the optimum compression for all films. But the experiments allowed to find a relatively small area where compression is optimal.
All analyzed video streams were divided into two groups depending on their features:
To select the optimal configuration of the window, the video streams belonging to each group were compressed using the fragmentary compression method. During the research, all possible configurations of windows ranging from one to eight pixels were analyzed (logical differences were used as elements). In total, about ten thousand hours of video were analyzed, which is about a billion frames. The results are presented in graphs.

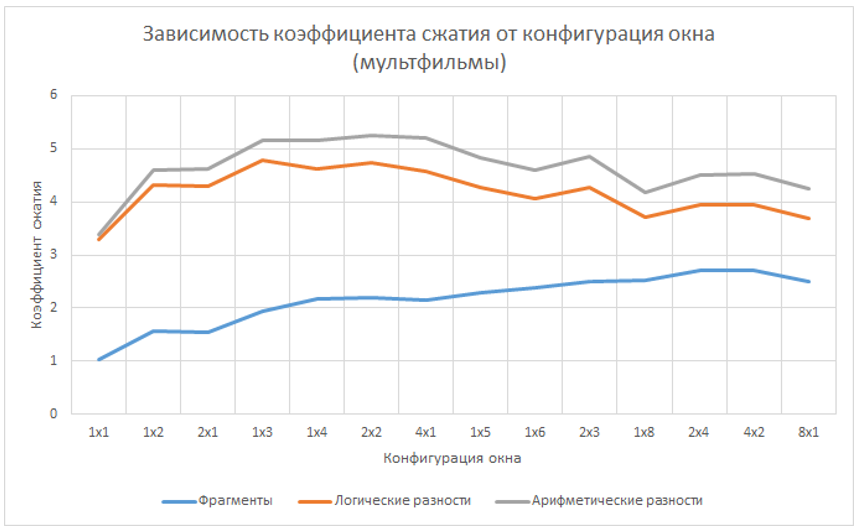
From the presented data it is obvious that the maximum compression ratio can be achieved using windows with an area of three, four or five pixels. Also, in practical use of the method of fragmentary compression of a video stream, it is necessary to take into account that with a fixed window area the highest compression efficiency is observed when using a rectangular window with a ratio of the sides close to 2/1.
The results discussed earlier were related to the coding situation of a video stream containing only the luminance component (the so-called monochrome video stream). Of greater practical interest are methods that allow encoding color video streams.
The easiest way to encode a color video stream is to independently encode color channels. The way in which the element bases collected for independent color channels were combined into one common base was also considered. In spite of the fact that the base share in transmission decreased at the same time, the increase in compression efficiency was insignificant. It was also shown that the efficiency of the fragmentary compression method in YIQ space is significantly higher than in the RGB space. Primarily, this effect is associated with losses arising from the transformation of color spaces.


It is also worth noting that the compression efficiency in the YIQ space can be significantly improved due to coarse quantization of the color difference channels.
To date, there are methods to compress video streams without loss. Some of them are highly specialized and effective only on one type of video streams (for example, on screen recordings), other methods are effective on different video streams. This section is devoted to comparing the effectiveness of the proposed method of fragmentary compression of a video stream with known methods.
In the Graphics & Media Lab Video Group at Moscow State University. Lomonosov was carried out an extensive comparison of lossless video compression algorithms for a variety of parameters (compression speed, resource consumption, compression efficiency, etc.). The most important characteristic is compression efficiency. By this criterion, the following codecs were analyzed:
The comparison was performed on standard test sequences. Each video sequence was compressed by each codec independently. The results are shown in the graph:

For convenience of analysis, the resulting values of compression ratios were averaged, and the resulting average estimates are given below:
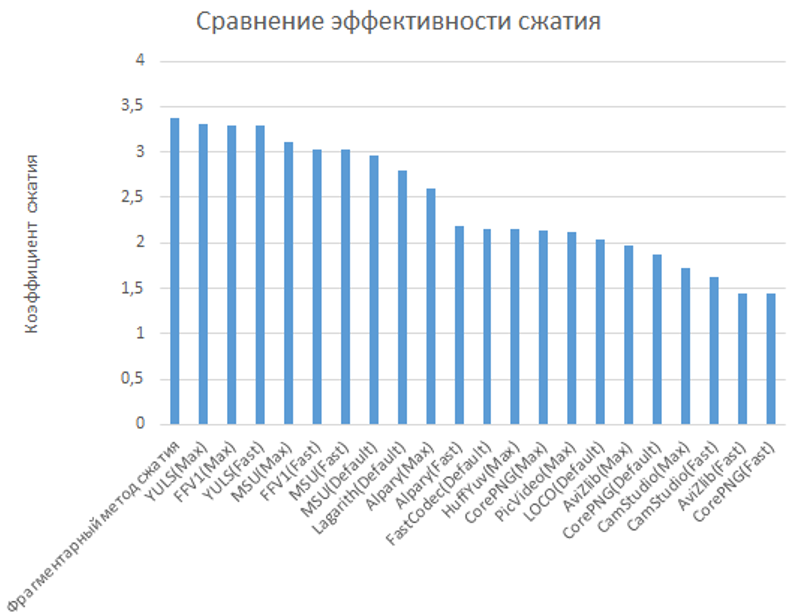
Direct application of the fragmented compression method on these test video sequences is ineffective. This is explained by the fact that the duration of the test video streams is very small and the essential element in the film compressed by the fragmentary compression method is the base of the elements:

With a sufficient duration of the video stream (from 5,000 frames), the average compression ratio of the fragmented compression method is 3.38, which exceeds the compression ratios of the best methods considered.
If the community is interested, I’ll tell you about the secant tree, which made it possible to achieve such a very good result.
Terminology used
Before describing the method itself, it is necessary to agree on the terminology used. All terms used are intuitive, but nevertheless, it is worth defining them strictly:
- Pixel is the minimum image unit. The numerical value of a pixel expresses the value of the image brightness function at one point on the screen. The number of bits allocated for coding the brightness is called the color depth and is referred to as bpp;
- Frame - a set of all pixels at a specific point in time. A frame is represented as a two-dimensional array of pixels with a height of N 1 and a width of N 2 pixels.
- Video stream (movie) - a sequence of frames ordered by time. The total number of frames in the film is hereinafter referred to as M.
- The window is a rectangular area of pixels of height n 1 and width n 2 .
- A fragment is a part of the frame bounded by a window.
- The logical difference is the result of applying the modulo 2 addition (exclusive OR) operation to two digital representations of the corresponding fragments in adjacent frames.
- The arithmetic difference is the result of the arithmetic subtraction of the digital representations of the corresponding fragments in adjacent frames.
- Element - as an element, depending on the characteristics of the task, there is either a fragment or various kinds of differences. The digital representation of the element is a bit string of length k. In the case of fragments or logical differences, k = n 1 * n 2 * bpp, and in the case of arithmetic differences, k = n 1 * n 2 * bpp + n 1 * n 2 , since an additional sign bit is required for each window pixel.
- The volume of the film (N f ) - the total number of elements in the film. N f = (N 1 * N 2 * M) / (n 1 * n 2 )
- The frequency of the element - the ratio of the number of occurrences of this element in the film to the volume of the film.
- Base elements - a set of all elements present in the video stream and their frequencies. The power of the base elements is denoted by N b .
- Element code is a binary code that uniquely identifies an element in the database.
The main idea of the fragmentary compression method
The main idea of the fragmentary compression method is to represent a video stream in the form of a chain of elements of length N f from the base of elements. Since the video stream is a set of meaningful images (frames), rather slowly varying in time, one should expect a significant correlation both between adjacent elements of one frame and between corresponding elements on neighboring frames. This should lead to two effects:
- Relatively low base power (N b ) relative to the power of the set of all possible fragment values (2 k f ) even with a sufficiently large movie volume;
- Significant irregularity of the frequency of occurrences of various elements from the base elements in the film. This should allow the use of efficient entropy coding-compression algorithms for a chain of elements in a video stream.
Thus, the main idea of the fragmentary compression method is to represent the video stream as a well-compressible sequence of elements from some specially compiled element base. The experiments conducted by the authors confirm this hypothesis.
The concept of the method allows the video stream to be compressed both lossless and lossy. In the case of lossy compression, both preprocessing (filtering) is possible, smoothing the original image, and post-processing, consisting in analyzing the element base and then isolating and removing both random noise and visually redundant information from the video stream. Sharing pre-and post-processing allows you to create a new compressed video stream with the desired properties.
The method of fragmented compression can be represented as a sequence of four steps:
- The formation of the base elements. In the case of lossy compression, pre-filtering of video stream frames is possible;
- Analysis of the obtained base of elements and its frequency characteristics;
- Construction of short codes for the elements of the base;
- Formation of the compressed film transmission scheme.
These steps are discussed in more detail below.
The formation of the base elements
The process of forming the base of elements is one of the most resource-intensive steps of the fragmentary compression method. The final compression rate depends largely on how effectively this stage is performed.
Due to the extremely high requirements for speed, the algorithm for forming the base of elements is performed in several stages, with different algorithms and data structures being used at each step.
The formation of the base elements of the frame - the first and easiest step. At this stage, the next frame is received from the video stream, pre-processed if necessary, and, depending on the type of element, the corresponding “pseudo frame” is formed.
When viewing a pseudo frame, the window shifts n 2 pixels in width and n 1 pixels in height. The figure shows an example of a frame of N 1 = 30 rows on N 2 = 45 columns, the viewing is performed using the square window n 1 = n 2 = 5. The thin lines in the figure show individual pixels, the thick lines show the borders of the window, and the numbers inside the window show the sequence number when viewed.
If the elements are logical or arithmetic differences, then the scan will result in the following set of differences:
For most real-life movies, the assumption is that there is a significant correlation between the corresponding elements in the neighboring frames. This is also seen in the table: most of the elements correspond to zero differences. To save memory, the resulting base elements of the frame is compacted. First, sorting is performed by some efficient algorithm, and then the matching elements are combined into one record. That is, instead of 48 zero differences in the compacted base there will be only one record.
At the second stage, the compacted base elements of the frame are recorded in a special buffer of elements - a separate memory area where a plurality of frame bases are accumulated, and then one large block is written to the global storage. The peculiarity of the buffer is that any element can have random access by index, i.e. in fact, it’s just a large array of elements located in RAM:
It is also worth noting that the base elements of the frame are recorded in the buffer "as is" without any additional re-sorting. This leads to the fact that the buffer contains a lot of ordered sequences of elements, but it is not ordered:
When there is not enough space to record the next frame base, the procedure for updating the list of actually encountered items is called.
At the third stage, the elements accumulated in the buffer are moved to a special global storage, which is a simply connected list of elements, ordered by their values. The representation of the global storage in the form of a list does not allow performing random access in constant time, but it does allow adding and deleting elements in constant time.
Before adding the items from the buffer to the global storage, the procedure of sorting and compacting the buffer already discussed earlier is performed. This allows you to add items in a linear time relative to the size of the list:
Three considered stages operate with data placed in the RAM. The final stage involves working with data placed on hard drives. In the overwhelming majority of cases, a sufficiently powerful modern computer allows you to fully assemble the base of elements in RAM, but there are situations when there is not enough RAM to place the entire base there (for example, if a common base is formed for hundreds of hours of shooting). In this case, it is necessary to save the received bases to disk as the RAM is exhausted, and then perform the procedure of merging the databases.
Thus in the process of forming the base of elements the following sequence of steps is performed:
Analysis of the obtained base of elements and its frequency characteristics
Analysis of the base of the elements involves the analysis of both the individual values of each element and the frequency characteristics of the base. This allows, firstly, to choose effective combinations of compression methods (building short codes and methods of their transmission), and, secondly, in the case of lossy compression, consciously reduce the base (filtering).
Construction of short codes for base elements
The base of elements includes an array of N b lines of length k bits and a table of frequencies of the appearance of these lines in a video stream (film). This information is sufficient for applying well-known entropy coding methods (Huffman tree, arithmetic coding, etc.). The listed algorithms have very high efficiency scores, but their actual use is associated with significant implementation difficulties.
For the construction of short codes of elements, the authors propose and use the method of constructing prefix codes proposed by them earlier with the help of cutting functions. In this method, the short codes of the elements of the base are based on the content of the rows of the elements themselves. The author proved that the average length of such codes does not exceed the value of H b * 1,049, where H b is the entropy of the base of elements, calculated from the frequency of occurrence of elements in the video stream. In numerical experiments with real films, H b never exceeded 20, which means that H b * 1,049 <H b +1, from which it follows that the average length of secant codes fits into the same prior estimates of redundancy that Shannon-Fano and Huffman At the same time, encoding with the help of secant functions is devoid of the disadvantages that arise when encoding and decoding the above-mentioned methods of large digital arrays (N b ≈ 10 7 -10 9 ).
Formation of the compressed film transmission scheme
In a compressed video stream, the elements are replaced with the previously received short codes. When playing a compressed video stream, a decoding problem arises. For decoding, it is necessary to have information on the compliance of short codes and base elements. The simplest way to transfer such information is the direct transfer of the element and its frequency (number of occurrences). This method involves the transfer of the base itself, as well as an additional 64 bits for each element. After receiving the data, the receiving party itself must build a code tree using a previously reported algorithm.
A method was proposed for recording and transmitting a tree, in whose leaves the entire base of elements is recorded. The volume of the transmission is equal to the base volume plus two additional bits for each base element ((k + 2) * N b ).
We agree on the tree traversal order: for example, we will use a wide traversal. If a dividing tree node is encountered, then bit 0 is transmitted, if a leaf was detected during the traversal, then bit 1 and the corresponding base element are transmitted. As a result, it is easy to show that only 2 extra bits are additionally transmitted to each base element. The figure shows the representation of a binary tree as a binary string using the described method:
The specified representation is reversible: for each line constructed by the described method, it is possible to build an initial code tree. In addition to the obvious memory savings, the described transmission method eliminates the need to build a code tree during decoding (it is restored in a natural way). That is, a code tree is built only once during compression.
Thus, the paper proposes a scheme for transmitting a video stream consisting of two parts: a code tree with base elements and a chain of compressed element codes.
The approximate structure of the compressed video stream is shown in the figure:
Selection of algorithm parameters
The degree of compression provided by the fragmented compression algorithm largely depends on the properties and characteristics of the formed base of elements. The main characteristics of the base are the size (number of elements) and frequency characteristics (primarily entropy).
To estimate the achievable compression ratio, we use the following formulas. Let l cf - the average length of the codes of the elements of the base, then the volume of the compressed transmission is V s = N b (k + 2) + l cf * N f , and the volume of the uncompressed film is equal to V f = N f * k.
The compression ratio is the value:
R SG = V SG / V f . The inverse of the compression ratio is called the compression ratio and is denoted by K contra .
The main goal to strive for is maximization of K szh . In the formula above, N 1 , N 2 , M, bpp are the characteristics of the original video stream, which we cannot influence. And the values of l cf , N bases depend on the area and configuration of the scan window (n 1 , n 2 ). Those. The only variable parameters in the fragmented compression method are the geometric dimensions of the window.
For any window size, there is a maximum possible base volume of 2 bpp * n 1 * n 2 , and this value is growing extremely fast. Of course, in real films there are far from all possible elements, but with an increase in the window size, the number of bits needed to represent the corresponding base element also grows. In addition, a significant number (more than 70% of the total) of elements appears that occur in the video stream no more than once. In the end, all these effects lead to a decrease in the compression ratio.
On the other hand, too small a window size will lead to an increase in N f and a restriction on N b , which in turn will cause the elements to repeat more evenly and the “tilting” of frequencies will smooth out. The more evenly the elements of the base are repeated, the closer its entropy is to log 2 N b . This, in turn, also leads to a decrease in the compression ratio.
Consider the two extreme cases window 1 * 1 and window N 1 * N 2 . And in the first and in the second case, K szh ≈1. In the process of research, it was found that the dependence of K cr on the scan window area (n 1 * n 2 ) has approximately the following form:
The task is to find the point where the compression level is maximum. Since the level of compression largely depends on the characteristics of the film; it is clear that there is no “ideal” configuration that will give the optimum compression for all films. But the experiments allowed to find a relatively small area where compression is optimal.
All analyzed video streams were divided into two groups depending on their features:
- Natural shooting. This group includes most movies, TV shows and amateur filming. For films of this group is characterized by a smooth change of frames over time. The changes are rather smooth and concentrated in the center of the frame. The background is in most cases uniform, but slight variations in brightness are possible.
To select the optimal configuration of the window, the video streams belonging to each group were compressed using the fragmentary compression method. During the research, all possible configurations of windows ranging from one to eight pixels were analyzed (logical differences were used as elements). In total, about ten thousand hours of video were analyzed, which is about a billion frames. The results are presented in graphs.
From the presented data it is obvious that the maximum compression ratio can be achieved using windows with an area of three, four or five pixels. Also, in practical use of the method of fragmentary compression of a video stream, it is necessary to take into account that with a fixed window area the highest compression efficiency is observed when using a rectangular window with a ratio of the sides close to 2/1.
Video encoding in various color spaces
The results discussed earlier were related to the coding situation of a video stream containing only the luminance component (the so-called monochrome video stream). Of greater practical interest are methods that allow encoding color video streams.
The easiest way to encode a color video stream is to independently encode color channels. The way in which the element bases collected for independent color channels were combined into one common base was also considered. In spite of the fact that the base share in transmission decreased at the same time, the increase in compression efficiency was insignificant. It was also shown that the efficiency of the fragmentary compression method in YIQ space is significantly higher than in the RGB space. Primarily, this effect is associated with losses arising from the transformation of color spaces.
It is also worth noting that the compression efficiency in the YIQ space can be significantly improved due to coarse quantization of the color difference channels.
Comparison of the effectiveness of the fragmentary video compression method with the methods used
To date, there are methods to compress video streams without loss. Some of them are highly specialized and effective only on one type of video streams (for example, on screen recordings), other methods are effective on different video streams. This section is devoted to comparing the effectiveness of the proposed method of fragmentary compression of a video stream with known methods.
In the Graphics & Media Lab Video Group at Moscow State University. Lomonosov was carried out an extensive comparison of lossless video compression algorithms for a variety of parameters (compression speed, resource consumption, compression efficiency, etc.). The most important characteristic is compression efficiency. By this criterion, the following codecs were analyzed:
- Alpary
- Arithyuv
- AVIzlib
- CamStudio GZIP
- Corepng
- Fastcode
- FFV1
- Huffyuv
- Lagarith
- LOCO
- Lzo
- MSU Lab
- PICVideo
- Snow
- x264
- Yuls
The comparison was performed on standard test sequences. Each video sequence was compressed by each codec independently. The results are shown in the graph:
For convenience of analysis, the resulting values of compression ratios were averaged, and the resulting average estimates are given below:
Direct application of the fragmented compression method on these test video sequences is ineffective. This is explained by the fact that the duration of the test video streams is very small and the essential element in the film compressed by the fragmentary compression method is the base of the elements:
With a sufficient duration of the video stream (from 5,000 frames), the average compression ratio of the fragmented compression method is 3.38, which exceeds the compression ratios of the best methods considered.
If the community is interested, I’ll tell you about the secant tree, which made it possible to achieve such a very good result.
')
Source: https://habr.com/ru/post/252445/
All Articles