Auto registration of tests on C language tools
 More recently, there was an article “Semi-automatic registration of unit tests on pure C” in which the author demonstrated the solution of the problem using counters from Boost. Following the same principle, a (successful) attempt was made to repeat this experience without using Boost for reasons of the illogicality of having a C dependence on Boost in a project, and also in such a small amount. At the same time, there were a lot of preprocessor support directives in the tests. And everything would have remained so, but practically at the final stage an alternative method of registration was found, which allows completely get rid of additional actions. This is a C89 solution for registering tests and a slightly more system-demanding solution for registering test suites.
More recently, there was an article “Semi-automatic registration of unit tests on pure C” in which the author demonstrated the solution of the problem using counters from Boost. Following the same principle, a (successful) attempt was made to repeat this experience without using Boost for reasons of the illogicality of having a C dependence on Boost in a project, and also in such a small amount. At the same time, there were a lot of preprocessor support directives in the tests. And everything would have remained so, but practically at the final stage an alternative method of registration was found, which allows completely get rid of additional actions. This is a C89 solution for registering tests and a slightly more system-demanding solution for registering test suites. The motivation of all this is simple and clear, but for the sake of completeness it is worth briefly identifying it. In the absence of auto-registration, one has to deal with either typing / inserting a repeating code, or generators external to the compiler. The first is reluctant to do plus the exercise itself is error prone, the second adds unnecessary dependencies and complicates the build process. The idea of using C ++ in tests only for the sake of this opportunity, when everything else is written in C, evokes a feeling of firing from a cannon at sparrows. To all this, in principle, it is interesting to solve the problem at the same level at which it arose.
We define the final goal as something like the code below with the additional condition that test names are not repeated anywhere except where they are defined, i.e. they are dialed once and only once and then not copied by any oscillator.
')
TEST(test1) { /* Do the test. */ } TEST(test2) { /* Do the test. */ } After a small digression to introduce certainty in the terminology, it will be possible to start searching for a solution.
Terminology and proposed test structure
Different test frameworks are inconsistently using words to designate individual tests or their groups. Therefore, we will define some words explicitly, and at the same time we will show their meaning using the example of a fairly common test structure.
A collection of tests (“suite”) will be understood as a group of test suites (“fixture”). This is the largest structural unit of the hierarchy. The sets in turn group the tests inside the collection. Tests by themselves. The number of elements of each type is arbitrary.
This is graphically:
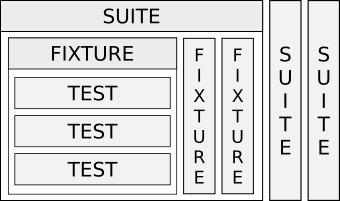
Each higher level combines elements of smaller ones and optionally adds preparation procedures (“setup”) and completion (“teardown”) tests.
Registration of tests in sets
Never let you know your mind.
- ISAAC ASIMOV, Foundation
Separate tests are added more often than whole sets, therefore auto-registration is more relevant for them. Also, they are all located within the same translation unit, which simplifies the solution of the problem.
So, it is necessary to organize the repository of the list of tests by means of the language, without using the preprocessor as the main control element. Failure to preprocessor means that we remain without explicit counters. But the presence of a counter is almost mandatory if it is necessary to uniquely identify tests and, in general, to somehow contact them, and not just declare them. At the same time, there is always a built-in macro
__LINE__ at hand, __LINE__ you need to figure out how to apply it in this situation. There is one more limitation: some explicit assignments to the elements of a global array for the similarity test_type tests[]; static void test(void) { /* Do the test. */ } tests[__LINE__] = &test; they are not suitable, since outside the functions such operations are simply not supported at the language level. The initial situation does not look very rosy:
- There is no possibility to store either intermediate or final state.
- There is no way to identify disconnected elements, and then assemble them together.
- As a result, there is no possibility to define a coherent structure (basically an array, but the list is also suitable, there would be a way), due to the inability to refer to the previous entity.
But not everything is as hopeless as it may seem. Imagine the ideal option, as if we have something that is missing. In this case, the code after the expansion of the auxiliary macros could look something like this:
MagicDataStructure MDS; static void test1(void) { /* Do the test. */ } MDS[__LINE__] = &test1; static void test2(void) { /* Do the test. */ } MDS[__LINE__] = &test2; static void fixture(void) { int i; for (i = 0; i < MDS.length; ++i) { MDS.func[i](); } } Things are easy: implement a “magic” structure, which, by the way, is suspiciously similar to an array of predetermined size. It makes sense to think about how we would work if it were an array in reality:
- You would define an array by initializing all
NULLelements. - Assign values to individual elements.
- Bypass the entire array and call each non-
NULLelement.
This set of operations is all that we need and does not look too unreal, perhaps arrays will really come in handy here. By definition, an array is a collection of similar elements. Usually this is some kind of single entity with support for the indexing operation, but it makes sense to treat the same array as a group of separate elements. Let's say whether this
int arr[4]; either
int arr0, arr1, arr2, arr3; At the moment and in light of the mention of the macro
__LINE__ above, it should already be clear where the author is __LINE__ . It remains to understand how you can implement a pseudo-array with support for assignment at the compilation stage. This seems to be an interesting exercise, so you should wait a little more with the demonstration of the ready-made solution and ask the following questions:- Which entity in C can appear more than once and not cause a compilation error?
- What can be interpreted by the compiler in different ways depending on the context?
Think of header files. After all, what is in them is usually present somewhere else in the code. For example:
/* file.h */ int a; /* file.c */ #include "file.h" int a = 4; /* ... */ In this case, everything works fine. Here is an example closer to the problem:
static void run(void); int main(int argc, char *argv[]) { run(); return 0; } static void run(void) { /* ... */ } Quite a mediocre code that can be slightly extended to achieve the desired functionality:
#include <stdio.h> static void (*run_func)(void); int main(int argc, char *argv[]) { if (run_func) run_func(); return 0; } static void run(void) { puts("Run!"); } static void (*run_func)(void) = &run; The reader is invited to independently verify that changing the order or commenting on the last mention
run_func is consistent with expectations, i.e. if run_func not run_func , then the only element of the “one-element array” ( run_func ) is NULL , otherwise it points to the run() function. The lack of dependence on the order is an important property that allows you to hide all the "magic" in the header file.From the example above, it is easy to make a macro for auto-registration, which declares a function and stores a pointer to it in a variable numbered using the value of the macro
__LINE__ . In addition to the macro itself, it is necessary to list all possible names of pointer variables and call them one by one. Here is an almost complete solution, not counting the presence of "extra" code, which should be hidden in the header file, but these are details: /* test.h */ #define CAT(X, Y) CAT_(X, Y) #define CAT_(X, Y) X##Y typedef void test_func_type(void); #define TEST(name) \ static test_func_type CAT(name, __LINE__); \ static test_func_type *CAT(test_at_, __LINE__) = &CAT(name, __LINE__); \ static void CAT(name, __LINE__)(void) /* test.c */ #include "test.h" #include <stdio.h> TEST(A) { puts("Test1"); } TEST(B) { puts("Test2"); } TEST(C) { puts("Test3"); } typedef test_func_type *test_func_pointer; static test_func_pointer test_at_1, test_at_2, test_at_3, test_at_4, test_at_5, test_at_6; int main(int argc, char *argv[]) { /* , * . */ if (test_at_1) test_at_1(); if (test_at_2) test_at_2(); if (test_at_3) test_at_3(); if (test_at_4) test_at_4(); if (test_at_5) test_at_5(); if (test_at_6) test_at_6(); return 0; } For clarity, it may be useful to look at the result of a macro substitution, which implies that it is impossible to place more than one test in a row, which, however, is more than acceptable.
static test_func_type A4; static test_func_type *test_at_4 = &A4; static void A4(void) { puts("Test1"); } static test_func_type B5; static test_func_type *test_at_5 = &B5; static void B5(void) { puts("Test2"); } static test_func_type C6; static test_func_type *test_at_6 = &C6; static void C6(void) { puts("Test3"); } A link to the full implementation will be provided below.
Why does it work
Now it's time to understand what is happening here, in more detail and answer the question why it works.
If we recall the example with headers, we can distinguish several possible variants of how data members can be represented in the code:
int data = 0; /* (1) */ extern int data; /* (2) */ int data; /* (3) */ (1) unambiguously a definition (and therefore a declaration too) due to the presence of an initializer.(2) is an ad only.(3) (our case) is an ad and, extern keyword and initializer leaves the compiler no choice but to postpone the decision on what this statement is (“statement”). It is this “oscillation” of the compiler that is used to emulate auto-registration.Just in case, a few examples with comments to finally clarify the situation:
int data1; /* , . */ int data2 = 1; /* , - . */ int data2; /* , . */ int data3; /* , , * , . */ int data3 = 1; /* , - . */ /* static . */ static int data4; /* , , * , . */ static int data4 = 1; /* , - . */ static int data4; /* , . */ int data5; /* , . */ int data5; /* , "" . */ int data6 = 0; /* , - . */ int data6 = 0; /* , . */ Two cases are important for us:
- There are only ads. In this case, the variable is initialized with zeros, which can be used to determine the absence of a test in the corresponding line.
- There is at least one ad and exactly one definition. The address of the function with the test is entered into the corresponding variable.
That, in fact, is all that is needed to implement the required operations and get a working automatic registration. This duality of some operators in the text allows you to expand the array element by element and “assign” the values of a part of the array.
Features and disadvantages
It is clear that if we do not want to insert a macro at the end of each test file that would serve as a marker for the last line, then it is necessary to initially lay down on some maximum number of lines. Not the best option, but not the worst. For example, a single test file is unlikely to contain more than a thousand lines, and you can opt for this upper boundary. There is one not very pleasant moment: if in this case the tests are defined on the line with the number greater than 1000, then they will lie dead weight and will never be called. Fortunately, there is a simple “solution” option: it is enough to compile tests with the
-Werror flag (a less rigid option: with -Werror=unused-function ) and similar files will not compile. ( UPD2: in the comments suggested how to solve this issue easier and with automatic interruption of compilation using STATIC_ASSERT . Enough in each TEST macro insert a check for a valid value of __LINE__ .)The sufficiency of the approach with a fixed array is generally not the only reason why it is better to fix the maximum number of rows in advance. If this is not done, the corresponding declarations (in the place where the tests are called) must be generated at compile time, which can significantly slow it down (this is not a guess, but the result of attempts). It's easier not to complicate things here, the benefits of being able to compile files of arbitrary size do not seem to be worth it.
In the example with the
TEST() macro above, you can see the use of a function pointer; this is just one test record, but you probably want to add more. The wrong way to do this is to add parallel pseudo-arrays. This will only increase compile time. The correct way: to use the structure, in this case adding new fields is almost free.For real processing (not copying code) of pseudo-array elements, it is necessary to form a real array. It is not the best solution to place the same function pointers in this array (or copy structures with information about tests), since this will make the initializer not constant. But placing pointers to pointers will make the array static, which frees the compiler from having to generate code to assign values to the stack during execution, as well as shorten the compilation time.
Initially, this solution was born to implement transparent registration of the
setup() / teardown() functions and only then was applied to the tests themselves. In principle, this is suitable for any functionality that can be overridden. Simply insert the pointer declaration and provide a macro to override it, if the macro was not used, the pointer will be zero, otherwise it will be a user-defined value.Compiler messages about top-level errors in tests may surprise with their volume, but this will happen in rather rare cases of the absence of a terminating semicolon and similar syntax errors.
Finally, you can evaluate the result of effort:
Test suite to: | Test suite after: |
Register test suites in collections
It can be used once, while it can be used at least twice.
- D. KNUTH, The Art Of Computer Programming 4A
Close to something in the previous task, but there are a couple of significant differences:
- Interesting characters (functions / data) are defined in different compilation units.
- And, as a result, there is no counter similar
__LINE__.
By virtue of the first item, the trick from the previous section in its pure form will not work here, but the basic idea will remain the same, while the means of its implementation will change a bit.
As mentioned at the beginning, in this part there are some additional requirements for the medium, namely the assembly system, which should be able to assign identifiers to files in the range
[0, N) , where N is the maximum number of test sets. Again, the border is at the top, but, let's say, a hundred sets in each collection of tests should be enough for many.If last time the compiler did all the “dirty work” for us, then this time it was the turn of the compiler to work (aka “linker”). In each translation unit, you must define the entry point using the same file identifier, and in the main file of the test collection, check the characters for presence and call them.
One possible option is to use "weak characters . " In this case, functions are almost always defined as usual, but in the main file they are marked with the
weak attribute (something like this: __attribute__((weak)) ). An obvious disadvantage is the requirement for the support of weak characters on the part of the compiler and linker.If you think a little about the structure of weak symbols, then their similarity with the function pointers becomes noticeable: undefined weak symbols are zero. It turns out that you can do without them: it is enough to define function pointers as before, but without the
static . The use of pointers in explicit form also brings additional benefit in the form of the absence of an automatically generated name in the list of stack frames.On this the first difference from the test suites can be considered reduced to the already known solution. The definition of the order relation between translation units remains. The file itself does not have enough information to accomplish this task, so information from outside is needed. Here, for each build system, there will be its own implementation details, below is an example for GNU / Make .
Determining the order itself is rather trivial, let it be the position of the file name in the sorted list of all the files that make up the test collection. Do not worry about the auxiliary files without tests, they will not interfere, as a maximum, will create gaps in the numbering, which is insignificant. This information will be transmitted through the macro definition using the compiler flag (
-D in this case).Actually, the function to determine the identifier:
pos = $(strip $(eval T := ) \ $(eval i := 0) \ $(foreach elem, $1, \ $(if $(filter $2,$(elem)), \ $(eval i := $(words $T)), \ $(eval T := $T $(elem)))) \ $i) The first argument is a list of all file names, and the second is the name of the current file. Returns the index. The function is not the most trivial in appearance, but it does its job regularly.
Adding
TESTID (here $(OBJ) stores the list of object files): %.o: %.c $(CC) -DTESTID=$(call pos, $(OBJ), $@) -c -o $@ $< On this, almost all difficulties are overcome and it remains only to use an identifier in the code, for example, like this:
#define FIXTURE() \ static void fixture_body(void); \ void (*CAT(fixture_number_, TESTID))(void) = &fixture_body; \ static void fixture_body(void) In the main file of the test collection there should be appropriate declarations and their bypass.
Remaining difficulties
If the number of files increases above the set limit, some of them may “fall out” of our field of vision as it could have happened with the tests. This time, the solution will require additional verification of the compile time. With a pre-known number of files in the collection, it is easy to check whether they will not be redundant. In fact, it is enough to provide each translation unit with access to this information using another macro:
... -DMAXTESTID=$(words $(OBJ)) ... It remains only to add a check for a sufficient number of ads using something like:
#define STATIC_ASSERT(msg, cond) \ typedef int msg[(cond) ? 1 : -1]; \ /* Fake use to suppress "Unused local variable" warning. */ \ enum { CAT(msg, _use) = (size_t)(msg *)0 } There is a somewhat less obvious problem of conflict (duplicate definition) of functions when adding / removing test suite files. Such changes cause an offset of the indices and require recompilation of all files affected by this. Here it is worth remembering checking the dates of modification of files by systems of the assembly and updating the date of the directory when its composition changes, i.e. in fact, each compiled file must be added depending on the directory in which it is located.
As a result, the rule for compiling a file with tests takes a similar form:
%.o: %.c $(dir %.c)/. $(CC) -DTESTID=$(call pos, $(OBJ), $@) -DMAXTESTID=$(words $(OBJ)) -c -o $@ $< Putting it all together, you can observe the following transformation of the test collection definition:
Test collection before: | A collection of tests after: |
Additional optimizations
The need for periodic recompilation and a slight slowdown in the processing of each file make you think about ways to compensate for these costs. Recall some of the available features.
Precompiled header. Once complex code is long processed by the compiler, it will be logical to prepare the result of processing once and reuse it.
Use ccache to speed up recompilation. A good idea by itself, for example, allows you to switch between repository branches an unlimited number of times and not wait for a complete recompilation: the total time will be determined first of all by the speed of pulling data from the cache.
-pipe compiler flag (if supported). Reduce the number of file operations through the use of additional RAM.
. , .
? , :
- .
- , ( ) 6,5 . — 13 ., , 5,5 . 5,7 ., ( ) .
Links
seatest , , -. seatest stic ( C99, ), . , stic.h . . Makefile ( ).
Results
Wikipedia , stic - C (, ). ( UPD: C++, , , , ). , ( -
#ifdef , ) . , : TEST(os_independent) { /* ... */ } TEST(unix_only, IF(not_windows)) { /* ... */ } , , , seatest, 3911 , 16% .
Source: https://habr.com/ru/post/252439/
All Articles