Writing a search plugin for Elasticsearch
Elaticsearch is a popular search engine and NoSQL database. One of its interesting features is the support of plug-ins, which can extend the built-in functionality and add a bit of business logic to the search level. In this article I want to talk about how to write such a plugin and tests to it. 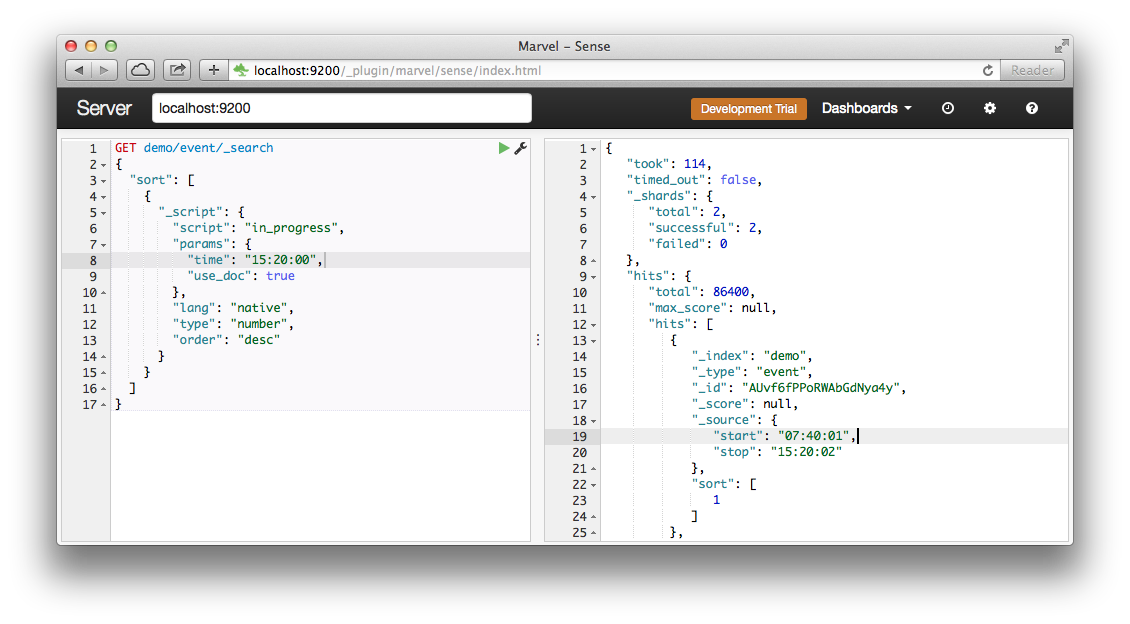 Just want to make a reservation that the task in this article is greatly simplified so as not to clutter up the code. For example, in one of the real applications a full schedule with exceptions is stored in the document, and on the basis of them the script calculates the necessary values. But I would like to focus on the plugin itself, so the example is very simple.
Just want to make a reservation that the task in this article is greatly simplified so as not to clutter up the code. For example, in one of the real applications a full schedule with exceptions is stored in the document, and on the basis of them the script calculates the necessary values. But I would like to focus on the plugin itself, so the example is very simple.
It is also necessary to mention that I am not an Elasticsearch committer, the information presented is mainly obtained by trial and error, and may be incorrect in some way.
So, suppose that we have an Event document with start and stop properties that store time as a string in the format “HH: MM: SS”. The task is for the specified time to sort the events so that the active events (start <= time <= stop) are at the beginning of the output. An example of such a document:
')
For a basis I took an example from one of the Elasticsearch developers . A plugin consists of one or more scripts that need to be registered:
The script consists of two parts: the NativeScriptFactory factory, and the script itself, inheriting AbstractSearchScript. The factory is creating a script (and at the same time validating the parameters). It is worth noting that the script is created only 1 time for the search (on each shard), so initialization / processing of parameters should be done at this stage.
The client application must pass the following parameters to the script:
So, the script is created and ready to go. In the script, the most important is the run () method:
This method is called for each document, so it is worth paying special attention to what is happening inside it, and how quickly. This has a direct impact on the performance of the plugin.
In general, the algorithm here is:
To access the document data, use one of the methods source (), fields (), or doc (). Looking ahead, I will say that doc () is much faster source () and if possible it is worth using it.
In this example, based on the document data, I create a model for further work.
(in trivial cases, of course, you can simply use the data from the document, and immediately return the result, and it would be faster)
The result in our case is “1” for the events that are happening now (start <= time <= stop), and “0” for all the others. Result type - Integer, since sort by Boolean Elasticsearch can not.
After processing the script for each document, the value will be determined by which Elasticsearch will sort them. Mission accomplished!
Besides the fact that tests are good in themselves, it is also a great entry point for debugging. It is very convenient to set breakpoint, and run the debug of the desired test. Without this, debugging the plugin would be very difficult.
The scheme of integration testing of the plugin is approximately as follows:
To run the test server, let's use the ElasticsearchIntegrationTest base class. You can customize the number of nodes, shards and replicas. Read more at GitHub .
Perhaps there are two ways to create test documents. The first is to build a document directly in the test - an example can be found here . This option is quite good, and at first I used it. However, the scheme of documents is changing, and over time it may turn out that the structure built in the test no longer corresponds to reality. Therefore, the second method is to store the mapping and data separately as resources. In addition, this method makes it possible in case of unexpected results on live servers just to copy the problem document as a resource and see how the test falls. In general, any method is good, the choice is yours.
To query the result of the script calculation, we use the standard Java client:
An optional part of the program is the integration with the Continuous Integration system of Travis . Add a .travis file:
So, the plugin is ready and tested. It's time to try it out.
About the installation of plug-ins can be found in the official documentation . The assembled plugin is in ./target. To facilitate local installation, I wrote a small script that builds the plugin and installs it:
The script is written for Mac / brew. For other systems, you may have to correct the path to the plugin file. In Ubuntu, it is located in / usr / share / elasticsearch / bin / plugin. After installing the plugin, do not forget to restart Elasticsearch.
A simple test document generator is written in Ruby.
We ask Elasticsearch to sort all events by the result of the “in_progress” script:
Result:
can not be compared in speed with a simple sort (2 ms), but still not bad for a laptop. In addition, the scripts are run in parallel in different shards and thus scaled.
As I wrote at the beginning, the script has several methods for accessing the contents of the document. These are source (), fields (), and doc (). Source () is a convenient and slow way. When requested, the entire document is loaded into HashMap. But then everything is available. Doc () is access to the indexed data, it is much faster, but working with it is a bit more difficult. First, the Nested type is not supported, which imposes restrictions on the structure of the document. Secondly, the indexed data may differ from what is in the document itself, first of all it concerns lines. As an experiment, you can try removing “index”: “not_analyzed” in mapping.json, and see how it all breaks down. As for the fields () method, to be honest, I never tried it, judging by the documentation, it is little better than source ().
Now let's try to use source () by changing the use_doc parameter to false.
The script from the plugin can be used not only for sorting, but in general in any places where scripts are supported. For example, you can calculate the value for the found documents. In this case, by the way, productivity is no longer so important, since calculations are made for a filtered and limited set of documents.
That's all, thank you for reading!
GitHub source code: github.com/s12v/elaticsearch-plugin-demo
PS By the way, we really need experienced programmers and system administrators to work on a large project based on AWS / Elasticsearch / Symfony2 in Berlin. If suddenly you are interested - write!
Just want to make a reservation that the task in this article is greatly simplified so as not to clutter up the code. For example, in one of the real applications a full schedule with exceptions is stored in the document, and on the basis of them the script calculates the necessary values. But I would like to focus on the plugin itself, so the example is very simple.It is also necessary to mention that I am not an Elasticsearch committer, the information presented is mainly obtained by trial and error, and may be incorrect in some way.
So, suppose that we have an Event document with start and stop properties that store time as a string in the format “HH: MM: SS”. The task is for the specified time to sort the events so that the active events (start <= time <= stop) are at the beginning of the output. An example of such a document:
')
{ "start": "09:00:00", "stop": "18:30:00" } Plugin
For a basis I took an example from one of the Elasticsearch developers . A plugin consists of one or more scripts that need to be registered:
public class ExamplePlugin extends AbstractPlugin { public void onModule(ScriptModule module) { module.registerScript(EventInProgressScript.SCRIPT_NAME, EventInProgressScript.Factory.class); } } Source code completelyThe script consists of two parts: the NativeScriptFactory factory, and the script itself, inheriting AbstractSearchScript. The factory is creating a script (and at the same time validating the parameters). It is worth noting that the script is created only 1 time for the search (on each shard), so initialization / processing of parameters should be done at this stage.
The client application must pass the following parameters to the script:
- time - a string in the format "HH: MM: SS", the point in time that interests us
- use_doc - determines which method to use to access the document data (more on that later)
public static class Factory implements NativeScriptFactory { @Override public ExecutableScript newScript(@Nullable Map<String, Object> params) { LocalTime time = params.containsKey(PARAM_TIME) ? new LocalTime(params.get(PARAM_TIME)) : null; Boolean useDoc = params.containsKey(PARAM_USE_DOC) ? (Boolean) params.get(PARAM_USE_DOC) : null; if (time == null || useDoc == null) { throw new ScriptException("Parameters \"time\" and \"use_doc\" are required"); } return new EventInProgressScript(time, useDoc); } } Source code completelySo, the script is created and ready to go. In the script, the most important is the run () method:
@Override public Integer run() { Event event = useDoc ? parser.getEvent(doc()) : parser.getEvent(source()); return event.isInProgress(time) ? 1 : 0; } Source code completelyThis method is called for each document, so it is worth paying special attention to what is happening inside it, and how quickly. This has a direct impact on the performance of the plugin.
In general, the algorithm here is:
- We read the document data we need
- Calculate the result
- We return it to Elasticsearch
To access the document data, use one of the methods source (), fields (), or doc (). Looking ahead, I will say that doc () is much faster source () and if possible it is worth using it.
In this example, based on the document data, I create a model for further work.
public class Event { public static final String START = "start"; public static final String STOP = "stop"; private final LocalTime start; private final LocalTime stop; public Event(LocalTime start, LocalTime stop) { this.start = start; this.stop = stop; } public boolean isInProgress(LocalTime time) { return (time.isEqual(start) || time.isAfter(start)) && (time.isBefore(stop) || time.isEqual(stop)); } } (in trivial cases, of course, you can simply use the data from the document, and immediately return the result, and it would be faster)
The result in our case is “1” for the events that are happening now (start <= time <= stop), and “0” for all the others. Result type - Integer, since sort by Boolean Elasticsearch can not.
After processing the script for each document, the value will be determined by which Elasticsearch will sort them. Mission accomplished!
Integration tests
Besides the fact that tests are good in themselves, it is also a great entry point for debugging. It is very convenient to set breakpoint, and run the debug of the desired test. Without this, debugging the plugin would be very difficult.
The scheme of integration testing of the plugin is approximately as follows:
- Run test cluster
- Create index and mapping
- Add a document
- Ask the server to calculate the value of the script for the specified parameters and document
- Make sure the value is correct.
To run the test server, let's use the ElasticsearchIntegrationTest base class. You can customize the number of nodes, shards and replicas. Read more at GitHub .
Perhaps there are two ways to create test documents. The first is to build a document directly in the test - an example can be found here . This option is quite good, and at first I used it. However, the scheme of documents is changing, and over time it may turn out that the structure built in the test no longer corresponds to reality. Therefore, the second method is to store the mapping and data separately as resources. In addition, this method makes it possible in case of unexpected results on live servers just to copy the problem document as a resource and see how the test falls. In general, any method is good, the choice is yours.
To query the result of the script calculation, we use the standard Java client:
SearchResponse searchResponse = client() .prepareSearch(TEST_INDEX).setTypes(TEST_TYPE) .addScriptField(scriptName, "native", scriptName, scriptParams) .execute() .actionGet(); Source code completelyIntegration with Travis-CI
An optional part of the program is the integration with the Continuous Integration system of Travis . Add a .travis file:
language: java jdk: - openjdk7 - oraclejdk7 script: - mvn test and the CI server will test your code after each change, it looks like this . Trifle, but nice.Application
So, the plugin is ready and tested. It's time to try it out.
Installation
About the installation of plug-ins can be found in the official documentation . The assembled plugin is in ./target. To facilitate local installation, I wrote a small script that builds the plugin and installs it:
mvn clean package if [ $? -eq 0 ]; then plugin -r plugin-example plugin --install plugin-example --url file://`pwd`/`ls target/*.jar | head -n 1` echo -e "\033[1;33mPlease restart Elasticsearch!\033[0m" fi SourceThe script is written for Mac / brew. For other systems, you may have to correct the path to the plugin file. In Ubuntu, it is located in / usr / share / elasticsearch / bin / plugin. After installing the plugin, do not forget to restart Elasticsearch.
Test data
A simple test document generator is written in Ruby.
bundle install ./generate.rb Test request
We ask Elasticsearch to sort all events by the result of the “in_progress” script:
curl -XGET "http://localhost:9200/demo/event/_search?pretty" -d' { "sort": [ { "_script": { "script": "in_progress", "params": { "time": "15:20:00", "use_doc": true }, "lang": "native", "type": "number", "order": "desc" } } ], "size": 1 }' Result:
{ "took" : 139, "timed_out" : false, "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "hits" : { "total" : 86400, "max_score" : null, "hits" : [ { "_index" : "demo", "_type" : "event", "_id" : "AUvf6fPPoRWAbGdNya4y", "_score" : null, "_source":{"start":"07:40:01","stop":"15:20:02"}, "sort" : [ 1.0 ] } ] } } It can be seen that the server counted the values for 86400 documents in 139 milliseconds. Of course itcan not be compared in speed with a simple sort (2 ms), but still not bad for a laptop. In addition, the scripts are run in parallel in different shards and thus scaled.
Source () and doc () methods
As I wrote at the beginning, the script has several methods for accessing the contents of the document. These are source (), fields (), and doc (). Source () is a convenient and slow way. When requested, the entire document is loaded into HashMap. But then everything is available. Doc () is access to the indexed data, it is much faster, but working with it is a bit more difficult. First, the Nested type is not supported, which imposes restrictions on the structure of the document. Secondly, the indexed data may differ from what is in the document itself, first of all it concerns lines. As an experiment, you can try removing “index”: “not_analyzed” in mapping.json, and see how it all breaks down. As for the fields () method, to be honest, I never tried it, judging by the documentation, it is little better than source ().
Now let's try to use source () by changing the use_doc parameter to false.
Request
And now “took”: 587 milliseconds, i.e. 4 times slower. In a real application with large documents, the difference can be hundreds of times. curl -XGET "http://localhost:9200/demo/event/_search?pretty" -d' { "sort": [ { "_script": { "script": "in_progress", "params": { "time": "15:20:00", "use_doc": false }, "lang": "native", "type": "number", "order": "desc" } } ], "size": 1 }' Other uses of the script
The script from the plugin can be used not only for sorting, but in general in any places where scripts are supported. For example, you can calculate the value for the found documents. In this case, by the way, productivity is no longer so important, since calculations are made for a filtered and limited set of documents.
curl -XGET "http://localhost:9200/demo/event/_search" -d' { "script_fields": { "in_progress": { "script": "in_progress", "params": { "time": "00:00:01", "use_doc": true }, "lang": "native" } }, "partial_fields": { "properties": { "include": ["*"] } }, "size": 1 }' Result
{ "took": 2, "timed_out": false, "_shards": { "total": 2, "successful": 2, "failed": 0 }, "hits": { "total": 86400, "max_score": 1, "hits": [ { "_index": "demo", "_type": "event", "_id": "AUvf6fO9oRWAbGdNyUJi", "_score": 1, "fields": { "in_progress": [ 1 ], "properties": [ { "stop": "00:00:02", "start": "00:00:01" } ] } } ] } } That's all, thank you for reading!
GitHub source code: github.com/s12v/elaticsearch-plugin-demo
PS By the way, we really need experienced programmers and system administrators to work on a large project based on AWS / Elasticsearch / Symfony2 in Berlin. If suddenly you are interested - write!
Source: https://habr.com/ru/post/252067/
All Articles