Creating a cloud network: not so simple

Translator's note: Ruxit network monitoring service engineer Alois Mayr wrote interesting material about the difficulties that new users may encounter when organizing a network in the cloud, and we prepared an adapted translation for it.
If your applications run on AWS [eng. Amazon Web Services] or one of these cloud platforms (such as 1cloud ), which means that you, among other things, successfully “shifted” your work with your network to cloud services. Naturally, for you it can be very valuable, primarily because you do not need to maintain the physical infrastructure of the network. However, the lack of direct access to the network does not mean that it does not need to be followed at all.
')
A bit of history
In traditional types of application architecture, the network infrastructure was under the strict control of a team of specialists. Such teams were responsible for replacing overloaded equipment before any problems occurred, identifying and eliminating weak links in the network, solving performance problems, tracking data transmission delay parameters, and even detecting network security threats. In other words, the usual networking team followed all seven levels of the OSI model.
Modern architectures need network technologies more than ever.
In cloud-based architectures, the situation is different, and now the use of networks plays a much larger role. Imagine a typical cloud-based architecture. You operate a data center with a variable number of computers allocated for operation (depending, for example, on the pricing mechanism and changing processor requirements). Your data center serves distributed applications that are designed, for example, based on microservices. In addition, your applications are distributed, say, using Docker containers , which gives your team the DevOps methodology [ Eng. Development Operations ], some leeway. In such situations, the presence of networks is needed more than ever. Your network should take over all communications necessary for the communication of microservices. It serves as a virtual “nervous system” for your applications.
Even though system administrators do not have direct access to the network, it nevertheless works and requires attention. It is often difficult to find out where your servers are located physically or how they are connected to other nodes in your network. Virtual machines and related services can even be hosted on the same virtual host; in this case, your network can only read data from memory. This means that quite often the physical network is connected to several virtual networks.
Difficulties when working with networks using cloud services
Due to the lack of direct access to the network (layers 1-2 of the OSI model), teams that adhere to the principles of DevOps find it difficult to keep track of it. They can use the monitoring tools offered by cloud providers, such as Cloud Watch, to read network performance indicators such as NetworkIn and NetworkOut, but these indicators may not be enough to identify network problems.
The following are some of the main difficulties encountered when using the DevOps methodology to maintain virtual network performance:
- The distribution of network resources between competing processes (for example, a problem known as TCP Incast );
- The changing network infrastructure in the presence of new or suspended objects;
- Network Scalability with ENI Network Interfaces [ eng. Elastic Network Interfaces ];
- The quality of the internal connections of the data center;
- The quality of connections to private networks located outside the data center.
Network usage monitoring
When monitoring the network, you should be able to adapt to the changes in infrastructure mentioned above. In particular, you need to be able to work with virtual network interfaces. In this regard, monitoring should be carried out on their hosts, and at the same time constantly monitor changes in the virtual infrastructure. In this case, you can monitor network connections between processes associated with other processes and services, thus monitoring the actual use of the network, not just network devices.
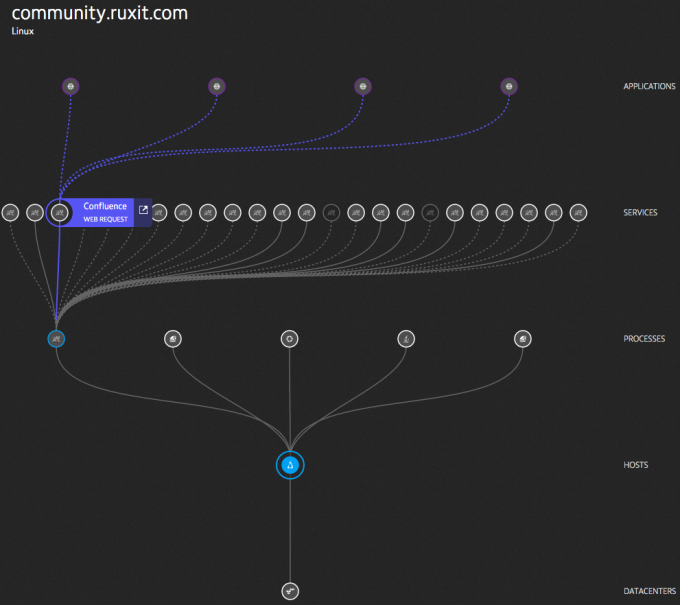
Resource monitoring is very important ... and simple!
With this approach to monitoring, your network will not be considered only as a combination of network interfaces, routing tables and security groups. Instead, your network will be considered as a limited resource used by processes and applications. From the point of view of processes, this resource is amenable to monitoring along with the central processor, operational and external memory, and can even be quantified. In addition, the performance of the full-packet application is monitored and it becomes possible to detect network problems down to the application level.
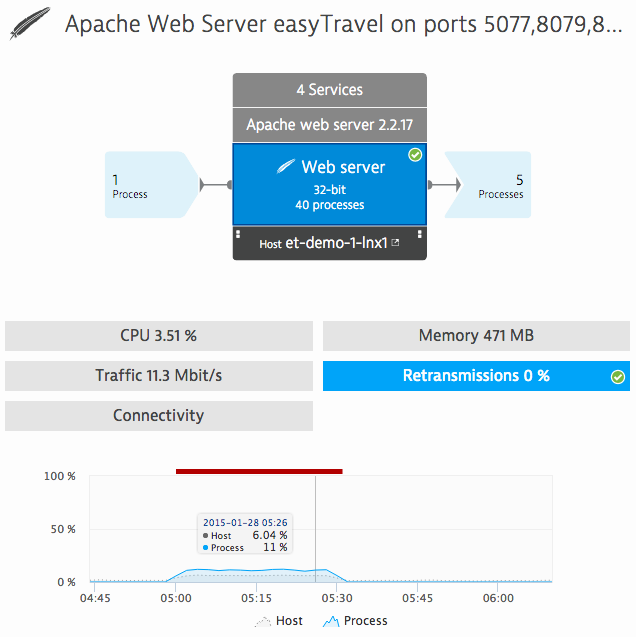
Below are a few basic network performance indicators that should be considered:
- The main indicator of network performance is network data traffic (bandwidth).
- The network interaction indicator determines the proportion of successfully completed TCP connections and indicates the availability of services. A TCP connection can be interrupted or terminated with timeouts, so the lack of connection is a clear sign of problems between the sender and receiver on the network.
- When determining the quality of established connections via TCP, one should also pay attention to the frequency of data retransmission. The purpose of the TCP protocol is to provide a reliable connection and error detection during data transfer. This means that the recipient must agree to receive data packets sent over a network link; otherwise, they are considered lost and then re-sent by the sender. Thus, the frequency of data retransmission indicates the presence of weak links in the network and congestion of its infrastructure.
Virtualized networks do not lend themselves to more or less traditional management methods. They need to be monitored, at least in terms of your hosts and processes, so that you have effective network performance indicators.
Source: https://habr.com/ru/post/252049/
All Articles