Entity Framework: improve performance when saving data in the database
When adding / changing a large number of records (10³ and higher), the performance of the Entity Framework leaves much to be desired. The reason for this is both the architectural features of the framework itself and the non-optimal generated SQL. Looking ahead - saving data to bypass the context reduces execution time by orders of magnitude.
The content of the article:
1. Insert / Update using standard Entity Framework
2. Finding a solution to the problem
3. Entity Framework Integration and SqlBulkCopy
4. Advanced insert using MERGE
5. Performance Comparison
6. Conclusions
Let's start with Insert. The standard way to add new records to the database is to add it to the context and then save it:
Each call to the Add method results in an expensive, in terms of execution, call to the internal algorithm DetectChanges . This algorithm scans all entities in the context and compares the current value of each property with the original value stored in the context, updates the connections between the entities, etc. A known way to improve performance, which is relevant until the release of EF 6, is disabling DetectChanges at the time of adding entities to the context:
It is also recommended not to keep tens of thousands of objects in context and to save data in blocks, keeping the context and creating a new every N objects, for example, like this . Finally, an optimized AddRange method appeared in EF 6, raising performance to the level of the Add + AutoDetectChangesEnabled bundle :
Unfortunately, the listed approaches do not solve the main problem, namely: when saving data in the database, a separate INSERT request is generated for each new record!
With Update, the situation is similar. The following code:
will lead to the execution of a separate SQL query for each modified object:
In the simplest cases, EntityFramework.Extended can help:
This code will bypass the context and generate 1 SQL query. For more information about EF speed and how to work with this library , see tp7 . Obviously, the solution is not universal and is suitable only for writing to all target lines of the same value.
')
Strongly disgusted with writing “bikes”, I first of all looked for best-practices for multiple insertion using EF. It would seem that a typical task - but a suitable solution “out of the box” could not be found. At the same time, SQL Server offers a number of quick data insertion techniques, such as the bcp utility and the SqlBulkCopy class. The latter will be discussed below.
System.Data.SqlClient.SqlBulkCopy is an ADO.NET class for writing large amounts of data to SQL Server tables. DataRow [] , DataTable , or IDataReader implementation can be used as a data source.
What can:
Minuses:
More information about the class can be found in the article JeanLouis , and here we look at our immediate problem - namely the lack of integration of SqlBulkCopy and EF. There is no established approach to solving this problem, but there are several projects of varying degrees of suitability, such as:
EntityFramework.BulkInsert
It turned out to be inoperative. While studying the Issues, I came across a discussion with the participation of ... the notorious Julie Lerman, describing a problem similar to mine and unanswered by the authors of the project.
EntityFramework.Utilities
Live project, active community. No support for Database First, but promise to add.
Entity Framework Extensions
$ 300
Let's try to do everything yourself. In the simplest case, inserting data from a collection of objects using SqlBulkCopy looks like this:
The task itself is to implement an IDataReader based on a collection of objects that is trivial, so I will limit myself to the link and go on to describing how to handle errors when pasting using SqlBulkCopy . By default, data is inserted in its own transaction. When an exception occurs, a SqlException is thrown and a rollback occurs, i.e. data in the database will not be recorded at all. And the “native” error messages of this class can only be called uninformative. For example, what might contain SqlException.AdditionalInformation :
or:
Unfortunately, SqlBulkCopy often does not provide information that uniquely identifies the string / entity that caused the error. Another unpleasant feature is that when you try to insert a duplicate record on the primary key, SqlBulkCopy will throw an exception and complete the work without providing an opportunity to handle the situation and continue execution.
Mapping
In the case of correctly generated entities and databases, the checks for the type conformity, or the length of the field in the table, are irrelevant. It is more useful to deal with column mapping performed through the SqlBulkCopy.ColumnMappings property:
For EF In 99% of cases, you will need to set the ColumnMappings explicitly (due to navigation properties and any additional properties). Navigation properties can be eliminated with the help of Reflection:
Such code will fit for the POCO class without additional properties, otherwise you will have to switch to “manual control”. Getting the table schema is also quite simple:
This makes it possible to manually perform mapping between the source class and the target table.
Using the SqlBulkCopy.BatchSize property and the SqlBulkCopyOptions class
SqlBulkCopy.BatchSize :
SqlBulkCopyOptions - enumeration:
We can optionally enable the check of triggers and constraints on the database side (disabled by default). When specifying BatchSize and UseInternalTransaction , the data will be sent to the server in blocks in separate transactions. Thus, all successful blocks until the first erroneous one will be stored in the database.
SqlBulkCopy can only add records to the table, and does not provide any functionality for modifying existing records. Nevertheless, we can speed up the execution of Update operations! How? Insert the data into a temporary empty table, and then synchronize the tables using the MERGE statement , which debuted in SQL Server 2008:
Using MERGE, it is easy and simple to implement various duplication processing logic: update data in the target table, or ignore or even delete matching records. Thus, we can save data from the collection of EF objects to the database using the following algorithm:
Steps 1 and 3 will be discussed in more detail.
Temporary table
It is necessary to create a table in the database, completely repeating the table schema for inserting data. Making manual copies is the worst possible option, since all further work on comparison and synchronization of table diagrams will also fall on your shoulders. It is safer to copy the scheme programmatically and immediately before pasting. For example, using SQL Server Management Objects (SMO) :
It is worth paying attention to the ScriptingOptions class, which contains several dozens of parameters for fine-tuning the generated SQL. The resulting StringCollection will be expanded into a String . Unfortunately, I did not find a better solution than to replace the source table name in the script with the name of a temporary a la String.Replace (“Order”, “Order_TEMP”) . I would be grateful for the hint of a beautiful solution to create a copy of the table within the same database. Run the finished script in any convenient way. A copy of the table is created!
Copying data from a temporary table to a target
It remains to execute the MERGE statement on the SQL Server side, comparing the contents of the temporary and target tables and performing an update or insertion (if necessary). For example, for the [Order] table, the code might look like this:
This SQL query compares records from the [Order_TEMP] temporary table with records from the [Order] target table, and performs Update if a record is found with a similar value in the Id field, or Insert if no such record is found. Run the code in any convenient way, and you're done! Do not forget to clean / delete the temporary table to taste.
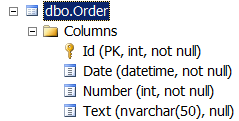
Runtime: Visual Studio 2013, Entity Framework 6.1.1 (Database First), SQL Server 2012. For testing, the [Order] table was used (the table schema is shown above). Measurements of the time of execution were carried out for the approaches to storing data in the database considered in the article, the results are presented below (the time is given in seconds):
Wow! If you use the Add method to add to the context and SaveChanges to save, saving 100,000 records to the database will take almost 2 hours! While SqlBulkCopy spends less than a second on the same task!
Again SqlBulkCopy out of competition. The source code of the test application is available on GitHub .
In the case of working with a context containing a large number of objects (10³ and above), abandoning the Entity Framework infrastructure (adding to context + saving context) and switching to SqlBulkCopy for writing to the database can provide a performance increase tens or even hundreds of times. However, in my opinion, using a bunch of EF + SqlBulkCopy everywhere is a clear sign that something is wrong with the architecture of your application. The approach considered in the article should be considered as a simple means to accelerate the performance in narrow places of an already written system, if changing the architecture / technology is difficult for some reason. Any developer using the Entity Framework should know the strengths and weaknesses of this tool. Successes!
The content of the article:
1. Insert / Update using standard Entity Framework
2. Finding a solution to the problem
3. Entity Framework Integration and SqlBulkCopy
4. Advanced insert using MERGE
5. Performance Comparison
6. Conclusions
1. Insert / Update using standard Entity Framework
Let's start with Insert. The standard way to add new records to the database is to add it to the context and then save it:
context.Orders.Add(order); context.SaveChanges(); Each call to the Add method results in an expensive, in terms of execution, call to the internal algorithm DetectChanges . This algorithm scans all entities in the context and compares the current value of each property with the original value stored in the context, updates the connections between the entities, etc. A known way to improve performance, which is relevant until the release of EF 6, is disabling DetectChanges at the time of adding entities to the context:
context.Configuration.AutoDetectChangesEnabled = false; orders.ForEach(order => context.Orders.Add(order)); context.Configuration.AutoDetectChangesEnabled = true; context.SaveChanges(); It is also recommended not to keep tens of thousands of objects in context and to save data in blocks, keeping the context and creating a new every N objects, for example, like this . Finally, an optimized AddRange method appeared in EF 6, raising performance to the level of the Add + AutoDetectChangesEnabled bundle :
context.Orders.AddRange(orders); context.SaveChanges(); Unfortunately, the listed approaches do not solve the main problem, namely: when saving data in the database, a separate INSERT request is generated for each new record!
SQL
INSERT [dbo].[Order]([Date], [Number], [Text]) VALUES (@0, @1, NULL) With Update, the situation is similar. The following code:
var orders = context.Orders.ToList(); //.. context.SaveChanges(); will lead to the execution of a separate SQL query for each modified object:
SQL
UPDATE [dbo].[Order] SET [Text] = @0 WHERE ([Id] = @1) In the simplest cases, EntityFramework.Extended can help:
//update all tasks with status of 1 to status of 2 context.Tasks.Update( t => t.StatusId == 1, t2 => new Task { StatusId = 2 }); This code will bypass the context and generate 1 SQL query. For more information about EF speed and how to work with this library , see tp7 . Obviously, the solution is not universal and is suitable only for writing to all target lines of the same value.
')
2. Finding a solution to the problem
Strongly disgusted with writing “bikes”, I first of all looked for best-practices for multiple insertion using EF. It would seem that a typical task - but a suitable solution “out of the box” could not be found. At the same time, SQL Server offers a number of quick data insertion techniques, such as the bcp utility and the SqlBulkCopy class. The latter will be discussed below.
System.Data.SqlClient.SqlBulkCopy is an ADO.NET class for writing large amounts of data to SQL Server tables. DataRow [] , DataTable , or IDataReader implementation can be used as a data source.
What can:
- Send data to the server block by block with transaction support;
- Perform mapping of columns from DataTable to database table;
- Ignore constraints, foreign keys when inserting (optional).
Minuses:
- Atomicity of the insert (optional);
- The impossibility of continuing work after the exception;
- Weak error handling capabilities.
More information about the class can be found in the article JeanLouis , and here we look at our immediate problem - namely the lack of integration of SqlBulkCopy and EF. There is no established approach to solving this problem, but there are several projects of varying degrees of suitability, such as:
EntityFramework.BulkInsert
It turned out to be inoperative. While studying the Issues, I came across a discussion with the participation of ... the notorious Julie Lerman, describing a problem similar to mine and unanswered by the authors of the project.
EntityFramework.Utilities
Live project, active community. No support for Database First, but promise to add.
Entity Framework Extensions
$ 300
3. Entity Framework Integration and SqlBulkCopy
Let's try to do everything yourself. In the simplest case, inserting data from a collection of objects using SqlBulkCopy looks like this:
//entities - EntityFramework using (IDataReader reader = entities.GetDataReader()) using (SqlConnection connection = new SqlConnection(connectionString)) using (SqlBulkCopy bcp = new SqlBulkCopy(connection)) { connection.Open(); bcp.DestinationTableName = "[Order]"; bcp.ColumnMappings.Add("Date", "Date"); bcp.ColumnMappings.Add("Number", "Number"); bcp.ColumnMappings.Add("Text", "Text"); bcp.WriteToServer(reader); } The task itself is to implement an IDataReader based on a collection of objects that is trivial, so I will limit myself to the link and go on to describing how to handle errors when pasting using SqlBulkCopy . By default, data is inserted in its own transaction. When an exception occurs, a SqlException is thrown and a rollback occurs, i.e. data in the database will not be recorded at all. And the “native” error messages of this class can only be called uninformative. For example, what might contain SqlException.AdditionalInformation :
The given value of the type String from the data source cannot be converted.
or:
SqlDateTime overflow. Must be between 1/1/1753 12:00:00 AM and 12/31/9999 11:59:59 PM.
Unfortunately, SqlBulkCopy often does not provide information that uniquely identifies the string / entity that caused the error. Another unpleasant feature is that when you try to insert a duplicate record on the primary key, SqlBulkCopy will throw an exception and complete the work without providing an opportunity to handle the situation and continue execution.
Mapping
In the case of correctly generated entities and databases, the checks for the type conformity, or the length of the field in the table, are irrelevant. It is more useful to deal with column mapping performed through the SqlBulkCopy.ColumnMappings property:
If the data source and the target table have the same number of columns and the source position of each source column in the data source corresponds to the source position of the corresponding target column, the ColumnMappings collection is not required. However, if the number of columns or their order is different, it is necessary to use ColumnMappings to ensure the correct copying of data between columns.
For EF In 99% of cases, you will need to set the ColumnMappings explicitly (due to navigation properties and any additional properties). Navigation properties can be eliminated with the help of Reflection:
Get property names for mapping
var columns = typeof(Order).GetProperties() .Where(property => property.PropertyType.IsValueType || property.PropertyType.Name.ToLower() == "string") .Select(property => property.Name) .ToList(); Such code will fit for the POCO class without additional properties, otherwise you will have to switch to “manual control”. Getting the table schema is also quite simple:
We read the table schema
private static List<string> GetColumns(SqlConnection connection) { string[] restrictions = { null, null, "<TableName>", null }; var columns = connection.GetSchema("Columns", restrictions) .AsEnumerable() .Select(s => s.Field<String>("Column_Name")) .ToList(); return columns; } This makes it possible to manually perform mapping between the source class and the target table.
Using the SqlBulkCopy.BatchSize property and the SqlBulkCopyOptions class
SqlBulkCopy.BatchSize :
| Batchsize | The number of lines in each batch. At the end of each packet, the number of lines contained in it is sent to the server. |
SqlBulkCopyOptions - enumeration:
| Member name | Description |
|---|---|
| CheckConstraints | Check constraints when inserting data. By default, restrictions are not checked. |
| Default | Use default values for all parameters. |
| Firetriggers | When this setting is specified, the server triggers insert triggers for rows inserted into the database. |
| KeepIdentity | Save source identification values. When this setting is not specified, identification values are assigned by the target table. |
| Keepnulls | Store NULL values in the target table regardless of the default settings. When this setting is not specified, null values, where possible, are replaced with default values. |
| Table lock | Get a bulk update lock for the entire duration of a bulk copy operation. When this setting is not specified, row lock is used. |
| UseInternalTransaction | When this setting is specified, each bulk copy operation is performed in a transaction. If you specify this setting and provide the constructor with a SqlTransaction object, an ArgumentException will be thrown. |
We can optionally enable the check of triggers and constraints on the database side (disabled by default). When specifying BatchSize and UseInternalTransaction , the data will be sent to the server in blocks in separate transactions. Thus, all successful blocks until the first erroneous one will be stored in the database.
4. Advanced insert using MERGE
SqlBulkCopy can only add records to the table, and does not provide any functionality for modifying existing records. Nevertheless, we can speed up the execution of Update operations! How? Insert the data into a temporary empty table, and then synchronize the tables using the MERGE statement , which debuted in SQL Server 2008:
MERGE (Transact-SQL)
Performs insert, update, or delete operations on the target table based on the results of the connection to the source table. For example, you can synchronize two tables by inserting, updating, or deleting rows in one table based on differences found in another table.
Using MERGE, it is easy and simple to implement various duplication processing logic: update data in the target table, or ignore or even delete matching records. Thus, we can save data from the collection of EF objects to the database using the following algorithm:
- create / clear a temporary table that is completely identical to the target table;
- insert data using SqlBulkCopy into a temporary table;
- using MERGE, add records from the temporary table to the target.
Steps 1 and 3 will be discussed in more detail.
Temporary table
It is necessary to create a table in the database, completely repeating the table schema for inserting data. Making manual copies is the worst possible option, since all further work on comparison and synchronization of table diagrams will also fall on your shoulders. It is safer to copy the scheme programmatically and immediately before pasting. For example, using SQL Server Management Objects (SMO) :
Server server = new Server(); //SQL auth server.ConnectionContext.LoginSecure = false; server.ConnectionContext.Login = "login"; server.ConnectionContext.Password = "password"; server.ConnectionContext.ServerInstance = "server"; Database database = server.Databases["database name"]; Table table = database.Tables["Order"]; ScriptingOptions options = new ScriptingOptions(); options.Default = true; options.DriAll = true; StringCollection script = table.Script(options); It is worth paying attention to the ScriptingOptions class, which contains several dozens of parameters for fine-tuning the generated SQL. The resulting StringCollection will be expanded into a String . Unfortunately, I did not find a better solution than to replace the source table name in the script with the name of a temporary a la String.Replace (“Order”, “Order_TEMP”) . I would be grateful for the hint of a beautiful solution to create a copy of the table within the same database. Run the finished script in any convenient way. A copy of the table is created!
The nuances of using SMO in .NET 4+
It should be noted that the call to Database.ExecuteNonQuery in .NET 4+ throws an exception of the form:
Associated with the fact that the wonderful SMO library is only available under .NET 2 Runtime. Fortunately, there is a workaround :
Another option is to use Database.ExecuteWithResults .
Mixed mode assembly version v2.0.50727 of this version has been built up for the version.
Associated with the fact that the wonderful SMO library is only available under .NET 2 Runtime. Fortunately, there is a workaround :
<startup useLegacyV2RuntimeActivationPolicy="true"> ... </startup> Another option is to use Database.ExecuteWithResults .
Copying data from a temporary table to a target
It remains to execute the MERGE statement on the SQL Server side, comparing the contents of the temporary and target tables and performing an update or insertion (if necessary). For example, for the [Order] table, the code might look like this:
MERGE INTO [Order] AS [Target] USING [Order_TEMP] AS [Source] ON Target.Id = Source.Id WHEN MATCHED THEN UPDATE SET Target.Date = Source.Date, Target.Number = Source.Number, Target.Text = Source.Text WHEN NOT MATCHED THEN INSERT (Date, Number, Text) VALUES (Source.Date, Source.Number, Source.Text); This SQL query compares records from the [Order_TEMP] temporary table with records from the [Order] target table, and performs Update if a record is found with a similar value in the Id field, or Insert if no such record is found. Run the code in any convenient way, and you're done! Do not forget to clean / delete the temporary table to taste.
5. Performance Comparison
Runtime: Visual Studio 2013, Entity Framework 6.1.1 (Database First), SQL Server 2012. For testing, the [Order] table was used (the table schema is shown above). Measurements of the time of execution were carried out for the approaches to storing data in the database considered in the article, the results are presented below (the time is given in seconds):
Insert
| The way to commit changes in the database | Number of records | ||
|---|---|---|---|
| 1000 | 10,000 | 100,000 | |
| Add + SaveChanges | 7.3 | 101 | 6344 |
| Add + (AutoDetectChangesEnabled = false) + SaveChanges | 6.5 | 64 | 801 |
| Add + separate context + SaveChanges | 8.4 | 77 | 953 |
| AddRange + SaveChanges | 7.2 | 64 | 711 |
| SqlBulkCopy | 0.01 | 0.07 | 0.42 |
Wow! If you use the Add method to add to the context and SaveChanges to save, saving 100,000 records to the database will take almost 2 hours! While SqlBulkCopy spends less than a second on the same task!
Update
| The way to commit changes in the database | Number of records | ||
|---|---|---|---|
| 1000 | 10,000 | 100,000 | |
| SaveChanges | 6.2 | 60 | 590 |
| SqlBulkCopy + MERGE | 0.04 | 0.2 | 1.5 |
Again SqlBulkCopy out of competition. The source code of the test application is available on GitHub .
findings
In the case of working with a context containing a large number of objects (10³ and above), abandoning the Entity Framework infrastructure (adding to context + saving context) and switching to SqlBulkCopy for writing to the database can provide a performance increase tens or even hundreds of times. However, in my opinion, using a bunch of EF + SqlBulkCopy everywhere is a clear sign that something is wrong with the architecture of your application. The approach considered in the article should be considered as a simple means to accelerate the performance in narrow places of an already written system, if changing the architecture / technology is difficult for some reason. Any developer using the Entity Framework should know the strengths and weaknesses of this tool. Successes!
Additional links
EntityFramework: Add, AddRange
Secrets of DetectChanges
Performance Considerations for Entity Framework 4, 5, and 6
Entity Framework Performance
Entity Framework and slow bulk INSERTs
Another look at the Entity Framework: performance and pitfalls
SqlBulkCopy
SqlBulkCopy - reloading big data without a crash or how to ride a wild horse
Using SqlBulkCopy To Perform Efficient Bulk SQL Operations
SqlBulkCopy + data reader
Creating a Generic List DataReader for SqlBulkCopy
SqlBulkCopy for Generic List <T>
SqlBulkCopy + MERGE
C # Bulk Upsert to SQL Server Tutorial
Secrets of DetectChanges
Performance Considerations for Entity Framework 4, 5, and 6
Entity Framework Performance
Entity Framework and slow bulk INSERTs
Another look at the Entity Framework: performance and pitfalls
SqlBulkCopy
SqlBulkCopy - reloading big data without a crash or how to ride a wild horse
Using SqlBulkCopy To Perform Efficient Bulk SQL Operations
SqlBulkCopy + data reader
Creating a Generic List DataReader for SqlBulkCopy
SqlBulkCopy for Generic List <T>
SqlBulkCopy + MERGE
C # Bulk Upsert to SQL Server Tutorial
Source: https://habr.com/ru/post/251397/
All Articles