The quality of data networks. Software and hardware measurements
 I would like to publish a series of articles on measuring the characteristics of communication systems and data networks. This article is introductory and it will only cover the very basics. In the future, I plan a deeper consideration in the style of "how it is done."
I would like to publish a series of articles on measuring the characteristics of communication systems and data networks. This article is introductory and it will only cover the very basics. In the future, I plan a deeper consideration in the style of "how it is done."When buying a product or service, we often operate on such a concept as quality. What is quality? If we turn to Ozhegov’s dictionary, we will see the following: “a set of essential features, properties, features that distinguish an object or phenomenon from others and give it certainty”. Transferring the definition to the field of communication networks, we conclude that we need to identify “essential features, properties and features”, which allow us to unambiguously determine the difference between one line or a communication network and another. The enumeration of all features and properties are summarized by the concept of "metric". When someone speaks about the metrics of communication networks, he means those characteristics and properties that will allow to accurately judge the communication system as a whole. The need for quality assessment lies mostly in the economic field, although its technical part is no less interesting. I will try to balance between them in order to reveal all the most interesting aspects of this area of knowledge.
All interested in asking under the cat.
')
Monitoring and diagnostics of communication systems
As I wrote above, quality metrics determine the economic component of owning a network or communication system. Those. the cost of renting or leasing a communication line directly depends on the quality of the communication line itself. Cost, in turn, is determined by supply and demand in the market. Further patterns are described by Adam Smith and developed by Milton Friedman. Even in Soviet times, when there was a planned economy, and the “market” was thought of as a crime against the authorities and the people, there was an institution of state acceptance, for both military and civilian purposes, designed to ensure proper quality. But back in our time and try to define these metrics.
Consider an Ethernet-based network as the most popular technology at the moment. We will not consider the quality metrics of the data transmission medium, since they are of little interest to the end user (unless the material of the medium itself is sometimes interesting: radio, copper or optics). The very first metric that comes to mind is bandwidth, i.e. how much data we can transfer per unit of time. The second , related to the first one, is packet capacity (PPS, Packets Per Second), which reflects how many frames can be transmitted per unit of time. Since the network equipment operates with frames, the metric allows you to assess whether the equipment is coping with the load and whether its performance is as stated.
The third metric is a measure of frame loss. If it is impossible to restore the frame, or the restored frame does not correspond to the checksum, then the receiving one or the intermediate system will reject it. This refers to the second level of the OSI system. If we take a closer look, most of the protocols do not guarantee delivery of the packet to the recipient, their task is only to send data in the right direction, and those who guarantee (for example, TCP) can lose a lot in bandwidth just because of frame retransmit, but all they rely on L2 frames, the loss of which is taken into account by this metric.
The fourth is delay (latency), i.e. after how many packets sent from point A to be at point B. From this characteristic, two more can be distinguished: one-trip delay (one-trip) and round trip (round-trip). The point is that the path from A to B can be one, and from B to A is already completely different. Just sharing time does not work. And the delay can change from time to time, or “tremble” - this metric is called jitter. Jitter shows the variation of delay relative to neighboring frames, i.e. the deviation of the delay of the first packet relative to the second, or fifth relative to the fourth, followed by averaging over a specified period. However, if an analysis of the overall picture is required or a change in the delay during the entire test time is of interest, and the jitter no longer reflects the exact picture, then the delay variation index is used. The fifth metric is the minimum MTU of the channel. Many do not attach importance to this parameter, which may be critical in the operation of “heavy” applications, where it is advisable to use jumbo frames. The sixth , and obscure for many parameter - berstnost - normalized maximum bit rate. By this metric, you can judge the quality of the equipment that makes up the network or data transmission system, allows you to judge the size of the equipment buffer and calculate the reliability conditions.
About measurements
Since the metrics have been determined, it is worth choosing a measurement method and tool.
Delay
A well-known tool that comes with most operating systems is the ping utility (ICMP Echo-Request). Many use it several times a day to check the availability of nodes, addresses, etc. Designed just to measure RTT (Round Trip Time). The sender makes a request and sends to the recipient, the recipient generates a response and sends it to the sender, the sender measuring the time between the request and the response calculates the delay time. Everything is clear and simple, nothing needs to be invented. There are some questions of accuracy and they are discussed in the next section.
But what if we only need to measure the delay in one direction? Here everything is more complicated. The fact is that, in addition to simply estimating the delay, it is useful to synchronize the time on the sender and recipient nodes. For this, PTP (Precision Time Protocol, IEEE 1588) was invented. What is better than NTP I will not describe, because everything is already painted here, I will say only that it allows you to synchronize time to within nanoseconds. In the end, it all comes down to ping-like testing: the sender creates a packet with a timestamp, the packet goes through the network, reaches the recipient, the recipient calculates the difference between the time in the packet and its own, if the time is synchronized, the correct delay is calculated, if not, This measurement is wrong.
If you accumulate measurement information, then, based on historical delay data, you can easily plot and calculate jitter and delay variation — an indicator that is important in VoIP and IPTV networks. Its importance is associated primarily with the work of the encoder and decoder. With a “floating” delay and adaptive buffer codec increases the likelihood of not having time to recover information, there is a “ringing” in the voice (VoIP) or “mixing” of the frame (IPTV).
Frame loss
By measuring the delay, if the response packet was not received, it is assumed that the packet was lost. So does ping. It seems too simple, but it is only at first glance. As described above, in the case of ping, the sender generates one packet and sends it, and the recipient forms its own about sends it back. Those. we have two packages. In case of loss, which one is lost? This may not be important (although it is also doubtful), if we have a direct route for packets that corresponds to the opposite, and if this is not the case? If this is not the case, then it is very important to understand in which leverage the problem is. For example, if the package reached the receiver, then the direct path functions normally, but if not, then you should start with diagnosing this section, but if the package reached, but did not return, then you definitely shouldn't spend time tracing a working straight segment. To help in identification could ordinal label embedded in the test packet. If there are gauges of the same type at both ends, then each of them knows the number of packets sent and received by them at any given time. Which of the packages did not reach the recipient can be obtained by comparing the list of sent and received packages.
Min MTU
Measuring this characteristic is not so difficult, rather, it is boring and routine. To determine the minimum MTU (Maximum transmission unit) size, you only need to run a test (the same ping) with different frame sizes and the DF bit set (Don't Fragmentate), which will result in non-passing packets with a frame size larger than acceptable, due to the prohibition of fragmentation.
For example, this does not work:
$ ping -s 1500 -Mdo 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 1500(1528) bytes of data. ping: local error: Message too long, mtu=1500 ping: local error: Message too long, mtu=1500 ^C --- 8.8.8.8 ping statistics --- 2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1006ms And so already passes:
$ ping -s 1400 -Mdo 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 1400(1428) bytes of data. 1408 bytes from 8.8.8.8: icmp_seq=1 ttl=48 time=77.3 ms 1408 bytes from 8.8.8.8: icmp_seq=2 ttl=48 time=76.8 ms 1408 bytes from 8.8.8.8: icmp_seq=3 ttl=48 time=77.1 ms ^C --- 8.8.8.8 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 76.839/77.133/77.396/0.393 ms Not often used metric from a commercial point of view, but relevant in some cases. Again, it is worth noting that with an asymmetrical packet path, different MTUs are possible in different directions.
Bandwidth
Surely many people know the fact that the amount of useful information transferred per unit of time depends on the frame size. This is due to the fact that the frame contains quite a lot of service information - headers, the size of which does not change when the frame is resized, but the field of the “useful” part (payload) changes. This means that despite the fact that even if we transmit data at link speeds, the amount of useful information transmitted over the same period of time can vary greatly. Therefore, despite the fact that there are utilities for measuring bandwidth (for example, iperf), it is often impossible to obtain reliable data on network bandwidth. The fact is that iperf analyzes traffic data based on the calculation of the very “useful” part surrounded by protocol headers (usually UDP, but TCP is also possible), therefore the network load (L1, L2) does not match the calculated (L4) . When using hardware meters, the traffic generation rate is set to L1 values, since otherwise it would not be obvious to the user why the load changes when measuring the frame size, it is not so noticeable when setting it in %% of the bandwidth, but is very noticeable when indicated in units of speed (Mbps, Gbps). In the test results, as a rule, the speed for each level is indicated (L1, L2, L3, L4). For example, so (you can switch L2, L3 in the output):
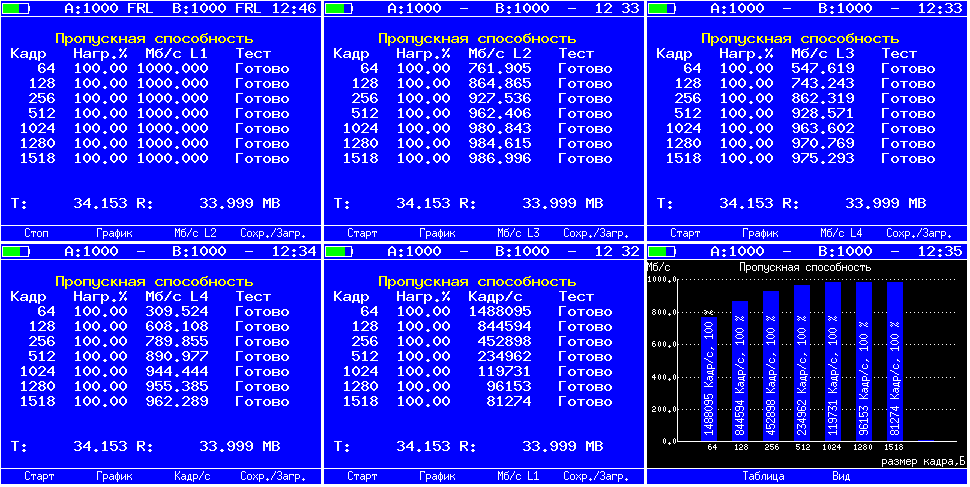
Frame Frames Per Second
If we talk about a network or communication system as a complex of communication lines and active equipment that ensures normal operation, then the efficiency of such a system depends on each component of it. Communication lines must provide work at the stated speeds (linear speed), and active equipment must have time to process all incoming information.
All equipment manufacturers claim the PPS parameter (packets per second), which directly indicates how many packets the equipment is able to “digest”. Previously, this parameter was very important, since the overwhelming number of equipment simply could not process a huge number of “small” packages, but now more and more manufacturers are claiming wirespeed. For example, if small packets are transmitted, then processing time is spent, as a rule, as much as on large ones. Since the contents of the package are not interesting to the equipment, but the information from the headers is important - from whom it came and to whom.
Nowadays, ASIC (application-specific integrated circuit) - specially designed for specific purposes microcircuits with very high performance, is becoming more and more common in switching equipment, while the field-programmable gate array (FPGA) was used quite often before. You can read my colleagues here and listen here .
Dragging
It is worth noting that a number of manufacturers save on components and use small buffers for packages. For example, work at link speed (wirespeed) is claimed, and in fact there are packet losses due to the fact that the port buffer cannot accommodate more data. Those. the processor has not yet processed the accumulated queue of packets, and the new ones continue to go. Often this behavior can be observed on various filters or interface converters. For example, it is assumed that the filter accepts a 1Gbps stream and sends the processing results to the 100Mbps interface if it is known that the filtered traffic is obviously less than 100Mbps. But in real life it happens that at some point in time there may be a surge in traffic of more than 100Mbps and in this situation the packets are lined up in a queue. If the buffer size is sufficient, then all of them will go to the network without losses, if not, then they will simply be lost. The larger the buffer, the longer the overload can be sustained.
Measurement errors
But the science of metrology would not be a science if it described just what and how to measure at its discretion. A field of knowledge becomes a science when the characteristics of research methods are determined based on proven knowledge. One of such metrological characteristics is that the measuring instrument itself must not introduce its own error into the measurement process, or this error must be reliably known and defined. In cases when we are dealing with software-based tools and general-purpose operating systems, the measurement error, unfortunately, cannot be accurately determined, and, accordingly, the measuring instrument cannot be calibrated accordingly. The fact is that the processes occurring during data processing, receiving packets from the network, forming responses are of a probabilistic nature associated with the architecture of the operating system. I will try to explain with the example of ping:
- the program measures time, forms a packet with data, and gives it to the OS for “descent” on OSI;
- OC queues the packet, then processes, if necessary, putting on the missing encapsulations, jerks the context, puts the packet into the network card's buffer through the driver, which also usually has a ring buffer;
- the package travels the network until it reaches the recipient;
- the recipient's network card, accepting a packet and putting it in a buffer, causes an interrupt;
- The recipient's OS, stopping other processing, reads the packet and enqueues for processing, processes, sends back (if we are talking about ping), or jerks the context and gives it to the program for processing (if the processing is not “nuclear”), i.e. points 1-2 are repeated only on the recipient's side;
- the package travels over the network again, only in the opposite direction (and not the fact that it is exactly the corresponding direct);
- items 4-5 for the sender are repeated;
- The sender program calculates the time between the beginning of 1 and the end of 7.
Thus, we obtained the time from the formation of a package by the program to the time it received the response package, instead of receiving the sum in points 3 and 6, i.e. “delayed” plots were taken into account in the delay. The solution to a problem of this kind will be to insert a timestamp into the packet as close as possible to the network output, i.e. at least the network card buffer. This will allow cutting off the “parasitic” influence of points 1-2, but 4-5 still remains. At the recipient, the packet should be returned without processing in the operating system, for example, simply by swapping the recipient's and sender's MACs. A recipient who received such a packet can compare the initial label set at the network output with the current label at the network input and make a much more accurate calculation of the delay. A good example can be seen by measuring the delay in the ping mode and in the certified test mode on our Bercut-ET or Bercut-ETX . In some systems, due to the peculiarities of the architecture, the ping can show values in the region of 30-60 ms in a direct connect (cross-connect), while a certified test will show 8-16 ns, i.e. the difference is in order. Two computers, most likely, will show the best result, but the error introduced by them in the measurement of the delay cannot be taken into account. And the ping in our device is not present to measure the delay per se, but as a standard tool for checking the availability of a node in the network.
Conclusion
The following metrics are basic and supporting for assessing the quality of networks and communication systems:
- bandwidth
- packet bandwidth
- frame loss
- delay
- one-trip
- round-trip
- jitter
- delay variation
- minimum MTU
- dragging
The general principle of measurement is the generation (or evaluation) of test packets as close as possible to the output (or to the input) of the area being measured, otherwise it is impossible to ensure accuracy due to an increase in the number of factors affecting the measurements. Currently testing methods such as RFC2544 and Y.1564 are common and used. A lot can be written about the principles of our instruments and the specifics of the tests. Just in the following publications I plan to reveal some secrets.
Thank you all for your attention.
Source: https://habr.com/ru/post/250821/
All Articles