Lock-free data structures. Concurrent maps: skip list

In previous articles ( one , two ), we considered the classic hash map with a hash table and a list of collisions. A lock-free ordered list was built, which served as the basis for the lock-free hash map.
Unfortunately, the lists are characterized by the linear complexity of the search for
O(N) , where N is the number of elements in the list, so our lock-free ordered list algorithm itself is of little interest for large NOr does it represent? ..
There is a rather curious data structure - skip-list , based on a simple, simply-connected list. It was first described in 1990 by W.Pugh, the translation of his original article is in Habré. This structure is of interest to us, since, having the lock-free ordered list algorithm, it is quite easy to implement a lock-free skip-list.
To begin with - a little about the principles of building a skip-list. A skip-list is a multi-level list: each element (sometimes called a tower) has a certain height
h .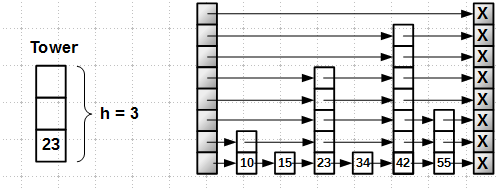
Height
h is chosen randomly from the range [1, Hmax] , where Hmax is the maximum possible height, usually 16 or 32. The probability that the height of the tower is one is P[h == 1] = 1/2 . The probability of height k is: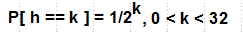
Despite the seeming difficulty of calculating the height, it can be calculated quite simply, for example, like this:
h = lsb( rand() ) , where lsb is the number of the least significant bit of the number.Magic 1/2
In fact, the constant
1/2 is my simplification, the original article deals with 0 < p < 1 and explores the behavior of the skip-list for various values of p . But for practical implementation, p = 1/2 is the best value, I think.It turns out that the greater the level, the more the list at this level is sparse compared to the lower ones. This rarefaction, along with probabilistic nature, gives an estimate of the complexity of the search for
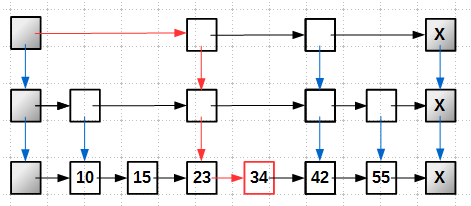
O(log N) , the same as for binary self-balancing trees.Skip-list search is quite simple: starting from the head tower, which has a maximum height, we go through the highest level until we find an element with a key larger than the desired one (or do not lean into the tail tail), go down to the level below, look for similarly in it, etc., until we get to level 0, the lowest; key search example 34:
Lock-free skip list
To build a lock-free skip-list, we already have a lock-free algorithm for each level. It remains to develop methods of working with levels. It would seem impossible to atomically insert a node-tower with a height of, say, 20, because for this you need to atomically change 20 pointers! It turns out that this is not necessary, it is enough to be able to atomically change one pointer, - what we already know how to do in the lock-free list.
Consider how the insertion in the lock-free skip-list. We will insert an element-tower with a height of 5 with a key of 23. The first stage we look for the position of the insert, moving through the levels from top to bottom. As a result, we have an array of
prev[] insertion positions at each level:
Next, insert a new element at level 0, the lowest. We can do the insert in the lock-free list:
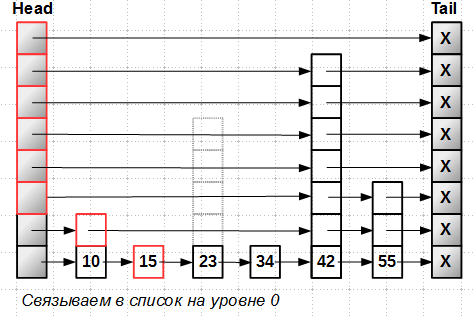
Everything - the element becomes part of the list, it can be found, it becomes attainable , despite the fact that the entire tower has not yet been completely inserted into the skip-list.
Next, we
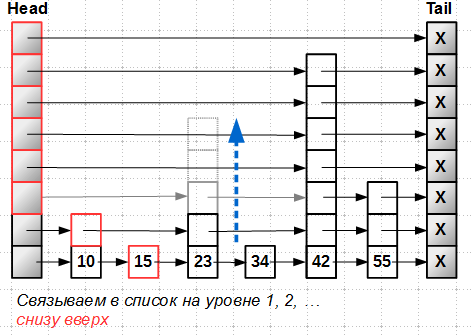
These inserts are of secondary importance, they are designed to increase the efficiency of the search, but in no way affect the attainability of the new key.
Deleting an element occurs in two phases: first, we find the element to be deleted and mark it as logically deleted using the marked pointer technique. The difficulty is that for the tower we have to mark all levels of the element, starting from the highest:
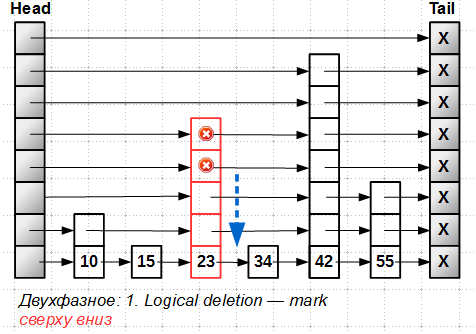
After all levels of the tower element are marked, a physical deletion is made (more precisely, the exclusion of an element from the list, since the memory is deleted under the element by Hazard Pointer or RCU), also from top to bottom:
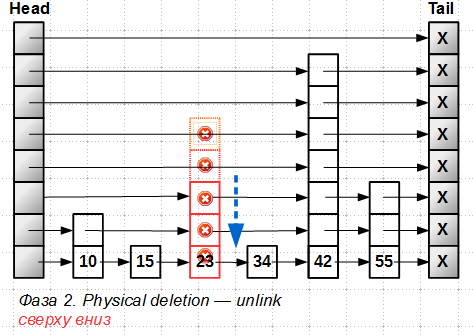
At each level, an algorithm is used to insert / remove from the usual lock-free ordered list, which we have already considered.
As you can see, the insertion / deletion procedures from the lock-free skip-list are multi-step, at each step interference with competing operations is possible, therefore, when programming the skip-list, special care is needed. For example, when inserting, we first look for positions in lists at all levels and form arrays of
prev[] . It is possible that in the process of inserting the list at some level will change and these positions will become invalid. In this case, you should update prev[] , that is, find the inserted element, and continue the insertion, starting from the level at which the bummer occurred.More interesting is the situation when the simultaneous insertion of the key
K and its removal occurs. This is quite possible: the insertion is considered successful when we have linked the item at level 0 of the list. After that, the element is already reachable and it is quite possible to remove it, despite the fact that it is not fully inserted into the upper levels. To resolve insertion and deletion collisions, the order is very important: the insertion is done from the bottom up, and the deletion (more precisely, its first phase is a logical removal, marked pointer) - counter-flow, from the top down. In this case, the insertion procedure is sure to see at any level a deletion flag and immediately stop its work.The removal procedure can also be competitive in both of its phases. In the phase of logical deletion, when tags are put on the tower from top to bottom, we are not afraid of competition. But in the phase of excluding a deleted item from the lists, any change in the skip-list, that is, breaking the
prev[] and found[] arrays, which determine the position of the deleted item, leads to the fact that we need to re-create these arrays. But the labels are already marked and the search function simply will not find the item to be deleted! To resolve this situation, we endow the search function with an unusual job: if it finds an element marked at any level, the search function eliminates (unlink) this element from the list of this level, that is, it helps to remove elements. After exclusion, the function resumes the search from the very beginning, that is, from the top level (variations are possible here, but the simplest thing is to start from the beginning). This is a typical example of mutual help, often found in lock-free programming: one thread helps another to do its work. That is why the find() function in many lock-free containers is not constant - a search can change the container.What else is characterized by skip-list? First, it is an ordered map, unlike a hash map, that is, it supports extracting the minimum
extract_min() and maximum extract_max() keys.Secondly, the skip-list is gluttonous for the Hazard Pointrer (HP) scheme: with a maximum tower height of 32 elements of the arrays of
prev[] and found[] , which determine the desired position, should be protected by hazard pointers, that is, we need at least 64 hazard pointer'a (in fact, in the implementation of libcds - 66). This is quite a lot for the HP circuit, see its device for details. For the RCU scheme, the implementation of the find() method presents some complexity, since this method can remove elements, and the RCU scheme requires that the An interesting practical task is the implementation of towers for a height of more than 1. Now in the implementation of the skip-list in the library libcds, the memory for towers with a height of more than 1 is distributed separately from the memory for the element even for the intrusive variant. Considering the probabilistic nature of the height, it turns out that for 50% of the elements memory allocation is done, this can affect performance, and also negatively affects memory fragmentation. There is an idea of a tower with a height of no more than
h_min distributed by one block and only for the high ones “to distribute” the memory under the tower: template <size_t Hmin = 4> struct tower { tower * next[Hmin]; tower * high_next; // >= Hmin }; If
Hmin = 4 , then with this construction, 93% of the elements will not require the allocation of additional memory for next - high_next to be nullptr .skip-list: bibliography
W.Pugh, a year or two after the publication of his work on the skip-list, presented another work on competitive implementation based on accurate locking (fine-grained locks).
The most cited work on the lock-free skip-list is the 2003 K.Fraser Practical lock-freedom dissertation, which presents several skip-list algorithms both on the basis of transactional memory and on the MCAS software implementation (CAS over several memory cells) . This work is now, in my opinion, purely theoretical interest, since the software emulation of transactional memory is quite difficult, as well as MCAS. Although with the release of Haswell implementation of transactional memory in the iron went to the masses ...
The implementation of the skip-list in libcds is based on the monograph The Art of Multiprocessor Programming, which I have repeatedly cited. “On motives” because the original algorithm is given for Java and has, it seems to me, several errors, which, perhaps, were corrected in the second edition. Or it is not a bug for Java at all.
There is also Fomichev’s dissertation , devoted to the question of resuming the search in the event of detected conflicts in the skip-list. As I mentioned above,
W.Pugh, a year or two after the publication of his work on the skip-list, presented another work on competitive implementation based on accurate locking (fine-grained locks).
The most cited work on the lock-free skip-list is the 2003 K.Fraser Practical lock-freedom dissertation, which presents several skip-list algorithms both on the basis of transactional memory and on the MCAS software implementation (CAS over several memory cells) . This work is now, in my opinion, purely theoretical interest, since the software emulation of transactional memory is quite difficult, as well as MCAS. Although with the release of Haswell implementation of transactional memory in the iron went to the masses ...
The implementation of the skip-list in libcds is based on the monograph The Art of Multiprocessor Programming, which I have repeatedly cited. “On motives” because the original algorithm is given for Java and has, it seems to me, several errors, which, perhaps, were corrected in the second edition. Or it is not a bug for Java at all.
There is also Fomichev’s dissertation , devoted to the question of resuming the search in the event of detected conflicts in the skip-list. As I mentioned above,
find() when it detects a marked (marked) element, tries to remove it from the list and resumes searching from the very beginning . Fomichev proposes a mechanism for arranging back-reference back links to resume work from some previous element rather than from the beginning, which, in principle, should affect the performance for the better. The back-reference support algorithm in the current state is quite complex and it is unclear whether the gain will be made or whether the code supporting the relevance will eat it.')
In the next article we will try to consider another extensive class of data structures that are the basis for associative containers — trees, or more precisely, their competitive implementation.
Source: https://habr.com/ru/post/250815/
All Articles