How Linux works with memory. Yandex Workshop
Hey. My name is Vyacheslav Biryukov. In Yandex, I manage the search operation team. Recently, for the students of the Information Technology Courses of Yandex, I gave a lecture on working with memory in Linux. Why memory? The main answer is: I like working with memory. In addition, information about it is quite small, and the one that is, as a rule, is irrelevant, because this part of the Linux kernel changes quite quickly and does not have time to get into the books. I will talk about the x86_64 architecture and about the Linux kernel version 2.6.32. Most likely the kernel version is 3.x.
This lecture will be useful not only for system administrators, but also for developers of high-load systems. It will help them understand exactly how interaction with the operating system kernel occurs.
')
Resident memory is the amount of memory that is now in the RAM of the server, computer, laptop.
Anonymous memory is a memory excluding file cache and memory that has a file backend on disk.
Page fault - memory trap. Regular mechanism when working with virtual memory.
Work with memory is organized through pages. The memory size is usually large, addressing is present, but the operating system and hardware are not very convenient to work with each of the addresses separately, therefore all memory is paginated. Page size - 4 KB. There are also pages of a different size: the so-called Huge Pages of 2 MB and pages of 1 GB in size (we will not talk about them today).
Virtual memory is the address space of the process. The process works not with physical memory directly, but with virtual memory. Such an abstraction makes it easier to write application code, not to think that you can accidentally refer to the wrong memory addresses or addresses of another process. This simplifies the development of applications, and also allows you to exceed the size of the main RAM through the mechanisms described below. Virtual memory consists of main memory and a swap device. That is, the amount of virtual memory can be in principle of unlimited size.
To manage virtual memory in the system there is an option
You can see how much memory we have committed, how much is used and how much we can still allocate, in the
In modern systems, all virtual memory is divided into NUMA nodes. Once we had computers with one processor and one memory bank (memory bank). Such architecture was called UMA (SMP). Everything was very clear: one system bus for communication of all components. Later it became inconvenient, began to limit the development of architecture, and, as a result, NUMA was invented.
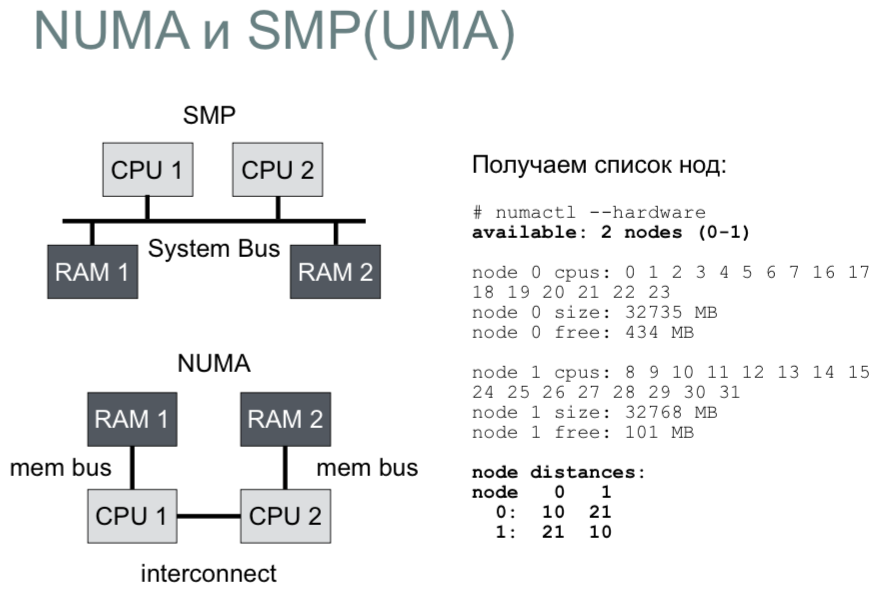
As you can see from the slide, we have two processors that communicate with each other via some channel, and each of them has its own buses, through which they communicate with their memory banks. If we look at the picture, the delay from CPU 1 to RAM 1 in the NUMA node will be two times less than from CPU 1 to RAM 2. We can get this data and other information using the
We see that the server has two nodes and information on them (how much free physical memory is in each node). Memory is allocated on each node separately. Therefore, you can consume all the free memory on one node, and the other - to underload. To prevent this from happening (this is typical of databases), you can start the process with the numactl interleave = all command. This allows you to distribute the allocation of memory between the two nodes evenly. Otherwise, the kernel selects the node on which the scheduling process was scheduled to start and always tries to allocate memory on it.
Also, the memory in the system is divided into Memory Zones. Each NUMA node is divided into a number of such zones. They serve to support a special iron that cannot communicate across the entire range of addresses. For example, ZONE_DMA is 16 MB of the first addresses, ZONE_DMA32 is 4 GB. We look at the memory zones and their status through the file
Through Page Cache in Linux, all read and write operations are by default. It is of dynamic size, that is, it is he who will eat all your memory, if it is free. As the old joke says, if you need free memory in the server, just pull it out of the server. Page Cache divides all the files that we read into pages (the page, as we said, is 4 KB). You can see if there are any pages of a particular file in Page Cache using the
How does the recording go? Any recording does not happen on the disk immediately, but in Page Cache, and this is done almost instantly. Here you can see an interesting "anomaly": writing to disk is much faster than reading. The fact is that when reading (if there is no given file page in Page Cache) we will go to the disk and wait synchronously for a response, and the record in turn will go instantly to the cache.
The downside of this behavior is that in fact the data is not recorded anywhere - they are simply in memory, and sometime they will need to be flushed to disk. At each page at record the flag is put down (it is called dirty). Such a “dirty” page appears in Page Cache. If many such pages are accumulated, the system understands that it is time to drop them onto a disk, otherwise you can lose them (if power is suddenly lost, our data will also be lost).
The process consists of the following segments. We have a stack that grows down; He has a limit on which he can not grow.
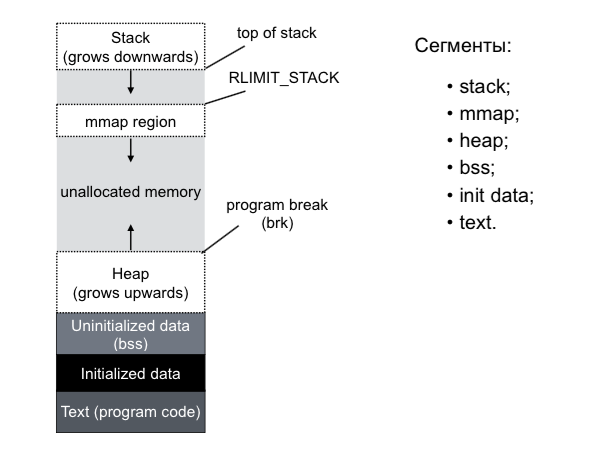
Then comes the mmap region: there are all the process-mapped process files that we opened or created using the
If we are talking about memory inside a process, then working with pages is also inconvenient: as a rule, memory allocation within a process occurs in blocks. Very rarely you need to select one or two pages, usually you need to select at once some interval of pages. Therefore, in Linux there is such a thing as a virtual memory area (VMA), which describes some kind of address space inside the virtual address space of this process. Each such VMA has its own rights (read, write, execute) and scope: it can be private or shared (which is “fiddling (share)” with other processes in the system).
Memory allocation can be divided into four cases: there is an allocation of private memory and memory, which we can share with someone (share); The two other categories are the division into anonymous memory and the one that is associated with the file on the disk. The most common memory allocation functions are malloc and free. If we are talking about
In fact, Linux does not allocate all the requested memory at once. The process of allocating memory — Demand Paging — begins with what we request from the system core a memory page, and it falls into the Only Allocated area. The kernel responds to the process: here is your memory page, you can use it. And nothing else happens. No physical allocation occurs. And it will happen only if we try to make an entry on this page. At this moment, the call will go to the Page Table - this structure translates the virtual addresses of the process into the physical addresses of the RAM. Two blocks will also be involved: MMU and TLB, as can be seen from the figure. They allow you to speed up the allocation and serve to translate virtual addresses into physical ones.
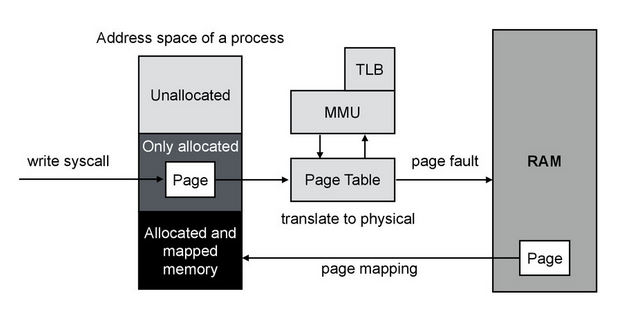
After we understand that this page in the Page Table does not correspond to anything, that is, there is no connection with the physical memory, we get Page Fault - in this case, minor (minor), since there is no access to the disk. After this process, the system can write to the allocated memory page. For the process, all this happens transparently. And we can observe an increase in the counter of the minor Page Fault for the process by one unit. There is also a major Page Fault - in the case when the disk is accessed for the contents of the page (in the case of
One of the Linux memory tricks — Copy On Write — allows you to do very fast fork processes.
The memory subsystem and the file subsystem are closely related. Since working with the disk directly is very slow, the kernel uses RAM as a layer.
What conclusions can be made? We can work with files as with memory. We have a lazy loading, that is, we can zapapit a very, very large file, and it will be loaded into the process memory via Page Cache only as needed. Everything also happens faster because we use fewer system calls and, in the end, it saves memory. It is also worth noting that at the end of the program the memory does not disappear anywhere and remains in Page Cache.
In the beginning it was said that all the writing and reading go through Page Cache, but sometimes for some reason, there is a need to deviate from this behavior. Some software products work in this way, for example, MySQL with InnoDB.
We can tell the kernel that in the near future we will not work with this file, and we can force you to unload the file pages from Page Cache using special system calls:
The vmtouch utility can also extract file pages from Page Cache - the “e” key.
Let's talk about Readahead. If we read the files from the disk via Page Cache every page one by one, then we will have quite a lot of Page Fault and we will often go to disk for data. Therefore, we can control the size of Readahead: if we read the first and second pages, the kernel realizes that, most likely, we need a third one. And since it is expensive to walk on the disk, we can read a little more in advance by loading the file in advance into Page Cache and responding in the future from it. This way, the replacement of future heavy major page faults with the minor (minor) page fault.
So we gave everyone a memory, all the processes are satisfied, and suddenly our memory is over. Now we need to somehow release it. The process of searching and allocating free memory in the kernel is called Page Reclaiming. In memory, there may be memory pages that cannot be retrieved - locked pages (locked). Besides them there are four more categories of pages. Kernel pages that should not be unloaded, because it will slow down the entire system; The Swappable pages are such pages of anonymous memory that can not be unloaded anywhere except in the swap device; Syncable Pages - those that can be synchronized with the disk, and in the case of an open file only for reading - such pages can be easily removed from memory; and Discardable Pages are those pages that you can simply refuse.
To put it simply, the kernel has one large Free List (in fact, it is not) in which memory pages are stored that can be issued to processes. The kernel tries to maintain the size of this list in some non-zero state in order to quickly allocate memory to processes. This list is replenished by four sources: Page Cache, Swap, Kernel Memory and OOM Killer.
We must distinguish between hot and cold areas of the memory and somehow replenish our Free Lists with them. Page Cache is based on the LRU / 2 queue principle. There is an active list of pages (Active List) and an inactive list (Inactive List) of pages between which there is some connection. Allocation requests are arriving in the Free List. The system gives pages from the head of this list, and the pages from the tail of the inactive list fall into the tail of the list. New pages, when we read a file through Page Cache, always get into the head and go to the end of the inactive list, if these pages did not have at least one more appeal. If such treatment was in any place of the inactive list, then the pages immediately fall into the head of the active list and begin to move towards its tail. If at this moment again they are addressed, then the pages again make their way to the top of the list. Thus, the system tries to balance the lists: the hottest data is always in Page Cache in the active list, and the Free List is never replenished at their expense.
Also here it is worth noting an interesting behavior: pages that fill up the Free List, which in turn arrive from the inactive list, but have not yet been allocated for allocation, can be returned back to the inactive list (in this case, to the head of the inactive list) .
In total, we get five such sheets: Active Anon, Inactive Anon, Active File, Inactive File, Unevictable. Such lists are created for each NUMA node and for each Memory Zone.
With the help of cgroups we can limit several processes by any parameters. In this case, we are interested in memory: we can limit memory without swap, and we can limit memory and swap. For each group, we can tie our own Out Of Memory Killer. Using cgroups, you can conveniently get memory statistics for a process or group of processes in terms of anonymous and non-anonymous memory, use of Page Cache and others (/sys/fs/cgroup/memory/memory.stat). When using cgroups with memory limitation, Page Reclaiming is of two kinds:
Books
For those who want to take a closer look at the device and the work of Linux with memory, I recommend reading:
This lecture will be useful not only for system administrators, but also for developers of high-load systems. It will help them understand exactly how interaction with the operating system kernel occurs.
')
Terms
Resident memory is the amount of memory that is now in the RAM of the server, computer, laptop.
Anonymous memory is a memory excluding file cache and memory that has a file backend on disk.
Page fault - memory trap. Regular mechanism when working with virtual memory.
The presentation at http://www.slideshare.net/yandex/linux-44775898 is not available.
Memory pages
Work with memory is organized through pages. The memory size is usually large, addressing is present, but the operating system and hardware are not very convenient to work with each of the addresses separately, therefore all memory is paginated. Page size - 4 KB. There are also pages of a different size: the so-called Huge Pages of 2 MB and pages of 1 GB in size (we will not talk about them today).
Virtual memory is the address space of the process. The process works not with physical memory directly, but with virtual memory. Such an abstraction makes it easier to write application code, not to think that you can accidentally refer to the wrong memory addresses or addresses of another process. This simplifies the development of applications, and also allows you to exceed the size of the main RAM through the mechanisms described below. Virtual memory consists of main memory and a swap device. That is, the amount of virtual memory can be in principle of unlimited size.
To manage virtual memory in the system there is an option
overcommit . It ensures that we do not reuse memory size. It is controlled via sysctl and can be in the following three values:- 0 is the default value. In this case, heuristics are used, which ensures that we are not able to allocate virtual memory in the process much more than is in the system;
- 1 - says that we do not follow the amount of allocated memory. This is useful, for example, in programs for calculations that allocate large data arrays and work with them in a special way;
- 2 - a parameter that allows you to strictly limit the amount of virtual memory of the process.
You can see how much memory we have committed, how much is used and how much we can still allocate, in the
CommitLimit and Commited_AS lines from the file /proc/meminfo .Memory Zones and NUMA
In modern systems, all virtual memory is divided into NUMA nodes. Once we had computers with one processor and one memory bank (memory bank). Such architecture was called UMA (SMP). Everything was very clear: one system bus for communication of all components. Later it became inconvenient, began to limit the development of architecture, and, as a result, NUMA was invented.
As you can see from the slide, we have two processors that communicate with each other via some channel, and each of them has its own buses, through which they communicate with their memory banks. If we look at the picture, the delay from CPU 1 to RAM 1 in the NUMA node will be two times less than from CPU 1 to RAM 2. We can get this data and other information using the
numactl hardware command.We see that the server has two nodes and information on them (how much free physical memory is in each node). Memory is allocated on each node separately. Therefore, you can consume all the free memory on one node, and the other - to underload. To prevent this from happening (this is typical of databases), you can start the process with the numactl interleave = all command. This allows you to distribute the allocation of memory between the two nodes evenly. Otherwise, the kernel selects the node on which the scheduling process was scheduled to start and always tries to allocate memory on it.
Also, the memory in the system is divided into Memory Zones. Each NUMA node is divided into a number of such zones. They serve to support a special iron that cannot communicate across the entire range of addresses. For example, ZONE_DMA is 16 MB of the first addresses, ZONE_DMA32 is 4 GB. We look at the memory zones and their status through the file
/proc/zoneinfo .Page cache
Through Page Cache in Linux, all read and write operations are by default. It is of dynamic size, that is, it is he who will eat all your memory, if it is free. As the old joke says, if you need free memory in the server, just pull it out of the server. Page Cache divides all the files that we read into pages (the page, as we said, is 4 KB). You can see if there are any pages of a particular file in Page Cache using the
mincore() system call. Or using the vmtouch utility, which is written using this system call.How does the recording go? Any recording does not happen on the disk immediately, but in Page Cache, and this is done almost instantly. Here you can see an interesting "anomaly": writing to disk is much faster than reading. The fact is that when reading (if there is no given file page in Page Cache) we will go to the disk and wait synchronously for a response, and the record in turn will go instantly to the cache.
The downside of this behavior is that in fact the data is not recorded anywhere - they are simply in memory, and sometime they will need to be flushed to disk. At each page at record the flag is put down (it is called dirty). Such a “dirty” page appears in Page Cache. If many such pages are accumulated, the system understands that it is time to drop them onto a disk, otherwise you can lose them (if power is suddenly lost, our data will also be lost).
Process memory
The process consists of the following segments. We have a stack that grows down; He has a limit on which he can not grow.
Then comes the mmap region: there are all the process-mapped process files that we opened or created using the
mmap() system call. Next comes a large amount of unallocated virtual memory that we can use. From the bottom upwards, the heap grows - this is an area of anonymous memory. Below are the areas of the binary that we run.If we are talking about memory inside a process, then working with pages is also inconvenient: as a rule, memory allocation within a process occurs in blocks. Very rarely you need to select one or two pages, usually you need to select at once some interval of pages. Therefore, in Linux there is such a thing as a virtual memory area (VMA), which describes some kind of address space inside the virtual address space of this process. Each such VMA has its own rights (read, write, execute) and scope: it can be private or shared (which is “fiddling (share)” with other processes in the system).
Memory allocation
Memory allocation can be divided into four cases: there is an allocation of private memory and memory, which we can share with someone (share); The two other categories are the division into anonymous memory and the one that is associated with the file on the disk. The most common memory allocation functions are malloc and free. If we are talking about
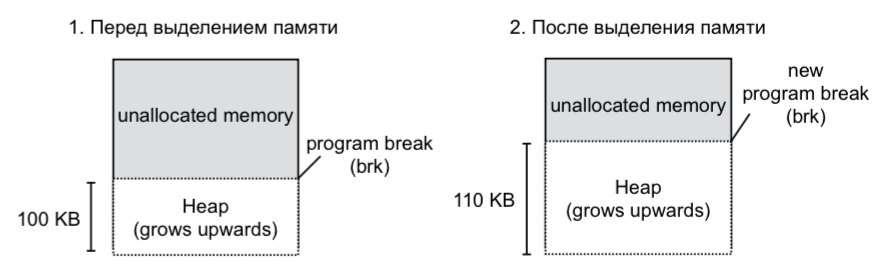
glibc malloc() , then it allocates anonymous memory in such an interesting way: it uses heap to allocate small volumes (less than 128 KB) and mmap() for large volumes. This allocation is necessary so that the memory is spent more optimally and it can easily be given to the system. If there is not enough memory in the heap to allocate, the system call brk() called, which expands the heap. The mmap() system call is responsible for mapping the contents of a file to the address space. munmap() in turn frees the mapping. mmap() has flags that control the visibility of changes and the level of access.In fact, Linux does not allocate all the requested memory at once. The process of allocating memory — Demand Paging — begins with what we request from the system core a memory page, and it falls into the Only Allocated area. The kernel responds to the process: here is your memory page, you can use it. And nothing else happens. No physical allocation occurs. And it will happen only if we try to make an entry on this page. At this moment, the call will go to the Page Table - this structure translates the virtual addresses of the process into the physical addresses of the RAM. Two blocks will also be involved: MMU and TLB, as can be seen from the figure. They allow you to speed up the allocation and serve to translate virtual addresses into physical ones.
After we understand that this page in the Page Table does not correspond to anything, that is, there is no connection with the physical memory, we get Page Fault - in this case, minor (minor), since there is no access to the disk. After this process, the system can write to the allocated memory page. For the process, all this happens transparently. And we can observe an increase in the counter of the minor Page Fault for the process by one unit. There is also a major Page Fault - in the case when the disk is accessed for the contents of the page (in the case of
mmpa() ).One of the Linux memory tricks — Copy On Write — allows you to do very fast fork processes.
Work with files and memory
The memory subsystem and the file subsystem are closely related. Since working with the disk directly is very slow, the kernel uses RAM as a layer.
malloc() uses more memory: copying to user space. Also, more CPU is consumed, and we get more context switches than if we worked with the file via mmap() .What conclusions can be made? We can work with files as with memory. We have a lazy loading, that is, we can zapapit a very, very large file, and it will be loaded into the process memory via Page Cache only as needed. Everything also happens faster because we use fewer system calls and, in the end, it saves memory. It is also worth noting that at the end of the program the memory does not disappear anywhere and remains in Page Cache.
In the beginning it was said that all the writing and reading go through Page Cache, but sometimes for some reason, there is a need to deviate from this behavior. Some software products work in this way, for example, MySQL with InnoDB.
We can tell the kernel that in the near future we will not work with this file, and we can force you to unload the file pages from Page Cache using special system calls:
- posix_fadvide ();
- madvise ();
- mincore ().
The vmtouch utility can also extract file pages from Page Cache - the “e” key.
Readahead
Let's talk about Readahead. If we read the files from the disk via Page Cache every page one by one, then we will have quite a lot of Page Fault and we will often go to disk for data. Therefore, we can control the size of Readahead: if we read the first and second pages, the kernel realizes that, most likely, we need a third one. And since it is expensive to walk on the disk, we can read a little more in advance by loading the file in advance into Page Cache and responding in the future from it. This way, the replacement of future heavy major page faults with the minor (minor) page fault.
So we gave everyone a memory, all the processes are satisfied, and suddenly our memory is over. Now we need to somehow release it. The process of searching and allocating free memory in the kernel is called Page Reclaiming. In memory, there may be memory pages that cannot be retrieved - locked pages (locked). Besides them there are four more categories of pages. Kernel pages that should not be unloaded, because it will slow down the entire system; The Swappable pages are such pages of anonymous memory that can not be unloaded anywhere except in the swap device; Syncable Pages - those that can be synchronized with the disk, and in the case of an open file only for reading - such pages can be easily removed from memory; and Discardable Pages are those pages that you can simply refuse.
Sources of replenishment Free List
To put it simply, the kernel has one large Free List (in fact, it is not) in which memory pages are stored that can be issued to processes. The kernel tries to maintain the size of this list in some non-zero state in order to quickly allocate memory to processes. This list is replenished by four sources: Page Cache, Swap, Kernel Memory and OOM Killer.
We must distinguish between hot and cold areas of the memory and somehow replenish our Free Lists with them. Page Cache is based on the LRU / 2 queue principle. There is an active list of pages (Active List) and an inactive list (Inactive List) of pages between which there is some connection. Allocation requests are arriving in the Free List. The system gives pages from the head of this list, and the pages from the tail of the inactive list fall into the tail of the list. New pages, when we read a file through Page Cache, always get into the head and go to the end of the inactive list, if these pages did not have at least one more appeal. If such treatment was in any place of the inactive list, then the pages immediately fall into the head of the active list and begin to move towards its tail. If at this moment again they are addressed, then the pages again make their way to the top of the list. Thus, the system tries to balance the lists: the hottest data is always in Page Cache in the active list, and the Free List is never replenished at their expense.
Also here it is worth noting an interesting behavior: pages that fill up the Free List, which in turn arrive from the inactive list, but have not yet been allocated for allocation, can be returned back to the inactive list (in this case, to the head of the inactive list) .
In total, we get five such sheets: Active Anon, Inactive Anon, Active File, Inactive File, Unevictable. Such lists are created for each NUMA node and for each Memory Zone.
A few words about cgroups
With the help of cgroups we can limit several processes by any parameters. In this case, we are interested in memory: we can limit memory without swap, and we can limit memory and swap. For each group, we can tie our own Out Of Memory Killer. Using cgroups, you can conveniently get memory statistics for a process or group of processes in terms of anonymous and non-anonymous memory, use of Page Cache and others (/sys/fs/cgroup/memory/memory.stat). When using cgroups with memory limitation, Page Reclaiming is of two kinds:
- Global Reclaiming, when we are looking for memory for the whole system - we replenish the Free Lists system;
- Target Reclaiming, when we release the memory in one of the cgroup - in case of lack of memory in it.
Books
For those who want to take a closer look at the device and the work of Linux with memory, I recommend reading:
- SystemsPerformance: Enterprise and the Cloud;
- Linux System Programming: Talking Directly to the Kernel and C Library;
- Linux Kernel Development (3rd Edition).
Source: https://habr.com/ru/post/250753/
All Articles