JMeter: Forget Beanshell Sampler
With the help of standard elements of the test plan in Jmeter, much can be done, but not all. To extend the functionality and implement more complex logic, it is customary to use the BeanShell Sampler - somehow it has historically been around the world. And all over the world they periodically suffer from this, but continue to eat cactus.
In principle, in order to achieve the best results in terms of the performance of the load station itself, the most effective way is to implement your Java Request or even write your own sampler. But personally, I do not like this decision because of:
So I always tried to avoid such a decision (and so far I avoided it!). I personally like it when the code is in the test plan itself, and you can track the time to execute this code using JMeter. In this sense, the BeanShell approach of the sampler is very convenient, only its implementation is bad. I'll tell you why.

Once we developed a highly loaded test plan using code inserts in BeanShell Sampler. At the design stage, everything went fine, but when we started the trial runs of the load tests, we were faced with very unpleasant behavior. On a certain number of threads, everything worked fine. But with an increase in the number of threads, some kind of inadequacy began. The test was heavily deficient in the target load intensity, and reports showed that the processing time of individual BeanShell samplers reached tens of seconds! Moreover, there were quite a few BeanShell samplers — one or two per thread group, and not to say that something complicated was happening there. Studying the performance parameters of the load station itself did not reveal any problems: the CPU load was 20–30 percent, the memory for the JMeter process was sufficient and the garbage collector cleared it in a timely manner. It is clear that the problem is in the JMeter software itself or in the implementation of the BeanShell interpreter. Playing with Reset bsh.Interpreter does not give anything; Moreover, in one place they write that it is better to install it so that there is no memory overflow, in another it is better to remove it for performance reasons.
Messages about such problems are occasionally found on the JMeter forums and come in the Apache JMeter User mailing list. Colleagues also complained about the behavior of some tests, but tended to attribute the problem to the tool itself.
')
JMeter has a very similar sampler called the JSR223 Sampler. Not even just a sampler, but the whole family: Sampler, Timer, Pre- and PostProcessor, Assertion, Timer and Listener. Documentation on it begins with very encouraging words that this sampler will allow to achieve significant performance improvements. But the attentive reader is immediately frustrated: to achieve this effect, you should choose a scripting engine that supports compilation. Right there, beside, it is indicated that the engine for Java is not.
Regarding Java, I will say even more: it is implemented by the same engine as BeanShell. It is easy to be convinced of it, having caused an error in the executed code. In the stack of exceptions in the log you will see that both there and there the bsh interpreter is called. Therefore, there is absolutely no difference between JSR223 / java and BeanShell Sampler. About the other engines, nothing is said, but they are also all interpretable. Thus, in the standard JMeter delivery there are no engines on which it would be possible to get profit from compilation.
The only compiled script engine mentioned in the documentation is Groovy . There are other engines that support JSR223. I tried Scala, was horrified by how slowly this bundle works and left this topic until better times. (Note: the point here is probably not in Scala, but in the implementation of the JSR 223 standard and in the implementation of the Compilable interface.)
To enable Groovy support, you need to download the latest version of binaries from the project site or here . From the archive we need only one file: embeddable \ groovy-all- {version} .jar. It needs to be unpacked in the zhimetra lib folder After restarting the program, Groovy appears in the list of available JSR223 languages:
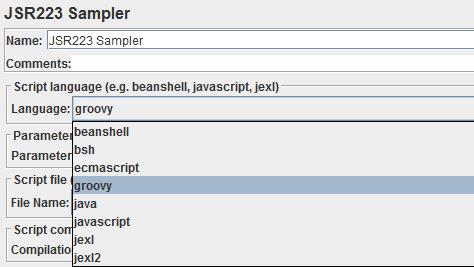
After we remade all the BeanShell samplers of our test plan for JSR223 + Groovy, a miracle happened: everything began to work as it should (well, or at least how we programmed), without brakes, and the CPU load became even lower. The response time of the JSR223 samplers was lower by orders of magnitude and the test went out to the required load.
If we go back to what we started with - various ways to implement additional program logic - then the solution with Groovy should be enough for almost all cases, except for those that really need to squeeze out the percentages. Groovy scripts are compiled into regular Java bytecode and executed in the context of each stream as if it were native Java code (but you have to remember that it has its own compiler, and there is an overhead for calling the engine). The guys from Blazemeter compared the speed of various implementation options and came to the conclusion that the Groovy code is only slightly inferior in speed to the code in pure Java.
I also did a little experiment. I wrote a small fragment that performs some kind of artificial calculations in integer arithmetic:
The dependence on the input data (Parameters) and the logging are added just in case, in order to prevent any cunning compilers and interpreters from optimizing the code, excluding its implementation altogether or caching the result. Moreover, Parameters was also unique. On my laptop with a Core i7 with 100 threads of 1000 iterations, each result was as follows:
The gap between Groovy is so significant that it is even hard to believe in it, nevertheless, judging by the log, everything worked out correctly.
The big advantage of Groovy is that in 95% of cases, arbitrary Java code is Groovy valid code. Even the BeanShell syntax is further away from the current Java standard (for example, in BeanShell you have to be perverted in the case of calling functions with an arbitrary number of arguments). If you are not interested in learning all its possibilities right now, then you should not. On the other hand, if you master it , you will certainly be able to increase your efficiency.
If you used the global namespace bsh.shared in BeanShell, then a small ambush arises: there is nothing like this in Groovy. Fortunately, this problem is easy to solve on your own. For this, 10 lines of code are written:
In essence, this is a singleton, which will always (each thread) return the same object. Further it gathers in jar and is put in the lib folder of Zhimetra. Since the class is declared in the global namespace (yes, I deserve censure for it), then in the Groovy code, without any import, you can use SharedHashMap to put something there:
When you need to pick up, it is similar:
* Groovy does not have to be a declaration of variable types, as well as semicolons.
Suppose you already have a test plan that already has many BeanShell samplers, and you have found this article because you have a problem. You want to switch to Groovy. Connecting Groovy is described above and takes you no more than five minutes.
First you need to create a JSR223 Sampler and transfer the code from BeanShell to it. You can significantly simplify your life if you can unify the code and select it into a separate file by entering it in the File Name field. Then you just need to paste the JSR223 samplers into the right places using Copy / Paste. If not, copy the code from BeanShell in each case.
It is important to note here that JMeter will compile the code entered in the sampler itself only if the compilation key is specified (the Compilation Cache Key field). It should be just a string, unique within the test plan. For scripts connected via files, you do not need to enter the compilation key, as it uses the full path to the file.
There is one subtlety in Groovy syntax. First, there are two types of strings:
See more here . Groovy strings have the ability to use $ {expression} type expressions that are automatically expanded within strings to the value of expression. This is quite a convenient moment, but it surprisingly coincides in syntax with reference to JMeter variables. So if you write in Groovy
and at the same time, the usual JMeter variable with the name currId is defined in the current thread, then its value will be substituted directly into the script. In addition, it is substituted once, because after that, the code will be compiled, and the result will be cached. Therefore, care must be taken that variable names used in such expressions do not overlap with JMeter variables. And if you really need to transfer the value to the JSR223 sampler, then you need to use the Parameters field for this.
When using an external file as a source code, JMeter variable substitutions do not occur (they occur only in the fields), but you can use Parameters.
If you do not plan to use the Groovy string capabilities, then it is advisable to use Java strings (that is, in single quotes). In addition, it will be better for performance, although a penny, of course.
The BeanShell sampler behavior illustrates a typical interpreter problem: the low speed of the interpreted code. If you have only a few lines in BeanShell, you probably won't notice any problems, but you will definitely notice if there is a lot of code or if there are loops there. Exactly the same problem was observed in the LoadRunner interpreter.
If you have not had any problems running a test that uses BeanShell, then I would recommend to be safe and not create them yourself in the future. Instead, it’s better to use JSR223 + Groovy right away, thus reducing the likelihood of performance problems with load stations.
Important points to take out of the article.
How without him?
In principle, in order to achieve the best results in terms of the performance of the load station itself, the most effective way is to implement your Java Request or even write your own sampler. But personally, I do not like this decision because of:
- more effort to develop a solution;
- non-transparent support for the solution (the code lies elsewhere; it must be recompiled using additional actions);
- possible loss of bonuses that JMeter gives (for example, if you have implemented a request in the DBMS in the code, and then an HTTP request, then you will see in the statistics them in sum, and not separately).
So I always tried to avoid such a decision (and so far I avoided it!). I personally like it when the code is in the test plan itself, and you can track the time to execute this code using JMeter. In this sense, the BeanShell approach of the sampler is very convenient, only its implementation is bad. I'll tell you why.
What is bad Beanshell Sampler
Once we developed a highly loaded test plan using code inserts in BeanShell Sampler. At the design stage, everything went fine, but when we started the trial runs of the load tests, we were faced with very unpleasant behavior. On a certain number of threads, everything worked fine. But with an increase in the number of threads, some kind of inadequacy began. The test was heavily deficient in the target load intensity, and reports showed that the processing time of individual BeanShell samplers reached tens of seconds! Moreover, there were quite a few BeanShell samplers — one or two per thread group, and not to say that something complicated was happening there. Studying the performance parameters of the load station itself did not reveal any problems: the CPU load was 20–30 percent, the memory for the JMeter process was sufficient and the garbage collector cleared it in a timely manner. It is clear that the problem is in the JMeter software itself or in the implementation of the BeanShell interpreter. Playing with Reset bsh.Interpreter does not give anything; Moreover, in one place they write that it is better to install it so that there is no memory overflow, in another it is better to remove it for performance reasons.
Messages about such problems are occasionally found on the JMeter forums and come in the Apache JMeter User mailing list. Colleagues also complained about the behavior of some tests, but tended to attribute the problem to the tool itself.
')
What to do
JMeter has a very similar sampler called the JSR223 Sampler. Not even just a sampler, but the whole family: Sampler, Timer, Pre- and PostProcessor, Assertion, Timer and Listener. Documentation on it begins with very encouraging words that this sampler will allow to achieve significant performance improvements. But the attentive reader is immediately frustrated: to achieve this effect, you should choose a scripting engine that supports compilation. Right there, beside, it is indicated that the engine for Java is not.
Regarding Java, I will say even more: it is implemented by the same engine as BeanShell. It is easy to be convinced of it, having caused an error in the executed code. In the stack of exceptions in the log you will see that both there and there the bsh interpreter is called. Therefore, there is absolutely no difference between JSR223 / java and BeanShell Sampler. About the other engines, nothing is said, but they are also all interpretable. Thus, in the standard JMeter delivery there are no engines on which it would be possible to get profit from compilation.
The only compiled script engine mentioned in the documentation is Groovy . There are other engines that support JSR223. I tried Scala, was horrified by how slowly this bundle works and left this topic until better times. (Note: the point here is probably not in Scala, but in the implementation of the JSR 223 standard and in the implementation of the Compilable interface.)
To enable Groovy support, you need to download the latest version of binaries from the project site or here . From the archive we need only one file: embeddable \ groovy-all- {version} .jar. It needs to be unpacked in the zhimetra lib folder After restarting the program, Groovy appears in the list of available JSR223 languages:
After we remade all the BeanShell samplers of our test plan for JSR223 + Groovy, a miracle happened: everything began to work as it should (well, or at least how we programmed), without brakes, and the CPU load became even lower. The response time of the JSR223 samplers was lower by orders of magnitude and the test went out to the required load.
Groovy performance
If we go back to what we started with - various ways to implement additional program logic - then the solution with Groovy should be enough for almost all cases, except for those that really need to squeeze out the percentages. Groovy scripts are compiled into regular Java bytecode and executed in the context of each stream as if it were native Java code (but you have to remember that it has its own compiler, and there is an overhead for calling the engine). The guys from Blazemeter compared the speed of various implementation options and came to the conclusion that the Groovy code is only slightly inferior in speed to the code in pure Java.
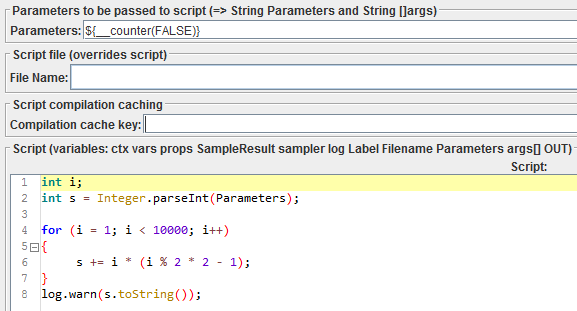
I also did a little experiment. I wrote a small fragment that performs some kind of artificial calculations in integer arithmetic:
int i; int s = Integer.parseInt(Parameters); for (i = 1; i < 10000; i++) { s += i * (i % 2 * 2 - 1); } log.warn(s.toString()); The dependence on the input data (Parameters) and the logging are added just in case, in order to prevent any cunning compilers and interpreters from optimizing the code, excluding its implementation altogether or caching the result. Moreover, Parameters was also unique. On my laptop with a Core i7 with 100 threads of 1000 iterations, each result was as follows:
| Implementation | Throughput |
|---|---|
| Beanshell Sampler | ~ 20 / sec |
| JSR223 + (java | beanshell | bsh) | ~ 20 / sec |
| JSR223 + Groovy | ~ 13800 / sec |
The gap between Groovy is so significant that it is even hard to believe in it, nevertheless, judging by the log, everything worked out correctly.
Java as a subset of Groovy
The big advantage of Groovy is that in 95% of cases, arbitrary Java code is Groovy valid code. Even the BeanShell syntax is further away from the current Java standard (for example, in BeanShell you have to be perverted in the case of calling functions with an arbitrary number of arguments). If you are not interested in learning all its possibilities right now, then you should not. On the other hand, if you master it , you will certainly be able to increase your efficiency.
bsh.shared
If you used the global namespace bsh.shared in BeanShell, then a small ambush arises: there is nothing like this in Groovy. Fortunately, this problem is easy to solve on your own. For this, 10 lines of code are written:
import java.util.concurrent.ConcurrentHashMap; public class SharedHashMap { private static final ConcurrentHashMap instance = new ConcurrentHashMap(); public static ConcurrentHashMap GetInstance() { return instance; } } In essence, this is a singleton, which will always (each thread) return the same object. Further it gathers in jar and is put in the lib folder of Zhimetra. Since the class is declared in the global namespace (yes, I deserve censure for it), then in the Groovy code, without any import, you can use SharedHashMap to put something there:
// hash map. sharedHashMap = SharedHashMap.GetInstance() // -. sharedHashMap.put('Counter', new java.util.concurrent.atomic.AtomicInteger()) When you need to pick up, it is similar:
sharedHashMap = SharedHashMap.GetInstance() // * counter = sharedHashMap.get('Counter') counter.incrementAndGet() //.. * Groovy does not have to be a declaration of variable types, as well as semicolons.
Migrating with Beanshell Sampler
Suppose you already have a test plan that already has many BeanShell samplers, and you have found this article because you have a problem. You want to switch to Groovy. Connecting Groovy is described above and takes you no more than five minutes.
First you need to create a JSR223 Sampler and transfer the code from BeanShell to it. You can significantly simplify your life if you can unify the code and select it into a separate file by entering it in the File Name field. Then you just need to paste the JSR223 samplers into the right places using Copy / Paste. If not, copy the code from BeanShell in each case.
Caching key
It is important to note here that JMeter will compile the code entered in the sampler itself only if the compilation key is specified (the Compilation Cache Key field). It should be just a string, unique within the test plan. For scripts connected via files, you do not need to enter the compilation key, as it uses the full path to the file.
Java and Groovy strings
There is one subtlety in Groovy syntax. First, there are two types of strings:
- in double quotes - Groovy strings
- in single quotes - Java strings
See more here . Groovy strings have the ability to use $ {expression} type expressions that are automatically expanded within strings to the value of expression. This is quite a convenient moment, but it surprisingly coincides in syntax with reference to JMeter variables. So if you write in Groovy
currId = 123 log.info("Current ID: ${currId}") and at the same time, the usual JMeter variable with the name currId is defined in the current thread, then its value will be substituted directly into the script. In addition, it is substituted once, because after that, the code will be compiled, and the result will be cached. Therefore, care must be taken that variable names used in such expressions do not overlap with JMeter variables. And if you really need to transfer the value to the JSR223 sampler, then you need to use the Parameters field for this.

When using an external file as a source code, JMeter variable substitutions do not occur (they occur only in the fields), but you can use Parameters.
If you do not plan to use the Groovy string capabilities, then it is advisable to use Java strings (that is, in single quotes). In addition, it will be better for performance, although a penny, of course.
Conclusion
The BeanShell sampler behavior illustrates a typical interpreter problem: the low speed of the interpreted code. If you have only a few lines in BeanShell, you probably won't notice any problems, but you will definitely notice if there is a lot of code or if there are loops there. Exactly the same problem was observed in the LoadRunner interpreter.
If you have not had any problems running a test that uses BeanShell, then I would recommend to be safe and not create them yourself in the future. Instead, it’s better to use JSR223 + Groovy right away, thus reducing the likelihood of performance problems with load stations.
Important points to take out of the article.
- Do not use BeanShell Sampler, use JSR223 + Groovy instead.
- JSR223 + java = the same BeanShell, therefore, see item 1.
- If it is possible to unify the code of several JSR223, then we use an external file. Besides the fact that eliminating duplication of code is in itself a good programming style, without having to worry about Compilation Cache Key.
- If we use the built-in sampler script, do not forget about Compilation Cache Key.
- If you need an analogue of bsh.shared, use the above solution.
Source: https://habr.com/ru/post/250731/
All Articles