Search for similar documents with MinHash + LHS
In this post, I will talk about how you can find similar documents using MinHash + Locality Sensitive Hashing. The description of LHS and Minhash on Wikipedia is replete with a horrific amount of formulas. In fact, everything is quite simple.
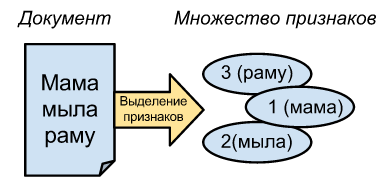
By the document in this article, I mean plain text, but in general it can be any byte array. The thing is that in order to compare any document using MinHash, you must first convert it to a set of elements.
For texts, converting to a set of word IDs is a good fit. Let's say, “mom washed the frame” -> [1, 2, 3], and “mom washed” -> [1, 2].
')
The similarity of these sets is 2/3, where 2 is the number of similar elements, and 3 is the total number of different words.
You can also break these texts into N-grams, for example, “mom washed the frame” is divided into trigrams “moms, ama, ma_, a_m, ...”, which will give similarity to 7/12.
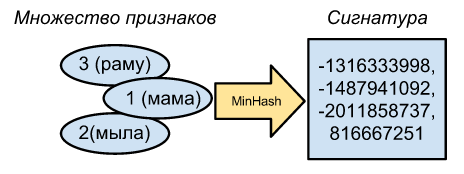
Captain Evidence tells us that MinHash is the minimum hash of all the hashes in our set. Let's say if we have a simple random hash function f (v) = v, then our sets of ID words [1, 2, 3] and [1, 2] are converted into a set of hashes [ 1078 , 2573, 7113] and [ 1078 , 2573 ], and for each set minhash is equal to 1078 . It seems easy.
The probability that the minimum hashes for the two sets coincide is very precisely equal to the similarity of these two sets. I do not want to prove it, because I'm allergic to formulas, but this is very important.
Okay, having one minhash, we won’t do very much, but it’s already clear that the same sets will give the same minhash, and for completely different sets and an ideal hash function, it is guaranteed to be different.
To fix the result, we can take a lot of different hash functions and for each of them find the minhash. Quite simply, you can get a lot of different hash functions by generating a lot of random, but different numbers, and xorit our first hash function on these numbers. Let's say we generate completely random numbers 700 and 7000, which will give us two additional hash functions. Then minhashes for [1, 2, 3] will be (1078, 2573, 7113) -> 1078 , (1674, 2225, 6517) -> 1674 , (8046, 4437, 145) -> 145 , and for [1, 2 ] minkheshi, it’s signature will be (1078, 2573) -> 1078 , (1674, 2225) -> 1674 , (8046, 4437) -> 4437 . As you can see, the first two pairs of minhashes are the same, from which it can be very roughly assumed that the similarity of the original sets is 2/3. It is clear that the more hash functions, the more accurately you can determine the similarity of the original sets.
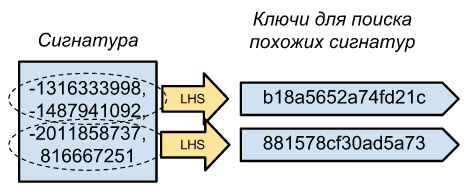
We can now determine how similar the documents are using only their signatures (N values of minhashes), but what do we need to write in the key-value store in order to be able to sample all more or less similar documents? If we use whole signatures as keys, then we will only select samples from almost identical documents, since the probability that N minheshes coincide is equal to s ^ N where s is the identity of the documents.
The solution is simple - let's say our signatures consist of 100 numbers, we can split it into several parts (say, 10 parts by 10 numbers), after which all these parts can be made keys of the whole signature.
That's all, now to determine that we already have a similar document in the database. It is necessary to obtain its signature from 100 minkheshs, divide it into ten keys, and for all corresponding full signatures, calculate its similarity (the number of coincident minskhs).
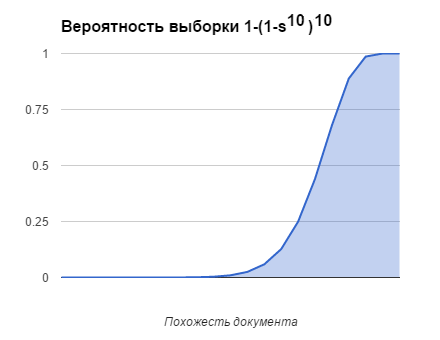
For ten keys with ten elements in each, the probability of selecting a document depending on the similarity of the document is
1. Isolation of symptoms
By the document in this article, I mean plain text, but in general it can be any byte array. The thing is that in order to compare any document using MinHash, you must first convert it to a set of elements.
For texts, converting to a set of word IDs is a good fit. Let's say, “mom washed the frame” -> [1, 2, 3], and “mom washed” -> [1, 2].
')
The similarity of these sets is 2/3, where 2 is the number of similar elements, and 3 is the total number of different words.
You can also break these texts into N-grams, for example, “mom washed the frame” is divided into trigrams “moms, ama, ma_, a_m, ...”, which will give similarity to 7/12.
2. Create a signature with MinHash
Captain Evidence tells us that MinHash is the minimum hash of all the hashes in our set. Let's say if we have a simple random hash function f (v) = v, then our sets of ID words [1, 2, 3] and [1, 2] are converted into a set of hashes [ 1078 , 2573, 7113] and [ 1078 , 2573 ], and for each set minhash is equal to 1078 . It seems easy.
The probability that the minimum hashes for the two sets coincide is very precisely equal to the similarity of these two sets. I do not want to prove it, because I'm allergic to formulas, but this is very important.
Okay, having one minhash, we won’t do very much, but it’s already clear that the same sets will give the same minhash, and for completely different sets and an ideal hash function, it is guaranteed to be different.
To fix the result, we can take a lot of different hash functions and for each of them find the minhash. Quite simply, you can get a lot of different hash functions by generating a lot of random, but different numbers, and xorit our first hash function on these numbers. Let's say we generate completely random numbers 700 and 7000, which will give us two additional hash functions. Then minhashes for [1, 2, 3] will be (1078, 2573, 7113) -> 1078 , (1674, 2225, 6517) -> 1674 , (8046, 4437, 145) -> 145 , and for [1, 2 ] minkheshi, it’s signature will be (1078, 2573) -> 1078 , (1674, 2225) -> 1674 , (8046, 4437) -> 4437 . As you can see, the first two pairs of minhashes are the same, from which it can be very roughly assumed that the similarity of the original sets is 2/3. It is clear that the more hash functions, the more accurately you can determine the similarity of the original sets.
3. Making Keys with Locality Sensitive Hashing
We can now determine how similar the documents are using only their signatures (N values of minhashes), but what do we need to write in the key-value store in order to be able to sample all more or less similar documents? If we use whole signatures as keys, then we will only select samples from almost identical documents, since the probability that N minheshes coincide is equal to s ^ N where s is the identity of the documents.
The solution is simple - let's say our signatures consist of 100 numbers, we can split it into several parts (say, 10 parts by 10 numbers), after which all these parts can be made keys of the whole signature.
That's all, now to determine that we already have a similar document in the database. It is necessary to obtain its signature from 100 minkheshs, divide it into ten keys, and for all corresponding full signatures, calculate its similarity (the number of coincident minskhs).
For ten keys with ten elements in each, the probability of selecting a document depending on the similarity of the document is
Source: https://habr.com/ru/post/250673/
All Articles