How does the brain work?
This post is based on a lecture by James Smith , a professor at the University of Wisconsin-Madison, specializing in microelectronics and computer architecture.
The history of computer science as a whole comes down to the fact that scientists are trying to understand how the human brain works and to recreate something similar in its capabilities. How exactly do scientists research it? Imagine that in the 21st century aliens arrive on Earth, who have never seen the computers we are used to, and are trying to investigate the structure of such a computer. Most likely, they will start by measuring the voltages on the conductors, and they will find that the data is transmitted in binary form: the exact value of the voltage is not important, it is only the presence or absence that is important. Then, perhaps, they will understand that all electronic circuits are made up of identical “logic gates”, which have an input and an output, and the signal inside the circuit is always transmitted in one direction. If aliens are smart enough, then they will be able to figure out how the combinational circuits work - they alone are enough to build relatively complex computing devices. Maybe aliens will figure out the role of a clock signal and feedback; but they are unlikely to be able, while studying a modern processor, to recognize in it a von Neumann architecture with shared memory, a command counter, a set of registers, etc. The fact is that by the end of forty years of chasing performance, a whole hierarchy of “memories” appeared with processors with ingenious synchronization protocols between them; several parallel pipelines, equipped with predictors of transitions, so that the concept of “team counter” actually loses its meaning; each command has its own register contents, etc. To implement a microprocessor, several thousand transistors are sufficient; it takes hundreds of millions to make its performance reach its usual level. The point of this example is that to answer the question “how does a computer work?”, It is not necessary to understand the work of hundreds of millions of transistors: they only obscure the simple idea underlying the architecture of our computers.
Neuron Simulation
The cortex of the human brain consists of about one hundred billion neurons. Historically, scientists who study the work of the brain, tried to cover with their theory all this colossal construction. The structure of the brain is described hierarchically: the cortex consists of lobes, the lobes - of “ hyper columns” , those of “minicolumns” ... The minicolumn consists of about a hundred individual neurons.
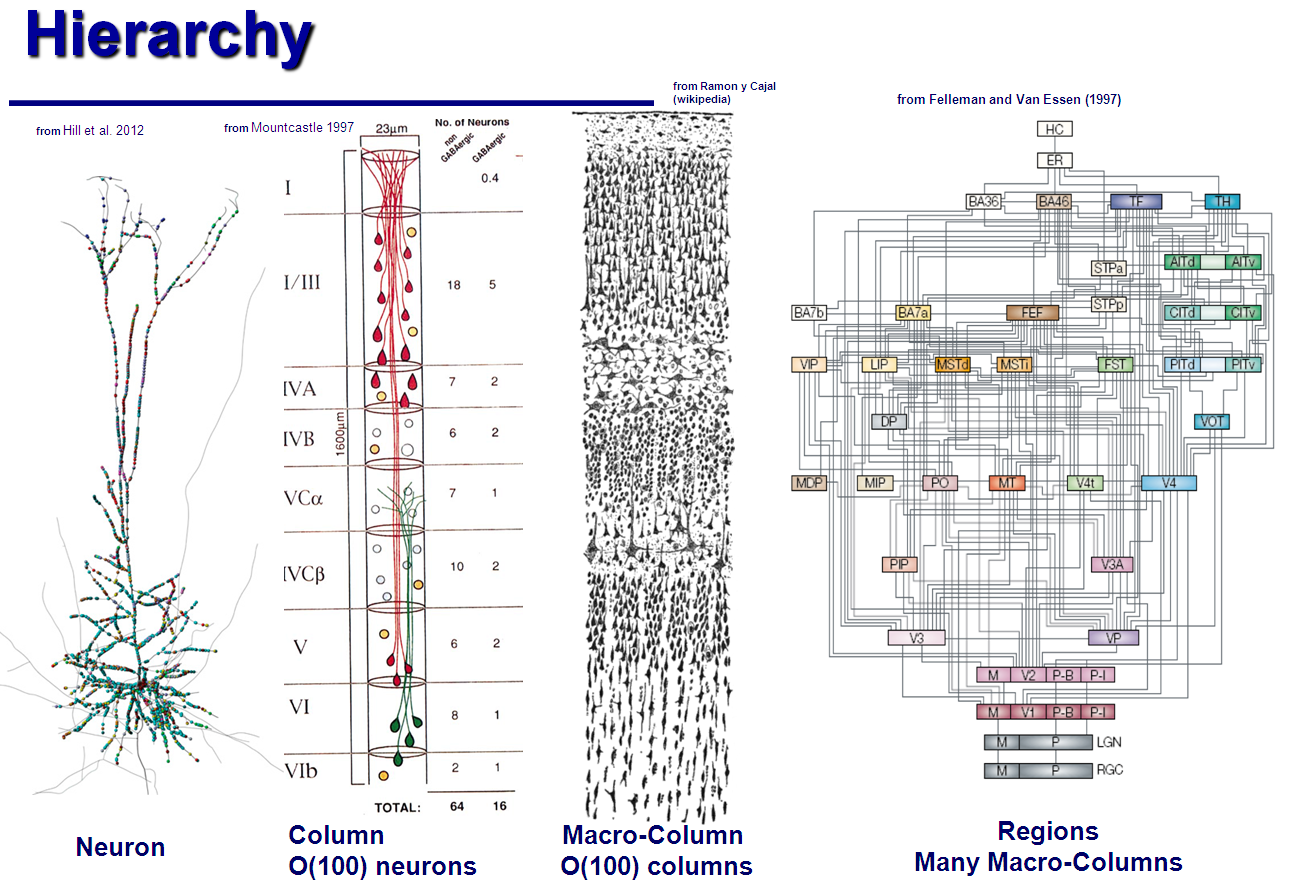
')
By analogy with a computer device, the absolute majority of these neurons are needed for speed and efficiency, for fault tolerance, etc .; but the basic principles of the device of the brain are just as impossible to detect with a microscope as it is impossible to detect the instruction counter by viewing a microprocessor under a microscope. Therefore, a more fruitful approach is to try to understand the structure of the brain at the lowest level, at the level of individual neurons and their columns; and then, based on their properties, to try to guess how the whole brain could work. Something like this, the aliens, having understood the operation of the logic gates, could eventually make up the simplest processor of them - and make sure that it is equivalent in their abilities to real processors, even though they are much more complicated and more powerful.
In the figure above, the body of the neuron (on the left) has a small red spot at the bottom; all the rest is dendrites , “inputs” of the neuron, and one axon , “output”. Multi-colored dots along the dendrites are synapses that connect a neuron to the axons of other neurons. The operation of neurons is described very simply: when a voltage “surge” occurs above the threshold level on the axon (typical burst duration is 1ms, the level is 100mV), then the synapse “breaks through” and the voltage surge goes to dendrite. At the same time, the surge “smoothes out”: first, the voltage rises to about 1 mV in 5..20 ms, then decays exponentially; thus, the burst duration is stretched to ~ 50ms.
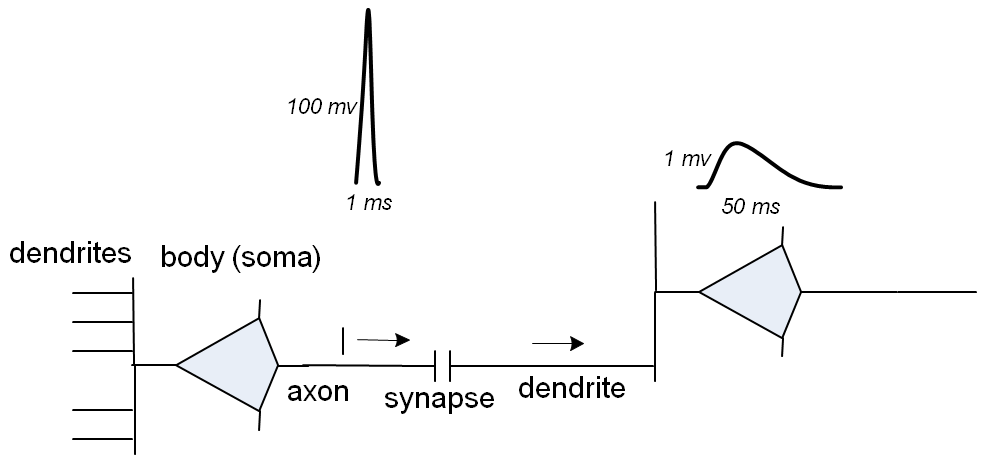
If several synapses of one neuron are activated with a small interval of time, then the “smoothed bursts” excited by each of them in the neuron are added. Finally, if quite a few synapses are active at the same time, the voltage on the neuron rises above the threshold level, and its own axon “breaks through” the synapses of the neurons associated with it.
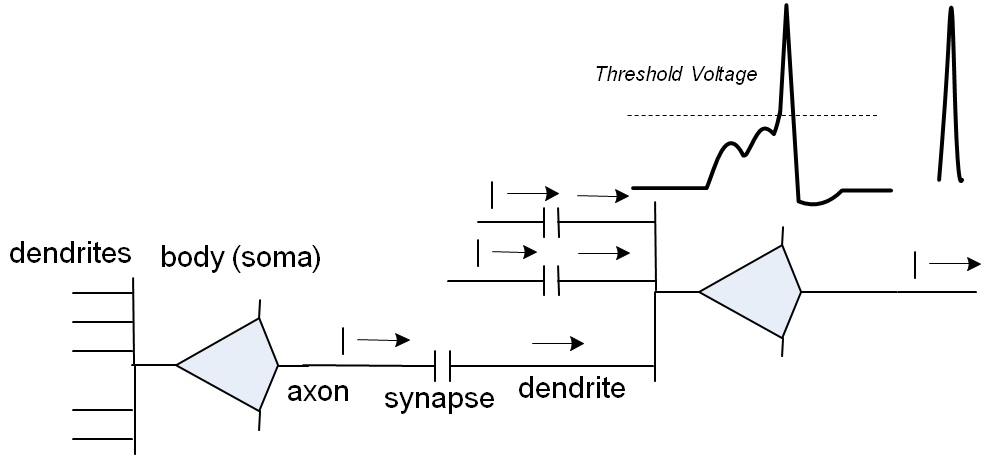
The more powerful the original bursts were, the faster the smoothed bursts grow, and the less delay there will be until activation of the next neurons.
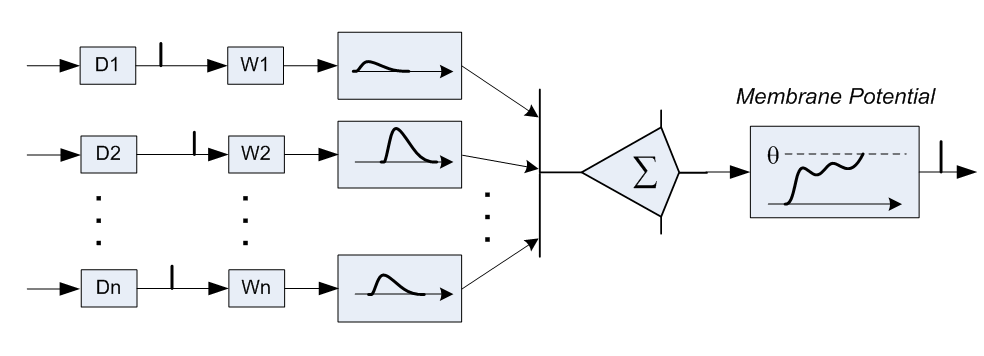
In addition, there are "inhibitory neurons", the activation of which lowers the total voltage on the neurons associated with it. There are 15.25% of such inhibitory neurons.
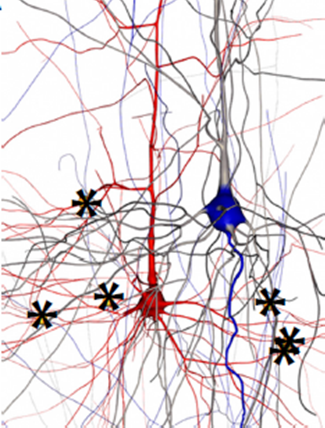 Each neuron has thousands of synapses; but at any given time no more than a tenth of all synapses are active. Neuron response time is in units of ms; the same order of the delay in the propagation of the signal along the dendrite, i.e. These delays have a significant impact on the functioning of the neuron. Finally, a pair of neighboring neurons, as a rule, connects not one synapse, but about a dozen - each with its own distance to the bodies of both neurons, and therefore with its own delay time. In the illustration to the right, two neurons, depicted in red and blue, are connected by six synapses.
Each neuron has thousands of synapses; but at any given time no more than a tenth of all synapses are active. Neuron response time is in units of ms; the same order of the delay in the propagation of the signal along the dendrite, i.e. These delays have a significant impact on the functioning of the neuron. Finally, a pair of neighboring neurons, as a rule, connects not one synapse, but about a dozen - each with its own distance to the bodies of both neurons, and therefore with its own delay time. In the illustration to the right, two neurons, depicted in red and blue, are connected by six synapses.Each synapse has its own “resistance” that lowers the incoming signal (in the example above, from 100mV to 1mV). This resistance dynamically adjusts: if the synapse is activated immediately before activating the axon, then the signal from this synapse apparently correlates well with the general conclusion, so that the resistance decreases and the signal will contribute more to the voltage on the neuron. If the synapse was activated immediately after the activation of the axon, then, apparently, the signal from this synapse had no relation to the activation of the axon, so that the resistance of the synapse increases. If two neurons are connected by several synapses with different delay times, then this adjustment of resistances allows you to choose the optimal delay, or the optimal combination of delays: the signal starts to reach exactly when it is most useful.
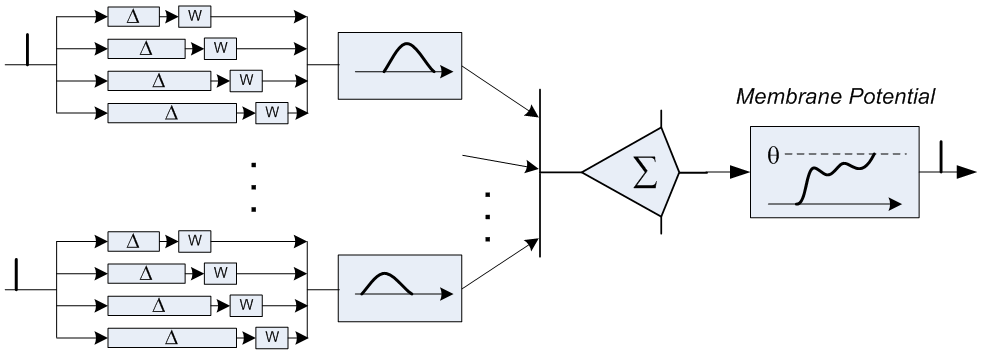
Thus, the model of a neuron accepted by neural network researchers — with a single connection between a pair of neurons and with an instantaneous propagation of a signal from one neuron to another — is very far from a biological picture. In addition, traditional neural networks operate not with the time of individual bursts, but with their frequency : the more often the bursts at the inputs of the neuron, the more often there will be bursts at the output. Those details of the neuron device, which are rejected in the traditional model - are they essential or insignificant for describing the work of the brain? Neuroscientists have accumulated a huge mass of observations about the structure and behavior of neurons - but which of these observations shed light on the overall picture, and which - only “implementation details”, and - like the predictor of transitions in the processor - do not affect anything other than work efficiency? James believes that it is the temporal characteristics of the interaction between neurons that make it possible to get closer to understanding the issue; that asynchrony is just as important for brain work as synchronism is for computer work.
Another “implementation detail” is the unreliability of a neuron: with some probability it can be activated spontaneously, even if the sum of the voltages on its dendrites does not reach the threshold level. Thanks to this, the “learning” of a neuron column can be started with any sufficiently large resistance at all synapses: first, no combination of synapse activations will lead to axon activation; then spontaneous bursts lead to the fact that the resistance of synapses, which were activated shortly before these spontaneous bursts, will decrease. Thus, the neuron will begin to recognize specific “patterns” of input bursts. Most importantly, patterns similar to those on which the neuron was trained will also be recognized, but the surge on the axon will be weaker and / or later, the smaller the neuron is “confident” in the result. Learning a column of neurons is much more effective than learning a normal neural network: a column of neurons does not need a control answer for those samples in which it is trained - in fact, it does not recognize , but classifies input patterns. In addition, the learning of the neuron column is localized - the change in synapse resistance depends on the behavior of only two neurons connected by it, and no others. As a result, learning leads to a change in resistance along the signal path, whereas when learning a neural network, weights change in the opposite direction: from the neurons closest to the output to the neurons closest to the input.
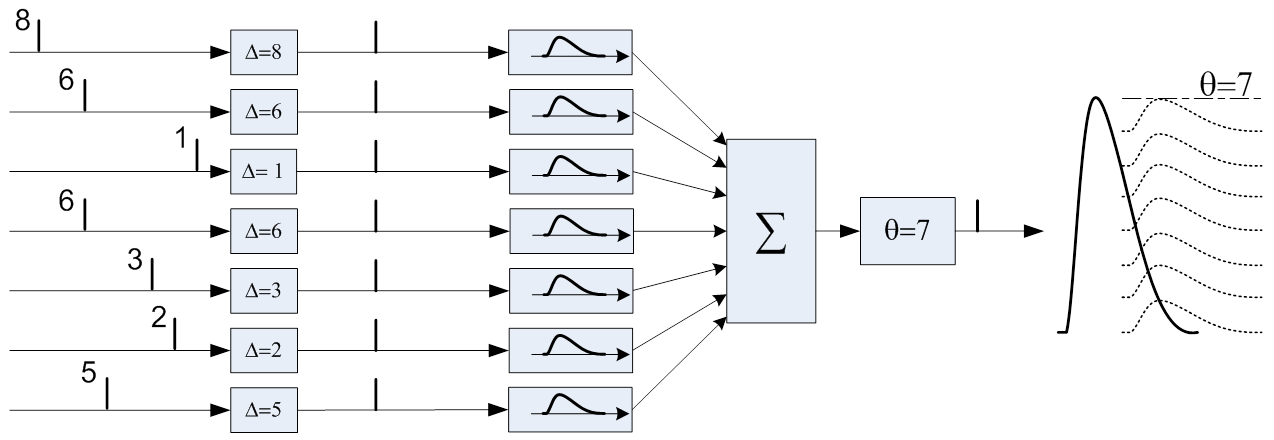
For example, here is a neuron column trained to recognize a burst pattern (8,6,1,6,3,2,5) - the values indicate the burst time on each of the inputs. As a result of the training, the delays are tuned to exactly match the pattern to be recognized, so that the voltage on the axon caused by the correct pattern is obtained as high as possible (7):
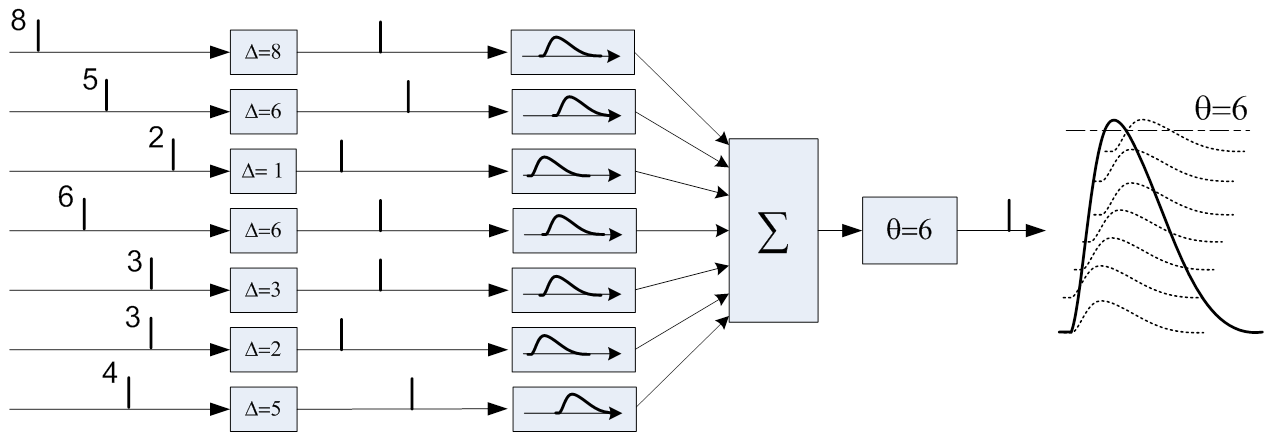
The same column will respond to a similar input pattern (8.5, 6, 6, 3, 4) with a smaller burst (6), with the voltage reaching the threshold level much later:
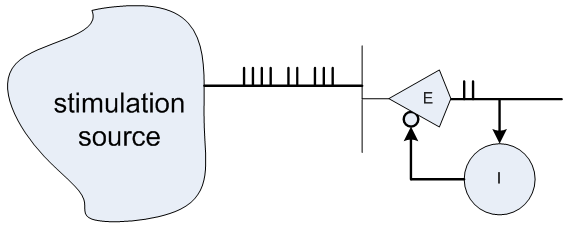 Finally, braking neurons can be used to implement “feedback”: for example, as in the illustration to the right, suppress repeated bursts at the output when the input remains active for a long time; or suppress the output spike, if it is too late compared to the input signals, in order to make the classifier more “categorical”; or, in a neural circuit for pattern recognition, different classifier columns can be connected by inhibitory neurons so that the activation of one classifier automatically suppresses all other classifiers.
Finally, braking neurons can be used to implement “feedback”: for example, as in the illustration to the right, suppress repeated bursts at the output when the input remains active for a long time; or suppress the output spike, if it is too late compared to the input signals, in order to make the classifier more “categorical”; or, in a neural circuit for pattern recognition, different classifier columns can be connected by inhibitory neurons so that the activation of one classifier automatically suppresses all other classifiers.Image recognition
To recognize handwritten tsifer from the MNIST database (28x28 pixels in shades of gray), James from the classifier columns described above assembled an analogue of the five-layer "convolutional neural network . " Each of the 64 columns in the first layer processes a fragment of 5x5 pixels from the source image; such fragments overlap. The columns of the second layer are processed four times from the first layer each, which corresponds to a fragment of 8x8 pixels from the original image. In the third layer there are only four columns - each corresponds to a fragment of 16x16 pixels. The fourth layer — the final classifier — breaks all images into 16 classes: the class is assigned according to which of the neurons is activated first. Finally, the fifth layer is the classic perceptron, which relates 16 classes with 10 control answers.
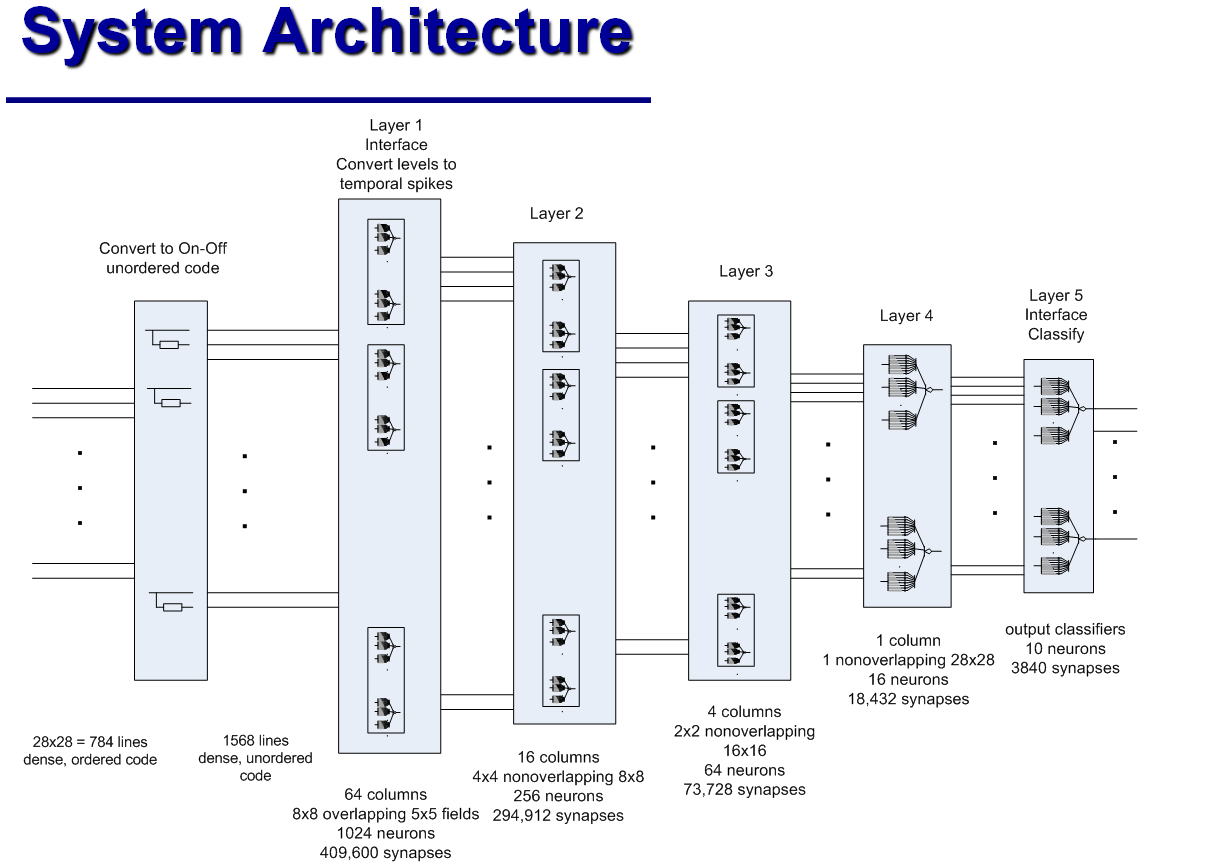
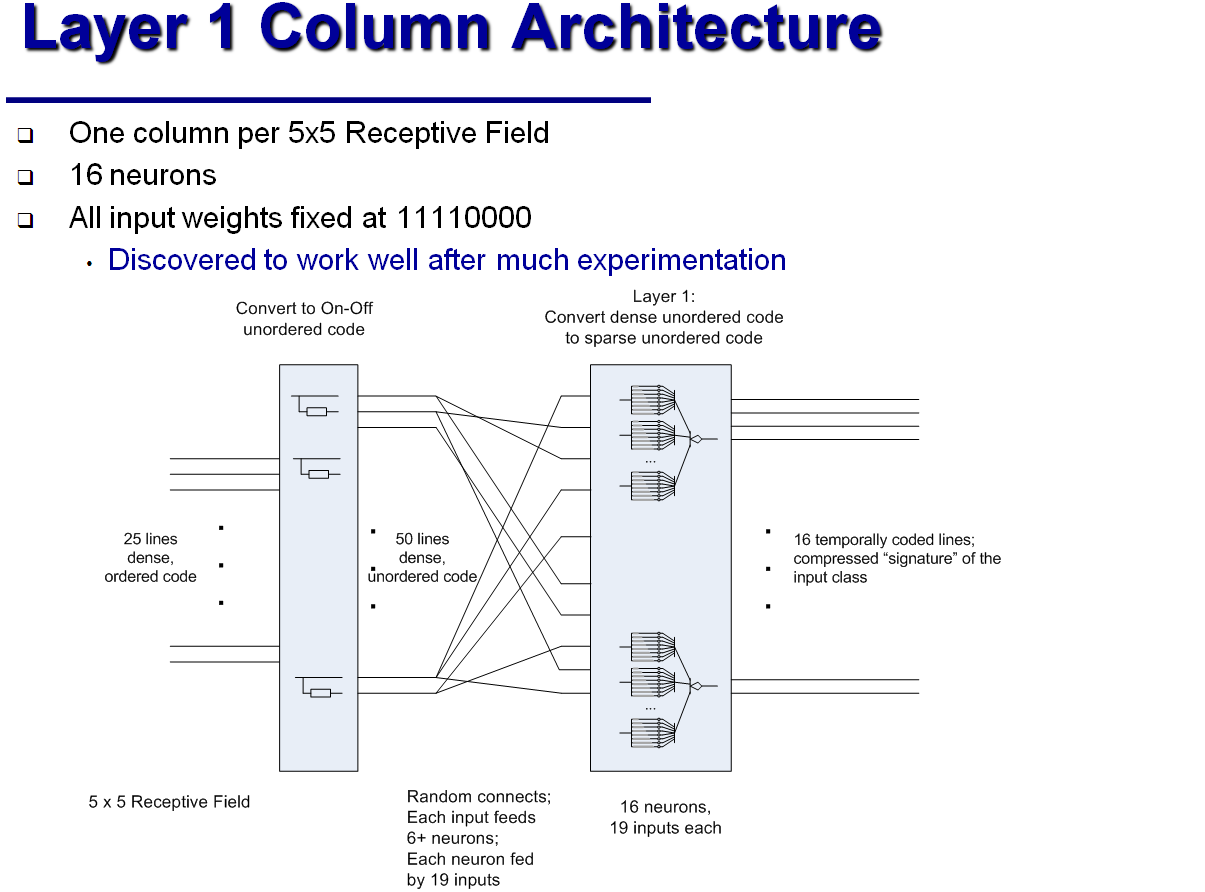
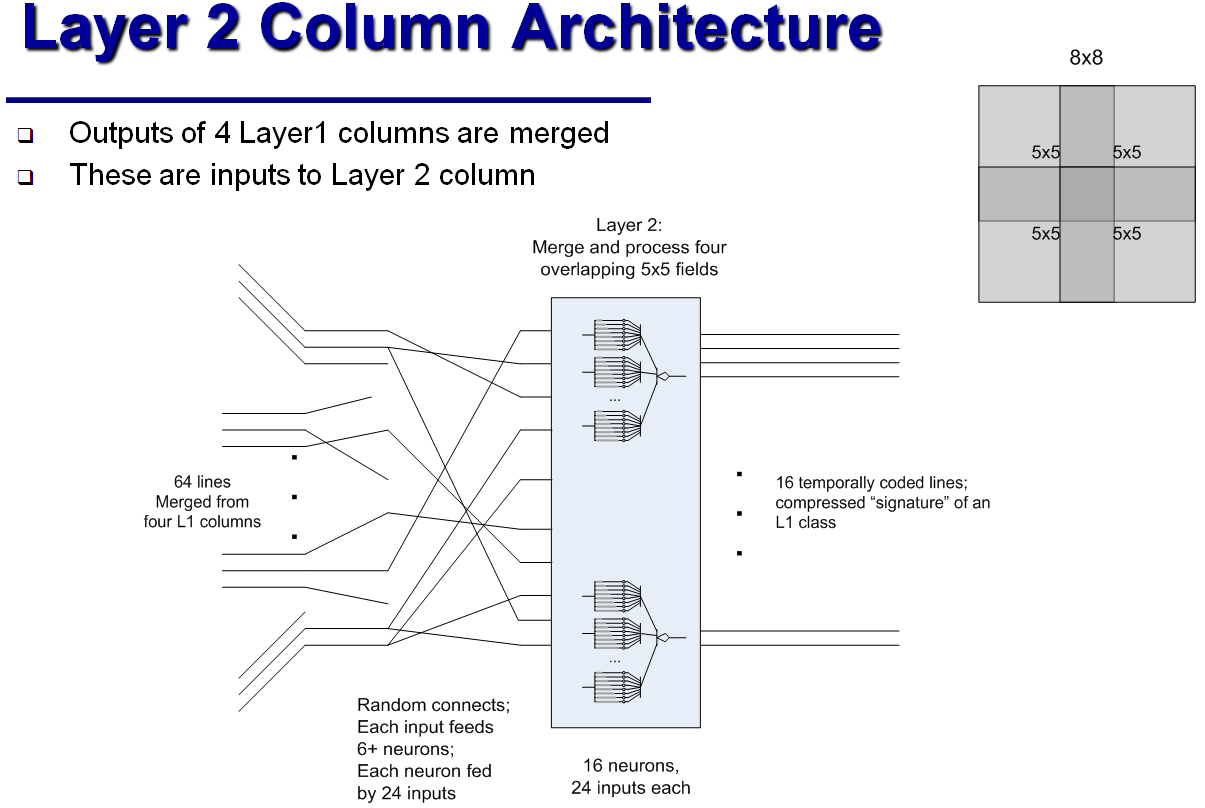
Classic neural networks reach an accuracy of 99.5% and even higher on the basis of MNIST; but according to James, his “hypercolumn” is trained in a much smaller number of iterations, due to the fact that the changes propagate along the path of the signal, and therefore affect a smaller number of neurons. As for the classical neural network, the developer of the hypercolumn defines only the configuration of the connections between neurons, and all the quantitative characteristics of the hypercolumn, i.e. synapse resistance with different delays are acquired automatically in the learning process. In addition, a hypercolumn requires an order of magnitude fewer neurons than a neural network with a similar capabilities. On the other hand, the simulation of such “analog neural circuits” on an electronic computer is somewhat hampered by the fact that, unlike digital circuits that work with discrete signals and discrete time intervals, the continuity of voltage changes and asynchronous neurons are important for neural circuits to work. James argues that a 0.1ms simulation step is enough for his recognizer to work correctly; but he did not specify how much "real time" is occupied by the training and operation of the classical neural network, and how much is the training and operation of his simulator. He himself has long been retired, and he devotes his free time to improving his analogue neural circuits.
Summary from tyomitch : a model based on biological prerequisites is presented, fairly simply arranged, and at the same time possessing interesting properties that radically distinguish it from the usual digital circuits and from neural networks. Perhaps such “analog neurons” will become the elemental basis of future devices that can cope with a number of tasks — for example, with pattern recognition — no worse than the human brain; just as digital circuits have long surpassed the human brain in the ability to count.
Source: https://habr.com/ru/post/250625/
All Articles