We overload data from XPS to 1C processing without OCR
Good day.
Faced, then, with such a problem. There is processing in 1C 8.2 and there it is necessary to push a bunch of data in automatic mode. A lot of data was in its database, in its architecture, and connecting the database to 1C or reformatting the tables was not possible. The only way, as it seemed to me, to bring the table to a virtual printer, and from there start dancing.
So, we have a document in the * .xps format, which the careful virtual printer gave us:
')
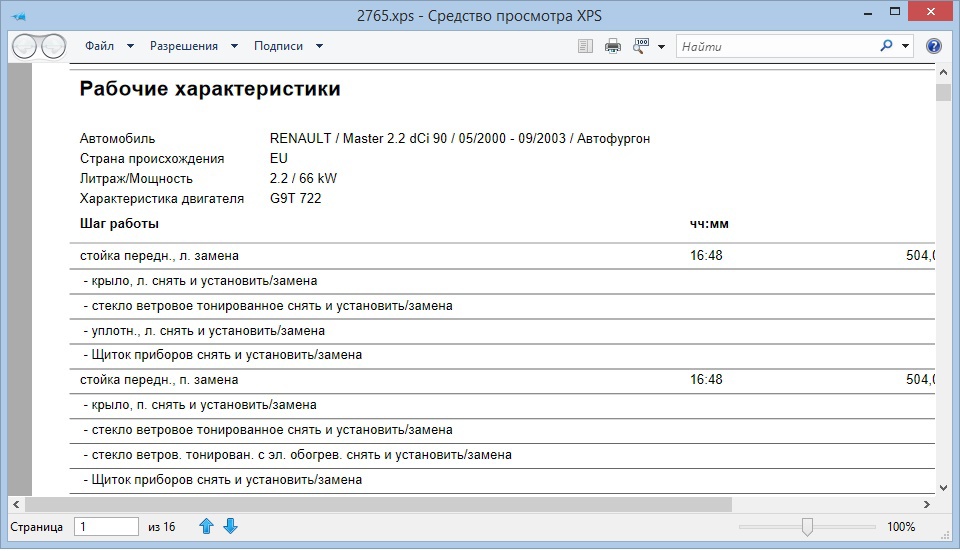
Actually, from all this, I need only the lines of the work itself, the lines of sub-work (begin with the sign "-") and the column of the standard time for each work. At first I thought that the XPS format is graphical and I have to get the resulting file into any OCR program, recognize the table there and save the data in Excel format. At first this was done, but there are huge disadvantages:
- there is no automation of the process when converting XPS -> 1C.
- OCR programs can mess up with text recognition.
- The conversion process takes a long time.
Therefore, we had to deal with the format of XPS directly.
Actually, as it turns out, the XPS format is a regular ZIP file. All information there is in the form of XML. Pictures go by pictures, text by text. But we need the text ...
Inside we have the following picture:
I will not go into the details and content of each folder - everything is simple, if you are interested, you can climb it yourself. I am specifically interested in only one file:
.. \ Documents \ 1 \ FixedDocument.fdoc
Here is the listing of this file:
As you can see, here are the paths to the file pages of the document.
We make it all in the code 1C:
First, unzip the contents of the file to a temporary folder:
Now in the file directory we have all the features to work. We are interested, as stated above, a list of files with pages. We overload the list in the table. We work with this file as with normal XML:
All, we have a list of files. Now proceed to the files themselves. The page file itself is text, but the rules for writing are not XML. The structure is block. The text and graphic information is separately written in blocks. All blocks have coordinates on the X and Y axis, for positioning on the page. I am only interested in text blocks and their coordinates, well, their information.
The blocks have a beginning and end, to understand where the beginning and end is simple: </>
In each block, the first word is his name. Text blocks are named: Glyphs
Here is an example block:
I am only interested in the parameters:
- OriginX, for the definition of columns.
- UnicodeString as the very value of what is contained in the string.
It is necessary to read as the normal text file. Text blocks are all written in one line. In 1C, you can read the line before the translation character of the corset:
And we check the resulting string for the parameter, if it starts with Glyphs, then we take it for review and analysis, if not - read the following.
We'll have to analyze the string by letter and rewrite it into a structure.
Actually, after performing the function, we have everything for analysis. The name of the parameter, its coordinates, the value of the parameter. Blocks display text in the XPS from top to bottom and from left to right. You can define columns by X coordinates, by parameter name we can analyze what information we need and what information is not. I will not describe further how it all went to the 1C reference book - everything is clear there. The main thing is, I got the answer how to quickly extract the necessary information from the "graphic" file.
Faced, then, with such a problem. There is processing in 1C 8.2 and there it is necessary to push a bunch of data in automatic mode. A lot of data was in its database, in its architecture, and connecting the database to 1C or reformatting the tables was not possible. The only way, as it seemed to me, to bring the table to a virtual printer, and from there start dancing.
So, we have a document in the * .xps format, which the careful virtual printer gave us:
')
Actually, from all this, I need only the lines of the work itself, the lines of sub-work (begin with the sign "-") and the column of the standard time for each work. At first I thought that the XPS format is graphical and I have to get the resulting file into any OCR program, recognize the table there and save the data in Excel format. At first this was done, but there are huge disadvantages:
- there is no automation of the process when converting XPS -> 1C.
- OCR programs can mess up with text recognition.
- The conversion process takes a long time.
Therefore, we had to deal with the format of XPS directly.
Actually, as it turns out, the XPS format is a regular ZIP file. All information there is in the form of XML. Pictures go by pictures, text by text. But we need the text ...
Inside we have the following picture:
I will not go into the details and content of each folder - everything is simple, if you are interested, you can climb it yourself. I am specifically interested in only one file:
.. \ Documents \ 1 \ FixedDocument.fdoc
Here is the listing of this file:
<?xml version="1.0" encoding="UTF-8" ?> - <FixedDocument xmlns="http://schemas.microsoft.com/xps/2005/06"> <PageContent Source="/Documents/1/Pages/1.fpage" /> <PageContent Source="/Documents/1/Pages/2.fpage" /> <PageContent Source="/Documents/1/Pages/3.fpage" /> <PageContent Source="/Documents/1/Pages/4.fpage" /> </FixedDocument> As you can see, here are the paths to the file pages of the document.
We make it all in the code 1C:
() = .; = (); . = ; . = "XPS |*.xps"; .() = ..(); = 0 - 1 (.[], .); (); ; ; First, unzip the contents of the file to a temporary folder:
(, ) = (, , ""); = (, ".xps", ""); ( + ); = Zip(); .( + , ZIP.); .(); Now in the file directory we have all the features to work. We are interested, as stated above, a list of files with pages. We overload the list in the table. We work with this file as with normal XML:
= XML; .( + + "\Documents\1\FixedDocument.fdoc"); .(); .(); .() .(); (.) ..(); ... = .; ; ; .(); All, we have a list of files. Now proceed to the files themselves. The page file itself is text, but the rules for writing are not XML. The structure is block. The text and graphic information is separately written in blocks. All blocks have coordinates on the X and Y axis, for positioning on the page. I am only interested in text blocks and their coordinates, well, their information.
The blocks have a beginning and end, to understand where the beginning and end is simple: </>
In each block, the first word is his name. Text blocks are named: Glyphs
Here is an example block:
<Glyphs Fill="#ff000000" FontUri="/Documents/1/Resources/Fonts/DD1ED91D-300C-4E84-BACC-6412D0EB3F5F.odttf" FontRenderingEmSize="13.2795" StyleSimulations="None" OriginX="971.84" OriginY="59.68" Indices="19,55;26;17;19;21,55;17;21;19;20,55;24" UnicodeString="07.02.2015" /> I am only interested in the parameters:
- OriginX, for the definition of columns.
- UnicodeString as the very value of what is contained in the string.
It is necessary to read as the normal text file. Text blocks are all written in one line. In 1C, you can read the line before the translation character of the corset:
= (, .UTF8); = .(); <> = (); ... And we check the resulting string for the parameter, if it starts with Glyphs, then we take it for review and analysis, if not - read the following.
We'll have to analyze the string by letter and rewrite it into a structure.
() , ; = ""; = ""; = """"; = ; (, "UnicodeString") > 0 = (, "UnicodeString") + 15 () = (, , 1); <> """" = + ; .("", ); ; ; = (, "OriginX") + 9 () = (, , 1); <> = + ; .("", ()); ; ; ; ; ; Actually, after performing the function, we have everything for analysis. The name of the parameter, its coordinates, the value of the parameter. Blocks display text in the XPS from top to bottom and from left to right. You can define columns by X coordinates, by parameter name we can analyze what information we need and what information is not. I will not describe further how it all went to the 1C reference book - everything is clear there. The main thing is, I got the answer how to quickly extract the necessary information from the "graphic" file.
Source: https://habr.com/ru/post/250371/
All Articles