Another way to compress CSS files
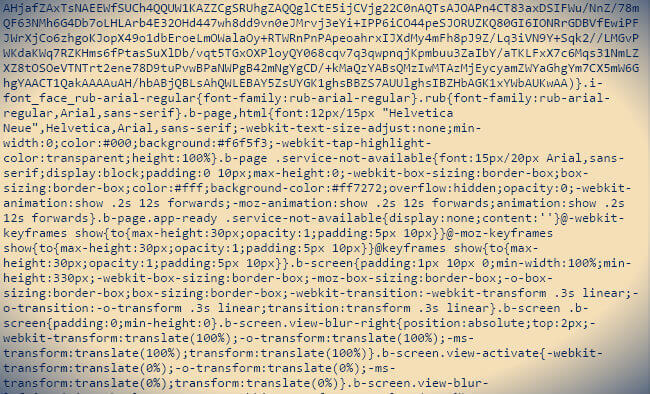
In the image above, many will see the famous picture. This is what most CSS files in production look like. We all try to have our web pages load quickly; To achieve this goal, we use various tools and techniques to optimize the loading and rendering pages. About one, but rarely used method, I would like to talk and tell how I managed to reduce the size of the mail.ru mail CSS file by 180Kb.
It would seem that there is nothing to optimize in the file shown above, all spaces and line breaks are deleted, the file is processed by some clever CSSO-type optimizer with structural change and it seems that such a file will be understood only by a browser or a drunk plumber. But, as we know, there is no limit to perfection perfection, and even less optimization.
Next, we will try to squeeze all the juice from this file.
')
If you look closely, we will notice something interesting in this file.

Please pay attention to the names of classes. Probably, you have already guessed what the discussion will be about - reducing the length of these names. Because with the advent of BEM and other CSS writing techniques, the class names became very long, and sometimes indecently long.
Life examples
I analyzed the CSS files, some popular resources and confirmed my assumption:

The image shows the classes found in the production of CSS versions of files of these sites.
Probably no one needs to explain the importance of the speed of the initial page load and its effect on user satisfaction, conversion, site traffic. With the advent of mobile devices and mobile Internet, this problem is very acute. For example, a 40Kb download on 4G Internet takes an average of 700ms, and if you look at 3G, EDGE, GPRS, WiFi during rush hour in a cafe or metro, the download time will increase significantly. Every kilobyte saved is worth its weight in gold.
If we fight for every space and line breaks in CSS files, ruthlessly cutting them out, why not compress the names of classes and identifiers to two or three characters? After all, your users do not care what the block class will be called on the page, but the page loading speed will be very important to them. Perhaps that is why the guys from Google use this technique (on google.com):
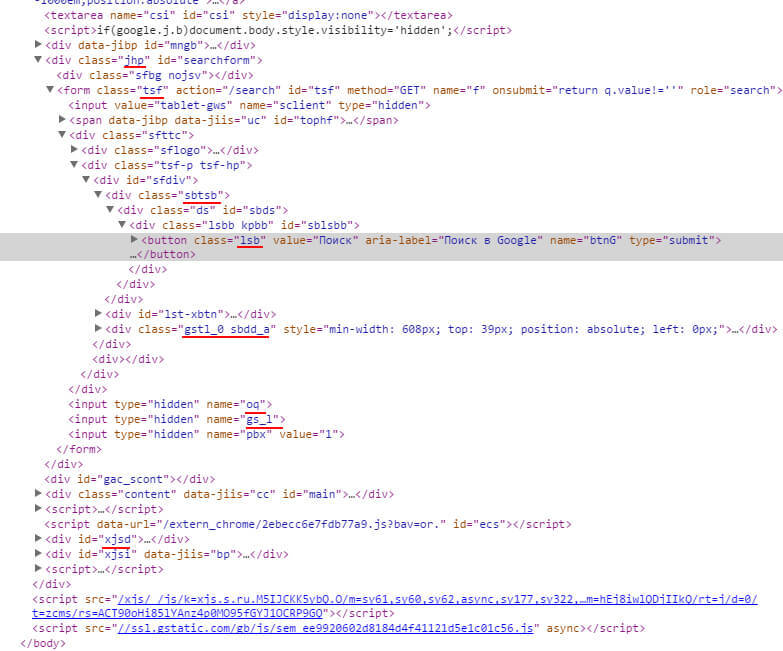
From words to deeds
So, with what it is necessary, I hope, understood. Let's get down to business. The first problem is that we cannot just take and reduce classes and identifiers in CSS files, because they are used in layout, templates and JS files. Replacing only in one place - everything will break. It becomes obvious that you need to replace the names in the whole bunch of files. In my projects for minification, gluing and other such tasks, I use Grunt.js. This build system is one of the world's most popular front-end development. Pursuing a cursory search for plug-ins that implement such a task, I did not find anything and decided to write my own
grunt-revizor
Thus was born the grunt-revizor . When writing it, I ran into several problems. In CSS files, everything is simple, the syntax is known in advance, .name or #name, but in other files it may look different. For example, in HTML
<div class = "name"> </ div>i.e. name already without a dot or in JS files
document.getElementById ('name') also without #, which complicates the problem of finding and replacing names. What is most frightening is that you can break something, for example, if the CSS class name is ".success" and in the JS file we have the variable "success", replacing it we break the JS code. And we cannot allow this, so we had to introduce the requirements for spelling names, namely, the name must end with a unique prefix, which will unambiguously enable us to distinguish a class from something else JS, HTML, and other files. For example, .b-tabs__title-block--, in this case the prefix is '-'.Sample Taska:
grunt.initConfig({ revizor: { options: { namePrefix: '__', compressFilePrefix: '-min' }, // : test/css/style1.css, test/css/style2.css, 'test/js/main.js ... src: ['test/css/*.css', 'test/html/*.html', 'test/js/*.js'], dest: 'build/' }, }); After launching this task, grunt will find all CSS, HTML and JS files that correspond to the paths from src, find all the class and identifier names ending in the __ prefix in the CSS files, compress the found names to two and three character, for example .b-tabs- -notselected__ -> .zS, after which it will save the new files, in which all found matches will be replaced, and save them in the build folder, with the names style1-min.css, index-min.html, main-min.js.
CSS example:
/* Original: style1.css */ .b-tabs__title-block-- { color: red; font-size: 16px; } .b-tabs__selected-- { font-weight: bold; } /* ======================================= */ /* Result: style1-min.css */ .eD { color: red; font-size: 16px; } .rt { font-weight: bold; } JS example:
/* Original: main.js */ var $tabmenu = $('#tabmenu--'); var tabmenu = document.getElementById('tabmenu--'); if ($tabmenu.hasClass('b-tabs__selected--')) { $tabmenu.removeClass('b-tabs__title-block--'); }; /* ======================================= */ /* Result: main-min.js */ var $tabmenu = $('#j3'); var tabmenu = document.getElementById('j3'); if ($tabmenu.hasClass('rt')) { $tabmenu.removeClass('eD'); }; The same principle for HTML, template and other files.
Some features of the plugin:
- First generated 2-character names. After the number of names exceeds 2500, 3-character names begin to be generated;
- To generate names, lowercase and uppercase letters of the Latin alphabet, numbers, symbols - and _ are used ;
- There is a collision check, i.e. A compressed name can match only one full name.
Example optimization
Let's try to find out the potential benefits of such optimization on the example of the same popular resources. I'll tell you how I will count. Of course, I will not skip CSS files through grunt-revizor, because they do not use a unique prefix. With the help of a simple Node file, I will count the total number of classes, calculate their length in bytes and calculate the potential file size from this. The simplified formula looks like this:
names = ['b-block1','b-block2','b-block3', ....]; saveSize = allNamesSize - (names.length*3) // allNamesSize - // 3 - | Site | Original file size | Compressed | In percents |
|---|---|---|---|
| Mail.ru mail (desktop version) | 849 Kb | 182.5 Kb | 26.4% |
| hh.ru (Desktop version) two files | 109.8 Kb | 30 Kb | 27.3% |
| vk.com (Mobile version) two files | 184.1 Kb | 48.5 Kb | 26.4% |
| Yandex.Taxi (Mobile version) | 127 Kb | 13 Kb | 10.3% |
| 2gis.ru (Mobile version) | 1293 Kb | 172 Kb | 13.3% |
Normal files were used, not gzip. Optimization data is approximate, because in addition to CSS files, styles were sometimes in the html page, respectively, were not taken into account here. An unpretentious regular parsing was used, which looked only for classes, moreover, not all of them were possible, and she did not look for identifiers. In addition to CSS compression, there will be a gain on other files, html, templates, etc., which are not included here either. I will note right away that some files are poorly served by such optimization, for example, files with few classes or short names are used, or many images inserted via data: URL, which is demonstrated on the 2gis and Yandex.Taxi files.
Conclusion
Of course, I did not invent anything new. This method is familiar to many, but it is rarely used, because it has both minuses and pros. For example, it introduces development difficulties, code purity, etc. By and large, gzip partially solves the problem of long names and compresses files nicely, but still a certain gain in the size and time of decompression of files can be obtained using gzip. For example, an optimized compressed mail.ru file is 20KB smaller than the same non-optimized compressed file.
I also want to say that my plugin is not a silver bullet in this issue, but only an example of implementation. Perhaps in the future from the plugin you get something really worthwhile. I will work closely on this idea, ideally, I would like the plugin to work with absolutely not prepared files, that is, without using a prefix, but to do everything automatically and accurately.
The meaning of my entire article is to raise the interest of developers to this issue, to listen to the opinions of others. Maybe someone already had a negative or positive experience in this matter. Please share it. Besides, the same Google, I think, knowingly uses this method.
In general, there is something to talk about and think about.
UDP: Soon I will answer all questions, give specific files, and compare the gain when using GZIP.
Source: https://habr.com/ru/post/250239/
All Articles