How Evernote Finds Text in Images
Searching for text in images is a fairly popular feature of Evernote. We would like to tell you how it works and answer some common questions.
How does the image processing
')
When a note is sent to Evernote during the synchronization process, any resources included in this note, with PNG, JPG or GIF MIME types, are sent to a separate set of servers that exclusively recognize text in nested images and return the results found. These results are added to the note as a hidden (more precisely not visible when viewing the note) set of metadata called recoIndex . You can see the whole recoIndex if you export the note to an ENEX file.
For example, here is an old note in one of our accounts with a snapshot of a beer bottle.

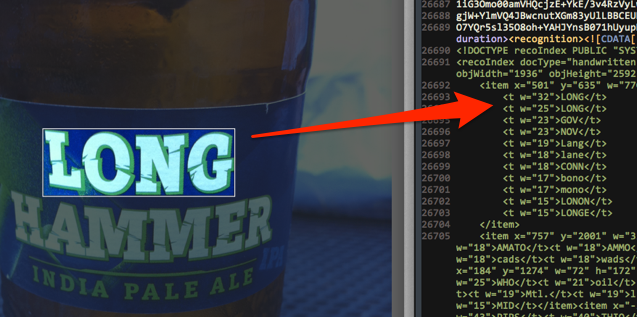
If you export this note as an ENEX file — portable export to XML for Evernote notes — and go to the end of the file, you can see the recoIndex section. RecoIndex contains several item elements. Each such element corresponds to a rectangle within which the Evernote recognition system suspects the presence of text.
Each item contains four attributes: x and y , corresponding to the coordinates of the upper left corner of the rectangle, as well as w and h , meaning its width and height.
When evaluating an image for textual content, a set of possible matches is created in the form of child elements associated with an item . Each match is assigned a weight (attribute w ), a numerical value that reflects the probability, the proposed text corresponds to the real one in the image.
The recognition results are embedded in the note and subsequently synchronized with the user's client applications. From now on, the text found in the image becomes searchable.
Here is the recoIndex in the note shown above.
<?xml version="1.0"?> <recoIndex docType="handwritten" objType="image" objID="a284273e482578224145f2560b67bf44" engineVersion="3.0.17.12" recoType="service" lang="en" objWidth="1936" objHeight="2592"> <item x="853" y="1278" w="14" h="17"> <tw="31">II</t> <tw="31">11</t> <tw="31">ll</t> <tw="31">Il</t> </item> <item x="501" y="635" w="770" h="254"> <tw="32">LONG</t> <tw="25">LONG</t> <tw="23">GOV</t> <tw="23">NOV</t> <tw="19">Lang</t> <tw="18">lane</t> <tw="18">CONN</t> <tw="17">bono</t> <tw="17">mono</t> <tw="15">LONON</t> <tw="15">LONGE</t> </item> <item x="757" y="2001" w="337" h="63"> <tw="23">APONTE</t> <tw="23">HAWK</t> <tw="19">Armas</t> <tw="19">Haas</t> <tw="18">AMBRY</t> <tw="18">AMATO</t> <tw="18">AMMO</t> <tw="18">areas</t> <tw="18">rads</t> <tw="18">pads</t> <tw="18">lads</t> <tw="18">fads</t> <tw="18">dads</t> <tw="18">cads</t> <tw="18">wads</t> <tw="18">WONKS</t> <tw="18">AMULET</t> </item> <item x="0" y="1284" w="128" h="730"> <tw="18">TWELFTH</t> </item> <item x="184" y="1274" w="72" h="172"> <tw="32">MIL</t> <tw="31">MIT</t> <tw="30">lot</t> <tw="28">It***</t> <tw="25">It**»</t> <tw="25">Ii**»</t> <tw="25">WHO</t> <tw="21">oil</t> <tw="20">LOL</t> <tw="19">TWX</t> <tw="19">TWI</t> <tw="19">mill</t> <tw="19">Ott</t> <tw="19">list</t> <tw="19">LWT</t> <tw="19">Mtl.</t> <tw="19">limit</t> <tw="19">tfiii</t> <tw="19">tot</t> <tw="18">Tim</t> <tw="18">pol</t> <tw="18">NHL</t> <tw="17">this</t> <tw="15">MID</t> </item> <!-- ... --> </recoIndex> The recoIndex set contains the item and t (matches) elements. As you can see, most item elements have several t elements, each of which is assigned a specific weight. When the user begins to search for text in the Evernote client, the search is also based on the contents of the t elements:
How is the processing of PDF
Evernote's text recognition system also works with PDF files, but their processing is different from images. In this case, an additional PDF document is created containing the recognized text. This document is added to the note with the original PDF. It is not visible to the user and is present only for search purposes. It is also not taken into account in the monthly available space for downloading user data.
For a PDF to be available for recognition, it must meet two criteria:
- contain a bitmap image
- do not have highlighted text (or at least have its minimum number).
In practice, many PDFs generated from text formats by other applications, such as text editors, do not meet these requirements. PDF files created by scanners usually meet the above criteria. However, if the scanner software performs its own text recognition in the received PDF, the file will also be excluded from processing by our service.
If you export a note from a PDF that went through text recognition, you can see two nodes in the document: data and alternate-data . The data contains the version of the original PDF encoded into 64-bit code, and the alternative- data contains the version available for search.
FAQ
What text can be recognized?
Virtually anyone, as long as the recognition system understands that this is text. Both typed (for example, street signs or posters) and handwritten (even if you don’t have the most accurate handwriting in the world) the text will be detected by the system.
What may affect the recognition is the orientation of the text. The text found in the image is evaluated for the presence of matches in the three orientation variants:
- 0 ° - normal horizontal orientation,
- 90 ° - vertical orientation
- 270 ° - vertical orientation.
Text located in the image from some other angle will be ignored. This also applies to text diagonally and mirrored.
It is also important to remember that there is no perfect text recognition system, and it is possible that the text will not be recognized contrary to your expectations. At the same time, the recognition engine is constantly being improved and improved in order to achieve greater accuracy.
Can I use Evernote to create a text version of an image with text?
Not. As mentioned above, the match system yields several options. In most cases, for a given rectangle there will be several potential matches of varying degrees of accuracy.
How fast is the recognition?
When you synchronize notes with an image, the picture is sent to the processing of a group of text recognition servers. The system is based on the principle of the queue, that is, each new image takes place at the end and will be processed after all standing before it.
The speed depends on the size of the queue at the time of sending the image. As a rule, the waiting time does not exceed an hour.
How many languages does the Evernote recognition system support?
Evernote can now index texts in 28 types in typewritten and 24 in handwritten form. New languages are regularly added, and the quality of work with existing languages is improved. Users can specify the languages used for which matches should be found during indexing by changing the corresponding parameters in the personal settings .
Where can I find out more about the Evernote recognition system?
We have previously published a couple of articles on this topic:
You can also read a review of the specifics of handwriting recognition in European and Asian languages.
Source: https://habr.com/ru/post/250189/
All Articles