Stages of birth of new functionality in the software product
This article will discuss the process of adding new functionality to the program. We will consider all the stages from the birth of the idea to the release, including the reporting of requirements by analysts to those who actually implement the whole thing, that is, to our favorite (without quotes and irony) developers. The article is primarily aimed at the transfer of practical experience (including unsuccessful) to build this process.
KDPV (this picture of relevance will probably never lose):

')
Disclaimer: all of the following description of the processes is based on the personal experience of the author, obtained in a particular company, and may not have anything to do with the objective reality of the reader. Information on each development stage is submitted in a compressed form and is intended to reveal only the main points of the process within a single article.
In the beginning was the word ...
For myself, I highlight 3 stages of the emergence of new functionality (aka "features"):
1. There is an idea described in general terms.
For example: “Add email notification support to the program”.
2. The idea is worked out from the user's point of view, that is, usage scenarios are written.
For example: “Upon completion of certain operations in the program, an e-mail will be sent to the address specified by the user through a predetermined SMTP server”.
3. The idea is explained to the developers / testers and the implementation begins directly.
Accordingly, in order to reach the 3rd stage, the analyst needs to thoroughly study the subject area and first of all understand for himself how “it” will work from the user's point of view, including (to a lesser extent) from the development point of view. Lack of elaboration of requirements at the first stage can lead to the fact that the implemented functionality will not work at all as expected by the analyst, but only as the developer understood it (which, unfortunately, happens quite often in the modern world).
Even such a seemingly simple "feature" without proper study can be corrupted if details are not properly worked out, such as:
Nevertheless, it does not matter how much time was spent on the initial elaboration of requirements, almost always unaccounted usage scenarios emerge, especially if the new functionality is quite voluminous. This is what the discussion of “features” with developers and testers who look at new opportunities from a completely different angle and can come up with scenarios that a simple user would never think of would be necessary. This process is described in more detail in the next section of the article.
Below is an example of the importance of knowing your own product when designing a new "feature" from real life. I warn you that there will be a lot of letters and specific terms. Who is not afraid - can look at the spoiler:
After the initial description (stage 2) has been compiled by the analyst, this text is read and analyzed by at least two people: the developer (who will implement it) and the tester (who will compose the test scripts).
The discussion in our case is carried out “on the sofas”: the analyst and the tester and / or the developer sit down at a cup ofayrish coffee and clarify all disputed points and inaccuracies in the description of the “features”. All discussion results are documented and lead to changes in the original description. Read more about the description of the description (and not only), read the next section.
At home, we use JIRA to track all activities (bugs, QA tasks, tickets from tech support, etc.), statistics, metrics. Confluence is used to describe processes, internal documentation, description of functional requirements, etc.
The JIRA <-> Confluence bundle was chosen for its great flexibility in building links between the elements of these two systems. For example, in Confluence, you can build a table using predefined filters from JIRA, build beautiful graphs, and track the status of several JIRA projects on one page. In addition, the built-in text editor Confluence is much more flexible than its counterpart in JIRA and is therefore better suited to describe the functionality.
There are no hard and fast rules in the description of the new functional in Confluence, but there are templates that are recommended to be followed. Here is an example of our template:
Header, JIRA ticketing, and main objectives:
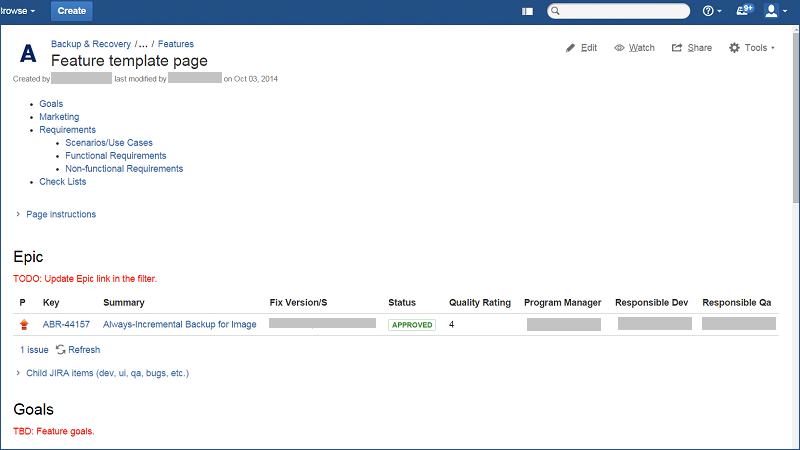
Information on marketing and instructions for registration requirements:

Link to tickets in which the user interface is drawn (“mocaps”), usage scenarios, functional and non-functional requirements:

Registration consists of the following steps:
1. A “Epic” ticket is launched in JIRA with a brief description of the required functionality.
2. It is decided which version / update this feature will be implemented in.
3. A page is launched in Confluence according to a template (example above) and is filled in by an analyst with a list of various free-form scenarios.
4. The page in Confluence is shown to testers (QA) and developers to study and write test scenarios.
5. JIRA creates tickets of the “dev task” type associated with the source “Epic” and estimates are made.
Next, the development is carried out directly, at the end of which the functionality is transferred to testers in order to “drive out” it according to previously created scripts.
At the same time, between steps 1 and 2, it can take considerable time, given that there is a lot of new functionality and, first of all, it is necessary to implement “features” with the highest priority depending on the current goals of the company.
In our case, the development is divided into many iterations (sprints) with a length of 2-4 weeks, after which a demonstration is made. The main purpose of the demonstrations is to make sure that the developed functionality corresponds to the initial idea and there are no additional risks. That is, we adhere to (we try, in any case) the principles of agile development .
Our developers were skeptical at first, considering it to be a waste of time, but, as practice has shown, it’s during the demonstrations that additional ideas arise, lost scenarios come to light and you can synchronize the vision of all participants in the process (analysts, testers, developers and bosses) .
In the development process, especially if the functionality is voluminous, it may be necessary to change the initial requirements (to ensure their compatibility with reality). All changes are documented in Confluence / JIRA and the task estimates are adjusted accordingly.
Acceptance "features" is carried out in several stages:
1. The developer says “ Done! You can see the assembly number XX »
2. The tester drives the new functionality according to the compiled test scenarios and gets bugs.
3. The analyst looks at the implemented “feature” from the point of view of user scenarios (in fact, this is a formal step, since the same was already done during the demonstrations).
4. "Feature" is given to other departments for internal testing:
First of all (after QA) we test all our products on our “production systems”. Our valiant adminshave the opportunity to be the first to taste all the horrors of the delights of the new versions and report on the problems found.
Only after all the previous stages the product is considered worthy to be seen by our end users.
A public release of a product in itself is a separate process with many subtleties - this is a big topic worthy of a separate article.
Summing up the above:
A. Think carefully about your ideas and arrange them correctly (at least adhere to one agreed standard)
B. Communicate with programmers and testers throughout the development time.
B. Conduct intermediate demonstrations without waiting for the end of the period allocated for product development.
G. DrinkIrish Coffee
If you use a similar methodology in product development, tell us how you could improve, accelerate, optimize the process in the comments.
KDPV (this picture of relevance will probably never lose):
')
Disclaimer: all of the following description of the processes is based on the personal experience of the author, obtained in a particular company, and may not have anything to do with the objective reality of the reader. Information on each development stage is submitted in a compressed form and is intended to reveal only the main points of the process within a single article.
Stages
In the beginning was the word ...
For myself, I highlight 3 stages of the emergence of new functionality (aka "features"):
1. There is an idea described in general terms.
For example: “Add email notification support to the program”.
2. The idea is worked out from the user's point of view, that is, usage scenarios are written.
For example: “Upon completion of certain operations in the program, an e-mail will be sent to the address specified by the user through a predetermined SMTP server”.
3. The idea is explained to the developers / testers and the implementation begins directly.
Accordingly, in order to reach the 3rd stage, the analyst needs to thoroughly study the subject area and first of all understand for himself how “it” will work from the user's point of view, including (to a lesser extent) from the development point of view. Lack of elaboration of requirements at the first stage can lead to the fact that the implemented functionality will not work at all as expected by the analyst, but only as the developer understood it (which, unfortunately, happens quite often in the modern world).
Even such a seemingly simple "feature" without proper study can be corrupted if details are not properly worked out, such as:
- Should multiple target email addresses be supported?
- Do I need to support SSL / TLS encryption?
- As a result of what specific operations should emails be sent?
- Do I need to send notifications on a schedule?
- What kind of text should be in the notifications?
- Do I need templates when setting the subject of the letter?
- Does the operation log in notifications? If so, then as text or as an attached text file?
- Etc. etc.
Nevertheless, it does not matter how much time was spent on the initial elaboration of requirements, almost always unaccounted usage scenarios emerge, especially if the new functionality is quite voluminous. This is what the discussion of “features” with developers and testers who look at new opportunities from a completely different angle and can come up with scenarios that a simple user would never think of would be necessary. This process is described in more detail in the next section of the article.
Below is an example of the importance of knowing your own product when designing a new "feature" from real life. I warn you that there will be a lot of letters and specific terms. Who is not afraid - can look at the spoiler:
Example
In our Acronis Backup product, there is such a thing as a backup plan (in the common "backup plan"). The backup plan, in turn, consists of several activities (called “tasks”), which are responsible for the different stages of the implementation of the plan. So, the backup itself is performed in a backup type (1 cache for each machine included in the plan), and additional activities like copying backups to additional storage (aka “staging”) or clearing the storage from old copies in tasks like replication and cleanup, respectively.
At one time, the “Replication / cleanup inactivity time” option was added, which, according to the idea, should limit the period during which the created backups can be copied, that is, limit the activity period of the replication / cleanup task (for example, allow this operation only from 1 to 3 nights so as not to load the network during working hours).
It turned out that the behavior of this option is different from the users' expectations when the backup task does not have time to complete BEFORE the time specified in the settings of the “Replication / cleanup inactivity time” option. Instead of waiting for the end of the backup task and not allowing the replication task to start, the program slows down the backup itself and waits for the end of the “inactivity” period.
Why did this happen? The problem option turned out to be “screwed” not to a separate activity of the “replication” type, but to the entire backup of the entire plan, which gave rise to this behavior.
This problem could have been avoided if a condition had been initially set (taking into account knowledge of the structure of backups) that this option should apply only to replication activity and not affect other activities. Accordingly, for setting such a condition, it is necessary for the analyst to know the structure of the backup plan, that is, he needs to know not only what behavior is expected by the user, but also to imagine where you can screw up when implementing the functional.
At one time, the “Replication / cleanup inactivity time” option was added, which, according to the idea, should limit the period during which the created backups can be copied, that is, limit the activity period of the replication / cleanup task (for example, allow this operation only from 1 to 3 nights so as not to load the network during working hours).
It turned out that the behavior of this option is different from the users' expectations when the backup task does not have time to complete BEFORE the time specified in the settings of the “Replication / cleanup inactivity time” option. Instead of waiting for the end of the backup task and not allowing the replication task to start, the program slows down the backup itself and waits for the end of the “inactivity” period.
Why did this happen? The problem option turned out to be “screwed” not to a separate activity of the “replication” type, but to the entire backup of the entire plan, which gave rise to this behavior.
This problem could have been avoided if a condition had been initially set (taking into account knowledge of the structure of backups) that this option should apply only to replication activity and not affect other activities. Accordingly, for setting such a condition, it is necessary for the analyst to know the structure of the backup plan, that is, he needs to know not only what behavior is expected by the user, but also to imagine where you can screw up when implementing the functional.
Discussion
After the initial description (stage 2) has been compiled by the analyst, this text is read and analyzed by at least two people: the developer (who will implement it) and the tester (who will compose the test scripts).
The discussion in our case is carried out “on the sofas”: the analyst and the tester and / or the developer sit down at a cup of
Hint
Some very clever testers record these conversations on a dictaphone to create an evidence base in situations like:
- Why is it not tested?
- And you said that this scenario was not valid and can be deleted!
- When did I say that ?!
- Here you are, audio recording. We have all the moves recorded.
- Why is it not tested?
- And you said that this scenario was not valid and can be deleted!
- When did I say that ?!
- Here you are, audio recording. We have all the moves recorded.
Registration and maintenance
At home, we use JIRA to track all activities (bugs, QA tasks, tickets from tech support, etc.), statistics, metrics. Confluence is used to describe processes, internal documentation, description of functional requirements, etc.
The JIRA <-> Confluence bundle was chosen for its great flexibility in building links between the elements of these two systems. For example, in Confluence, you can build a table using predefined filters from JIRA, build beautiful graphs, and track the status of several JIRA projects on one page. In addition, the built-in text editor Confluence is much more flexible than its counterpart in JIRA and is therefore better suited to describe the functionality.
There are no hard and fast rules in the description of the new functional in Confluence, but there are templates that are recommended to be followed. Here is an example of our template:
Header, JIRA ticketing, and main objectives:
Information on marketing and instructions for registration requirements:
Link to tickets in which the user interface is drawn (“mocaps”), usage scenarios, functional and non-functional requirements:
Registration consists of the following steps:
1. A “Epic” ticket is launched in JIRA with a brief description of the required functionality.
2. It is decided which version / update this feature will be implemented in.
3. A page is launched in Confluence according to a template (example above) and is filled in by an analyst with a list of various free-form scenarios.
4. The page in Confluence is shown to testers (QA) and developers to study and write test scenarios.
5. JIRA creates tickets of the “dev task” type associated with the source “Epic” and estimates are made.
Next, the development is carried out directly, at the end of which the functionality is transferred to testers in order to “drive out” it according to previously created scripts.
At the same time, between steps 1 and 2, it can take considerable time, given that there is a lot of new functionality and, first of all, it is necessary to implement “features” with the highest priority depending on the current goals of the company.
Development
In our case, the development is divided into many iterations (sprints) with a length of 2-4 weeks, after which a demonstration is made. The main purpose of the demonstrations is to make sure that the developed functionality corresponds to the initial idea and there are no additional risks. That is, we adhere to (we try, in any case) the principles of agile development .
Our developers were skeptical at first, considering it to be a waste of time, but, as practice has shown, it’s during the demonstrations that additional ideas arise, lost scenarios come to light and you can synchronize the vision of all participants in the process (analysts, testers, developers and bosses) .
In the development process, especially if the functionality is voluminous, it may be necessary to change the initial requirements (to ensure their compatibility with reality). All changes are documented in Confluence / JIRA and the task estimates are adjusted accordingly.
Hint
The general rule we follow is: " No entry in JIRA = no work completed ." In other words, any development activity should be reflected in JIRA. To some, this may seem like an unnecessary formalization of processes, but the transition to this rule has helped us reduce the entropy of the universe of documentation and the chaos accompanied by written code.
Release
Acceptance "features" is carried out in several stages:
1. The developer says “ Done! You can see the assembly number XX »
2. The tester drives the new functionality according to the compiled test scenarios and gets bugs.
3. The analyst looks at the implemented “feature” from the point of view of user scenarios (in fact, this is a formal step, since the same was already done during the demonstrations).
4. "Feature" is given to other departments for internal testing:
First of all (after QA) we test all our products on our “production systems”. Our valiant admins
Only after all the previous stages the product is considered worthy to be seen by our end users.
A public release of a product in itself is a separate process with many subtleties - this is a big topic worthy of a separate article.
Conclusion
Summing up the above:
A. Think carefully about your ideas and arrange them correctly (at least adhere to one agreed standard)
B. Communicate with programmers and testers throughout the development time.
B. Conduct intermediate demonstrations without waiting for the end of the period allocated for product development.
G. Drink
If you use a similar methodology in product development, tell us how you could improve, accelerate, optimize the process in the comments.
Source: https://habr.com/ru/post/250145/
All Articles