How our code works. Single project server architecture
 It so happened that by the age of thirty I changed jobs only once and did not have the opportunity to learn from my own experience how different companies set up web projects designed for high response speed and a large number of users. <irony> So, dear habrauser, caught in my field of view offline, saw me, run better, until I started to bother you with questions about error handling, logging and updating process on working servers </ irony> . I am interested not in the set of technologies used, but on the principles on which the code base is built. How the code is divided into classes, how classes are divided into layers, how business logic interacts with the infrastructure, what are the criteria by which the quality of the code is assessed and how the process of developing new functionality is organized. Unfortunately, it is not easy to find such information, at best, everything is limited to listing the technologies and a brief description of the developed bicycles, but you want, of course, a more detailed picture. In this topic, I will try to describe in as much detail as possible how the code works in the company where I work.
It so happened that by the age of thirty I changed jobs only once and did not have the opportunity to learn from my own experience how different companies set up web projects designed for high response speed and a large number of users. <irony> So, dear habrauser, caught in my field of view offline, saw me, run better, until I started to bother you with questions about error handling, logging and updating process on working servers </ irony> . I am interested not in the set of technologies used, but on the principles on which the code base is built. How the code is divided into classes, how classes are divided into layers, how business logic interacts with the infrastructure, what are the criteria by which the quality of the code is assessed and how the process of developing new functionality is organized. Unfortunately, it is not easy to find such information, at best, everything is limited to listing the technologies and a brief description of the developed bicycles, but you want, of course, a more detailed picture. In this topic, I will try to describe in as much detail as possible how the code works in the company where I work.I apologize in advance if my tone seems to someone to be a mentor - I have no ambitions to train anyone, the maximum that this post claims is a story about the architecture of the server part of one real project. In my not very developed city in terms of software development, I have not once or twice met developers who were very interested in our experience in building server-side web applications, so guys, I write this post largely because of you, and I sincerely hope that I will be able to satisfy your interest.
Like any other hired developer, I am not the owner of the code and cannot demonstrate the working draft listings, but telling about how the code base is organized without listings will still be wrong, too. Therefore, I have no choice but to “invent” an abstract product and, by its example, go through the entire process of developing the server side: from getting TK programmers to implementing storage services, using the practices adopted in our team and drawing parallels with how our real project.
MoneyFlow. Formulation of the problem
A virtual customer wants to create a cloud system to account for the expenditure of funds from the family budget. He already came up with a name for it - MoneyFlow and drew UI mockups. He wants the system to have web, android and iOS versions, and the application has a high (<200 ms) response speed for any user actions. The customer is going to invest serious funds in the promotion of the service and promises an avalanche-like growth of users immediately after launch.
')
Software development is an iterative process, and the number of iterations during development mainly depends on how accurately the task was set initially. In this sense, our team was lucky, we have two wonderful analysts and a no less remarkable designer-designer (yes, there is such luck too), so by the beginning of work we usually have the final version of the TOR and a ready-made layout, which greatly simplifies life and frees us, developers, from headaches and the development of extrasensory skills to read the thoughts of the customer at a distance. The virtual customer in my face also did not let us down and provided UI mockups as a description of his vision of the service. I apologize in advance to the experts in building UI, pixel-perfectionists and just people with a developed sense of beauty for the eerie graphics of the layouts and their no less awful usability. My only (albeit weak) excuse is just the fact that this is more a prototype than a real project, but I still hide these layouts under the cat.
The idea of the service is simple - the user enters expenses into the system, on the basis of which reports are built in the form of pie charts.
Layout 1. Add expense
Layout 2. Sample Report
Categories of expenses and types of reports are predetermined by the customer and the same for all users. The web version of the application will be a SPA written in Angular JS, and the server API on ASP.NET, from which the JS application receives data in JSON format. We will build the service on the same technology stack on which our real application is built. This stack looks something like this.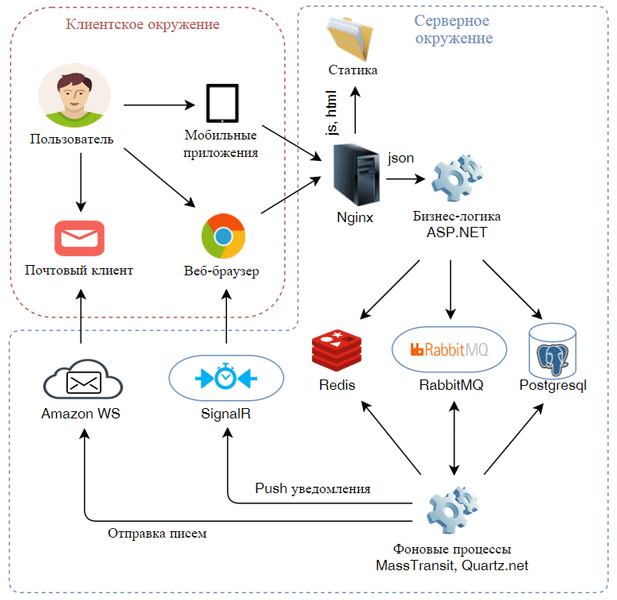
The contract of interaction between the client and server parts of the application
In our team, the development of new functional server and client parts of the service is conducted in parallel. After getting acquainted with the TZ, we first determine the interface by which the front-end interaction with the backend is built. It so happened that our API is built as RPC, not REST, and when we define it (API) we are primarily guided by the principle of the necessity and sufficiency of the transmitted data. Let's try on the layouts to estimate what information the client application may need from the server side.
Layout 3. List of operations
In the layout of the list we have only three columns - the amount, description and the day when the operation was performed. In addition, the client application to display the list will require the category to which the expense operation relates, and Id, so that you can click on the list to go to the editing screen.
An example of the result of calling the server method for a page with a list of committed expense transactions.
[ { "id":"fe9a2da8-96df-4171-a5c4-f4b00d0855d5", "sum":540.0, "details":" ", "date":"2015-01-25T00:00:00+05:00", "category":”Transport” }, { "id":"a8a1e175-b7be-4c34-9544-5a25ed750f85", "sum":500.0, "details":" ", "date":"2015-01-25T00:00:00+05:00", "category":”Entertainment” } ] Now look at the layout of the edit page.
Layout 4. Edit Screen
To display the edit page, the client application will need a method that returns the next JSON string.
{ "id":"23ed4bf4-375d-43b2-a0a7-cc06114c2a18", "sum":500.0, "details":" ", "date":"2015-01-25T00:00:00+05:00", "category":”Entertainment”, "history":[ { "text":" ", "created":"2015-01-25T16:06:27.318389Z" }, { "text":" ", "created":"2015-01-25T16:06:27.318389Z" } ] } Compared to the operation model requested in the list, information on the record creation / modification history was added to the model on the edit page. As I already wrote, we are guided by the principle of necessity and sufficiency and do not create a single common data model for each entity that could be used in the API in each method associated with it. Yes, in the MoneyFlow application, there is a difference in the models of the list and the edit page in just one field, but in reality such simple models are only in books, like “How to learn to program in C ++ at expert level,” with an unkindly smiling plump peasant in a sweater on the cover. Real projects are much more complicated, the difference in the model for the editing screen as compared with the model requested in the list in a real project can reach two-digit fields and if we try to use the same model everywhere, we will unnecessarily increase the list generation time and waste we will load our servers.
JSON objects returned by the server are of course serialized DTO objects, so in the server code we will have classes that define the models for each method from the API. In accordance with the principle of DRY, these classes, if possible, are built into a hierarchy.
Classes defining the MoneyFlow API contract for list screens, creating and editing operations.
// public class ChargeOpForAdding { public double Sum { get; set; } public string Details { get; set; } public ECategory Category { get; set; } } // public class ChargeOpForList : ChargeOpForAdding { public Guid Id { get; set; } public DateTime Date { get; set; } } // public class ChargeOpForEditing : ChargeOpForList { public List<HistoryMessage> History { get; set; } } After the contract is determined, the front-end developers involved create mocks for non-existent server methods and go on to create Angular JS magic. Yes, we have a very fat and very wonderful client, to whom respected iKbaht habrayusers , Houston and some more equally remarkable habra-anonymous authors have put their hand. And it would be completely ugly on the part of server developers, if our beautiful, powerful JS application worked on a slow API. Therefore, on the back end, we try to develop our API as fast as possible, doing most of the work asynchronously and building the data storage model as readable as possible.
We break the system into modules
If we consider the application MoneyFlow from the point of view of functionality, we can distinguish two different modules in it - this is a module for working with expenses and a reporting module. If we were confident that the number of users of our application would be small, we would build a reporting module directly on top of the cost entry module. In this case, we would have, for example, a stored procedure that would build for the user a report for the year directly on the basis of the expenses paid. This scheme is very convenient from the point of view of data consistency, but, unfortunately, it also has a drawback. With a sufficiently large number of users, the table with the cost data will become too large for our stored procedure to work out quickly, counting on the fly, for example, how much money was spent by the user on transport for the year. Therefore, so that the user does not have to wait for the report for a long time, we will have to generate reports in advance, updating their content as new data appears in the cost accounting system.
Software development is an iterative process. If we consider the scheme with a single data model for expenses and reports as the first iteration, then the delivery of reports into a separate denormalized database is already iteration number two. If we further theorize, then we can completely grope for the following improvements. For example, how often do we have to update reports for the last month or year? Probably, in early January, users will enter information about purchases made at the end of December into the system, but most of the data coming into the system will relate to the current calendar month. The same is true for reporting, users are much more likely to be interested in reports for the current month. Therefore, in the third iteration, if the effect of using a separate repository for reports will be offset by an increase in the number of users, you can optimize the storage system by transferring data for the current period to a faster repository located, for example, on a separate server. Or using a repository like Redis, which stores its data in RAM. If we draw an analogy with our real project, then we are at iteration 2.5. Faced with a drop in performance, we optimized our storage system by transferring the data of each module to independent databases, and we also transferred some of the frequently used data to Redis.
According to the legend, the MoneyFlow project is only preparing to launch, so we will keep it at iteration number two, leaving room for future improvements.
Synchronous and asynchronous execution stacks
In addition to increasing productivity by storing data in the most readable form, we try to produce most of the work seamlessly for the user in the asynchronous execution stack. Every time a request comes to us from the client application, we look at what part of the work needs to be done before the answer is returned to the client. Very often we return the answer almost immediately, having performed only the necessary part, like checking the validity of the incoming data, shifting most of the work to asynchronous processing. It works as follows.

In the team we call the asynchronous stack of execution background processes that are busy processing messages coming from the server queues. I will describe the device of our background handler in detail below, but for now let's see an example of interaction between the client application and server API when clicking on the “Add” button from layout 1. For those who are too lazy to scroll - clicking on this button adds a new expense “Going to the movies ”: 500r to the system.
What actions need to be performed each time a new expense is entered into the system?
- Check the validity of the input data
- Add information about the transaction to the cost accounting module
- Update the corresponding report in the reporting module
Which of these actions should we manage to do before we report to the client about the successful processing of the operation? Exactly that we have to make sure that the data transmitted by the client application is correct, and return an error to it if this is not the case. We can also quite add a new entry to the cost accounting module (although we can also transfer this to the background process), but it will be completely unnecessary to update reports synchronously, forcing the user to wait for each report, and there may be several, to be updated.
Now the code itself. For each request that came from the client side, we create an object responsible for its correct processing. The object processing the request for the creation of a new expenditure transaction would look like this with us.
//, // public class ChargeOpsCreator { private readonly IChargeOpsStorage _chargeOpsStorage; private readonly ICategoryStorage _categoryStorage; private readonly IServiceBusPublisher _serviceBusPublisher; public ChargeOpsCreator(IChargeOpsStorage chargeOpsStorage, ICategoryStorage categoryStorage, IServiceBusPublisher pub) { _chargeOpsStorage = chargeOpsStorage; _categoryStorage = categoryStorage; _serviceBusPublisher = pub; } public Guid Create(ChargeOpForAdding op, Guid userId) { // CheckingData(op); // // var id = Guid.NewGuid(); _chargeOpsStorage.CreateChargeOp(op); // _serviceBusPublisher.Publish(new ChargeOpCreated() {Date = DateTime.UtcNow, ChargeOp = op, UserId = userId}); return id; } // private void CheckingData(ChargeOpForAdding op) { // if (op.Sum <= 0) throw new DataValidationException(" "); // if (!_categoryStorage.CategoryExists(op.Category)) throw new DataValidationException(" "); } } The ChargeOpsCreator object checked the validity of the input data and added the completed operation to the cost accounting module, after which the Id of the created record was returned to the client application. The process of updating reports is performed in the background process; for this, we sent the message ChargeOpCreated to the queue server, the processor of which will update the report for the user. Messages sent to the service bus are simple DTO objects. This is what the ChargeOpCreated class looks like, which we have just sent to the service bus.
public class ChargeOpCreated { // public DateTime Date { get; set; } //, public ChargeOpForAdding ChargeOp{ get; set; } //, public Guid UserId { get; set; } } Splitting an application into layers
Both the execution stack (synchronous and asynchronous) at the assembly level are divided into three layers - the application layer (execution context), the business logic layer and data storage services. Each layer is strictly defined area of responsibility.
Synchronous stack. Application layer
In a synchronous stack, the execution context is an ASP.NET application. His zone of responsibility, besides the usual for any web server actions like receiving requests and serializing / deserializing data, we have small. It:
- user authentication
- Instance of business logic objects using IoC container
- error handling and logging
All the code in the controllers is reduced to creating with the help of IoC a container of business logic objects responsible for further processing of requests. This is what the controller method will look like, called to add a new expense in the MoneyFlow application.
public Guid Add([FromBody]ChargeOpForAdding op) { return Container.Resolve<ChargeOpsCreator>().Create(op, CurrentUserId); } The application layer in our system is very simple and lightweight; in a day we can change the execution context of our system from ASP.NET MVC (as we have historically) to ASP.NET WebAPI or Katana.
Synchronous stack. Business logic layer
The business logic layer in the synchronous stack consists of many small objects that process incoming user requests. The ChargeOpsCreator class, listed above, is just an example of such an object. The creation of such classes will dock well with the principle of sole responsibility, and each such class can be fully tested with unit tests due to the fact that all its dependencies are injected into the constructor.
The tasks of the business logic layer in our application include:
- validation of incoming data
- user authorization (checking the user's rights to perform an action)
- interaction with the data storage layer
- generating DTO messages to send to the client application
- sending messages to the queue server for further asynchronous processing
It is important that we check the input data for correctness only in the business logic layer of the synchronous stack. All other modules (queue disassemblers, storage services) are considered “demilitarized” from the point of view of inspections by the zone, with very few exceptions.
In a real project, the objects of the business logic layer are separated from the controllers, where they are instantiated, by interfaces. But this office did not bring us any particular practical benefits, but only complicated the IoC section of the container in the configuration file.
Asynchronous stack
In an asynchronous stack, an application is a service that parses messages arriving at the server of queues. By itself, the service does not know which queues it should connect to, what types of messages and how it should process, and how many threads it can allocate for processing messages of a particular queue. All this information is contained in the configuration file loaded by the service at startup.
Example config service (pseudocode).
< = “ReportBuilder” = “10”> <_> <=“ChargeOpCreatedHandler” __=”2” __=”200” _=”CriticalError” … /> </_> </> /* 5 */ < = “MailSender” = “5”> ... At start, the service reads the configuration file, checks that there is a queue on the message server called ReportBuilder (if not, creates it), checks for the existence of a routing sending messages like ChargeOpCreated to this queue (if not, sets up routing itself), and starts processing messages that fall into the ReportBuilder queue by running the appropriate handlers for them. In our case, this is the only ChargeOpCreatedHandler type handler (about the objects handlers just below). Also, the service will understand from the configuration file that it can allocate up to 10 streams for parsing the “ReportBuilder” queue messages, that if an error occurs in the operation of the ChargeOpCreatedHandler object, the message should return to the queue with a 200ms timeout, and when the handler re-drops, the message should go to a log with the note “CriticalError” and some more similar parameters. This gives us a wonderful opportunity “on the fly”, without making changes to the code, to scale the queue disassemblers, launching additional services on backup servers in case of accumulation of messages in any queue, telling it in the config file what kind of queue it should parse, which is very , very comfortably.
The queuing service is a wrapper over the MassTransit library ( the project itself , an article in Habré ) that implements the DataBus pattern over the RabbitMQ queue server. But a programmer who writes in the business logic layer does not need to know anything about this, the entire infrastructure he touches (queue server, storage key / value, DBMS, etc.) is hidden from him by a layer of abstraction. Probably, many have seen the post “How two programmers baked bread” about Boris and Marcus, using diametrically opposite approaches to writing code. Both of us would have approached: Markus would develop business logic and a layer working with data, while Boris would work with us on infrastructure, the development of which we try to maintain at a high level of abstraction (sometimes it seems to me that even Boris would approve our code) . When developing business logic, we are not trying to build objects into a long hierarchy, creating a large number of interfaces, we rather try to comply with the KISS principle, leaving our code as simple as possible. So, for example, in MoneyFlow, the ChargeOpCreated message handler will look like, which we have already carefully specified in the configuration of the ReportBuilder service, which deals with the analysis of the Queue.
public class ChargeOpCreatedHandler:MessageHandler<ChargeOpCreated> { private readonly IReportsStorage _reportsStorage; public ChargeOpCreatedHandler(IReportsStorage reportsStorage) { _reportsStorage = reportsStorage; } public override void HandleMessage(ChargeOpCreated message) { // _reportsStorage.UpdateMonthReport(userId, message.ChargeOp.Category, message.Date.Year, message.Date.Month, message.ChargeOp.Sum); } } All handler objects are descendants of the MessageHandler abstract class, where T is the type of the message to be parsed, with the only abstract method HandleMessage overloaded in the heirs.
public abstract class MessageHandler<T> : where T : class { public abstract void HandleMessage(T message); } After receiving the message from the queue server, the service creates the required handler object using the IoC container and calls the HandleMessage method, passing the received message as a parameter. To leave the opportunity to test the behavior of the handler in isolation from its dependencies, all external dependencies, while with ChargeOpCreatedHandler it is only a report storage service, are injected into the designer.
As I already wrote, we do not check the correctness of the input data in the processing of messages - the business logic of the synchronous stack should deal with this and do not handle errors - it is the responsibility of the service in which the handler was running.
Error handling in the asynchronous execution stack
The reporting module is more suitable for the definition of consistency in the end ( eventual consistency ) than for the definition of strong consistency , but it still guarantees the ultimate consistency of data in the reporting module for any possible system failures. Imagine that a server with a database that stores reports fell. It is clear that in the case of binary clustering, when each database instance is duplicated on a separate server, a similar situation is practically excluded, but still imagine that this happened. Customers continue to make their own expenses, messages about them appear in the queue server, but the parser responsible for updating the reports cannot access the database server and crashes. According to the service configuration above, after dropping the ChargeOpCreated message, the same message will be returned to the queue server after 200 ms, after the second attempt (also unsuccessful) the message will be serialized and stored in a special storage of dropped messages, which in our project is combined with logs. , , ( ), . - . , . , “”, , , , .
We have a shared storage layer for asynron and synchronous execution stacks. For a business logic developer, a storage service is simply an interface with methods for retrieving and modifying data. Under the interface is a service that completely encapsulates access to the data of a specific module. When designing service interfaces, we try, if possible, to follow the concept of CQRS - each method we have is either a command that performs some action or a request that returns data in the form of DTO objects, but not at the same time. We do this not to partition the storage system into two independent structures for reading and writing, but rather for order.
No matter how much we reduce the response time, doing most of the work asynchronously, an unsuccessfully designed storage system can erase all the work done. I did not accidentally leave a description of how the storage layer in our project is arranged at the very end. We made it a rule to develop storage services only after the implementation of the business logic layer objects has been completed, so that when designing the database tables, we will understand exactly how the data from these tables will be used. If during development of business logic we need to get some information from the storage layer, we add a new method to the interface that hides the service implementation, a new method that provides data in a form convenient for business logic. Our business logic defines the storage interface, but not vice versa.
Here is an example of a report storage service interface that was defined during the development of the business logic of the MoneyFlow application.
public interface IReportsStorage { // . json string GetMonthReport (Guid userId, int month, int year); // void UpdateMonthReport(Guid userId, ECategory category, int year, int month, double sum); } For data storage, we use the Postgresql relational database. But this of course does not mean that we store the data in a relational form. We lay the possibility of scaling by sharding and design tables and queries to them according to the sharding-specific canons: we do not use join-s, we construct queries on primary keys, etc. When building a MoneyFlow report repository, we also leave the possibility to transfer part of the reports to another server, if it is suddenly needed later, without rebuilding the table structure. How do we do sharding - using the built-in mechanism for the physical separation of tables ( partitioning) or by adding a shard manager to the storage service of the reports - we will decide when the need arises. In the meantime, we should concentrate on designing the structure of the table, which would subsequently not hinder sharding.
Postgresql has wonderful NoSQL data types, such as json and less well-known, but no less remarkable hstore.. The report that is needed by the client application must be a json string. Therefore, it would be logical for us to use the built-in json type for storing reports and give it to the client as is, without spending resources on the DB Tables-> DTO-> json serialization chain. But in order to repost hstore again, I will do the same with the only difference that inside the database the report will be in the form of an associative array, which hstore is intended to store.
To store the reports we will need one table with four fields:
| Field | Which means |
| id | user ID |
| year | reporting year |
| month | the reporting month |
| report | hash table with report data |
The primary key of the table will be composite in the fields id year month. We will use expenditure categories as keys of the associative array report, and the amount spent on the corresponding category as values.
Sample database report.

On this line it is clear that the user with id “d717b8e4-1f0f-4094-bceb-d8a8bbd6a673” spent 500r on transport in January 2015 and 2500r on entertainment.
GetMonthReport() , json postgresql, UpdateMonthReport() . -, , , . -, (race condition) — / . , hstore, UpSert, . 99% , , . , , - , . , AddReport(), GetReport(), UpdateReport() . -. , - , , : , , .
Report Store Service Code.
// public class ReportStorage : IReportsStorage { private readonly IDbMapper _dbMapper; private readonly IDistributedLockFactory _lockFactory; public ReportStorage(IDbMapper dbMapper, IDistributedLockFactory lockFactory) { _dbMapper = dbMapper; _lockFactory = lockFactory; } // json public string GetMonthReport(Guid userId, int month, int year) { var report = _dbMapper.ExecuteScalarOrDefault<string>("select hstore_to_json(report) from reps where id = :userId and year = :year and month = :month", new QueryParameter("userId", userId), new QueryParameter("year", year), new QueryParameter("month", month)); // - json if (string.IsNullOrEmpty(report)) return "{}"; return report; } // public void UpdateMonthReport(Guid userId, ECategory category, int year, int month, double sum) { // using (_lockFactory.AcquireLock(BuildLockKey(userId, year, month) , TimeSpan.FromSeconds(10))) { // RaceUnsafeMonthReportUpsert(userId, category.ToString().ToLower(), year, month, sum); } } // upsert private void RaceUnsafeMonthReportUpsert(Guid userId, string category, int year, int month, double sum) { // : null - , - , double? sumForCategory = _dbMapper.ExecuteScalarOrDefault<double?>("select Coalesce((report->:category)::real, 0) from reps where id = :userId and year = :year and month = :month", new QueryParameter("category", category), new QueryParameter("userId", userId), new QueryParameter("year", year), new QueryParameter("month", month)); // - , if (!sumForCategory.HasValue) { _dbMapper.ExecuteNonQuery("insert into reps values(:userId, :year, :month, :categorySum::hstore)", new QueryParameter("userId", userId), new QueryParameter("year", year), new QueryParameter("month", month), new QueryParameter("categorySum", BuildHstore(category, sum))); return; } // , _dbMapper.ExecuteNonQuery("update reps set report = (report || :categorySum::hstore) where id = :userId and year = :year and month = :month", new QueryParameter("userId", userId), new QueryParameter("year", year), new QueryParameter("month", month), new QueryParameter("categorySum", BuildHstore(category, sumForCategory.Value + sum))); } // - ( :) hstore private string BuildHstore(string category, double sum) { var sb = new StringBuilder(); sb.Append(category); sb.Append("=>\""); sb.Append(sum.ToString("0.00", CultureInfo.InvariantCulture)); sb.Append("\""); return sb.ToString(); } // private string BuildLockKey(Guid userId, int year, int month) { var sb = new StringBuilder(); sb.Append(userId); sb.Append("_"); sb.Append(year); sb.Append("_"); sb.Append(month); return sb.ToString(); } } In the ReportStorage service constructor, we have two dependencies — IDbMapper and IDistributedLockFactory. IDbMapper is a facade above the lightweight ORM framework BLToolkit.
public interface IDbMapper { List<T> ExecuteList<T>(string query, params QueryParameter[] list) where T : class; List<T> ExecuteScalarList<T>(string query, params QueryParameter[] list); T ExecuteObject<T>(string query, params QueryParameter[] list) where T : class; T ExecuteObjectOrNull<T>(string query, params QueryParameter[] list) where T : class; T ExecuteScalar<T>(string query, params QueryParameter[] list) ; T ExecuteScalarOrDefault<T>(string query, params QueryParameter[] list); int ExecuteNonQuery(string query, params QueryParameter[] list); Dictionary<TKey, TValue> ExecuteScalarDictionary<TKey, TValue>(string query, params QueryParameter[] list); } NHibernate - ORM, DTO , BLToolkit .
IDistributedLockFactory — , ServiceStack RedisLocks .
, : — “ ” -, , , - .
“”
There is a certain amount of cunning in the words that we have divided the reporting system of the MoneyFlow application into a separate, independent module. Yes, we store the report data separately from the accounting system data, but in our application, business logic and parts of the infrastructure, such as a service bus or, for example, a web server, are shared resources for all application modules. For our small company, in which for recounting programmers, the fingers of one hand of the milling-machine operator are enough, this approach is more than justified. In large companies, where work on different modules can be carried out by different teams, it is customary to take care of minimizing the use of common resources and the lack of single points of failure. So, if the MoneyFlow application were developed in a large company, its architecture would be a classic SOA.

The refusal of the idea to make a system based on completely independent modules, communicating with each other on the basis of one simple protocol, was not easy for us. Initially, when designing, we planned to make a real SOA solution, but at the last moment, after weighing all the pros and cons within our compact (not in the closed and limited sense, but simply very small), the teams decided to use the “mixed” concept of module division: common infrastructure and business logic are independent storage services. Now I understand that this decision was right. We were able to direct time and effort not spent on complete duplication of the infrastructure of the modules to improve other aspects of the application.
Instead of conclusion
. , , - -, , API. , . API , .
Source: https://habr.com/ru/post/249453/
All Articles