The synapse ensemble is a structural unit of the neural network

Last May, Google’s deep-learning laboratory staff and scientists from two American universities published the study Intriguing properties of neural networks . The article about him was freely retold here on Habré , and the study itself was also criticized by a specialist from ABBYY .
As a result of their research, Google researchers became disillusioned with the ability of neurons in the network to disentangle attributes of the input data and began to think that neural networks did not unravel the semantically significant features by individual structural elements, but stored them throughout the network as a whole as in a hologram. In the lower part of the illustration to this article in black and white, I led the activation cards of the 29th, 31st and 33rd neurons of the network I taught to draw the picture. The fact that the carcass of a bird without a head and wings, depicted for example by the 29th neuron, will seem to people to be a semantically significant feature, Google users consider only the interpretation of the observer as a mistake.
')
In the article I will try to show with a real example that disintegrating signs can be detected in artificial neural networks. I will try to explain why the Google users saw what they saw, and could not see the unraveled signs, and show you where semantically significant signs are hidden on the net. The article is a popular version of the report, read at the conference " Neuroinformatics - 2015 " in January of this year. The science version of the article can be read in the conference materials.
The question is now being actively discussed both among those interested and among professionals. Evidence to withstand criticism has not yet been able to present until any side.
Despite the fact that experimenters with the help of electrodes implanted into the brain in human experiments, were able to detect the so-called “neuron Jennifer Aniston” - a neuron that responds only to the image of the actress. It was possible to catch both Luke Skywalker's neuron and Elizabeth Taylor's neuron. With the discovery of " coordinate neurons ", " neurons of a place " and " neurons of borders " in rats and bats, many finally get used to saying "a neuron of such and such a property". Although the discoverers of the neuron Jennifer Aniston, interpreting the data responsibly, rather say that they have found part of large assemblies of neurons, rather than individual neurons of the signs. Her neuron reacted to concepts related to it (for example, scenes from the series, in which it is not in the frame), and Luke Skywalker's neuron found in humans also worked on Master Yoda. In order to completely confuse everyone in one study , neurons selectively reacting to a snake could be found in monkeys that snakes had never seen in their lives.
In general, the topic of “ Grandmother 's Neuron ”, raised by neurophysiologists in 1967-69, causes considerable excitement to this day.
Part One: Data
Most often, the neural network is used for classification. At the entrance it receives a lot of input noisy images, and at the exit it should successfully classify them by a small number of signs. For example, is there a cat in the picture or not. This typical task is inconvenient for searching the network for meaningful features in the input data for a number of reasons. And the first of them is that there is no possibility to strictly observe the relationship between the semantic feature and the state of some inner element. In the article from Google and several other studies, a clever trick was used - first, the input data were calculated that would maximize the selected neuron, and then the researcher carefully examined these data, trying to find meaning in them. But we know that the human brain can skillfully find meaning even where it is not there. The brain has long evolved in this direction, and the fact that on the Rorschach test, people see something other than ink blots on paper, makes it necessary to be wary of any method of searching for meaning in a picture containing many elements. Including on my pictures.
The method used in this and a number of other studies is also bad because the maximal excitation may not be the normal mode of operation of a neuron. For example, in the middle picture, where the activation map of the 31st neuron is shown, it can be seen that on the correct input data up to the maximum value it is not excited, and generally when looking at the picture it seems that the meaning is more likely to be areas where it is not active . To see something present it may be useful to study the behavior of the network in small neighborhoods from its normal operating mode.
In addition, a very large network was explored in the Google study. Unsupervised learning networks contained up to a billion variable parameters, for example. Even if there is a neuron in the network, it would be very difficult to stumble upon it in large black letters writing out the word “existence”.
Therefore, we will experiment with a completely different task. First, the experimenter makes a picture. The network has only two inputs, and two real numbers are fed to them - the coordinates X and Y. And at three outputs R, G and B we will expect a prediction of what color the point should be in the picture in these coordinates. All values are normalized to the segment (-1; 1). The RMS error for all points of the picture in the amount will be the criterion for the success of learning to draw (in some pictures it is written in the lower left corner, RMSE).
The article uses a non-recurrent network of 37 neurons with hypertangent as a sigmoid and somewhat nonstandard synaptic location. For training, the method of back propagation of error was used, with the Mini-Batch version of the algorithm, and an additional algorithm, which is a distant relative of the energy-limiting algorithms. In general, nothing supernatural. There are more modern algorithms, but most of them are not able to achieve more accurate results on a network of such modest size.
And now fill the image with pixels that are colored the way our network predicts. A map of the neural network's representations of the beautiful will be obtained, used at the beginning of the article as an image to attract attention. On the left is the original picture of a flying peacock, and on the right is how the neural network imagined it.
The first important conclusion can be made from the first glance at the picture. It is not very meaningful to hope that the signs of the image are described by neurons. If only because the picture clearly visible elements of the image is simply more than neurons. That is, the authors of most studies looking for signs in neurons are not looking there.
Part Two: A little bit of reverse engineering
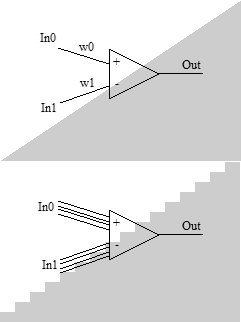 Imagine that we were faced with the task: without any training, construct a classifier from neurons that determines where the input point is located - above or below the straight line passing through the point (0,0). To solve this problem, a single neuron is enough. The weights of synapses correlate as a straight line slope coefficient and have different signs. A sign of potential at the exit will give us the answer.
Imagine that we were faced with the task: without any training, construct a classifier from neurons that determines where the input point is located - above or below the straight line passing through the point (0,0). To solve this problem, a single neuron is enough. The weights of synapses correlate as a straight line slope coefficient and have different signs. A sign of potential at the exit will give us the answer.Now significantly complicate the task. We will compare the two values in the same way, but now the input values will come in the form of a binary number. For example, 4-bit. By the way, not every learning algorithm will cope with such a task. However, the analytical answer is also obvious. We manage all the same one neuron. For the first four synapses, which take the first value, the weights are related as 8: 4: 2: 1, for the second one - the same, but different by -k times. Spreading the solution of this problem into two separate neurons means complicating the solution of the problem, unless the input value converted from the binary code is necessary somewhere else in the other part of the network. And what happens: on the one hand, the neuron is one, but, on the other hand, it reveals two completely separate ensembles of synapses representing the processing of different properties of the input data. Hence the first conclusion:
- For the presentation of properties in the neural network can respond not to neurons, but groups of synapses.
- In one neuron, we often see a combination of several signs.
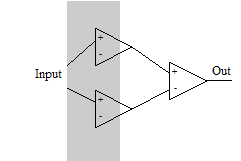 Let's do the third thought experiment. Suppose we have only one input and we need the neuron to be turned on only on one range of values. This task cannot be solved on a single neuron with a monotonic activation function. We need three neurons. The first one will be activated on the first border and activate the output neuron, the second one will be activated at a higher input value and inhibit the output neuron on the second border.
Let's do the third thought experiment. Suppose we have only one input and we need the neuron to be turned on only on one range of values. This task cannot be solved on a single neuron with a monotonic activation function. We need three neurons. The first one will be activated on the first border and activate the output neuron, the second one will be activated at a higher input value and inhibit the output neuron on the second border.This thought experiment teaches us important new findings:
- The ensemble of synapses can capture several neurons.
- If there are several synapses in the system that change a certain boundary with different intensity and at a different moment, the ensemble of synapses, including them both, can be used to control the new “gap between borders” property.
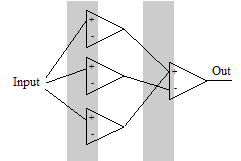 Finally put the last fourth thought experiment.
Finally put the last fourth thought experiment.Suppose we need to include the output neuron in two independent and non-overlapping sections. You can solve the puzzle using 4 neurons. The first neuron is activated and activates the output. The second neuron is activated partially and inhibits the output neuron. At this time, the third is activated, again activating the output neuron. Finally, the second neuron gains maximum activation and, due to the greater weight of its synapse, retards the output neuron again. Then the 1st boundary depends almost completely on the first neuron, and the fourth on the last one in the first layer. However, the position of the second and third frontiers, although it can be changed without affecting other frontiers, but this will have to change the weights of several synapses in concert. This thought experiment taught us a few more principles.
Despite the fact that every synapse in the network of this type affects the processing of the entire signal, only a few of them affect individual properties strongly, ensuring their presentation and modification. The impact of most synapses is significantly less severe. If you try to influence a property by changing such “weak” synapses, then those properties that they are strongly involved in managing will change unacceptably much earlier than you notice any changes in the selected attribute.
- Some synapses are ensembles that can change individual signs. The ensemble works only within the framework of the environment surrounding other neurons and synapses. At the same time, the work of the ensemble is almost independent of small changes in the environment.
These are the ensembles of synapses, characterized by the described properties, we will look in our network to confirm the possibility of their existence with a real example.
Part Three: Synaptic Ensembles
The small size of the network, given by us in the first part of the article, gives us the opportunity to directly study how the change in the weight of each of the synapses affects the picture generated by the network. Let's start with the very first synapse, strictly speaking, number 0. This synapse, in proud solitude, is responsible for tilting the bird carcass to the left side, and for nothing else. No other synapse takes part in the formation of this reference line.

The picture shows a very large change in the weight of the synapse, from -0.8 to +0.3, specifically, so that the change caused is more noticeable. With such a large change in the weight of the synapse, other properties begin to change. In reality, the working range of changes in the weight of a given synapse is much smaller.

Looking at the activation map of the neuron to which this synapse leads, one might think that the second synapse of this neuron will also somehow manage the inclination of the first reference line, around which the whole geometry of our birdie is built, but not. Changes in the weight of the second synapse leads to a change in another property — the width of the bird’s body.

It should be noted here that the effect of closely located synapses on a property can often be interpreted as a separate property. However, this is generally not the case. For example, look at the map of changes caused by the 418th synapse, which is part of an ensemble that controls the balance of green in the picture.

If we try to move the network along the base, consisting of the 0th and 418th synapses, we will see how the bird leans to the left and becomes less green, but it is hardly possible to consider this as one property. In their article, Google researchers argued that the natural basis, which excites as much as possible one structural element of the network, seems to have a semantic significance not worse than the basis assembled from a linear combination of such vectors for several elements. But we see that this is true only when the synapses, along which the greatest change occurs, enter into close synaptic ensembles. But if the synapses regulate very different properties, then mixing does not help in confusing them.

Now consider some more complex property affecting a small part of the picture. For example, the size and shape of the areas under the wings, where our peacock has short tail feathers. We write out all the neurons that directly affect these areas (for example, the left one), namely, they are responsible for changing individual parts of the bird, not its general geometry. It turns out that the ensemble includes synapses 21,22, 23, 24, 25, 26, 27.

For example, the 23rd and 24th synapses increase the area chosen by us, in the opposite way affecting the length of the wing. So, changing them at the same time, you can change the area under the wing, having little effect on the length of the wing. Just as in the fourth thought experiment we proposed.

All these synapses lead to the 6th neuron, and when looking at its activation map, to put it mildly, it is not obvious that it participates in the control of this property. What speaks in favor of the effectiveness of the visualization method proposed in this article.

If we look at which synapses affect the size and shape of this area together with other areas, then another couple of dozen 37-46 (8th neuron), 70-83 (11th and 12th neurons), 90-94 (12 and 13th neurons), 129-138 (16th neuron) and a few more, for example, 178th (19th neuron). In total, about 46 synapses from 460 available on the network are involved in the ensemble. At the same time, the rest of the synapses can bend almost the entire image, but the selected area is almost unaffected, such as the 28th, even if you twitch for it.

So what do we see? An ensemble of synapses regulating the property we have chosen. Its effect on other properties of the network, if necessary, is compensated by coordinated changes in the weights of synapses in the ensemble or by using other ensembles. The synapse ensemble employs at least 7 neurons, this is the fifth part of all neurons in the network and they are also used by many other ensembles.
Similarly, you can consider in detail the synapses affecting the color of the areas, or the shape of the flight feathers. On many other signs present in the image.
Part Four: Analyzing the Results
The network elements that encode semantically meaningful signs may be in the network, but these are not neurons, but ensembles of synapses of different sizes.
Most neurons are involved in multiple ensembles at once. Therefore, studying the activation parameters of an individual neuron, we will see a combination of the influence of these ensembles. On the one hand, this makes it very difficult to determine the role of neurons, and on the other hand, most of the combinations of ensembles will seem to the researcher, if not literally meaningful, then containing obvious signs of meaning.
In the study of Googlelots, which was mentioned at the very beginning, of course, it was not stated directly that the structural units of the network do not encode semantically significant features. Proving non-existence is generally extremely difficult. Instead, they compared data that activated one random neuron and data activating a linear combination of several randomly selected neurons of one layer. They showed that the degree of apparent meaningfulness of such data does not differ and interpreted this as an indication that the individual signs are not coded.
However, now looking at the material of the article, we understand that one neuron, as well as linear combinations of several close neurons, demonstrate the answer to the data of several ensembles of synapses, and indeed, the content of information does not differ fundamentally. That is, the observation made in the study is correct, and it could be expected, only its interpretation given in the most general words was in doubt.
It also becomes clear why different works on the topic of identifying semantically significant features in the structural elements of the network gave so many different results.
In conclusion I want to quite briefly say what I started with. About the activation maps of the latest neurons in the network, so eloquently looking. The neural network can approach the function required from it as a sum of functions that effectively approximate individual segments. But the more data a network successfully learns, the less it can select its structural elements to encode each individual attribute. The more she is forced to seek and apply qualitative generalizations. If you need to implement a simple classification with a billion adjustable parameters, each of them is likely to manage the property only on one small area and only along with hundreds of others. However, if you force the network to learn a picture in which it has a hundred significant properties, and it has only four dozen neurons at its disposal, it either cannot cope or allocates semantically significant features into separate structural units, where they will be easy to detect. The output neurons of the network are connected with a not very large number of neurons, and to form a picture with so many significant elements, the network had to collect the results of the work of several synapse ensembles on the penultimate neurons. Neurons 29, 31 and 33 were lucky, they gathered geometric data that is easy to recognize and we immediately paid attention to them. Neurons 27, 28 or 32 were less fortunate, they gathered information about the location of the color spots in the picture and understand what this cacophony means only the neural network itself can.

Source: https://habr.com/ru/post/249031/
All Articles