Parsing the Microsoft Office localization file format
Have you ever noticed that the AGGREGATE function in Excel for the second set of arguments has an incorrect argument description? In fact, in the second set, the descriptions of the arguments are interspersed from the second and first sets. This bug is accurately reproduced in Excel 2010, 2013. I wondered why this was happening, because Microsoft cannot carelessly treat the interface of one of its main products. The result was a complete parsing of the MS Office localization file format.

After a brief search for descriptions of the function arguments for the contents of the files in the office folder, the file c: \ Program Files \ Microsoft Office \ Office15 \ 1033 \ XLINTL32.DLL was found . Where 1033 is the LCID of the localization language ( for details, see msdn ).

From a quick glance it became clear that, in principle, I found what I was looking for. The argument descriptions for the AGGREGATE function for both variants in the file were correct. It turned out that Excel incorrectly parses its own localization file. Then it was decided to write your Excel localization files parser, or at least to understand the format of the MS Office localization files.
For a start, it was decided to write a parser of only descriptions of arguments and functions, as a quick glance at the file that is presented above gave the impression that the format is quite simple - the exclamation mark between the text serves as an exclamation mark, and you can understand what text means .
As a result, after a slightly thoughtful reading of the file, the following scheme for describing arguments and functions was revealed:
According to this scheme, a parser was quickly written, which coped quite well with its work, but there were several problems:
But in principle, with a large number of dirty hacks, it was possible to pull out descriptions of functions for almost all localizations.
')
It remains to solve the problem of which function belongs to which description. To do this, I again began searching for the contents of files in MS Office folders, only this time I was looking for the names of the functions. And I was lucky: next to the file XLINTL32.DLL with descriptions of functions lay the file XLLEX.DLL, in which there was something similar to the names of the functions:
Only they went all somehow in a row and without gaps. And if for the English language it was still possible to disassemble this text with hands into separate names of functions, then for Arabic or Thai just so I could not do it.
In principle, it became clear that it was time to understand the format of the Excel localization files, or to score on this matter and go to bed. The first was chosen.
At first I noticed that both function descriptions and function names are stored in dll files in a resource with the name "1" and type "234". Thoughtful study of the resource dump from the XLLEX.DLL file (this is the one with the names of the functions) led me to the following discovery: between the sections with normal text there are areas with krakozybrami, which must bear a certain meaning. Then it was decided to study these sites more deeply using WinHEX and a calculator. Take the plot krakozyabrov that go in front of the site with the names of functions:

The first two bytes: 01 00 - I still do not know what they mean. The second two bytes are 56 02 - if you turn them over 0256, and if you also convert them from hex to decimal, you will get 598. Exactly as many function names below in the block of meaningful text. This is already pleased. Look further: the following pairs of bytes, if swapped, are like an increasing sequence. So it is, these bytes are the offset of the description of a separate function from the end of the gib block. In fact, the screenshot from the XLLEX.DLL file shows that the first function is COUNT - 5 bytes (0005h-0000h), the second - IF - 2 bytes (0007h-0005h), the third - ISNA - 4 bytes (000Bh-0007h) .
This is all very well, but how to determine where the block of cracks begins, in which the lengths of the names of the functions are given. Indeed, in each localization, this block has its own offset. Then I began to dig the header of the resource dump from the XLLEX.DLL file.
The first 4 bytes are the size of the resource. Further, I was interested in the bytes that are located at offset 33h 34h - their value - 0256 - exactly the same as the number of function names written in the file. In addition, every 17 bytes is repeated 03h, and the last 4 bytes in the area selected in the screenshot - 0E 6F 00 00 just equal to the number equal to the size of the resource = the size of the selected area + 4 + 4 - 1. That is, in fact, this the size of that part of the file where the data is.
Now you can write out all the bytes that are between duplicate 03h and group them a little:
After a long search of different variants, what these bytes may denote, the following pattern was highlighted:
In principle, this data is already enough to make an automatic parser for the XLLEX.DLL file and pull out the names of all functions in all languages and a lot of other information. But one problem arose in the process: only a very small part of the localizations stored data in UTF-8 format. Most of the data is stored in some completely incomprehensible formats: each character is encoded with 1 byte with some offset relative to the table of this language in UTF-8. For example, Cyrillic "C" and "H" were recorded as A1 and A7, and in the UTF8 table they have the numbers D0A1 and D0A7, but the "p" was written as C0, although it should be D180.
To solve this problem, I first, naturally, tried to understand how Excel itself translates strings from such an incomprehensible encoding at least in UTF-8. To do this, it was necessary to compare the block descriptions for several languages, I took the Russian localization and English:
Begin the description of the block for the English localization:
From this, some conclusions were made: the first two bytes in the block description are encoding. If the first byte = 0, then the text in this block is written in Unicode LE, and everything is simple. If the first byte of the encoding = 01, then you need to look at the second byte. If the second byte = 00, then the text is encoded in a simple UTF-8 encoding; here, too, do not break your head. But what if the second byte is not 0?
At first, I simply compiled a dictionary: the value of the second byte is the offset in the UTF-8 table. It quickly bored me, and I began to look for a pattern. It soon became clear that the offset in the UTF-8 table can be defined as: offset = (byte2-80h) * 4 + C0h. The only problem is that for some groups of codings C0h had to be changed to another number.
As a result, the text conversion functions began to look like this:
After all this, it was possible to precisely and correctly pull out all the localized text from the XLLEX.DLL file, but this method was completely unsuitable for the file with the descriptions of the functions and arguments of XLINTL32.DLL. Here I had to start everything from the very beginning, but it was already easier.
To begin with, in the XLINTL32.DLL file I tried to find something already familiar and similar to the data from the XLLEX.DLL file. The familiar picture began at offset 0459h:

Those. since 04B1h there were block descriptions, the same as in the XLLEX.DLL file, but above this offset everything was somehow incomprehensible. And not all the text from the resource obeyed the rules, which were derived from parsing the XLLEX.DLL file.
It was decided later on those blocks that I have already learned to recognize are called blocks of the second type, and those that I do not know how yet are blocks of the first type, since they went in the XLINTL32.DLL file above the blocks of the second type.
The text of the first type blocks began almost immediately after the end of the second type block map, it remains to find where the first type block map is located in the file, and how to define a text delimiter in the first type blocks. This block was selected for study:

It clearly shows the following lines: “Cut, copy, and paste”, “Print”, “For charts”, etc. In addition, a “characteristic” ladder of zeros and increasing values is visible in hex codes. The first two values in this ladder are 46h and 6Eh - the difference between them in the decimal form is 40, since the text is explicitly set in Unicode LE, then the length “Cut, copy, and paste” will be 20 * 2 = 40. Converges. Check another pair of values: 78h-6Eh = 10/2 = 5 - exactly the length of “Print”. Let's rewrite beautifully all bytes from the 07BE66h offset to the beginning of the meaningful text:
00 46000000
00 6E000000
00 78000000
...
FF E2020000
The total length of the resulting statement is 07BEABh - 07BE66h + 1 = 46h - somewhere it already was. It turns out that the descriptions of the elements in the first type block look like this: 1 byte element type, 4 bytes - the offset of the element relative to the beginning of this block. As it turned out later, the types of elements in the block of the first type are 00h - plain text in Unicode, 0Ah - some strange krakozyabry, FFh - the last element in this block.
Now the last thing remains: deal with the resource header and find out how the offsets are determined for all blocks.
To begin with, I remembered that the description of all blocks of the second type ends at offset 0A67h, and begins at offset 0459h, the total length of the description of blocks of the second type is 0A67h-0459h + 1 = 060Fh, and at address 0455h lies a four-byte number 060Bh: 060Bh + 4 = 060Fh . It turns out that at the address 455h the length of the section describing the blocks of the second type is recorded.
In order to understand how the displacements of blocks of the first type from the beginning of the resource are described, it was decided to compile for each block of the first type the offset table of the beginning of this block and its length.
The first block of the first type begins where the descriptions of the blocks of the second type end - 0A68h.
And between the beginning of the resource and the offset 0455h there were bytes, very reminiscent of the increasing sequence:
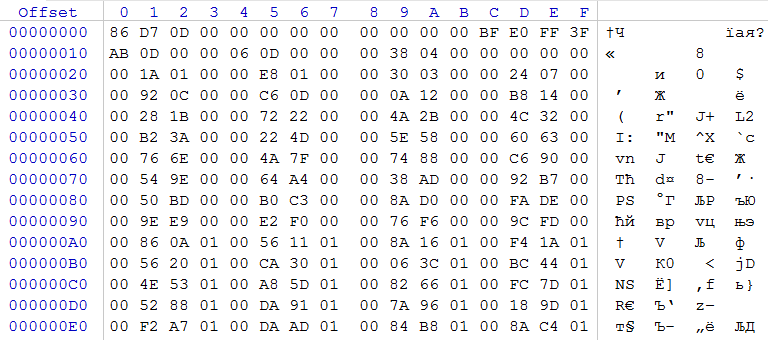
Let's try to subtract from 01E8h (offset 25h) the number 011Ah (offset 21h): 01E8h-011Ah = CEh, just the length of the second block. For fun: subtract 0330h (offset 29h) from 01E8h (offset 25h): 0330h-01E8 = 0148h, and 011Ah looks like the length of the first block. It turns out that descriptions of offsets of blocks of the first type come from offset 1Dh. They are recorded in the form of offsets of the beginning of the block from the end of the descriptions of the blocks of the second type (or the beginning of the section with the contents of the blocks - as convenient as possible). It remains to understand that the bytes are between 04h and 1D. If we subtract 1D (the beginning of the description of the displacements of the first type blocks) and 0455h (the offset for which the description length of the second type blocks is stored, that is, the descriptions of the first type blocks end): 0455h-1D = 0438h, such a number lies at the offset 19h. What is located in the remaining twenty-one bytes between 04h and 19h is a mystery to me. Yes, and really did not want to understand, because in all office localization files this offset is the same.
My program for reading localization files of Microsoft Office: Link to Ya.Disk
UPD: 1/16/2016
It turned out that blocks of the first type are sometimes encoded with an additional dictionary, which is written to the very end of the file. Apparently this is done to reduce the file size, because A dictionary can contain many letters in one byte. Actually, the link is now updated source code.
Among the names of Excel functions, there are those that are not described anywhere in the documentation, and you cannot use them in formulas. Why are their names localized for me is still a mystery. Here are some of these features:
During the long winter holidays I was even more boring, and I set out to determine how Excel calculates the height of the line based on the font. After several dozen hours spent in OllyDbg and IDA, almost 2000 lines of C # code were generated, which give 100% line height match with Excel for all fonts, their sizes and parameters. In addition, several interesting features of Excel internals were found, but this topic is already for a separate article.
Variant in the forehead
After a brief search for descriptions of the function arguments for the contents of the files in the office folder, the file c: \ Program Files \ Microsoft Office \ Office15 \ 1033 \ XLINTL32.DLL was found . Where 1033 is the LCID of the localization language ( for details, see msdn ).
From a quick glance it became clear that, in principle, I found what I was looking for. The argument descriptions for the AGGREGATE function for both variants in the file were correct. It turned out that Excel incorrectly parses its own localization file. Then it was decided to write your Excel localization files parser, or at least to understand the format of the MS Office localization files.
For a start, it was decided to write a parser of only descriptions of arguments and functions, as a quick glance at the file that is presented above gave the impression that the format is quite simple - the exclamation mark between the text serves as an exclamation mark, and you can understand what text means .
As a result, after a slightly thoughtful reading of the file, the following scheme for describing arguments and functions was revealed:
- All the descriptions are written in some proprietary order of functions for Excel, which did not coincide with the order of functions described in the specification for the xls format.
- Each function description is written in the following form: “!” + Comma separated descriptions of function arguments + [“!” + Second set of arguments, if any] + ”!!” + description of the function itself + ”!” + Argument descriptions, separated by “ ! ”
- Not all functions have a description, there are even completely empty functions that are written in the file like this: !!! - that's all.
According to this scheme, a parser was quickly written, which coped quite well with its work, but there were several problems:
- Between the descriptions of some functions, and specifically between the descriptions for the functions numbered 249 and 250, as well as between 504 and 505 there were incomprehensible kryakozyabry, and then again the normal descriptions:
- Descriptions of some functions did not fit the selected scheme and had to write crutches for them.
- It is not clear which function belongs to which description.
- The offset of the beginning of the block of descriptions of functions for different localizations was different, and we had to recognize this offset with our hands and enter it into the dictionary in the parser. What kind of automation can we talk about here?
- In some localizations, the descriptions were in UTF-8 format, in other UTF-16, somewhere in general half of the descriptions were on UTF-8, the other on UTF-16.
But in principle, with a large number of dirty hacks, it was possible to pull out descriptions of functions for almost all localizations.
')
Go down deeper
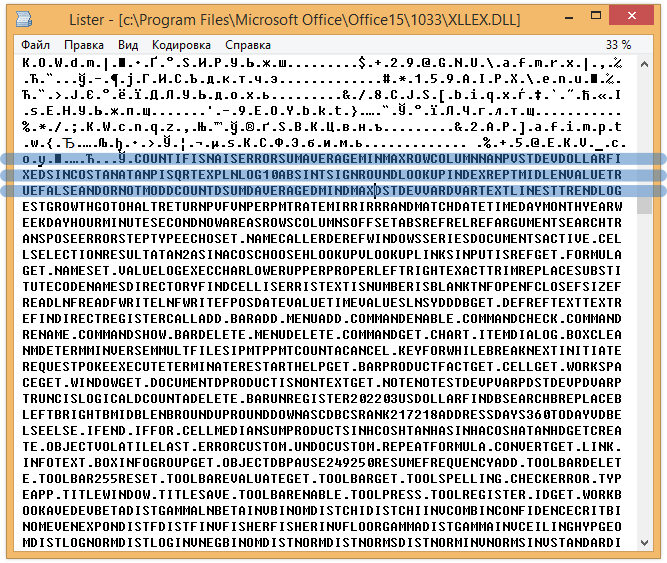
It remains to solve the problem of which function belongs to which description. To do this, I again began searching for the contents of files in MS Office folders, only this time I was looking for the names of the functions. And I was lucky: next to the file XLINTL32.DLL with descriptions of functions lay the file XLLEX.DLL, in which there was something similar to the names of the functions:
Only they went all somehow in a row and without gaps. And if for the English language it was still possible to disassemble this text with hands into separate names of functions, then for Arabic or Thai just so I could not do it.
In principle, it became clear that it was time to understand the format of the Excel localization files, or to score on this matter and go to bed. The first was chosen.
At first I noticed that both function descriptions and function names are stored in dll files in a resource with the name "1" and type "234". Thoughtful study of the resource dump from the XLLEX.DLL file (this is the one with the names of the functions) led me to the following discovery: between the sections with normal text there are areas with krakozybrami, which must bear a certain meaning. Then it was decided to study these sites more deeply using WinHEX and a calculator. Take the plot krakozyabrov that go in front of the site with the names of functions:
The first two bytes: 01 00 - I still do not know what they mean. The second two bytes are 56 02 - if you turn them over 0256, and if you also convert them from hex to decimal, you will get 598. Exactly as many function names below in the block of meaningful text. This is already pleased. Look further: the following pairs of bytes, if swapped, are like an increasing sequence. So it is, these bytes are the offset of the description of a separate function from the end of the gib block. In fact, the screenshot from the XLLEX.DLL file shows that the first function is COUNT - 5 bytes (0005h-0000h), the second - IF - 2 bytes (0007h-0005h), the third - ISNA - 4 bytes (000Bh-0007h) .
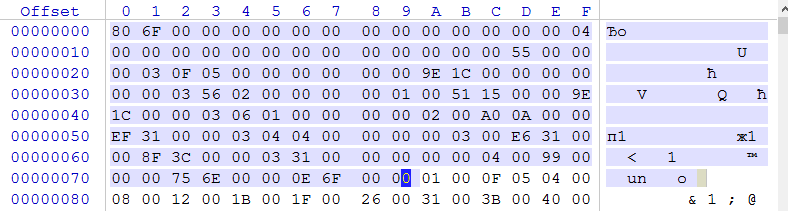
This is all very well, but how to determine where the block of cracks begins, in which the lengths of the names of the functions are given. Indeed, in each localization, this block has its own offset. Then I began to dig the header of the resource dump from the XLLEX.DLL file.
The first 4 bytes are the size of the resource. Further, I was interested in the bytes that are located at offset 33h 34h - their value - 0256 - exactly the same as the number of function names written in the file. In addition, every 17 bytes is repeated 03h, and the last 4 bytes in the area selected in the screenshot - 0E 6F 00 00 just equal to the number equal to the size of the resource = the size of the selected area + 4 + 4 - 1. That is, in fact, this the size of that part of the file where the data is.
Now you can write out all the bytes that are between duplicate 03h and group them a little:
| 03 | 0F05 | 00000000 | 0000 | 9E1C0000 | 00000000 |
| 03 | 5602 | 00000000 | 0100 | 51150000 | 9E1C0000 |
| 03 | 0601 | 00000000 | 0200 | A00A0000 | EF310000 |
| 03 | 0404 | 00000000 | 0300 | E6310000 | 8F3C0000 |
| 03 | 3100 | 00000000 | 0400 | 99000000 | 756E0000 |
- 1 byte is a block type (types 02, 03, 04 are normal lines in office files, 01 is similar to the WordBasic function table, there all the description goes as a function name and an index for each function).
- 2 bytes - the number of elements in the block.
- 4 bytes - I do not know. In all files that I watched, this value is always 0, it can be reserved.
- 2 bytes - the sequence number of the block.
- 4 bytes - block size
- 4 bytes - the offset of the block from the end of the block description, in the case of our file from 7Ah.
Understand encodings
In principle, this data is already enough to make an automatic parser for the XLLEX.DLL file and pull out the names of all functions in all languages and a lot of other information. But one problem arose in the process: only a very small part of the localizations stored data in UTF-8 format. Most of the data is stored in some completely incomprehensible formats: each character is encoded with 1 byte with some offset relative to the table of this language in UTF-8. For example, Cyrillic "C" and "H" were recorded as A1 and A7, and in the UTF8 table they have the numbers D0A1 and D0A7, but the "p" was written as C0, although it should be D180.
To solve this problem, I first, naturally, tried to understand how Excel itself translates strings from such an incomprehensible encoding at least in UTF-8. To do this, it was necessary to compare the block descriptions for several languages, I took the Russian localization and English:
Begin the description of the block for the English localization:
- English: 0100 5602 0500 ... (the second two bytes, as we found out above - the number of elements in the block, the third two bytes - the length of the first element (COUNT function - 5 bytes) ...)
- Russian: 0184 5602 0400 ... (the second two bytes are the number of elements, the third two bytes are the length of the first element (the COUNT function is 4 bytes) ...)
From this, some conclusions were made: the first two bytes in the block description are encoding. If the first byte = 0, then the text in this block is written in Unicode LE, and everything is simple. If the first byte of the encoding = 01, then you need to look at the second byte. If the second byte = 00, then the text is encoded in a simple UTF-8 encoding; here, too, do not break your head. But what if the second byte is not 0?
At first, I simply compiled a dictionary: the value of the second byte is the offset in the UTF-8 table. It quickly bored me, and I began to look for a pattern. It soon became clear that the offset in the UTF-8 table can be defined as: offset = (byte2-80h) * 4 + C0h. The only problem is that for some groups of codings C0h had to be changed to another number.
As a result, the text conversion functions began to look like this:
C # code
#region Convert int GetCharSize(int blockIndex) { if(block2Encoding[blockIndex][0] == 0) return 2; if(block2Encoding[blockIndex][0] == 1) return 1; if (block2Encoding[blockIndex][0] == 2) return 2; if (block2Encoding[blockIndex][0] == 3) return 1; return 1; } byte[] Convert(byte[] array, int blockIndex) { byte encodingByte1 = block2Encoding[blockIndex][0]; byte encodingByte2 = block2Encoding[blockIndex][1]; if(encodingByte1 == 0 || encodingByte1 == 2) return Convert0000(array); if(encodingByte2 < 0x80) return ConvertFromUTF8(array, 0x00, 0xC2); int d = encodingByte2 - 0x80; d *= 4; byte byte1; byte byte2; if(d < 0x20) { byte1 = 0; byte2 = (byte) (0xC0 + d); } else if(d < 0x40) { byte1 = 0xE0; byte2 = (byte) (0xA0 + (d - 0x20)); } else { d -= 0x40; byte1 = (byte) (0xE1 + d / 0x40); byte2 = (byte) (0x80 + d % 0x40); } return ConvertFromUTF8(array, byte1, byte2); } byte[] ConvertFromUTF8(byte[] array, byte byte1, byte byte2) { List<byte> result = new List<byte>(); foreach(byte b in array) { if(b <= 0xFF / 2) result.Add(b); else { if(byte1 != 0) result.Add(byte1); byte d = (byte) (byte2 + (b - 1) / 0xBF); result.Add(d); d = b; if(b >= 0xC0) { d = (byte) (b - 0xC0 + 0x80); } result.Add(d); } } return result.ToArray(); } byte[] Convert0000(byte[] array) { return Encoding.Convert(Encoding.Unicode, Encoding.UTF8, array); } #endregion We dig up the essence
After all this, it was possible to precisely and correctly pull out all the localized text from the XLLEX.DLL file, but this method was completely unsuitable for the file with the descriptions of the functions and arguments of XLINTL32.DLL. Here I had to start everything from the very beginning, but it was already easier.
To begin with, in the XLINTL32.DLL file I tried to find something already familiar and similar to the data from the XLLEX.DLL file. The familiar picture began at offset 0459h:
Those. since 04B1h there were block descriptions, the same as in the XLLEX.DLL file, but above this offset everything was somehow incomprehensible. And not all the text from the resource obeyed the rules, which were derived from parsing the XLLEX.DLL file.
It was decided later on those blocks that I have already learned to recognize are called blocks of the second type, and those that I do not know how yet are blocks of the first type, since they went in the XLINTL32.DLL file above the blocks of the second type.
The text of the first type blocks began almost immediately after the end of the second type block map, it remains to find where the first type block map is located in the file, and how to define a text delimiter in the first type blocks. This block was selected for study:
It clearly shows the following lines: “Cut, copy, and paste”, “Print”, “For charts”, etc. In addition, a “characteristic” ladder of zeros and increasing values is visible in hex codes. The first two values in this ladder are 46h and 6Eh - the difference between them in the decimal form is 40, since the text is explicitly set in Unicode LE, then the length “Cut, copy, and paste” will be 20 * 2 = 40. Converges. Check another pair of values: 78h-6Eh = 10/2 = 5 - exactly the length of “Print”. Let's rewrite beautifully all bytes from the 07BE66h offset to the beginning of the meaningful text:
00 46000000
00 6E000000
00 78000000
...
FF E2020000
The total length of the resulting statement is 07BEABh - 07BE66h + 1 = 46h - somewhere it already was. It turns out that the descriptions of the elements in the first type block look like this: 1 byte element type, 4 bytes - the offset of the element relative to the beginning of this block. As it turned out later, the types of elements in the block of the first type are 00h - plain text in Unicode, 0Ah - some strange krakozyabry, FFh - the last element in this block.
Now the last thing remains: deal with the resource header and find out how the offsets are determined for all blocks.
To begin with, I remembered that the description of all blocks of the second type ends at offset 0A67h, and begins at offset 0459h, the total length of the description of blocks of the second type is 0A67h-0459h + 1 = 060Fh, and at address 0455h lies a four-byte number 060Bh: 060Bh + 4 = 060Fh . It turns out that at the address 455h the length of the section describing the blocks of the second type is recorded.
In order to understand how the displacements of blocks of the first type from the beginning of the resource are described, it was decided to compile for each block of the first type the offset table of the beginning of this block and its length.
The first block of the first type begins where the descriptions of the blocks of the second type end - 0A68h.
| Bias | Length |
|---|---|
| 0A68h | 011Ah |
| 0B82h | 00CEh |
| 0C50h | 0148h |
Let's try to subtract from 01E8h (offset 25h) the number 011Ah (offset 21h): 01E8h-011Ah = CEh, just the length of the second block. For fun: subtract 0330h (offset 29h) from 01E8h (offset 25h): 0330h-01E8 = 0148h, and 011Ah looks like the length of the first block. It turns out that descriptions of offsets of blocks of the first type come from offset 1Dh. They are recorded in the form of offsets of the beginning of the block from the end of the descriptions of the blocks of the second type (or the beginning of the section with the contents of the blocks - as convenient as possible). It remains to understand that the bytes are between 04h and 1D. If we subtract 1D (the beginning of the description of the displacements of the first type blocks) and 0455h (the offset for which the description length of the second type blocks is stored, that is, the descriptions of the first type blocks end): 0455h-1D = 0438h, such a number lies at the offset 19h. What is located in the remaining twenty-one bytes between 04h and 19h is a mystery to me. Yes, and really did not want to understand, because in all office localization files this offset is the same.
My program for reading localization files of Microsoft Office: Link to Ya.Disk
UPD: 1/16/2016
It turned out that blocks of the first type are sometimes encoded with an additional dictionary, which is written to the very end of the file. Apparently this is done to reduce the file size, because A dictionary can contain many letters in one byte. Actually, the link is now updated source code.
Short file structure specification
4 bytes - resource size
21 bytes - not fame
4 bytes - the number of blocks of type 1 * 4 = the number of bytes, which describes the map of blocks of type 1
* Begin of the description of the map of blocks of the first type *
4 bytes - offset of type 1 block from the end of block description. The difference between two adjacent values is the length of a block of type 1.
* The end of the description of the map of blocks of the first type *
4 bytes - the number of bytes used to describe a block map of type 2 = number of blocks of type 2 * 17 bytes
* Begin to describe the map of blocks of the second type *
1 byte - block type
2 bytes - the number of elements in the block 2 types
4 bytes - I do not know. In my opinion it is always 0, it can be reserved.
2 bytes - the ordinal number of block 2
4 bytes - the length of the block of the second type
4 bytes - offset of the second type block from the end of the block description
* The end of the description of the map of blocks of the second type *
4 bytes - data length for type 2 blocks
* Blocks of the first type *
1 byte - type of element - FD - this element is the last in this block, if 00 is plain text in Unicode, if 0A is xs.
4 bytes - the offset of the element relative to the beginning of this block
Further elements
* End of blocks of the first type *
* Blocks of the second type *
1 byte - the first byte of the encoding
1 byte - the second byte of the encoding
2 bytes - the number of elements in the block
* Map of elements of the block of the second type *
2 bytes - offset relative to the beginning of the block elements. Starts with the second element. If the offset gets over the FFFF, then after the offset two more bytes are added = how many times the FFFF should be taken.
* The end of the map of the elements of the block of the second type *
* End of blocks of the second type *
********************
By encodings:
Encoding is defined as:
if the second byte == 0, then this is a simple Unicode Little Endian.
if the second byte == 1, then the elements are encoded in UTF8 and the offset can be determined by the first byte.
********************
Blocks of the second type are several more types.
2, 3, 4 - regular lines
1 - it looks like a WordBasic table, at the beginning there is a table of some indexes (maybe indexes of WordBasic functions)
21 bytes - not fame
4 bytes - the number of blocks of type 1 * 4 = the number of bytes, which describes the map of blocks of type 1
* Begin of the description of the map of blocks of the first type *
4 bytes - offset of type 1 block from the end of block description. The difference between two adjacent values is the length of a block of type 1.
* The end of the description of the map of blocks of the first type *
4 bytes - the number of bytes used to describe a block map of type 2 = number of blocks of type 2 * 17 bytes
* Begin to describe the map of blocks of the second type *
1 byte - block type
2 bytes - the number of elements in the block 2 types
4 bytes - I do not know. In my opinion it is always 0, it can be reserved.
2 bytes - the ordinal number of block 2
4 bytes - the length of the block of the second type
4 bytes - offset of the second type block from the end of the block description
* The end of the description of the map of blocks of the second type *
4 bytes - data length for type 2 blocks
* Blocks of the first type *
1 byte - type of element - FD - this element is the last in this block, if 00 is plain text in Unicode, if 0A is xs.
4 bytes - the offset of the element relative to the beginning of this block
Further elements
* End of blocks of the first type *
* Blocks of the second type *
1 byte - the first byte of the encoding
1 byte - the second byte of the encoding
2 bytes - the number of elements in the block
* Map of elements of the block of the second type *
2 bytes - offset relative to the beginning of the block elements. Starts with the second element. If the offset gets over the FFFF, then after the offset two more bytes are added = how many times the FFFF should be taken.
* The end of the map of the elements of the block of the second type *
* End of blocks of the second type *
********************
By encodings:
Encoding is defined as:
if the second byte == 0, then this is a simple Unicode Little Endian.
if the second byte == 1, then the elements are encoded in UTF8 and the offset can be determined by the first byte.
********************
Blocks of the second type are several more types.
2, 3, 4 - regular lines
1 - it looks like a WordBasic table, at the beginning there is a table of some indexes (maybe indexes of WordBasic functions)
It is interesting
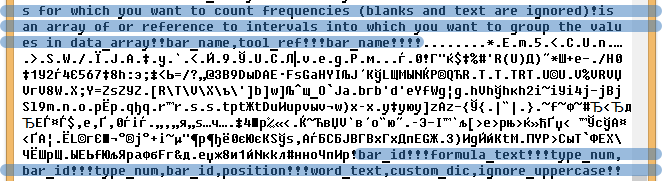
Among the names of Excel functions, there are those that are not described anywhere in the documentation, and you cannot use them in formulas. Why are their names localized for me is still a mystery. Here are some of these features:
- GOTO (reference);
- HALT (cancel_close);
- ECHO (logical);
- WINDOWS (type_num, match_text);
- INPUT (message_text, type_num, title_text, default, x_pos, y_pos, help_ref);
- ADD.TOOLBAR (bar_name, tool_ref).
PS
During the long winter holidays I was even more boring, and I set out to determine how Excel calculates the height of the line based on the font. After several dozen hours spent in OllyDbg and IDA, almost 2000 lines of C # code were generated, which give 100% line height match with Excel for all fonts, their sizes and parameters. In addition, several interesting features of Excel internals were found, but this topic is already for a separate article.
Source: https://habr.com/ru/post/248597/
All Articles