How to get started in Kaggle: a guide for beginners in Data Science
Good day, dear habrovchane! Today I would like to talk about how, without having special experience in machine learning, you can try your hand at competitions held by Kaggle .

As you probably already know, Kaggle is a platform for researchers at various levels, where they can try out their data analysis models for serious and relevant tasks. The essence of such a resource is not only the ability to get a good cash prize if it is your model that turns out to be the best, but also (and this is probably more important) to gain experience and become a specialist in data analysis and machine learning. . After all, the most important question often faced by such specialists is where to find real tasks? Here they are enough.
')
We will try to participate in a training competition that does not provide any incentives other than experience.
To do this, I chose the problem of recognizing handwritten numbers from a sample of MNIST . Some information from the wiki . The MNIST (Mixed National Institute of Standards and Technology database) is the main base for testing image recognition systems, and is also widely used for teaching and testing machine learning algorithms. It was created by rearranging images from the original NIST database, which was difficult enough to recognize. In addition, certain transformations were performed (the images were normalized and smoothed to obtain gray gradations).
The MNIST database consists of 60,000 images for learning and 10,000 images for testing. A large number of articles were written on the MNIST recognition problem, for example (in this case, the authors used a hierarchical system of convolutional neural networks).
The original sample is presented on the site .
Kaggle features a complete MNIST sample, organized a little differently. Here, the training sample includes 42,000 images, and the test sample includes 28,000 images. However, they are equivalent in content. Each MNIST image is represented by a 28X28 pixel image with 256 shades of gray. An example of several ambiguous identifying numbers is shown in the picture below.

To create our own neural network model for digit recognition, we use the Python interpreter with the installed nolearn 0.4 package, as well as numpy and scipy (to satisfy all dependencies).
Here the introductory article written by Adrian Rosebrock in my blog helped me a lot. It provides introductory information about neural networks of deep trust and their learning, although the author himself uses the usual multi-layered perceptron of the architecture 784-300-10 without any training before testing. So do we. By the way, the process of using the package on the nolearn page is considered in great detail and by the example of various classical samples.
So, following the instructions given in the above-mentioned articles, we will create our multi-layer perceptron, train it on the loaded and processed data, and then we will carry out testing.
To begin with, let's create our double-layer perceptron of architecture 784-300-10:
This requires some explanation. The first parameter of the neural network constructor is a list containing the number of inputs and neurons in each layer, learn_rates — learning rate, learn_rate_decays — a multiplier setting the change in learning rate after each epoch, epochs — number of learning epochs, verbose — output flag of a detailed report of the learning process.
After executing this instruction, the required model will be created and we will only have to load the data. Kaggle provides us with two files: train.csv and test.csv , containing samples for training and testing, respectively. The file structure is simple - the first line contains the header, followed by the data. For train.csv, each line with data is preceded by a corresponding label - a digit from 0 to 9, which defines the image. There is no label in test.csv.
The next step is to load the data into the arrays using the package for working with csv-files. Do not forget to normalize:
After that we train our neural network on the prepared data:
The process itself takes some time, determined by the number of learning epochs specified in the construction of a neural network. At each training epoch, the values of loss and err (the value of the loss function and error) will be displayed (for a given verbose parameter).
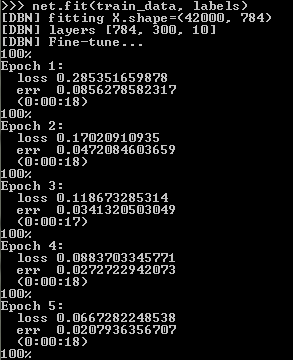
After learning, all we have to do is to load the test data and save the predictions for each image from the test sample to a file with a csv extension:
Next, load the resulting file into the testing system (see figure) and wait.
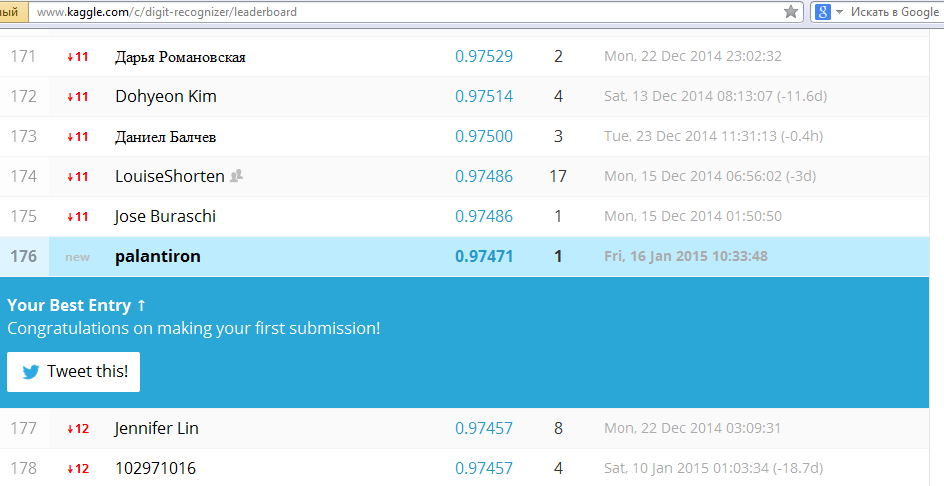
Done! 176 place out of more than 500 participants. For a start, quite good. Now we can try to improve the result obtained, for example, by applying our own developments or modifying and selecting parameters in nolearn. The benefit of time is enough: the MNIST competition has been repeatedly extended and now it will run until 12/31/2015. Good luck and thank you for reading this article.
As you probably already know, Kaggle is a platform for researchers at various levels, where they can try out their data analysis models for serious and relevant tasks. The essence of such a resource is not only the ability to get a good cash prize if it is your model that turns out to be the best, but also (and this is probably more important) to gain experience and become a specialist in data analysis and machine learning. . After all, the most important question often faced by such specialists is where to find real tasks? Here they are enough.
')
We will try to participate in a training competition that does not provide any incentives other than experience.
To do this, I chose the problem of recognizing handwritten numbers from a sample of MNIST . Some information from the wiki . The MNIST (Mixed National Institute of Standards and Technology database) is the main base for testing image recognition systems, and is also widely used for teaching and testing machine learning algorithms. It was created by rearranging images from the original NIST database, which was difficult enough to recognize. In addition, certain transformations were performed (the images were normalized and smoothed to obtain gray gradations).
The MNIST database consists of 60,000 images for learning and 10,000 images for testing. A large number of articles were written on the MNIST recognition problem, for example (in this case, the authors used a hierarchical system of convolutional neural networks).
The original sample is presented on the site .
Kaggle features a complete MNIST sample, organized a little differently. Here, the training sample includes 42,000 images, and the test sample includes 28,000 images. However, they are equivalent in content. Each MNIST image is represented by a 28X28 pixel image with 256 shades of gray. An example of several ambiguous identifying numbers is shown in the picture below.
To create our own neural network model for digit recognition, we use the Python interpreter with the installed nolearn 0.4 package, as well as numpy and scipy (to satisfy all dependencies).
Here the introductory article written by Adrian Rosebrock in my blog helped me a lot. It provides introductory information about neural networks of deep trust and their learning, although the author himself uses the usual multi-layered perceptron of the architecture 784-300-10 without any training before testing. So do we. By the way, the process of using the package on the nolearn page is considered in great detail and by the example of various classical samples.
So, following the instructions given in the above-mentioned articles, we will create our multi-layer perceptron, train it on the loaded and processed data, and then we will carry out testing.
To begin with, let's create our double-layer perceptron of architecture 784-300-10:
from nolearn.dbn import DBN net = DBN( [784, 300, 10], learn_rates=0.3, learn_rate_decays=0.9, epochs=10, verbose=1, ) This requires some explanation. The first parameter of the neural network constructor is a list containing the number of inputs and neurons in each layer, learn_rates — learning rate, learn_rate_decays — a multiplier setting the change in learning rate after each epoch, epochs — number of learning epochs, verbose — output flag of a detailed report of the learning process.
After executing this instruction, the required model will be created and we will only have to load the data. Kaggle provides us with two files: train.csv and test.csv , containing samples for training and testing, respectively. The file structure is simple - the first line contains the header, followed by the data. For train.csv, each line with data is preceded by a corresponding label - a digit from 0 to 9, which defines the image. There is no label in test.csv.
The next step is to load the data into the arrays using the package for working with csv-files. Do not forget to normalize:
import csv import numpy as np with open('D:\\train.csv', 'rb') as f: data = list(csv.reader(f)) train_data = np.array(data[1:]) labels = train_data[:, 0].astype('float') train_data = train_data[:, 1:].astype('float') / 255.0 After that we train our neural network on the prepared data:
net.fit(train_data, labels) The process itself takes some time, determined by the number of learning epochs specified in the construction of a neural network. At each training epoch, the values of loss and err (the value of the loss function and error) will be displayed (for a given verbose parameter).
After learning, all we have to do is to load the test data and save the predictions for each image from the test sample to a file with a csv extension:
with open('D:\\test.csv', 'rb') as f: data = list(csv.reader(f)) test_data = np.array(data[1:]).astype('float') / 255.0 preds = net.predict(test_data) with open('D:\\submission.csv', 'wb') as f: fieldnames = ['ImageId', 'Label'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() i = 1 for elem in preds: writer.writerow({'ImageId': i, 'Label': elem}) i += 1 Next, load the resulting file into the testing system (see figure) and wait.
Done! 176 place out of more than 500 participants. For a start, quite good. Now we can try to improve the result obtained, for example, by applying our own developments or modifying and selecting parameters in nolearn. The benefit of time is enough: the MNIST competition has been repeatedly extended and now it will run until 12/31/2015. Good luck and thank you for reading this article.
Source: https://habr.com/ru/post/248395/
All Articles