How we build a message handling system
Our team is developing a back-end system for processing messages from mobile devices. Devices collect information about the operation of complex equipment and send messages to the processing center. In this article I want to share approaches to the construction of such systems. Ideas are quite general, they can be applied to any system with the following architecture:
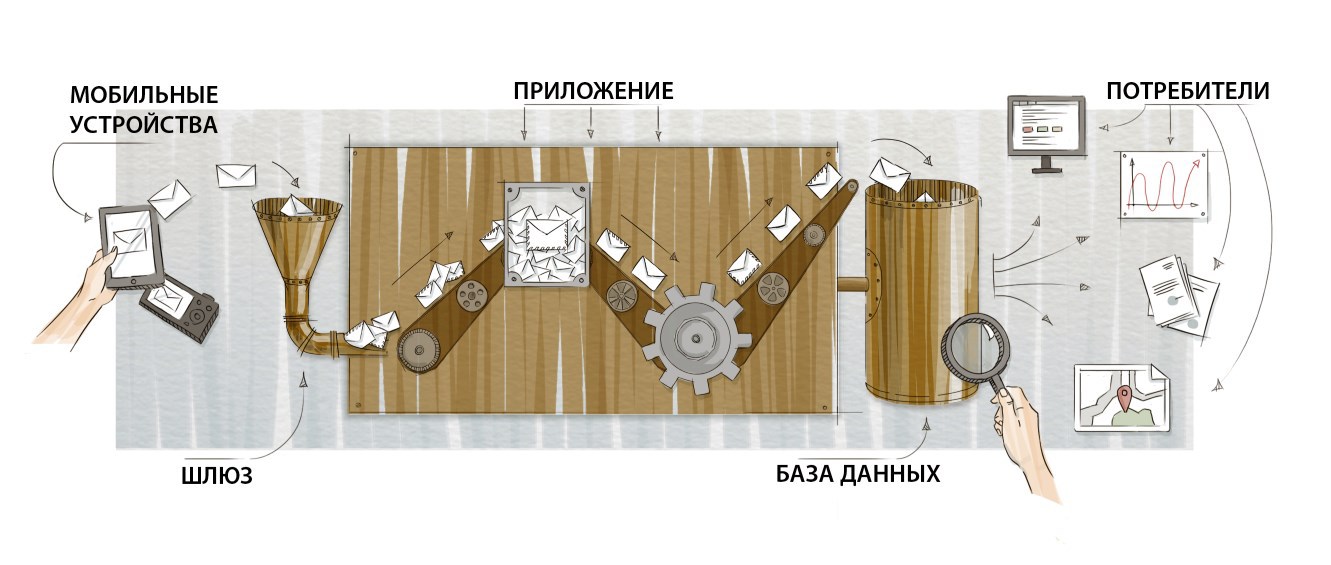
The communication channels of the device send messages to our gateway (gateway) - the entry point of the application. The task of the application is to find out exactly what has come, take the necessary actions and save the information in a database for further analysis. We will consider the base as the end point of processing. It sounds simple, but with the growth of the number and variety of messages, several nuances appear, which I want to discuss.
A little about the level of load. Our system processes messages from tens of thousands of devices, while on average we receive from a few hundred to a thousand messages in a second. If your numbers differ by a couple of orders of magnitude in one direction or another, the set of your problems and approaches to solving them may be different.
')
In addition to the actual number of messages per second, there is the problem of their uneven receipt. The application should be ready for short load peaks ten times higher than the average. To solve this problem, the system is organized as a set of queues and their handlers.
The receiving gateway does not do any real work - it simply receives the message from the client and places it in the queue. This is a very cheap operation, so the gateway can receive a huge number of messages per second. Then, there is a separate process that receives several messages from the queue - just as much as it wants and can - and does the hard work. Processing is asynchronous, and the load is stably limited. It is possible that at the peak, the time spent in the queue will increase slightly, that's all.
Often, processing a message is nontrivial and consists of several actions. The next logical step is to split the work into several stages: several queues and handlers. At the same time, physically different queues and handlers can be located on different servers, each of which can be customized and scaled for its specific task:
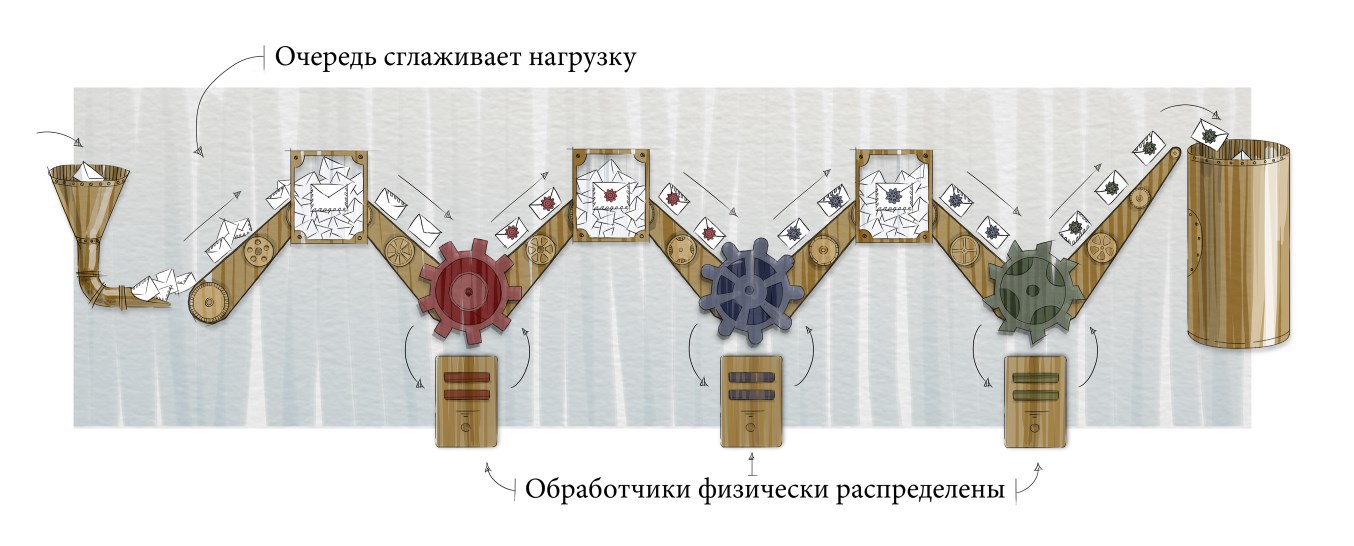
The first stage contains messages in the form in which they came from the device. The handler decodes them and places them second. The second handler can, for example, produce some aggregation and create information that is interesting for the business, and the third handler can save it in a database.
This is the basic alignment, what else do you need to think about?
Asynchronous distributed message processing adds additional complexity to the software product. We are constantly working to reduce this price. The code is optimized, first of all, in the direction of increasing readability, clarity for all team members, ease of change and support. If in the end no one except the author can figure out the code, no great architecture will help make the team happy.
The thesis seems simple, but it took us quite a long time before we not only voiced this principle, but also became stable and constantly apply it in our daily work. We try to constantly do refactoring if we feel that the code can be made slightly better and simpler. All sources are reviewed, and the most critical parts are usually developed in pairs.
It makes sense to immediately determine the requirements for the ability of the system to continue to function in the event of equipment and subsystem failures. All of them will be different. Perhaps someone is ready to just throw out all messages in the 5 minutes that one of the servers is rebooting.
In our system, we do not want to lose messages. If a service is unavailable, the call to the database ends with a timeout, or a random error occurs in the processing, it should not result in the loss of information from the devices. Dependent messages should remain in the queue and will be processed immediately after the problem is fixed.
Suppose your code on one server synchronously calls a web service on another server. If the second server is unavailable, the processing will end in error, and you can only log it. With asynchronous processing, the message will wait for the second server to return to a working state.
The number of messages processed per unit of time, delays, and server loadings are all important parameters of system performance. That is why we are building a flexible architecture into the project.
However, do not focus on optimization from the very beginning. Usually, the overwhelming majority of performance problems are created by relatively small pieces of code. Unfortunately, few people can predict in advance exactly where these problems will be. This is where people write whole books about premature optimization . Make sure your architecture allows you to quickly set up the system and forget about optimization before the first load tests.
At the same time, load tests need to start doing early, and then make them part of the standard testing procedure. And only when the tests show a specific problem, take up the optimization.
I already wrote about this above. Our main toolkit is queues and their handlers. In addition to the classic style of organizing the code, “received a request, called the remote code, waited for a response, returned the answer to the top”, we get the approach “received a message from the queue, completed, sent a message to another queue”. On how successful the balance in the combination of the two approaches you find depends on both the scalability and ease of system design.
If the processing of a message is quite complex and can be broken up into several stages, consider several queues and processors. Keep in mind that excessive fragmentation can make the system more difficult to understand. It needs a balance. Quite often there is a split, natural and understandable to developers. If not, try to think about points of failure. If the handler can fail for several independent reasons, you can think about splitting it.
Usually, the message comes in the format of some protocol of interaction of devices on the network: binary, xml, json, etc. Decode and translate them into your internal format as early as possible. This will solve at least two problems. First, there can be several protocols; after decoding, you can unify the format of further messages. Secondly, logging and debugging is simplified.
Structure the processing code so that you can easily change the queue configuration. Splitting a handler into two should not lead to a refactoring cloud. Do not let your code depend too much on the specific implementation of the queues, tomorrow you may want to change it.
Often it makes sense to receive messages from the queue not one at a time, but immediately in groups. The services you use can receive an array of data for batch processing, in which case one big call will usually be much more efficient than a hundred small ones. Inserting hundreds of entries into the database at one time will be faster than a hundred remote calls.
Invest in monitoring from the start. You should easily and visually see the bandwidth schedule, average processing time, current queue size, time since the last message with a breakdown by queue.
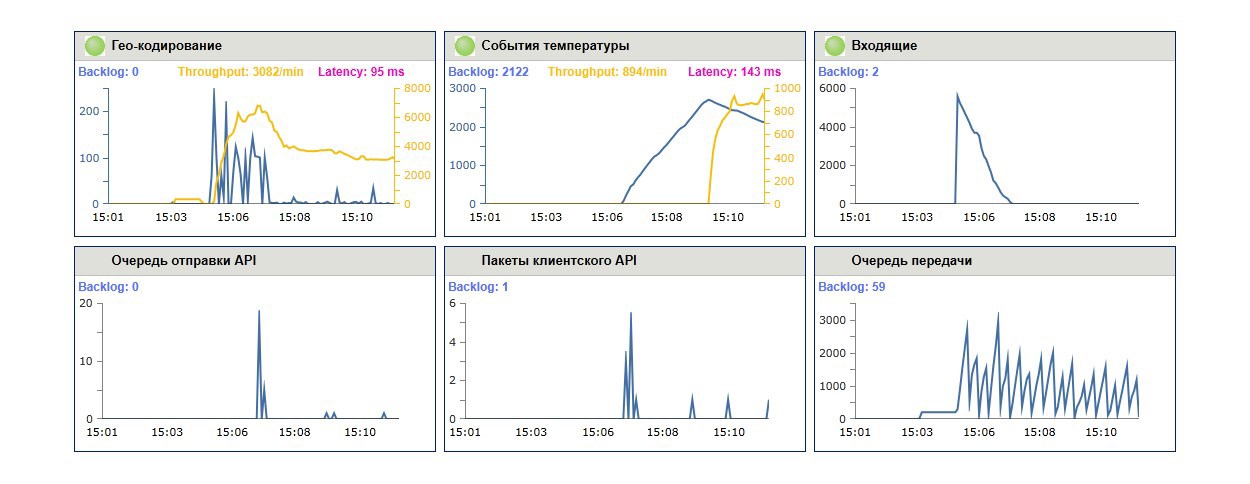
We use monitoring not only in the combat environment, but also in the test, and even on the developers' machines. Properly configured graphics and notifications are very useful for debugging and preload testing.
Message processing systems are an ideal testing ground for automated testing. The input protocol is defined and limited, no interactions with living people. Cover the code with unit tests. Provide the ability to replace the combat queues on the test queues in the local memory and do quick tests of the interaction of handlers. Finally, do full-fledged integration tests that can be driven in beta (staging) environments (and better in products).
Most of the time, you don’t want a single message error to stop the entire queue. Equally important is the ability to diagnose an error. Put such messages in a special repository and target all your searchlights at this repository. Provide the ability to easily move a message back to the processing queue as soon as the cause of the error has been eliminated.
The same or a similar mechanism can be used to store messages that should be processed no earlier than some point in the future. We keep them in the sump and periodically check to see if the hour has arrived.
Installation and updating of the system should be done in one or several clicks. Aim for frequent product updates, ideally for automatic deployment after each commit to the master branch. The installation script will help developers keep their personal environment, as well as the testing environment up to date.
A good clear architecture is also a way to simplify the communication of developers, their common vision and a set of concepts. In this sense, we were greatly helped by the formulation of the metaphor of the system in the form of a picture with which one can begin many discussions in the project.
Our metaphor is similar to this picture from Uncle Bob’s article The Clean Architecture :
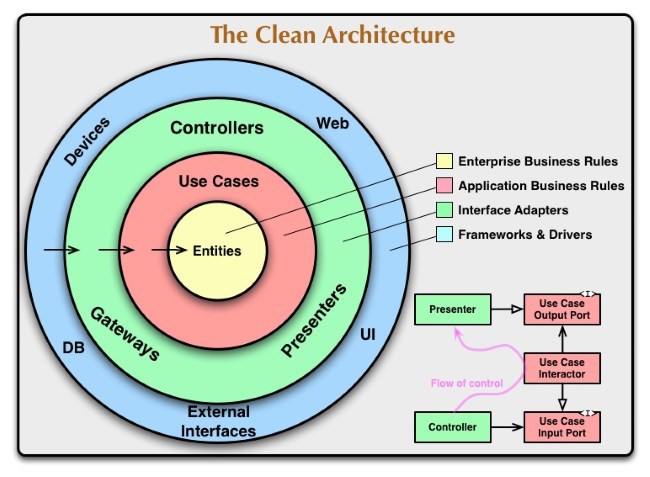
In our scheme, we denote the entities of the system and their dependencies, which helps in the discussion to get closer to the correct design, find errors or plan refactoring.
The communication channels of the device send messages to our gateway (gateway) - the entry point of the application. The task of the application is to find out exactly what has come, take the necessary actions and save the information in a database for further analysis. We will consider the base as the end point of processing. It sounds simple, but with the growth of the number and variety of messages, several nuances appear, which I want to discuss.
A little about the level of load. Our system processes messages from tens of thousands of devices, while on average we receive from a few hundred to a thousand messages in a second. If your numbers differ by a couple of orders of magnitude in one direction or another, the set of your problems and approaches to solving them may be different.
')
In addition to the actual number of messages per second, there is the problem of their uneven receipt. The application should be ready for short load peaks ten times higher than the average. To solve this problem, the system is organized as a set of queues and their handlers.
The receiving gateway does not do any real work - it simply receives the message from the client and places it in the queue. This is a very cheap operation, so the gateway can receive a huge number of messages per second. Then, there is a separate process that receives several messages from the queue - just as much as it wants and can - and does the hard work. Processing is asynchronous, and the load is stably limited. It is possible that at the peak, the time spent in the queue will increase slightly, that's all.
Often, processing a message is nontrivial and consists of several actions. The next logical step is to split the work into several stages: several queues and handlers. At the same time, physically different queues and handlers can be located on different servers, each of which can be customized and scaled for its specific task:
The first stage contains messages in the form in which they came from the device. The handler decodes them and places them second. The second handler can, for example, produce some aggregation and create information that is interesting for the business, and the third handler can save it in a database.
This is the basic alignment, what else do you need to think about?
Determine the values
1. Easy to create, modify, and maintain
Asynchronous distributed message processing adds additional complexity to the software product. We are constantly working to reduce this price. The code is optimized, first of all, in the direction of increasing readability, clarity for all team members, ease of change and support. If in the end no one except the author can figure out the code, no great architecture will help make the team happy.
The thesis seems simple, but it took us quite a long time before we not only voiced this principle, but also became stable and constantly apply it in our daily work. We try to constantly do refactoring if we feel that the code can be made slightly better and simpler. All sources are reviewed, and the most critical parts are usually developed in pairs.
2. Fault tolerance
It makes sense to immediately determine the requirements for the ability of the system to continue to function in the event of equipment and subsystem failures. All of them will be different. Perhaps someone is ready to just throw out all messages in the 5 minutes that one of the servers is rebooting.
In our system, we do not want to lose messages. If a service is unavailable, the call to the database ends with a timeout, or a random error occurs in the processing, it should not result in the loss of information from the devices. Dependent messages should remain in the queue and will be processed immediately after the problem is fixed.
Suppose your code on one server synchronously calls a web service on another server. If the second server is unavailable, the processing will end in error, and you can only log it. With asynchronous processing, the message will wait for the second server to return to a working state.
3. Performance
The number of messages processed per unit of time, delays, and server loadings are all important parameters of system performance. That is why we are building a flexible architecture into the project.
However, do not focus on optimization from the very beginning. Usually, the overwhelming majority of performance problems are created by relatively small pieces of code. Unfortunately, few people can predict in advance exactly where these problems will be. This is where people write whole books about premature optimization . Make sure your architecture allows you to quickly set up the system and forget about optimization before the first load tests.
At the same time, load tests need to start doing early, and then make them part of the standard testing procedure. And only when the tests show a specific problem, take up the optimization.
We adjust the brain
1. Operate with queues and asynchronous handlers.
I already wrote about this above. Our main toolkit is queues and their handlers. In addition to the classic style of organizing the code, “received a request, called the remote code, waited for a response, returned the answer to the top”, we get the approach “received a message from the queue, completed, sent a message to another queue”. On how successful the balance in the combination of the two approaches you find depends on both the scalability and ease of system design.
2. Split processing into several steps.
If the processing of a message is quite complex and can be broken up into several stages, consider several queues and processors. Keep in mind that excessive fragmentation can make the system more difficult to understand. It needs a balance. Quite often there is a split, natural and understandable to developers. If not, try to think about points of failure. If the handler can fail for several independent reasons, you can think about splitting it.
3. Do not mix decoding and processing
Usually, the message comes in the format of some protocol of interaction of devices on the network: binary, xml, json, etc. Decode and translate them into your internal format as early as possible. This will solve at least two problems. First, there can be several protocols; after decoding, you can unify the format of further messages. Secondly, logging and debugging is simplified.
4. Make queuing configuration easy
Structure the processing code so that you can easily change the queue configuration. Splitting a handler into two should not lead to a refactoring cloud. Do not let your code depend too much on the specific implementation of the queues, tomorrow you may want to change it.
5. Process messages in groups
Often it makes sense to receive messages from the queue not one at a time, but immediately in groups. The services you use can receive an array of data for batch processing, in which case one big call will usually be much more efficient than a hundred small ones. Inserting hundreds of entries into the database at one time will be faster than a hundred remote calls.
Create tools
1. Implement total observation
Invest in monitoring from the start. You should easily and visually see the bandwidth schedule, average processing time, current queue size, time since the last message with a breakdown by queue.
We use monitoring not only in the combat environment, but also in the test, and even on the developers' machines. Properly configured graphics and notifications are very useful for debugging and preload testing.
2. Test everything
Message processing systems are an ideal testing ground for automated testing. The input protocol is defined and limited, no interactions with living people. Cover the code with unit tests. Provide the ability to replace the combat queues on the test queues in the local memory and do quick tests of the interaction of handlers. Finally, do full-fledged integration tests that can be driven in beta (staging) environments (and better in products).
3. Start a sump for error messages.
Most of the time, you don’t want a single message error to stop the entire queue. Equally important is the ability to diagnose an error. Put such messages in a special repository and target all your searchlights at this repository. Provide the ability to easily move a message back to the processing queue as soon as the cause of the error has been eliminated.
The same or a similar mechanism can be used to store messages that should be processed no earlier than some point in the future. We keep them in the sump and periodically check to see if the hour has arrived.
4. Automate deployment
Installation and updating of the system should be done in one or several clicks. Aim for frequent product updates, ideally for automatic deployment after each commit to the master branch. The installation script will help developers keep their personal environment, as well as the testing environment up to date.
Instead of conclusion
A good clear architecture is also a way to simplify the communication of developers, their common vision and a set of concepts. In this sense, we were greatly helped by the formulation of the metaphor of the system in the form of a picture with which one can begin many discussions in the project.
Our metaphor is similar to this picture from Uncle Bob’s article The Clean Architecture :
In our scheme, we denote the entities of the system and their dependencies, which helps in the discussion to get closer to the correct design, find errors or plan refactoring.
Source: https://habr.com/ru/post/248093/
All Articles