Non-personalized recommendations: association method
Personal recommendations allow you to acquaint the user with objects about which he may never have known (and would not have known), but who might like him taking into account his interests, preferences and behavioral properties. However, often the user is not looking for a new object, but, for example, object A resembles object B (“Fast and Furious 2” is similar to “Fast and Furious”), or object A, which is acquired / consumed with object B (cheese with wine, beer with baby food, buckwheat with stew, etc.). Building such recommendations allows non-personalized recommendation systems (LDCs).
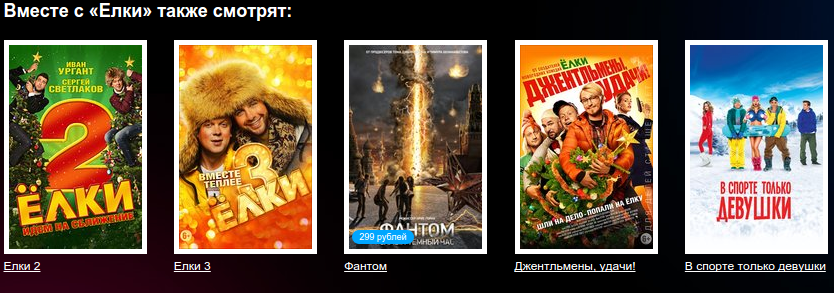
It is possible to recommend similar / related objects, focusing on knowledge about objects (properties, tags, parameters) or on knowledge of actions related to objects (purchases, views, clicks). The advantage of the first method is that it allows you to accurately determine objects with similar properties (“Fast and Furious 2” and “Fast and Furious” - similar actors, similar genre, similar tags, ...). However, this method will not be able to recommend related objects: cheese and wine. Another disadvantage of this method is the fact that it takes quite a bit of effort to mark all objects available on the service.
At the same time, almost every service logs information about which user has viewed / bought / clicked which object. This information is sufficient for building LDCs, which will allow recommending both similar and related objects.
')
Under the cat, the method of associations is described, which allows to build non-personalized recommendations based only on the data on actions on objects. In the same place the code on Python, allowing to apply a method for a large amount of data.
To begin, consider the basic algorithm for building non-personalized recommendations. Suppose we have objects — movies and users. Users are watching movies. Our initial data is the sparse matrix D (movies x users). If user u has watched the movie f, then in the corresponding cell of the matrix D is 1.
In order to find films that are similar to a given movie f, it is necessary to know the similarity of the movie f with all other films. The similarity data is stored in the S matrix (movies x movies).
The basic algorithm for building non-personalized recommendations is as follows:
From what has been described it is clear that the recommendations and their quality depend only on the method of constructing the matrix S, and to be more precise, on the method of determining the similarity of the two films.
How to determine the similarity of films x and y, if they looked a lot of users X and Y, respectively? The simplest solution is the Jacquard coefficient , which calculates the similarity of two objects (x and y) as:
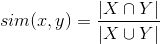
Here the numerator is the number of users who viewed both movie x and movie y. The denominator is the number of users who viewed either the movie x or the movie y.
The calculated value is symmetrical: x is similar to y as well as y is similar to x. If we want to make the coefficient asymmetric, then we can change the formula to the following:
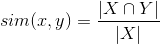
At first glance, this method is ideal: it increases the value of the similarity of films that are watched together, and normalizes the metric relative to the number of users who watched the movie.
Consider the above formula for the case when the object y is very popular (for example, a Harry Potter film). Since the film is very popular and watched by many people, sim (x, y) will tend to 1 for almost all x films. This means that the movie y will be similar to all movies, and this is in most cases bad. Hardly "Harry Potter" will be similar to the film "Green Elephant".
The Harry Potter Problem is also called the banana trap. Suppose a certain store is trying to increase profits by recommending goods to the buyer, which they often take along with what the buyer intends to buy. One of the most purchased items at the grocery store are bananas. Using the formula above, the system will recommend all buyers to purchase bananas. Bananas will be bought - all is well. But these are bad recommendations, since bananas would be bought without recommendations. When recommending bananas, we reduce profits by at least one successfully recommended product that is different from bananas.
Obviously, the formula must be modified so that the object x makes the object y more attractive. Those. It is necessary to take into account not only that the objects x and y take together, but also the fact that the object x is not taken without y.
Modify the formula of similarity as follows:
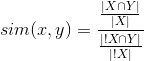
Here! X is the set of users who have not watched the movie x. If y is a very popular object, then the denominator in the formula will be large. Then the similarity value will be less, and the recommendations will be more relevant. This method is called the association method.
To compare the work of the method of associations and the Jacquard coefficient, we consider the search for similar films using these two methods according to the following initial data.
The similarity matrix, constructed using the asymmetric Jacquard coefficient, looks as follows (we reset the diagonal in order not to recommend the original film):
The similarity matrix for the method of associations will look as follows (in addition to the diagonal we zero infinity - cases where 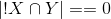 ).
).
As can be seen from the matrix of similarity, the method of associations allows to take into account the superpopularity of the film “Harry Potter and the Philosopher’s Stone”. When building associations with the Hobbit: An Unexpected Journey, the weight of Harry Potter (1.5) will be less than the weight of the more relevant movie The Hobbit: The Desolation of Smaug (2).
Below is a function for building a similarity matrix based on the association method. The function is written in Python using scipy and scikit-learn. This implementation allows you to quickly and inexpensively calculate the matrix of similarity for a large amount of source data.
Since within a single row of the matrix the values | X | and |! X | do not change, and similar objects will be within one line, then | X | and |! X | were omitted when calculating association metrics. The final metric formula looks like this:
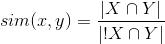
The association method is just one way of building non-personalized recommendations. As with any other method, before applying it you need to solve a number of issues:
- determine the minimum amount of data for which the method can be applied;
- determine the threshold value of the association metric;
- to determine what to do if the recommended metrics value of the association metrics is less than the threshold value;
- etc.
From the above it follows that the association method may not be applied to all objects. Therefore, it is worth combining with one or more methods of building non-personalized recommendations. This approach will allow you to create good recommendations regardless of the amount of data about the user or object.
PS Successful recommendations!
It is possible to recommend similar / related objects, focusing on knowledge about objects (properties, tags, parameters) or on knowledge of actions related to objects (purchases, views, clicks). The advantage of the first method is that it allows you to accurately determine objects with similar properties (“Fast and Furious 2” and “Fast and Furious” - similar actors, similar genre, similar tags, ...). However, this method will not be able to recommend related objects: cheese and wine. Another disadvantage of this method is the fact that it takes quite a bit of effort to mark all objects available on the service.
At the same time, almost every service logs information about which user has viewed / bought / clicked which object. This information is sufficient for building LDCs, which will allow recommending both similar and related objects.
')
Under the cat, the method of associations is described, which allows to build non-personalized recommendations based only on the data on actions on objects. In the same place the code on Python, allowing to apply a method for a large amount of data.
Building non-personalized recommendations
To begin, consider the basic algorithm for building non-personalized recommendations. Suppose we have objects — movies and users. Users are watching movies. Our initial data is the sparse matrix D (movies x users). If user u has watched the movie f, then in the corresponding cell of the matrix D is 1.
In order to find films that are similar to a given movie f, it is necessary to know the similarity of the movie f with all other films. The similarity data is stored in the S matrix (movies x movies).
The basic algorithm for building non-personalized recommendations is as follows:
- for a given movie f, find the corresponding row R in the matrix S;
- choose from the line R the set of the most similar to f films - FR;
- FR and there are non-resonalized recommendations (similar / related).
Similarity method
From what has been described it is clear that the recommendations and their quality depend only on the method of constructing the matrix S, and to be more precise, on the method of determining the similarity of the two films.
How to determine the similarity of films x and y, if they looked a lot of users X and Y, respectively? The simplest solution is the Jacquard coefficient , which calculates the similarity of two objects (x and y) as:
Here the numerator is the number of users who viewed both movie x and movie y. The denominator is the number of users who viewed either the movie x or the movie y.
The calculated value is symmetrical: x is similar to y as well as y is similar to x. If we want to make the coefficient asymmetric, then we can change the formula to the following:
At first glance, this method is ideal: it increases the value of the similarity of films that are watched together, and normalizes the metric relative to the number of users who watched the movie.
"The Harry Potter Problem" or "Banana Trap"
Consider the above formula for the case when the object y is very popular (for example, a Harry Potter film). Since the film is very popular and watched by many people, sim (x, y) will tend to 1 for almost all x films. This means that the movie y will be similar to all movies, and this is in most cases bad. Hardly "Harry Potter" will be similar to the film "Green Elephant".
The Harry Potter Problem is also called the banana trap. Suppose a certain store is trying to increase profits by recommending goods to the buyer, which they often take along with what the buyer intends to buy. One of the most purchased items at the grocery store are bananas. Using the formula above, the system will recommend all buyers to purchase bananas. Bananas will be bought - all is well. But these are bad recommendations, since bananas would be bought without recommendations. When recommending bananas, we reduce profits by at least one successfully recommended product that is different from bananas.
Association method
Obviously, the formula must be modified so that the object x makes the object y more attractive. Those. It is necessary to take into account not only that the objects x and y take together, but also the fact that the object x is not taken without y.
Modify the formula of similarity as follows:
Here! X is the set of users who have not watched the movie x. If y is a very popular object, then the denominator in the formula will be large. Then the similarity value will be less, and the recommendations will be more relevant. This method is called the association method.
Method comparison
To compare the work of the method of associations and the Jacquard coefficient, we consider the search for similar films using these two methods according to the following initial data.
| movies \ users | BUT | B | C | D | E |
|---|---|---|---|---|---|
| 1. Harry Potter and the Sorcerer's Stone | one | one | one | one | one |
| 2. The Hobbit: An Unexpected Journey | one | one | one | ||
| 3. The Hobbit: The Desolation of Smaug | one | one | one | ||
| 4. Chronicles of Narnia: Prince Caspian | one | ||||
| 5. Dragon Heart | one |
| movies \ films | one | 2 | 3 | four | five |
|---|---|---|---|---|---|
| one | 0 | 0.6 | 0.6 | 0.2 | 0.2 |
| 2 | one | 0 | 0.667 | 0 | 0.333 |
| 3 | one | 0.667 | 0 | 0 | 0 |
| four | one | 0 | 0 | 0 | 0 |
| five | one | one | 0 | 0 | 0 |
).| movies \ films | one | 2 | 3 | four | five |
|---|---|---|---|---|---|
| one | 0 | 0 | 0 | 0 | 0 |
| 2 | 1.5 | 0 | 2 | 0 | 0 |
| 3 | 1.5 | 2 | 0 | 0 | 0 |
| four | 0.25 | 0 | 0 | 0 | 0 |
| five | 0.25 | 0.5 | 0 | 0 | 0 |
Implementation
Below is a function for building a similarity matrix based on the association method. The function is written in Python using scipy and scikit-learn. This implementation allows you to quickly and inexpensively calculate the matrix of similarity for a large amount of source data.
Since within a single row of the matrix the values | X | and |! X | do not change, and similar objects will be within one line, then | X | and |! X | were omitted when calculating association metrics. The final metric formula looks like this:
def get_item_item_association_matrix(sp_matrix): """ :param sp_matrix: ( x ) :return: ( x ) """ watched_x_and_y = sp_matrix.dot(sp_matrix.T).tocsr() watched_x = csr_matrix(sp_matrix.sum(axis=1)) magic = binarize(watched_x_and_y).multiply(watched_x.T) watched_not_x_and_y = magic - watched_x_and_y rows, cols = watched_not_x_and_y.nonzero() data_in_same_pos = watched_x_and_y[rows, cols].A.reshape(-1) return csr_matrix((data_in_same_pos / watched_not_x_and_y.data, (rows, cols)), watched_x_and_y.shape) Conclusion
The association method is just one way of building non-personalized recommendations. As with any other method, before applying it you need to solve a number of issues:
- determine the minimum amount of data for which the method can be applied;
- determine the threshold value of the association metric;
- to determine what to do if the recommended metrics value of the association metrics is less than the threshold value;
- etc.
From the above it follows that the association method may not be applied to all objects. Therefore, it is worth combining with one or more methods of building non-personalized recommendations. This approach will allow you to create good recommendations regardless of the amount of data about the user or object.
PS Successful recommendations!
Source: https://habr.com/ru/post/247813/
All Articles