How lazy calculations work
Little Lambda decided that cleaning the room can be postponed until later.
Lazy computing is a commonly used technique in computer execution of Haskell programs. They make our code simpler and more modular, but they can also cause confusion, especially when it comes to memory usage, becoming a common trap for newbies. For example, a harmless looking expression
In this tutorial, I want to explain how lazy calculations work and what they mean for the execution time and the amount of memory expended by Haskell programs. I will begin the story with the fundamentals of graph reduction, and then I will proceed to discussing the strict left convolution - the simplest example for understanding and eliminating memory leaks.
')
The topic of lazy computing has been addressed in many textbooks (for example, in Simon Thompson ’s book "Haskell - The Craft of Functional Programming" ), but information about them seems to be still problematic to find on the net. I hope my guide will help solve this problem.
Lazy computing is a tradeoff. On the one hand, they help us make the code more modular. On the other hand, it is sometimes impossible to fully understand how the calculation takes place in a particular program - there are always some slight differences between reality and what you think about it. At the end of the article I will give recommendations on how to deal with situations of this kind. So let's get started!
Running Haskell programs means evaluating expressions. The basic idea behind this is called applying a function . Let function be given
We can calculate the expression
replacing
Two functions are used here:
Please note that in this case we have to calculate
To avoid unnecessary duplication, we use a method called “ graph reduction ”. Generally speaking, any expression can be represented as a graph. For our example, it looks like this:
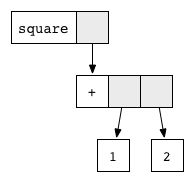
Each block corresponds to the use of the corresponding function, whose name is written on a white field, and gray fields indicate arguments. This graphic notation is similar to how the compiler actually represents an expression with pointers to memory cells.
Each function defined by the programmer corresponds to a reduction rule . For example, the rule for
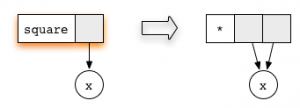
Circled
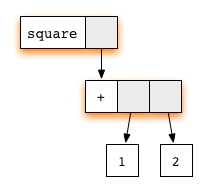
Any subgraph that matches the rule is called a reducible expression or redex for short. Wherever we meet redex, it can be shortened and updated the selected rectangle corresponding to the rule. In our example, there are two Redexes: you can reduce either the
If we start with redex
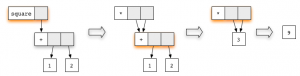
At each step, the redex, highlighted in color, is updated. On the penultimate graph, a new redex appears, which is related to the multiplication rule. By completing this reduction, we get the final result
If the expression (graph) does not contain redexes, i.e. nothing can be cut in it, then the deed is done. When this happens, we say that the expression is in normal form . This is the final result of the calculation. In the previous example, the normal form was the single number represented by the graph.

But constructors like
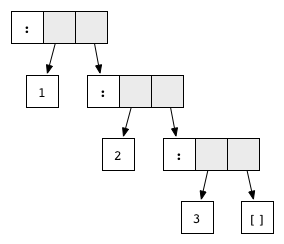
The normal form of the list is
Generally speaking, there are two more requirements for the graph so that it can be called to be in normal form. First, it must be finite , and second, it must not have cycles . The opposite of these conditions is sometimes found during recursion. For example, an expression defined as
correlated with cyclic graph
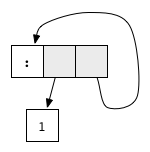
It has no redexes, but is not in normal form: the tail of the list recursively points to the list itself, resulting in an infinite loop.
In Haskell, we usually do not display the normal form completely. Moreover, most often we stop when the graph reaches a weak head normal form (WHNF). A graph is said to be in WHNF if its topmost node is a constructor . For example, the expression
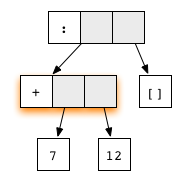
is located in WHNF because its top node is the list constructor
On the other hand, any graph that is not in the WHNF is called an uncalculated expression or converter . An expression that begins with a constructor is in the WHNF, but its arguments may easily not be computed.
A very interesting example of a graph in WHNF is the graph of the
Often an expression contains several redexes. How important is the sequence in which we will shorten them?
One of the reduction orders, called energetic calculation , calculates the function's arguments to their normal form before reducing it. This strategy is used in most programming languages.
However, Haskell compilers typically use a different order of computation, called lazy , when the topmost application of a function is reduced primarily. In this case, it may be necessary to calculate some arguments, but only in the required quantity. Consider a function defined by several equations using pattern matching. For each of them, the arguments will be calculated from left to right until their top node contains a constructor corresponding to the pattern. If the comparison is made with a regular variable, then the arguments are not evaluated. If the sample is a constructor, then this means a calculation before the WHNF.
Hopefully, an example will make this concept clearer. Let given function
It is represented by two reduction rules depending on the value of the first argument:
Now consider the expression
represented as
Both arguments in it are redexes. The first equation of the function
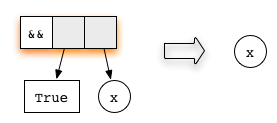
The second argument is not evaluated, since the topmost application of the function is already redex. Lazy evaluation always starts reduction from the topmost node, which we will do using the rule for the

This expression is in normal form - therefore, everything is ready!
Note that if you reduce the application
In the general case, the normal form obtained with the help of lazy calculations never differs from the result of executing the same expression by their energetic counterpart. So in this sense, it does not matter in what order the reduction occurs. However, lazy calculations are performed in fewer steps and can deal with cyclical (infinite) graphs, which is not available for energetic calculations.
I hope the visual representation of expressions in the form of graphs helped you to get a general idea of lazy calculations, since it clearly emphasizes the concept of redex and the necessary reduction order. However, for specific calculations, drawing pictures is somewhat burdensome. To track the reduction process, we usually work with a textual representation using Haskell syntax.
Graphs make it easier to visualize common subgraphs. In the text view, we need to denote common expressions by giving them names using the
The
Our second example - logical AND - turns into
In this case, there is no need to share any subexpression, so the
From now on, we will use only the textual representation.
Let us now consider how the use of lazy calculations affects the running time and the memory required by Haskell programs. If until now you dealt only with energetic calculations, then get ready for surprises (especially when it comes to memory).
How many steps does the expression evaluation take? For energetic calculations, the answer is simple: for each application of a function, we add the time required to calculate its arguments with the time required to perform the function body itself. But what about lazy computing? Fortunately, the situation is favorable. We have the following upper limit:
Theorem : Lazy calculations never take more computational steps than vigorous calculations.
This means that during the analysis of the execution time of the algorithm, we can always pretend that the arguments are calculated "energetically". For example, you can transliterate the sorting code in Haskell and be sure that the result will have the same (and sometimes the best) algorithmic complexity as its energetic twin.
However, the implementation of lazy computing requires certain administrative costs. For applications with high performance, like image processing or digital simulations, it is beneficial to “not be lazy” and stay closer to the hardware. Otherwise, the mantra "simple and modular code" leads us to lazy calculations. For example, optimizing the compiler called " thread merging " aims to improve the performance of array operations, as with a modular, list-like interface. This idea is embodied in the vector library.
Unfortunately, the situation with the use of memory is not as simple as over time. The essence of the problem lies in the fact that the amount of memory required by an uncalculated expression may differ significantly from the volume occupied by its normal form. The expression uses the more space the more nodes the graph contains. For example,
will take up more storage than its normal form
whose more familiar syntax looks like
When a variant with an uncalculated expression goes out of control, a memory leak occurs. The solution here will be to control the entire calculation process to ensure its completion as quickly as possible. Haskell has a combinator for this purpose.
As suggested by a type declaration, essentially it simply returns its second argument and behaves more like a function
Consider a typical example showing how to use
For reference: the foldl function is defined in the Haskell Prelude as
The calculation process is as follows:
As you can see, the accumulating parameter grows from branch to branch — a memory leak occurs. To avoid it, you need a guarantee that the battery is always in the WHNF. The next version of
It can be found in the Data.List module. Now the calculation process looks like this:
During the evaluation, the expression has a constant size. Using
As a rule, the
By the way, please note that in a language with energetic calculations for the problem of summing digits from
Another important lesson that can be learned from the task at hand is the following: in fact, the calculation that I showed is not exactly the case. If we define an enumeration list
then the reduction in WHNF will actually look like this:
those. the new first argument is not
In principle, I talked about this for so long in order to draw a simple conclusion: with lazy calculations, it is not possible to trace the trace in detail, except for very simple examples. Thus, analyzing the memory usage of Haskell programs is not an easy task. My advice: do something only in cases where there is a clear memory leak. For this, I would recommend using profiling tools to figure out what is happening. After the problem has been formulated, tools like space and
That's all I wanted to tell you about lazy computing and memory usage. There is one more important example of a leak that I did not mention, but which is no less important:
The expression
Lazy computing is a commonly used technique in computer execution of Haskell programs. They make our code simpler and more modular, but they can also cause confusion, especially when it comes to memory usage, becoming a common trap for newbies. For example, a harmless looking expression
foldl (+) 0 [1..10^8] In this tutorial, I want to explain how lazy calculations work and what they mean for the execution time and the amount of memory expended by Haskell programs. I will begin the story with the fundamentals of graph reduction, and then I will proceed to discussing the strict left convolution - the simplest example for understanding and eliminating memory leaks.
')
The topic of lazy computing has been addressed in many textbooks (for example, in Simon Thompson ’s book "Haskell - The Craft of Functional Programming" ), but information about them seems to be still problematic to find on the net. I hope my guide will help solve this problem.
Lazy computing is a tradeoff. On the one hand, they help us make the code more modular. On the other hand, it is sometimes impossible to fully understand how the calculation takes place in a particular program - there are always some slight differences between reality and what you think about it. At the end of the article I will give recommendations on how to deal with situations of this kind. So let's get started!
Basics: graph reduction
Expressions, graphs and redexes
Running Haskell programs means evaluating expressions. The basic idea behind this is called applying a function . Let function be given
square x = x*x We can calculate the expression
square (1+2), replacing
square on the left side of the definition with its right side until we get the value of the variable x for the current argument. square (1+2) => (1+2)*(1+2) Two functions are used here:
+ and * (1+2)*(1+2) => 3*(1+2) => 3*3 => 9 Please note that in this case we have to calculate
(1+2) twice. However, it is clear that in fact the answers are the same, since both expressions are associated with the same argument x .To avoid unnecessary duplication, we use a method called “ graph reduction ”. Generally speaking, any expression can be represented as a graph. For our example, it looks like this:
Each block corresponds to the use of the corresponding function, whose name is written on a white field, and gray fields indicate arguments. This graphic notation is similar to how the compiler actually represents an expression with pointers to memory cells.
Each function defined by the programmer corresponds to a reduction rule . For example, the rule for
square looks like this:Circled
x replaces the subgraph. Note that both arguments to the multiplication function point to the same subgraph. Such a way of its general use is the key to the absence of duplication.Any subgraph that matches the rule is called a reducible expression or redex for short. Wherever we meet redex, it can be shortened and updated the selected rectangle corresponding to the rule. In our example, there are two Redexes: you can reduce either the
square function or addition (+) .If we start with redex
square , and then continue the calculation with the redex addition, we get the chainAt each step, the redex, highlighted in color, is updated. On the penultimate graph, a new redex appears, which is related to the multiplication rule. By completing this reduction, we get the final result
9 .Normal form and weak header normal form
If the expression (graph) does not contain redexes, i.e. nothing can be cut in it, then the deed is done. When this happens, we say that the expression is in normal form . This is the final result of the calculation. In the previous example, the normal form was the single number represented by the graph.
But constructors like
Just , Nothing or list constructors : and [] also reduced to normal form. At the same time, they look like functions, but since they are represented by the data declaration and do not have the right part, there is no reduction rule for them. For example, the graphThe normal form of the list is
1:2:3:[] .Generally speaking, there are two more requirements for the graph so that it can be called to be in normal form. First, it must be finite , and second, it must not have cycles . The opposite of these conditions is sometimes found during recursion. For example, an expression defined as
ones = 1 : ones correlated with cyclic graph
It has no redexes, but is not in normal form: the tail of the list recursively points to the list itself, resulting in an infinite loop.
In Haskell, we usually do not display the normal form completely. Moreover, most often we stop when the graph reaches a weak head normal form (WHNF). A graph is said to be in WHNF if its topmost node is a constructor . For example, the expression
(7+12):[] oris located in WHNF because its top node is the list constructor
(:) . And this is not a normal form, since the first argument contains redex.On the other hand, any graph that is not in the WHNF is called an uncalculated expression or converter . An expression that begins with a constructor is in the WHNF, but its arguments may easily not be computed.
A very interesting example of a graph in WHNF is the graph of the
ones function mentioned above. In the end, its uppermost element is the constructor. In Haskell, we can create and manipulate endless lists! They are great for making code more modular.The order of calculations, lazy calculations
Often an expression contains several redexes. How important is the sequence in which we will shorten them?
One of the reduction orders, called energetic calculation , calculates the function's arguments to their normal form before reducing it. This strategy is used in most programming languages.
However, Haskell compilers typically use a different order of computation, called lazy , when the topmost application of a function is reduced primarily. In this case, it may be necessary to calculate some arguments, but only in the required quantity. Consider a function defined by several equations using pattern matching. For each of them, the arguments will be calculated from left to right until their top node contains a constructor corresponding to the pattern. If the comparison is made with a regular variable, then the arguments are not evaluated. If the sample is a constructor, then this means a calculation before the WHNF.
Hopefully, an example will make this concept clearer. Let given function
(&&) , which implements the logical I. Its definition is as follows: (&&) :: Bool -> Bool -> Bool True && x = x False && x = False It is represented by two reduction rules depending on the value of the first argument:
True or False .Now consider the expression
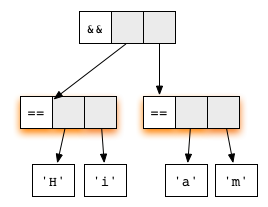
('H' == 'i') && ('a' == 'm') represented as
Both arguments in it are redexes. The first equation of the function
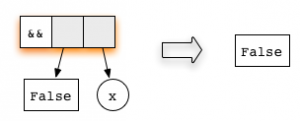
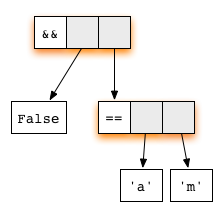
(&&) checks whether the first argument matches the constructor True . Thus, a lazy evaluation begins with the reduction of the first argument:The second argument is not evaluated, since the topmost application of the function is already redex. Lazy evaluation always starts reduction from the topmost node, which we will do using the rule for the
(&&) function. Will getThis expression is in normal form - therefore, everything is ready!
Note that if you reduce the application
(&&) as quickly as possible, you will never need to look for the value of the second argument, which will reduce the overall time cost. Some imperative languages use a similar trick, called " short - circuited computation ." However, usually this functionality is “stitched” into the language and works only for logical operations. In Haskell, this method can be applied to all functions - it is just a sequence of lazy calculations.In the general case, the normal form obtained with the help of lazy calculations never differs from the result of executing the same expression by their energetic counterpart. So in this sense, it does not matter in what order the reduction occurs. However, lazy calculations are performed in fewer steps and can deal with cyclical (infinite) graphs, which is not available for energetic calculations.
Text view
I hope the visual representation of expressions in the form of graphs helped you to get a general idea of lazy calculations, since it clearly emphasizes the concept of redex and the necessary reduction order. However, for specific calculations, drawing pictures is somewhat burdensome. To track the reduction process, we usually work with a textual representation using Haskell syntax.
Graphs make it easier to visualize common subgraphs. In the text view, we need to denote common expressions by giving them names using the
let keyword. For example, our very first example of reducing the square (1+2) expression would look like this: square (1+2) => let x = (1+2) in x*x => let x = 3 in x*x => 9 The
let … in syntax allows you to make the general expression x = (1+2) . Notice that the lazy evaluation first reduces the square function, and only then calculates the argument x .Our second example - logical AND - turns into
('H' == 'i') && ('a' == 'm') => False && ('a' == 'm') => False In this case, there is no need to share any subexpression, so the
let keyword is not in the code.From now on, we will use only the textual representation.
Time & Memory
Let us now consider how the use of lazy calculations affects the running time and the memory required by Haskell programs. If until now you dealt only with energetic calculations, then get ready for surprises (especially when it comes to memory).
Time
How many steps does the expression evaluation take? For energetic calculations, the answer is simple: for each application of a function, we add the time required to calculate its arguments with the time required to perform the function body itself. But what about lazy computing? Fortunately, the situation is favorable. We have the following upper limit:
Theorem : Lazy calculations never take more computational steps than vigorous calculations.
This means that during the analysis of the execution time of the algorithm, we can always pretend that the arguments are calculated "energetically". For example, you can transliterate the sorting code in Haskell and be sure that the result will have the same (and sometimes the best) algorithmic complexity as its energetic twin.
However, the implementation of lazy computing requires certain administrative costs. For applications with high performance, like image processing or digital simulations, it is beneficial to “not be lazy” and stay closer to the hardware. Otherwise, the mantra "simple and modular code" leads us to lazy calculations. For example, optimizing the compiler called " thread merging " aims to improve the performance of array operations, as with a modular, list-like interface. This idea is embodied in the vector library.
Memory
Unfortunately, the situation with the use of memory is not as simple as over time. The essence of the problem lies in the fact that the amount of memory required by an uncalculated expression may differ significantly from the volume occupied by its normal form. The expression uses the more space the more nodes the graph contains. For example,
((((0 + 1) + 2) + 3) + 4) will take up more storage than its normal form
10 . An expression like enumFromTo 1 1000 whose more familiar syntax looks like
[1..1000] . This application of the function consists of only three nodes, which takes up considerably less memory than the 1:2:3:…:1000:[] list, containing at least one thousand elements.When a variant with an uncalculated expression goes out of control, a memory leak occurs. The solution here will be to control the entire calculation process to ensure its completion as quickly as possible. Haskell has a combinator for this purpose.
seq :: a -> b -> b As suggested by a type declaration, essentially it simply returns its second argument and behaves more like a function
const . However, the seq xy expression will first calculate x before the WHNF, after which we will continue to work with y . Conversely, in const xy second argument y not affected at all, and x calculated without delay.Consider a typical example showing how to use
seq , and which every Haskell programmer should know: a strict left convolution . Let the task be given to sum all the numbers from 1 to 100 . We will do this using the accumulating parameter, i.e. as in the left convolution foldl (+) 0 [1..100] For reference: the foldl function is defined in the Haskell Prelude as
foldl :: (a -> b -> a) -> a -> [b] -> a foldl fa [] = a foldl fa (x:xs) = foldl f (fax) xs The calculation process is as follows:
foldl (+) 0 [1..100] => foldl (+) 0 (1:[2..100]) => foldl (+) (0 + 1) [2..100] => foldl (+) (0 + 1) (2:[3..100]) => foldl (+) ((0 + 1) + 2) [3..100] => foldl (+) ((0 + 1) + 2) (3:[4..100]) => foldl (+) (((0 + 1) + 2) + 3) [4..100] => … As you can see, the accumulating parameter grows from branch to branch — a memory leak occurs. To avoid it, you need a guarantee that the battery is always in the WHNF. The next version of
foldl does this trick: foldl' :: (a -> b -> a) -> a -> [b] -> a foldl' fa [] = a foldl' fa (x:xs) = let a' = fax in seq a' (foldl' fa' xs) It can be found in the Data.List module. Now the calculation process looks like this:
foldl' (+) 0 [1..100] => foldl' (+) 0 (1:[2..100]) => let a' = 0 + 1 in seq a' (foldl' (+) a' [2..100]) => let a' = 1 in seq a' (foldl' (+) a' [2..100]) => foldl' (+) 1 [2..100] => foldl' (+) 1 (2:[3..100]) => let a' = 1 + 2 in seq a' (foldl' (+) a' [3..100]) => let a' = 3 in seq a' (foldl' (+) a' [3..100]) => foldl' (+) 3 [3..100] => … During the evaluation, the expression has a constant size. Using
seq ensures that the WHNF accumulative parameter is removed before the next list item is considered.As a rule, the
foldl function foldl prone to memory leaks, so it’s better to use foldl' or foldr instead.By the way, please note that in a language with energetic calculations for the problem of summing digits from
1 to 100 you can never write code like the one above. In fact, in this case, the list [1..100] will first be calculated to the normal form, which takes as much memory space as the ineffective version of the foldl . If you want to solve the problem effectively, then you need to write a recursive cycle. But in Haskell, lazy calculations allow you to do this by using one general-purpose combinator for the list [1..100] , which is calculated “on demand”. This is another example of how code can be made more modular.Another important lesson that can be learned from the task at hand is the following: in fact, the calculation that I showed is not exactly the case. If we define an enumeration list
[n..m] as enumFromTo nm = if n < m then n : enumFromTo (n+1) m else [] then the reduction in WHNF will actually look like this:
[1..100] => 1 : [(1+1)..100] those. the new first argument is not
2 , but the expression (1+1) . Not that there was a big difference, but keep in mind: you have to be very careful when tracing lazy calculations accurately - they never do exactly as you imagine. The actual code for enumFromTo is slightly different from the one shown above. In particular, note that [1..] is constructed as a list of numbers that are not in the WHNF.In principle, I talked about this for so long in order to draw a simple conclusion: with lazy calculations, it is not possible to trace the trace in detail, except for very simple examples. Thus, analyzing the memory usage of Haskell programs is not an easy task. My advice: do something only in cases where there is a clear memory leak. For this, I would recommend using profiling tools to figure out what is happening. After the problem has been formulated, tools like space and
seq invariants can guarantee the calculation of the corresponding expressions in WHNF, regardless of the fine details of performing lazy calculations.That's all I wanted to tell you about lazy computing and memory usage. There is one more important example of a leak that I did not mention, but which is no less important:
let small' = fst (small, large) in … small' … The expression
small' retains a reference to the large expression even when it is dropped by the fst function. Perhaps you should somehow calculate the small' expression in the WHNF so that you can easily use the memory occupied by large .Source: https://habr.com/ru/post/247213/
All Articles