Playing with genetic algorithms
One Saturday evening in December, I sat on the book The Blind Watchmaker (Blind Watchmaker), as I caught the eye of an incredibly interesting experiment: take any sentence, such as the Shakespearean string: Methinks it is like a weasel and a random string of the same length: wdltmnlt dtjbkwirzrezlmqco p and let's start making random changes to it. After how many generations, this random string will turn into a Shakespearean string, if only descendants more similar to Shakespeare's will survive?
Today we will repeat this experiment, but on a completely different scale.

')
The structure of the article:
Caution traffic!
In the field of artificial intelligence, a genetic algorithm implies a heuristic of search for solutions based on natural selection. As a rule, it is used for tasks where the search space is so huge that an exact solution cannot be found and the heuristic solution satisfies the requirements. The task itself has a certain solution quality function that needs to be maximized.
In its simplest form, the genetic algorithm has the following structure (see diagram): we start with some solution, in our case, this is a random string; we introduce mutations, for example, we change a randomly selected letter in a string to a randomly selected letter and get a new set of strings ( k mutations per string); of them, we select only those that are closer to Shakespeare (by the number of matching characters), for example, 10 such lines, if there is no Shakespeare among them, then we start the process again.
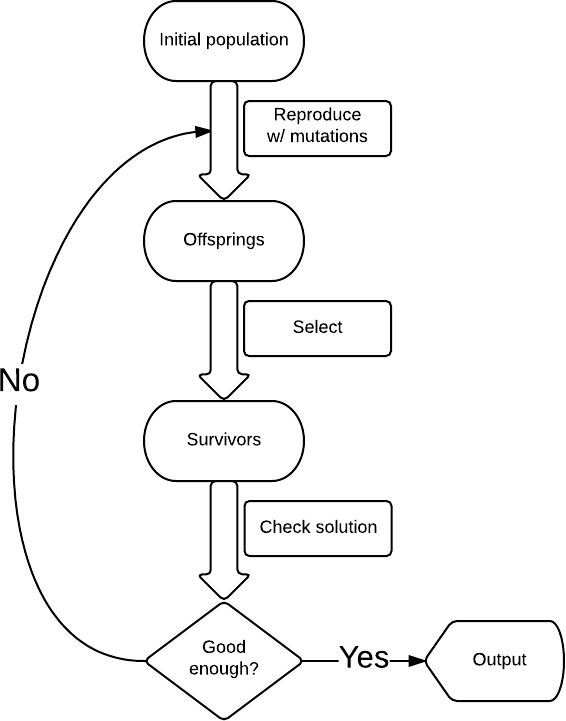
In many respects, genetic algorithms are similar to classical optimization methods, a population is a set of current points, mutations are a study of neighboring points, selection is a choice of new points for finding a solution in conditions of limited computing resources.
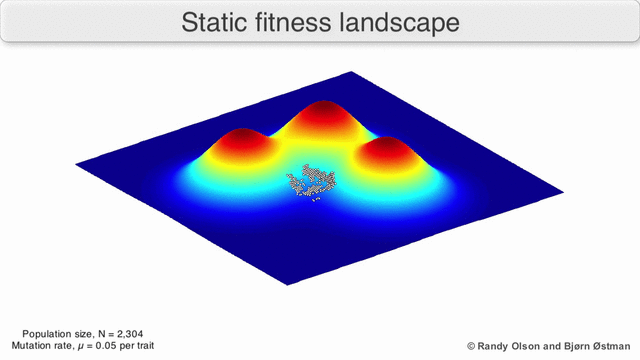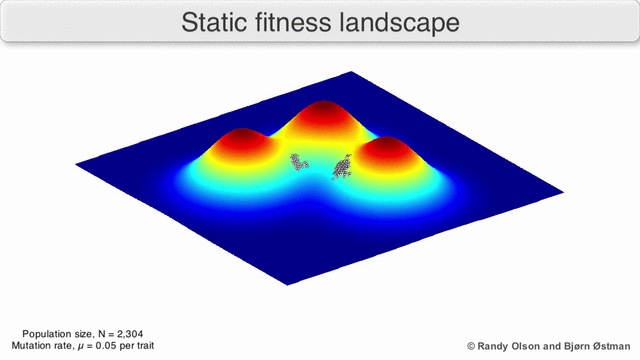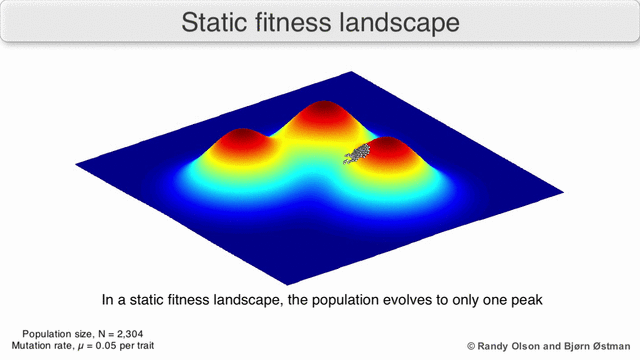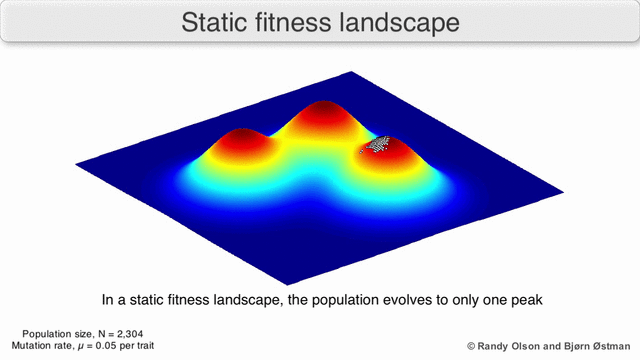
The population always tends to the nearest maximum, since we select the current search points as having the maximum value (all other points will die, they will not compete with the nearest maximum). Since the size of the population is significant, and therefore the probability of taking at least one step towards the maximum is not negligible, then after a certain number of steps the population will shift towards the local maximum. And the descendants of the point shifted closer to the maximum have a greater "survival". So after a sufficient number of steps, the descendants of this point will begin to dominate the population and it will all shift to the maximum.
Visualization of a population tending to a local maximum:
(due to randy olson )
Input : string S
Output : a natural number N , equal to the number of generations required to convert a random string of length len ( S ) to a string S
What is mutation in our case? By a mutation of string S, we mean replacing one randomly selected character from string S with another arbitrary character of the alphabet. In this task we use only Latin lowercase characters and a space.
What is the initial population (initial population in the scheme)? This is a random string equal in length to the input string S.
What are offsprings? Suppose we fixed the number of mutations per line per constant k , then descendants are k mutations of each line of the current generation.
What are survivors ? Suppose we fixed the population size by a constant h , then the survivors are h lines as similar as possible to the input string S.
In pseudocode (suspiciously similar to python), it looks like this:

Consider the following line: The quick brown fox jumps over the lazy dog and reproduce the output of our program for it:
Consider the chain of changes (on the left is the generation number):
As we see, each generation differs by no more than one symbol from each other. It took a total of 46 generations to get from rbbzmffwfhwtxnjjiozz ujhhlxeoyhezarquvmopyk to the quick brown fox jumps over the lazy dog through mutations and selection.
Individual examples, Shakespeare's string or English pro-fox pangram , are interesting, but not too convincing. Therefore, I decided to consider a more interesting question: what would happen if we take a pair of classical works, break them up into sentences and count the number of generations for each of them? What will be the nature of the dependence of the number of generations on a line (for example, on its length)?
As a classic, I chose To Kill a Mocking Bird by Harper Lee (Kill a Mockingbird, Harper Lee) and Catcher in the Rye by JD Salinger (Over the Abyss of Rye, JD Salinger). We will measure two parameters - the distribution of the number of generations by sentences and the dependence of the number of generations on the length of the string (is there a correlation?).
The parameters were as follows: the number of descendants of the string: 100; Number of survivors per generation: 10.
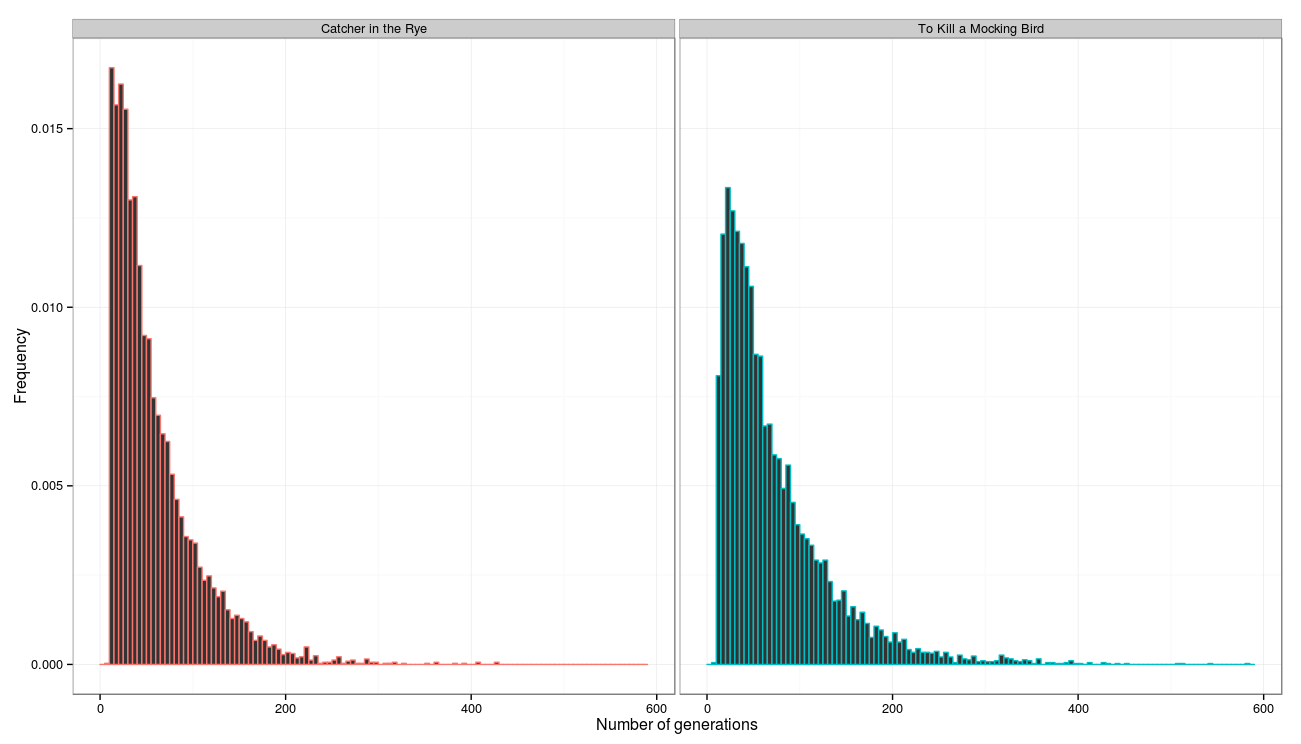
As we can see, for most of the proposals, it was possible to reach the line fairly quickly, less than 100 iterations were required, almost 200 iterations were enough for all the proposals (among all the proposals there was only one that required 1135 iterations, judging by the proposal, the breakdown algorithm was wrong and glued several sentences into one ):
The correlation between line length and the number of generations is ideal. This means that in almost every generation it was possible to move a step closer to the target line.
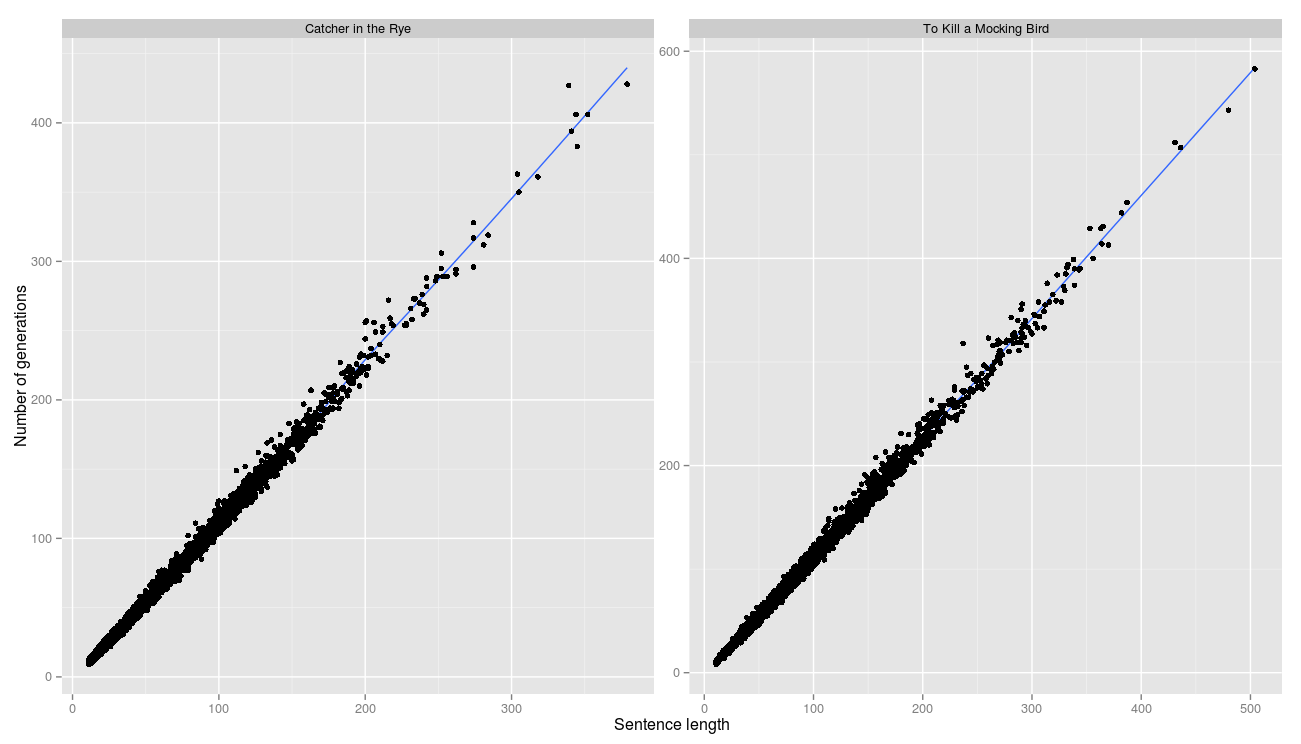
R ^ 2 is 0.996 and 0.997, respectively.
Thus, it was experimentally established that under the conditions of our problem for any input string S , the number of generations linearly depends on the length of the string, which is consistent with the initial assumptions.
All the code, python - the genetic algorithm \ text processing and R - visualization, is available on github:
github.com/SergeyParamonov/genetics-experiments
We dealt with the basic structure of genetic algorithms and applied to solving the problem of string mutation. As a result of experiments with classical texts, we found that in our conditions there is a linear relationship between the length of the line and the number of generations necessary to achieve the input line.
We also noted that the basic search structure can be modified (for example, using crossover — using several generation members to create descendants) to solve a wide class of optimization problems where it is too difficult to find an exact solution.
Today we will repeat this experiment, but on a completely different scale.
')
The structure of the article:
- What is a genetic algorithm?
- Why does it work
- We formalize a problem with a random string.
- An example of the algorithm
- Experiments with the classics
- Code and data
- findings
Caution traffic!
What is a genetic algorithm?
In the field of artificial intelligence, a genetic algorithm implies a heuristic of search for solutions based on natural selection. As a rule, it is used for tasks where the search space is so huge that an exact solution cannot be found and the heuristic solution satisfies the requirements. The task itself has a certain solution quality function that needs to be maximized.
In its simplest form, the genetic algorithm has the following structure (see diagram): we start with some solution, in our case, this is a random string; we introduce mutations, for example, we change a randomly selected letter in a string to a randomly selected letter and get a new set of strings ( k mutations per string); of them, we select only those that are closer to Shakespeare (by the number of matching characters), for example, 10 such lines, if there is no Shakespeare among them, then we start the process again.
Why does it work
In many respects, genetic algorithms are similar to classical optimization methods, a population is a set of current points, mutations are a study of neighboring points, selection is a choice of new points for finding a solution in conditions of limited computing resources.
The population always tends to the nearest maximum, since we select the current search points as having the maximum value (all other points will die, they will not compete with the nearest maximum). Since the size of the population is significant, and therefore the probability of taking at least one step towards the maximum is not negligible, then after a certain number of steps the population will shift towards the local maximum. And the descendants of the point shifted closer to the maximum have a greater "survival". So after a sufficient number of steps, the descendants of this point will begin to dominate the population and it will all shift to the maximum.
Visualization of a population tending to a local maximum:
(due to randy olson )
We formalize a problem with a random string.
Input : string S
Output : a natural number N , equal to the number of generations required to convert a random string of length len ( S ) to a string S
What is mutation in our case? By a mutation of string S, we mean replacing one randomly selected character from string S with another arbitrary character of the alphabet. In this task we use only Latin lowercase characters and a space.
What is the initial population (initial population in the scheme)? This is a random string equal in length to the input string S.
What are offsprings? Suppose we fixed the number of mutations per line per constant k , then descendants are k mutations of each line of the current generation.
What are survivors ? Suppose we fixed the population size by a constant h , then the survivors are h lines as similar as possible to the input string S.
In pseudocode (suspiciously similar to python), it looks like this:
An example of the algorithm
Consider the following line: The quick brown fox jumps over the lazy dog and reproduce the output of our program for it:
Consider the chain of changes (on the left is the generation number):
1 rbbzmffwfhwtxnjjiozz ujhhlxeoyhezarquvmopyk 2 rbbzmffwfhwtxnjjiozz ujhhlxeoyhezarquzmopyk 3 rbb mffwfhwtxnjjiozz ujhhlxeoyhezarquzmopyk 4 rbb mffwfhwtxnjjiozz ujhhlxeoyhezarquzmodyk 5 rbb mffwfhbtxnjjiozz ujhhlxeoyhezarquzmodyk 6 rbb mffcfhbtxnjjiozz ujhhlxeoyhezarquzmodyk 7 rbb mffcf btxnjjiozz ujhhlxeoyhezarquzmodyk 8 rbb mffcf btxnjjiozz ujhhlxeoyheza quzmodyk 9 rbb mffcf brxnjjiozz ujhhlxeoyheza quzmodyk 10 rbb mffcf brxnjjiozz ujphlxeoyheza quzmodyk 20 rbb mffcf bronj fox jujpslxveyheza luzmodyk 30 rbb mficf bronj fox jumps overhehe luzy dyg 40 he m ick bronn fox jumps over the lazy dog 41 he q ick bronn fox jumps over the lazy dog 42 he q ick bronn fox jumps over the lazy dog 43 he q ick brown fox jumps over the lazy dog 44 he quick brown fox jumps over the lazy dog 45 ahe quick brown fox jumps over the lazy dog 46 the quick brown fox jumps over the lazy dog
Full output
print_genes ("The quick brown fox jumps over the lazy dog")
1 rbbzmffwfhwtxnjjiozz ujhhlxeoyhezarquvmopyk
2 rbbzmffwfhwtxnjjiozz ujhhlxeoyhezarquzmopyk
3 rbb mffwfhwtxnjjiozz ujhhlxeoyhezarquzmopyk
4 rbb mffwfhwtxnjjiozz ujhhlxeoyhezarquzmodyk
5 rbb mffwfhbtxnjjiozz ujhhlxeoyhezarquzmodyk
6 rbb mffcfhbtxnjjiozz ujhhlxeoyhezarquzmodyk
7 rbb mffcf btxnjjiozz ujhhlxeoyhezarquzmodyk
8 rbb mffcf btxnjjiozz ujhhlxeoyheza quzmodyk
9 rbb mffcf brxnjjiozz ujhhlxeoyheza quzmodyk
10 rbb mffcf brxnjjiozz ujphlxeoyheza quzmodyk
11 rbb mffcf brxnj iozz ujphlxeoyheza quzmodyk
12 rbb mffcf brxnj ioz ujphlxeoyheza quzmodyk
13 rbb mffcf bronj ioz ujphlxeoyheza quzmodyk
14 rbb mffcf bronj ioz ujphlxeeyheza quzmodyk
15 rbb mffcf bronj ioz ujphlxeeyheza luzmodyk
16 rbb mffcf bronj ioz ujphlxveyheza luzmodyk
17 rbb mffcf bronj foz ujphlxveyheza luzmodyk
18 rbb mffcf bronj foz jujphlxveyheza luzmodyk
19 rbb mffcf bronj foz jujpslxveyheza luzmodyk
20 rbb mffcf bronj fox jujpslxveyheza luzmodyk
21 rbb mffcf bronj fox jujpslxveyheza luzm dyk
22 rbb mffcf bronj fox jujpslxverheza luzm dyk
23 rbb mffcf bronj fox jumpslxverheza luzm dyk
24 rbb mffcf bronj fox jumpslxverheha luzm dyk
25 rbb mffcf bronj fox jumpslxverhehe luzm dyk
26 rbb mffcf bronj fox jumps xverhehe luzm dyk
27 rbb mffcf bronj fox jumps xverhehe luzm dyg
28 rbb mffcf bronj fox jumps xverhehe luzy dyg
29 rbb mffcf bronj fox jumps overhehe luzy dyg
30 rbb mficf bronj fox jumps overhehe luzy dyg
31 rbb mficf bronj fox jumps overhehe lazy dyg
32 rbb mficf bronn fox jumps overhehe lazy dyg
33 rbb mficf bronn fox jumps over ehe lazy dyg
34 rhb mficf bronn fox jumps over ehe lazy dyg
35 hb mficf bronn fox jumps over ehe lazy dyg
36 hb mfick bronn fox jumps over ehe lazy dyg
37 hb m ick bronn fox jumps over ehe lazy dyg
38 hb m ick bronn fox jumps over ehe lazy dog
39 he m ick bronn fox jumps over ehe lazy dog
40 he m ick bronn fox jumps over the lazy dog
41 he q ick bronn fox jumps over the lazy dog
42 he q ick bronn fox jumps over the lazy dog
43 he q ick brown fox jumps over the lazy dog
44 he quick brown fox jumps over the lazy dog
45 ahe quick brown fox jumps over the lazy dog
46 the quick brown fox jumps over the lazy dog
As we see, each generation differs by no more than one symbol from each other. It took a total of 46 generations to get from rbbzmffwfhwtxnjjiozz ujhhlxeoyhezarquvmopyk to the quick brown fox jumps over the lazy dog through mutations and selection.
Experiments with the classics
Individual examples, Shakespeare's string or English pro-fox pangram , are interesting, but not too convincing. Therefore, I decided to consider a more interesting question: what would happen if we take a pair of classical works, break them up into sentences and count the number of generations for each of them? What will be the nature of the dependence of the number of generations on a line (for example, on its length)?
As a classic, I chose To Kill a Mocking Bird by Harper Lee (Kill a Mockingbird, Harper Lee) and Catcher in the Rye by JD Salinger (Over the Abyss of Rye, JD Salinger). We will measure two parameters - the distribution of the number of generations by sentences and the dependence of the number of generations on the length of the string (is there a correlation?).
The parameters were as follows: the number of descendants of the string: 100; Number of survivors per generation: 10.
results
As we can see, for most of the proposals, it was possible to reach the line fairly quickly, less than 100 iterations were required, almost 200 iterations were enough for all the proposals (among all the proposals there was only one that required 1135 iterations, judging by the proposal, the breakdown algorithm was wrong and glued several sentences into one ):
The correlation between line length and the number of generations is ideal. This means that in almost every generation it was possible to move a step closer to the target line.
R ^ 2 is 0.996 and 0.997, respectively.
Thus, it was experimentally established that under the conditions of our problem for any input string S , the number of generations linearly depends on the length of the string, which is consistent with the initial assumptions.
Code and data
All the code, python - the genetic algorithm \ text processing and R - visualization, is available on github:
github.com/SergeyParamonov/genetics-experiments
findings
We dealt with the basic structure of genetic algorithms and applied to solving the problem of string mutation. As a result of experiments with classical texts, we found that in our conditions there is a linear relationship between the length of the line and the number of generations necessary to achieve the input line.
We also noted that the basic search structure can be modified (for example, using crossover — using several generation members to create descendants) to solve a wide class of optimization problems where it is too difficult to find an exact solution.
Source: https://habr.com/ru/post/246951/
All Articles