New optimizations for x86 in GCC 5.0: PIC in 32-bit mode
This post continues a series of three articles on x86 optimizations in GCC 5.0. The previous article dealt with vectorization . Let me remind you that GCC 5.0 is now in phase stage3, that is, the introduction of new optimizations has actually been completed and the level of performance with rare exceptions will remain the same in the product release. Today we will talk about the acceleration of position-independent code or position independent code (PIC) in 32-bit mode for x86.
PIC (according to Wikipedia ) is a program that can be placed in any area of memory, since all references to memory cells in it are relative. This method of compiling the program is used for Android, libraries and many other applications. Most Android applications are now 32-bit, so GCC performance for the PIC in 32-bit mode is very important.
It is expected that GCC 5.0 will significantly ( up to 30% ) overclock applications where performance is concentrated in an integer cycle, namely, such as cryptography, data protection from interference, data compression, hashing and others, especially those where vectorization is by reasons not applied.
What has changed in GCC 5.0 compared to GCC 4.9?
')
In GCC 4.9, the EBX register is reserved for the address of the global offset table or the global offset table (GOT) and is therefore not available for distribution. Thus, for PIC in 32-bit mode, only 6 registers are available (instead of the usual 7): EAX, ECX, EDX, ESI, EDI and EBP. This leads to a significant loss of performance when there are not enough registers to distribute.
In GCC 5.0, the EBX register is available for allocation. Thus, the total number of free registers for the PIC does not differ from the absolute code . Below are the results for the test with integer calculations in a loop with a lack of registers.
Where:
Such a matrix is used to minimize the computations within the cycle to relatively fast additions and subtractions, but to increase the number of dependencies.
Compile options "-Ofast -funroll-loops -fno-tree-vectorize --param max-completely-peeled-insns = 200" plus "-march = slm" for Silvermont , "-march = core-avx2" for Haswell , " -fPIC "for PIC and" -DLD = {4, 5, 6, 7, 8} -DST = 7 "
"-fno-tree-vectorize" - is used to avoid vectorization and, therefore, using xmm registers (of which the same amount is always available)
"--param max-completely-peeled-insns = 200" - are used so that GCC 5.0 and 4.9 are equal, since for 4.9 this parameter was equal to 100
The performance gain of GCC 5.0 compared to 4.9 (how many times it accelerated, higher - better).
The x-axis changes the number of downloads in the loop: LD. More “LD” leads to greater register pressure.
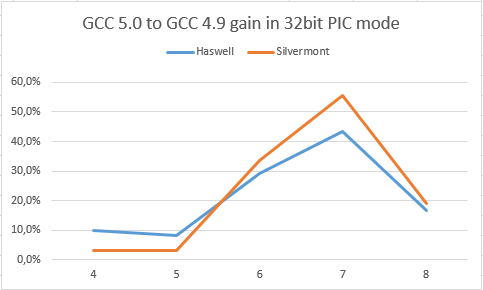
Here we see that both Silvermont and Haswell show an impressive increase. But in order to confirm that this happened precisely because of the addition to the distribution of the EBX register, one should turn to 2 charts below:
These charts show the slowdown from the transition to the PIC for Haswell and Silvermont on GCC 5.0 and GCC 4.9 compilers (higher is better)
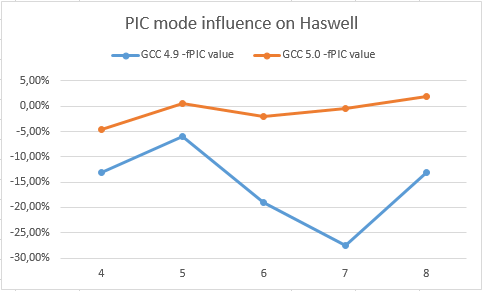
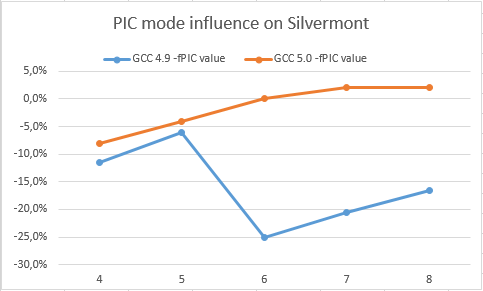
Here you can see that GCC 5.0 does not lose much from the transition to the PIC. On the contrary, GCC 4.9 slows down quite significantly on both Haswell and Silvermont. This confirms that GCC 5.0 should speed up integer loops for PICs. Moreover, developers will be able to use more aggressive optimizations (increasing register pressure), such as spin unrolling, function inline substitution, more aggressive removal of invariants ...
You can try GCC 5.0 now. Porting to Android NDK is also possible.
Processors used in measurements:
Silvermont : Intel® Atom (TM) CPU C2750 @ 2.41GHz
Haswell : Intel® Core (TM) i7-4770K CPU @ 3.50GHz
Compilers used in measurements:
You can download the example on which measurements were taken from the original text of the article in English .
PIC (according to Wikipedia ) is a program that can be placed in any area of memory, since all references to memory cells in it are relative. This method of compiling the program is used for Android, libraries and many other applications. Most Android applications are now 32-bit, so GCC performance for the PIC in 32-bit mode is very important.
It is expected that GCC 5.0 will significantly ( up to 30% ) overclock applications where performance is concentrated in an integer cycle, namely, such as cryptography, data protection from interference, data compression, hashing and others, especially those where vectorization is by reasons not applied.
What has changed in GCC 5.0 compared to GCC 4.9?
')
In GCC 4.9, the EBX register is reserved for the address of the global offset table or the global offset table (GOT) and is therefore not available for distribution. Thus, for PIC in 32-bit mode, only 6 registers are available (instead of the usual 7): EAX, ECX, EDX, ESI, EDI and EBP. This leads to a significant loss of performance when there are not enough registers to distribute.
In GCC 5.0, the EBX register is available for allocation. Thus, the total number of free registers for the PIC does not differ from the absolute code . Below are the results for the test with integer calculations in a loop with a lack of registers.
int i, j, k; uint32 *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < ST; k++) { uint32 s = 0; for (j = 0; j < LD; j++) s += (in[j] * c[j][k] + 1) >> j + 1; out[k] = s; } in += LD; out += ST; } Where:
- c is a constant matrix:
const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1}; Such a matrix is used to minimize the computations within the cycle to relatively fast additions and subtractions, but to increase the number of dependencies.
- in and out - pointers to global arrays "a [1024 * LD]" and "b [1024 * ST]"
- uint32 is unsigned int
- LD and ST are macros that define the length of a group of loads from memory and save to memory, respectively.
Compile options "-Ofast -funroll-loops -fno-tree-vectorize --param max-completely-peeled-insns = 200" plus "-march = slm" for Silvermont , "-march = core-avx2" for Haswell , " -fPIC "for PIC and" -DLD = {4, 5, 6, 7, 8} -DST = 7 "
"-fno-tree-vectorize" - is used to avoid vectorization and, therefore, using xmm registers (of which the same amount is always available)
"--param max-completely-peeled-insns = 200" - are used so that GCC 5.0 and 4.9 are equal, since for 4.9 this parameter was equal to 100
The performance gain of GCC 5.0 compared to 4.9 (how many times it accelerated, higher - better).
The x-axis changes the number of downloads in the loop: LD. More “LD” leads to greater register pressure.
Here we see that both Silvermont and Haswell show an impressive increase. But in order to confirm that this happened precisely because of the addition to the distribution of the EBX register, one should turn to 2 charts below:
These charts show the slowdown from the transition to the PIC for Haswell and Silvermont on GCC 5.0 and GCC 4.9 compilers (higher is better)
Here you can see that GCC 5.0 does not lose much from the transition to the PIC. On the contrary, GCC 4.9 slows down quite significantly on both Haswell and Silvermont. This confirms that GCC 5.0 should speed up integer loops for PICs. Moreover, developers will be able to use more aggressive optimizations (increasing register pressure), such as spin unrolling, function inline substitution, more aggressive removal of invariants ...
You can try GCC 5.0 now. Porting to Android NDK is also possible.
Processors used in measurements:
Silvermont : Intel® Atom (TM) CPU C2750 @ 2.41GHz
Haswell : Intel® Core (TM) i7-4770K CPU @ 3.50GHz
Compilers used in measurements:
You can download the example on which measurements were taken from the original text of the article in English .
Source: https://habr.com/ru/post/246913/
All Articles